本文主要是介绍geopandas学习(五)分层设色,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
geopandas学习(五)分层设色
文章参考:参考
地区分布图(Choropleth maps,又叫面量图)作为可能是最常见的一种地理可视化方法。
其核心是对某个与矢量面关联的数值序列进行有意义的分层,并为这些分层选择合适美观的色彩,最后完成对地图的着色。
优点是美观且直观,即使对地理信息一窍不通的人,也能通过颜色区分出不同面之间的同质性与异质性:
但同样地,如果对数据分层采取的方法有失严谨没有很好的遵循数据特点,会很容易让看到图的人产生出不正确的判断。
下面我们按照先分层,后设色的顺序进行介绍。
1.1 基于mapclassify的数据分层
上一篇文章中我们提到过,,在geopandas.GeoDataFrame.plot()中,参数scheme对应的数据分层是基于第三方库mapclassify实现的。
import pandas as pd
import matplotlib.pyplot as plt
import geopandas as gpd
import warningswarnings.filterwarnings('ignore')%matplotlib inline
plt.rcParams["font.family"] = "SimHei" # 设置全局中文字体为黑体# 读入中国矢量数据
china = gpd.read_file('zip://china-shapefiles.zip!china-shapefiles',layer='china',encoding='utf-8')# 由于每行数据是单独的面,因此按照其省份列OWNER融合
china = china.dissolve(by='OWNER').reset_index(drop=False)# 读入南海九段线数据
nine_lines = gpd.read_file('zip://china-shapefiles.zip!china-shapefiles',layer='china_nine_dotted_line',encoding='utf-8')# 读入2020-03-08更新的新冠肺炎原始数据
raw = pd.read_csv('DXYArea.csv', parse_dates=['updateTime'])# 定义CRS
albers_proj = '+proj=aea +lat_1=25 +lat_2=47 +lon_0=105'# 抽取updateTime列中的年、月、日信息分别保存到新列中
raw['year'], raw['month'], raw['day'] = list(zip(*raw['updateTime'].apply(lambda d: (d.year, d.month, d.day))))# 得到每个省份最新的指标数据
temp = raw.sort_values(['provinceName', 'updateTime'], ascending=False, ignore_index=True).groupby('provinceName') \.first() \.reset_index(drop=False) \.loc[:, ['provinceName', 'provinceEnglishName','province_confirmedCount','province_suspectedCount','province_curedCount','province_deadCount']]# 查看前5行
temp.head()
因此要想对geopandas中的数据分层有深入的了解,我们就得先来了解一下mapclassify中的各种数据分层算法。
1.1.1 BoxPlot
在mapclassify中我们使用BoxPlot()来为数据实现箱线图分层:
import mapclassify as mc# 对各省2020-03-04对应的累计确诊数量进行分层
bp = mc.BoxPlot(temp['province_confirmedCount'])
# 查看数据分层结果
bp
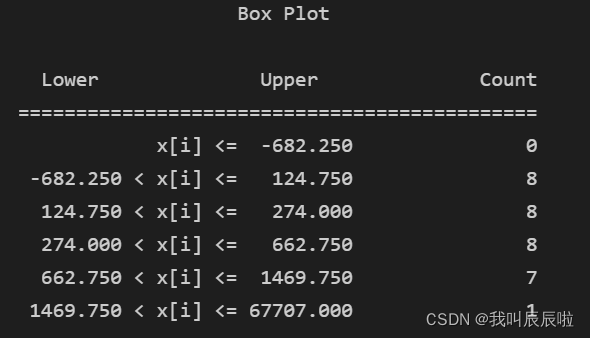
可以看出通过箱线图法将数据分成了五类,其中异常值只有1个即为湖北省。
下面我们配合geopandas来对上述结果进行可视化,和上一篇文章一样,按照省级单位名称连接我们的疫情数据与矢量数据:
data_with_geometry = pd.merge(left=temp.replace('澳门', '澳门特别行政区'),right=china,left_on='provinceName',right_on='OWNER',how='right').loc[:, ['provinceName','provinceEnglishName','province_confirmedCount','province_suspectedCount','province_curedCount','province_deadCount','geometry']]
# 将数据从DataFrame转换为GeoDataFrame
data_with_geometry = gpd.GeoDataFrame(data_with_geometry, crs='EPSG:4326')
data_with_geometry.head()
接着对其进行可视化,在上一篇文章图28的基础上,将scheme参数改为BoxPlot,又因为箱线图可以看作无监督问题,故分层数量k在这里无效,删去:
fig, ax = plt.subplots(figsize=(10, 10))ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,column='province_confirmedCount',cmap='Reds',missing_kwds={"color": "lightgrey","edgecolor": "black","hatch": "","label": "缺失值"},legend=True,scheme='BoxPlot',legend_kwds={'loc': 'lower left','title': '确诊数量分级','shadow': True})ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,edgecolor='grey',linewidth=3,alpha=0.4)ax.axis('off')
plt.suptitle('新型冠状肺炎累计确诊数量地区分布', fontsize=24) # 添加最高级别标题
plt.tight_layout(pad=4.5) # 调整不同标题之间间距
ax.text(-2800000, 1300000, '* 原始数据来源&这篇关于geopandas学习(五)分层设色的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








