本文主要是介绍基于ENVI5.3和ArcGIS实现不同等级数据面积统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
假如我有一个地区的FVC数据,我要对整个数据分级,分成5个或者10个等级,然后统计每个等级所占的面积,那么用ENVI该怎么实现呢?
如下图所示,就是我的一个地区的FVC数据。
为了节约演示时间,我把这个数据分为5个等级。

选中数据,然后右键,找到New Raster Color Slices 点击,然后在文件中找到你要分级统计的数据,点击确认。

点击确认后,就会发现软件会给你自动做一个分级,也就是给你分了16级,当然我们这里不要他自动的分级结果。我们就把所有的x掉,自己重新分为5级。

如下图所示,那个四个x的就是删除全部,绿色十字架的那个就是添加分级的按钮,下图就是我自己设置好的分级的结果,每一个小级都可以自己设置颜色,我这里是FVC也就是植被覆盖度,那当然用绿色显示最合适了!
大家可以看我我右边圈住的那个红色方框,FVC值介于0-1之间,你可以根据这个间距设置你自己认为合理的区间哈。

大家可以看下,下图就是我设置分级的结果图,红色都是值比较低的趋势,基本上都是城区,大致是合理的。
下面我要讲到最核心的部分了,我如何统计这5个等级所占的面积呢?

选择 statistics for all colors ,选择FVC数据。

发现,额,报错了。原因可能是数据太大了或者其他原因,但是数据量小的情况下一般不会报错,就是直接统计了。出现报错,我们选择其他方法:
将分级结果导出为shp文件,然后使用ArcGIS的分区统计工具。

选择slices ,右键导出为shp文件,并重新命名。
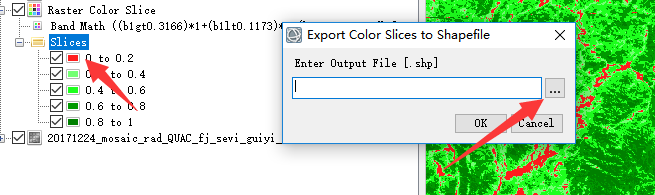
然后导出为shp文件后使用以表格显示分区统计进行统计。
我数据量过大,就先用我之前存的数据演示:
下图这是我统计不同高程的FVC面积,所用的那个shp文件,为啥要转shp呢,因为那个dem数据是30米的,它与遥感影像空间分辨率不一致(GF-4 PMS 50米),不好匹配。
 找到这个工具就可以统计了,剩下的步骤就是选择数据,导出结果就可以了,输出结果是一个表格样式的,不同等级参数的面积都可以显示出来。
找到这个工具就可以统计了,剩下的步骤就是选择数据,导出结果就可以了,输出结果是一个表格样式的,不同等级参数的面积都可以显示出来。


这篇关于基于ENVI5.3和ArcGIS实现不同等级数据面积统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








