本文主要是介绍NLP泰斗董振东老师与他的知网 | 纪念,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 点击上方↑↑↑蓝字关注我们~
点击上方↑↑↑蓝字关注我们~ 
参加 2019 Python开发者日,请扫码咨询 ↑↑↑
整理 | 琥珀
出品 | AI科技大本营(ID:rgznai100)
昨晚,我们通过中国中文信息学会发布的讣告得知,我国著名中文信息处理专家、《知网》(HowNet)发明人董振东教授,于 2019 年 2 月 28 日凌晨十二时零八分在加拿大蒙特利尔市逝世,享年 82 岁。昨日,也是我们获悉深度学习三巨头 Yoshua Bengio、Yann LeCun、Geoffrey Hinton 获得 ACM 图灵奖的日子。不禁慨叹:岁月既成就了对科研孜孜不倦者的计算机事业,也令其两鬓斑白、盛年不再,一晃几十年过去。
很长时间里,他们也是作为后辈的我们值得尊敬和学习的榜样。随后,自然语言处理专家、现任京东首席科学家的李维重发旧文,并摘录了董老师的语录金句:“我们老了,但机器翻译还年轻”、“我这一辈子做了二件事,一件是别人不愿做的事,一件是别人做不了的事”……
在今年年初清华大学发布的四个知识计算开放平台(内容涵盖语言知识、常识知识、世界知识和科技知识库)里,其中一个正是源自在中文世界有巨大影响力的语言和常识知识库《知网》(HowNet)的 OpenHowNet。
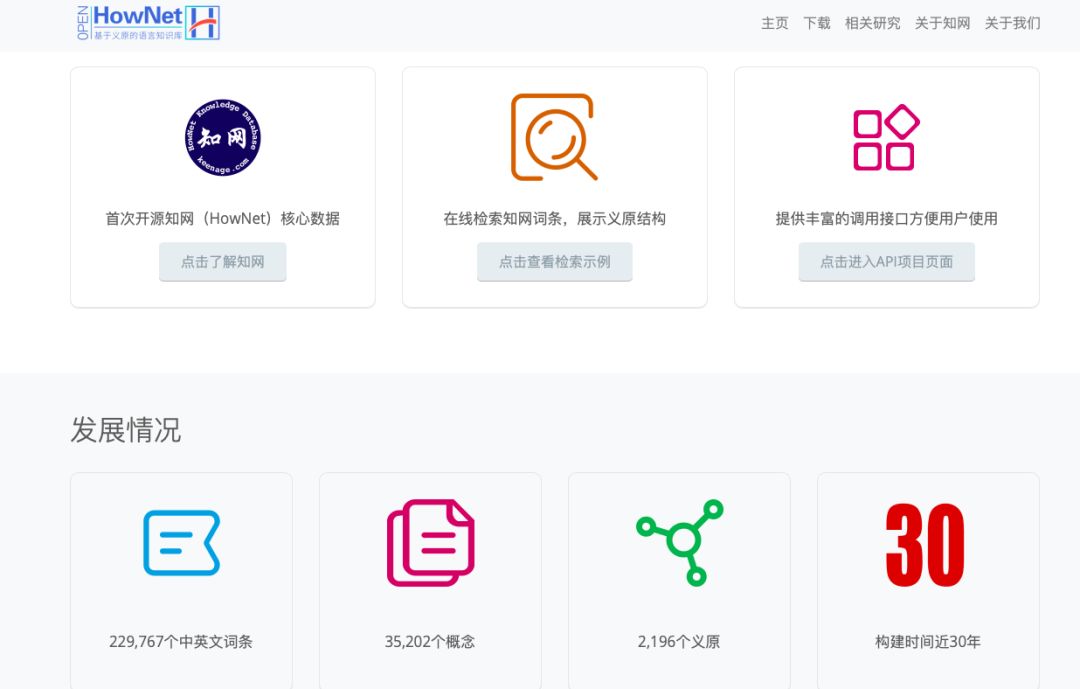
https://openhownet.thunlp.org/about_hownet
这也将我们拉回到了董振东教授与他毕三十年之功建立的《知网》(HowNet)。据悉,知网是一个以汉语和英语的词语所代表的概念为描述对象,以解释概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。《知网》的构建秉承还原论思想,即所有词语的含义可以由更小的语义单位构成,而这种语义单位被称为“义原”(Sememe),即最基本的、不宜再分割的最小语义单位。它构建了包含 2000 多个义原的精细的语义描述体系,并为十几万个汉语和英语词所代表的概念标注了义原。
欢迎来到《知网》的页面:(需要强调的是,此《知网》并非我们之前所说的中国知网“CNKI”。)

该网站是研究知识处理和多语言 NLP 的基础。重点是对 NLP 的深入研究以及语言基础设施的建设。它旨在推动语言数据可以形成合力、分享和频繁交流。希望它能成为中国语言协会的孵化器。
《知网》最早由董振东、董强父子二人在 20 世纪 90 年代设计和构建,至今已有近 30 年历史,期间不断迭代更新。这个页面上,承载着是两代人的心血。2017 年,语知科技公司,基于《知网》的语义分析技术,作为一个输出自然语言理解技术的平台开始成立。
在这个网站上,我们看到了《知网》上线以来的所有动态:

http://www.keenage.com/html/c_index.html
我们还能找到董振东教授接受记者采访时的点滴记录:
记者:您为什么要公开知网?
董振东:我从事科研工作之初,就一直主张在基础研究中的资源性成果应该进行公开。现在有了 Internet,它提供了一个公开的天地。我为什么主张公开呢?因为十几年来,我看到国内的许多研究生在做项目时,导师让他做中文的分析,但是他最后没有做,他没有办法做,由于他没有计算机分析用的词典,词典中起码要有词性、词义等内容。再有,中文句子中,每个词连在一起,他还需要分词。所以,他必须先完成词典和分词工具软件。做完这些工作,两年的时间已经过去了,他该毕业了。而且他只能做一个规模很小的东西,因为没有那么多时间。也就是说,基础的东西太多了,尤其是中文。
中文是非常复杂的,和英文等西方语言不一样……中文处理时,需要分词。分词系统根本不是一个应用系统,和机器翻译完全不一样,分词永远不是目的。但是,尽管国内有各种各样的分词系统,但网上一个也没有。一个人在深入研究中文处理时,有一个现成的分词系统就行了,准确率是 95% 或 97% 都关系不大。因为要研究的是后面的内容。但是由于研究者拿不到这些信息,就逼着他去做前面的。这样造成严重的低水平重复。同时,每个人都做不了很大、很全面的系统。词典也是如此。
http://www.keenage.com/html/news/news.html
刘知远曾在一篇文章《在深度学习时代用 HowNet 搞事情》中简谈过对 HowNet 的看法,他表示:“HowNet 在 2000 年前后引起了国内 NLP 学术界极大的研究热情,在词汇相似度计算、文本分类、信息检索等方面探索了 HowNet 的重要应用价值,与当时国际上对 WordNet 的应用探索相映成趣。”
生平简历
董振东,1937 年 4 月生,上海人。
董振东教授自 70 年代即开始从事机器翻译研究工作。
1987 年成功开发了我国第一个商品化机器翻译系统原型《科译 1 号》。
1987 年至 1992 年,他担任中国、日本、马来西亚、印尼、泰国五国多国语机器翻译国际合作项目的中方技术负责人。
1990 年作为 “905” 中文信息平台项目的总体组负责人,指导和规划了平台的总体设计和实施计划。
1990 年代后期开始设计与实现的《知网》,在理论上和实践上均具有重大的发现和独创。《知网》在国内外产生了重要影响。
1987 年获得解放军科技进步二等奖和国家科技进步二等奖。
2011 年获得中国中文信息学会首届终身成就奖。
2012 年获 “钱伟长中文信息处理科学技术奖” 一等奖。
董振东教授现任清华大学人工智能研究院知识智能研究中心学术顾问,上海交通大学、北方软件学院兼职教授。曾担任军事科学院研究员、机器翻译研究组组长,五国机器翻译国际合作项目中方技术负责人,中国软件公司语言工程实验室主任,日本言语研究所主任研究员,新加坡国立大学系统科学研究院研究员等职。
中国中文信息学会表示:董振东教授曾任中国中文信息学会常务理事,我国机器翻译事业的开创者,毕生从事机器翻译研究与开发工作,为我国中文信息处理事业做出了突出贡献,他倡导的创新精神影响了一大批中青年学者。
缅怀!
(*本文是AI科技大本营整理文章,转载请联系原作者)
◆
精彩推荐
◆
「2019 Python开发者日」7折票限时开售!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。
目前演讲嘉宾议题已确认,扫描海报二维码,即刻抢购7折优惠票价!更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
免费线下沙龙 | Python 技术学习指南与趋势探讨
清华、北大、浙大的计算机课程资源集都在这里了
受用一生的高效PyCharm使用技巧
GitHub超全机器学习工程师成长路线图,开源两日收获3700+Star!
腾云驾雾的计算,让你蒙圈了么?
中本聪的足球队,香吗?
漫画:我是程序员,总想打产品经理怎么办?
让苹果“沦为配角”的华为都发布了什么?
曝光!月薪5万的程序员面试题:73%人都做错,你敢试吗?

你也可以点击阅读原文,查看大会详情。
这篇关于NLP泰斗董振东老师与他的知网 | 纪念的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







