本文主要是介绍西工大CSAPP第二章课后题2.56~2.58答案及解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
因为我获取并阅读CSAPP电子书的方式是通过第三方网站免费下载,没有付给原书作者相应的报酬,遵循价值交换原则,我会尽我所能通过博客的方式,推广这本书以及原书作者就职的大学,以此回馈原书作者的劳动成果。另外,由于西工大让我能够不认真听课、不好好写作业、糊弄考试还能过,有了很多很多时间做自己认为对社会有价值的事情,所以感谢西工大对我的宽容与支持。
2.56 尝试为了不同样例数值,运行show_bytes代码
“尝试为了不同样例数值”的意思有两点:1. 不带参数运行a10292023.exe的输出中的其它的结果也应该被考虑;2. 带参数运行a10292023.exe的输出中的结果也应该被考虑。因为第1点已经在前文被分析到,所以本文只分析第2点,带参数运行a10292023.exe的输出中的结果。
PS D:\C> .\a10292023.exe 2
calling test_show_bytes
02 00 00 00
00 00 00 40
e4 fe 61 00
PS D:\C> .\a10292023.exe -2
calling test_show_bytes
fe ff ff ff
00 00 00 c0
e4 fe 61 00
在第1个例子中,".\a10292023.exe 2"表示在当前的工作目录下,运行a10292023.exe文件,同时将"2"作为参数传给a10292023.exe中的main()函数部分。编译生成a10292023.exe文件的源文件是a10292023.c,a10292023.c中的main()函数的定义是"int main(int argc, char *argv[])",因为运行a10292023.exe文件时,参数2被传递给main()函数,所以argc的值是2,表示指针数组argv中有两个元素。在指针数组argv中,第1个元素argv[0]是字符串"a10292023.exe",第2个元素argv[1]是字符串"2"。为了了解当参数为2时a10292023.exe的输出结果,将main()函数的内容显示在下面,并且弄清楚"argc>1"时main()函数的运行逻辑是有必要的。
int main(int argc, char *argv[])
{int val = 12345;if (argc > 1) {if (argc > 1) {val = strtol(argv[1], NULL, 0);}printf("calling test_show_bytes\n");test_show_bytes(val);} else {printf("calling show_twocomp\n");show_twocomp();printf("Calling simple_show_a\n");simple_show_a();printf("Calling simple_show_b\n");simple_show_b();printf("Calling float_eg\n");float_eg();printf("Calling string_ueg\n");string_ueg();printf("Calling string_leg\n");string_leg();}return 0;
}当"argc"大于1时,"val = strtol(argv[1], NULL, 0);","strtol"函数能够将字符串形式的整数转换为整型的变量,比如“3”会转换为int型的3,“4”会转换为int型的4,“4a”会转换为int型的4,而考虑到“a”是一个字符型的字符,而不是整数型的字符,所以“a”不会被转换。在例子中,"strtol"函数读取字符串"argv[1]"中的内容,并且将无法转换的第一个字符存到"NULL"指向的变量中。当然因为"NULL"是一个空指针,所以不会保存无法转换的第一个字符。"0"表示根据argv[1]字符串中整数的表示形式,自动决定相应的进制。如果argv[1]字符串是以"0x"开头,那么将以16进制的形式将字符串中的整数部分转换为整型的变量,如果argv[1]字符串是以"0"开头,那么将以8进制的形式将字符串中的整数部分转换为整型的变量,如果argv[1]字符串既不以"0"开头,又不以"0x"开头,那么将以10进制的形式将字符串中的整数部分转换为整型的变量。虽然strtol的返回值是一个长整型的变量,但是考虑到长整型"long int"变量和整型"int"变量的长度都是4个字节,所以即使变量val被定义为整型int,也不会因为隐式类型转换埋下不必要的隐患。在第1个例子中,val变量被赋值为2,"printf("calling test_show_bytes\n");"在Powershell中输出"calling test_show_bytes"。"test_show_bytes(val);"表示"main()"函数调用"test_show_bytes()"函数。"test_show_bytes()"函数的内容如下图所示:
/* $begin test-show-bytes */
void test_show_bytes(int val) {int ival = val;float fval = (float) ival;int *pval = &ival;show_int(ival);show_float(fval);show_pointer(pval);
}
/* $end test-show-bytes */"int ival = val;"表示定义一个整型变量ival,并且变量ival的值被初始化为变量val的值,因为变量ival和变量val的数据类型都是整型,所以不存在类型转换。"float fval = (float) ival;"表示定义一个浮点型变量fval,并且变量fval的值被初始化为变量ival的值,这里存在强制类型转换。"int *pval = &ival;"表示定义一个指针变量,指向int型变量ival。接着调用三个函数"show_int(ival);"、"show_float(fval);"、"show_pointer(pval);",分别输出三个变量ival, fval和pval在内存中的机器数表示。
void show_int(int x) {show_bytes((byte_pointer) &x, sizeof(int)); //line:data:show_bytes_amp1
}void show_float(float x) {show_bytes((byte_pointer) &x, sizeof(float)); //line:data:show_bytes_amp2
}void show_pointer(void *x) {show_bytes((byte_pointer) &x, sizeof(void *)); //line:data:show_bytes_amp3
}观察输出结果,不难发现被市面上大部分适配Intel64位CPU的笔记本采用的字节顺序是小端。
第2个例子的分析方法是类似于第1个例子的分析方法。综上所述,我们确定了,被市面上大部分适配Intel64位CPU的笔记本采用的字节顺序是小端。
2.57 编写程序"show_short", "show_long", "show_double",打印类型为short, long, double对应的C数据对象的字节表示,尝试在不同的机器上运行它们。
参考a10292023.c文件中已有的"show_int", "show_float"函数的函数格式,可以写出如下图所示的三个程序"show_short", "show_long"和"show_double"。
void show_short(short x) {show_bytes((byte_pointer) &x, sizeof(short)); //line:data:show_bytes
}
void show_long(long x) {show_bytes((byte_pointer) &x, sizeof(long)); //line:data:show_bytes
}
void show_double(double x) {show_bytes((byte_pointer) &x, sizeof(double)); //line:data:show_bytes
}三个函数的不同有两点:1. 三个函数的参数不同,第1个函数使用短整型short型的变量作为参数,第2个函数使用长整型long型的变量作为参数,第3个函数使用双精度浮点型double型的变量作为参数;2. 三个函数虽然都调用了"show_bytes"函数,但是在给"show_bytes"函数传递参数时,第2个传入参数的值分别是2、4、8,之所以第2个传入参数的值是2、4、8,是因为short型变量在内存中占用空间的大小是2B,long型变量在内存中占用空间的大小是4B,double型变量在内存中占用空间的大小是8B。show_bytes函数将从short或long或double变量在内存中空间的第一个字节地址开始,一次读取这个字节地址之后连续的2、4、8个字节。通过这样的操作,就能够分别实现"show_short","show_long"和"show_double"。
在a10292023.c文件中,将已写好的"show_short","show_long"和"show_double"插入到"show_int"与"show_float"函数之间,并且修改"test_show_bytes()"函数。
/* $begin test-show-bytes */
void test_show_bytes(int val) {int ival = val;float fval = (float) ival;int *pval = &ival;short sval = (short)ival;long lval = (long)ival;double dval = (double)ival;show_int(ival);show_float(fval);show_pointer(pval);show_short(sval);show_long(lval);show_double(dval);
}
/* $end test-show-bytes */接着使用带参数运行C可执行文件的形式,在Powershell中运行a10292023.exe文件,得到了图示的结果:
PS D:\C> .\a10292023.exe 233
calling test_show_bytes
e9 00 00 00
00 00 69 43
d4 fe 61 00
e9 00
e9 00 00 00
00 00 00 00 00 20 6d 40
PS D:\C> .\a10292023.exe 123456
calling test_show_bytes
40 e2 01 00
00 20 f1 47
d4 fe 61 00
40 e2
40 e2 01 00
00 00 00 00 00 24 fe 40
值得注意的是,在第2个例子中,当运行a10292023.exe文件时的参数是123456时,"short sval = (short)ival;"会将变量ival的高2字节截断。变成了"40 e2"。还有针对"show_bytes"函数中"printf(" %.2x", start[i]);"的输出,根据cplusplus网站对printf函数特性的文档,可以将其修改为"printf(" %.2hhx", start[i]);"这样子更能直观的显示出,变量start[i]的大小是1B。
2.58 编写一个名为"is_little_endian"的程序,当被编译并且运行在小端机器上时会返回1,当被编译并且运行在大端机器上时会返回0。这个程序应该能运行在任何机器上,而不必考虑字的大小。
#include<stdio.h>
#include<limits.h>
typedef unsigned char* byte_pointer;
int is_little_endian() {int a = INT_MIN;byte_pointer b = (byte_pointer)&a;return !b[0];
}
int main() {printf("%d", is_little_endian());return 0;
}注意int型变量的大小可能为2B,也可能为4B,为什么呢?因为根据C标准确定了int类型变量必须能够表示的最小范围是-32767~32768,对于无符号整型unsigned int来说,这个范围是0~65535,至于具体应该比这个范围大,还是和这个范围相同,则取决于机器自己。C标准确定的整型变量应该能够表示的最小范围如下图所示:
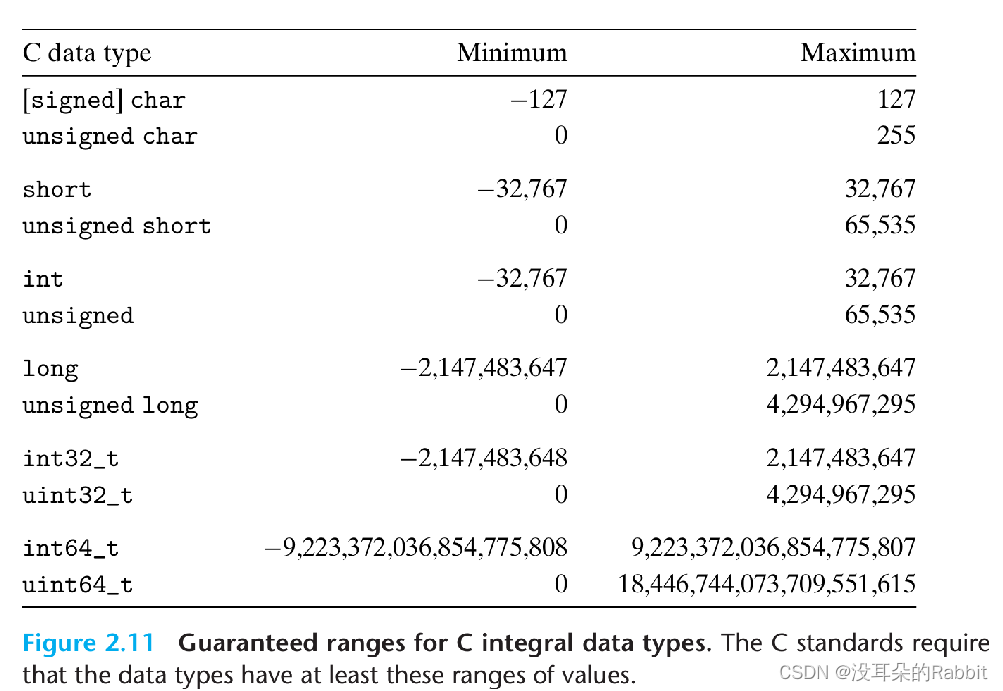
因为历史原因,一个字的长度可能为2B,也有可能为4B,就像是int类型变量的大小可能为2B,也可能为4B。题目要求不考虑字的大小,就是要不考虑int类型变量占据内存中存储空间的大小,所以我们可以使用"sizeof(int)"来自动确定int类型变量占据内存中存储空间的大小。这样子就能确保程序能够运行在任何机器上,而不必考虑字的大小。
题目要求,编写程序,当运行该程序的机器的字节顺序是小端顺序时,返回值是1,而当运行该程序的机器的字节顺序是大端顺序时,返回值是0。根据大端顺序和小端顺序的性质,在小端顺序下,在一个变量被内存分配给的一块存储空间中,一个变量的低位被存放在低地址,高位被存放在高地址。对于"limits.h"头文件中定义的宏"INT_MIN",它表示int类型的变量的最小值,为-32767或者更小,具体有多小取决于该机器对于int类型变量长度的定义。如果int类型变量的长度为2B,那么INT_MIN在内存中的表示即为0x8000,如果int类型变量的长度为4B,那么INT_MIN在内存中的表示即为0x80000000。"byte_pointer b = (byte_pointer)&a;"定义一个指针类型的变量b,指向变量a被内存分配给的一块存储空间的第1个字节。"return !b[0];"如果运行该程序的机器使用的字节顺序是小端,那么变量b指向的变量a被内存分配给的一块存储空间的第1个字节会是0,即"b[0]=0x00";而如果运行该程序的机器使用的字节顺序是大端,那么变量b指向的变量a被内存分配给的一块存储空间的第1个字节会是80,即"b[0]=0x80"。但如果只是返回"b[0]"的话,不光会错误显示是否大小端,而且即使机器采用的是大端顺序,返回值也会是32768(如果机器给int类型变量定义的长度是4B)或者-32768(如果机器给int类型变量定义的长度是2B)。所以为了避免出现这种情况,在本应返回的"b[0]"之前,添加"!",即返回"!b[0]"。当运行该程序的机器的字节顺序是小端时,"b[0]"的值为0x00,进行逻辑非操作之后的结果为"0x1";当运行该程序的机器的字节顺序时大端时,"b[0]"的值为0x80,进行逻辑非操作之后的结果为"0x0"。这样子就能够达到题目的要求:当被编译并且运行在小端机器上时会返回1,当被编译并且运行在大端机器上时会返回0。同时因为截取的字节位是b[0],而不是b[1]或者b[3],无论具体机器对int类型变量的长度的定义如何,该程序都能够正常并且正确的运行。所以除了能够达到题目要求之外,也能够满足题目的限制条件。
2.59 写一个C的表达式,它将表示由x的最低位字节和y的其余位字节组成的一个字。对于运算式x=0x89ABCDEF和y=0x76543210来说,它将表示0x765432EF。
#include<stdio.h>
#include<stdlib.h>
unsigned int word_combine(int x, int y) {return x&0xFF | y&0xFFFFFF00;
}
int main(int argc, char* argv[]) {unsigned int x = (unsigned int)strtoul(argv[1], NULL, 0);unsigned int y = (unsigned int)strtoul(argv[2], NULL, 0);printf("%#x", word_combine(x, y));return 0;
}PS D:\C> gcc -o d10222023 d10222023.c
PS D:\C> .\d10222023.exe 0x89ABCDEF 0x76543210
0x765432ef
PS D:\C> .\d10222023.exe 0x13151719 0x24262820
0x24262819
PS D:\C>
在"main"函数中, "unsigned int x = (unsigned int)strtoul(argv[1], NULL, 0);",定义一个无符号整型变量x,并将变量x的值初始化为"strtoul"的被强制转换为unsigned int类型的返回值,"strtoul"函数将从"argv[1]"字符串中自动判断进制,并读取一个无符号长整型数,而返回值也是一个无符号长整型数。在这里进行强制类型转换的目的是,明确并强调函数"strtoul"的返回值是无符号长整型,而不是无符号整型。在这里不使用strtol函数读取有符号长整型数的原因是,凡是大于"0x7FFFFFFF"的数,都会被"strtol"函数判定为超出了有符号长整型数的最大表示范围,进而统一视为"0x7FFFFFFF"处理。"unsigned int y = (unsigned int)strtoul(argv[2], NULL, 0);"同上,"printf("%#x", word_combine(x, y));"输出经过处理后的结果,"%#x"中的"#"表示自动在十六进制数前添加"0x"前缀,相当于"0x%x"。"%#x"中的x表示以十六进制形式输出整型数。接着看"word_combine"函数,"return x&0xFF | y&0xFFFFFF00;"中的C表达式"x&0xFF | y&0xFFFFFF00"即为题目要求的表达式。"x&0xFF"获取了x的最低位字节,对于"x=0x89ABCDEF"来说,"x&0xFF=0x000000EF","y&0xFFFFFF00"获取了y中除了最低位字节以外的其余字节,对于"y=0x76543210"来说,"y&0xFFFFFF00=0x76543200",最后"x&0xFF | y&0xFFFFFF00"通过按位或的操作,将两个按位与操作之后的结果融合在一起,对于"x=0x89ABCDEF, y=0x76543210"来说,结果即为"0x765432EF"。
这篇关于西工大CSAPP第二章课后题2.56~2.58答案及解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



