本文主要是介绍每日慢查询上亿,快看美团的SQL急救大法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于数据库来说,慢查询往往意味着风险。SQL执行得越慢,消耗的CPU资源或IO资源也会越大。大量的慢查询可直接引发业务故障,关注慢查询即是关注故障本身。本文主要介绍了美团如何利用数据库的代价优化器来优化慢查询,并给出索引建议,评估跟踪建议质量,运营治理慢查询。
一、背景
慢查询是指数据库中查询时间超过指定阈值(美团设置为100ms)的SQL,它是数据库的性能杀手,也是业务优化数据库访问的重要抓手。随着美团业务的高速增长,日均慢查询量已经过亿条,此前因慢查询导致的故障约占数据库故障总数的10%以上,而且高级别的故障呈日益增长趋势。因此,对慢查询的优化已经变得刻不容缓。
那么如何优化慢查询呢?最直接有效的方法就是选用一个查询效率高的索引。关于高效率的索引推荐,主要有基于经验规则和代价的两种算法。
在日常工作中,基于经验规则的推荐随处可见,对于简单的SQL,如 select * from sync_test1 where name like 'Bobby%' ,直接添加索引IX(name) 就可以取得不错的效果;但对于稍微复杂点的SQL,如 select * from sync_test1 where name like 'Bobby%' and dt > '2021-07-06' ,到底选择IX(name)、IX(dt)、IX(dt,name) 还是IX(name,dt),该方法也无法给出准确的回答。更别说像多表Join、子查询这样复杂的场景了。所以采用基于代价的推荐来解决该问题会更加普适,因为基于代价的方法使用了和数据库优化器相同的方式,去量化评估所有的可能性,选出的是执行SQL耗费代价最小的索引。
二、基于代价的优化器介绍
1、SQL执行与优化器
一条SQL在MySQL服务器中执行流程主要包含:SQL解析、基于语法树的准备工作、优化器的逻辑变化、优化器的代价准备工作、基于代价模型的优化、进行额外的优化和运行执行计划等部分。具体如下图所示:
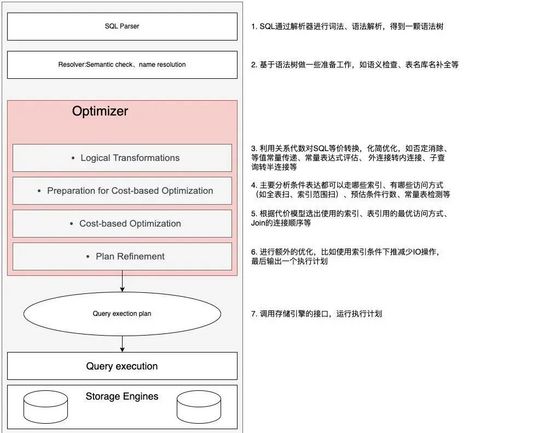
SQL执行与优化器
2、代价模型介绍
而对于优化器来说,执行一条SQL有各种各样的方案可供选择,如表是否用索引、选择哪个索引、是否使用范围扫描、多表Join的连接顺序和子查询的执行方式等。如何从这些可选方案中选出耗时最短的方案呢?这就需要定义一个量化数值指标,这个指标就是代价(Cost),我们分别计算出可选方案的操作耗时,从中选出最小值。
代价模型将操作分为Server层和Engine(存储引擎)层两类,Server层主要是CPU代价,Engine层主要是IO代价,比如MySQL从磁盘读取一个数据页的代价io_block_read_cost为1,计算符合条件的行代价为row_evaluate_cost为0.2。除此之外还有:
- memory_temptable_create_cost (default 2.0) 内存临时表的创建代价。
- memory_temptable_row_cost (default 0.2) 内存临时表的行代价。
- key_compare_cost (default 0.1) 键比较的代价,例如排序。
- disk_temptable_create_cost (default 40.0) 内部myisam或innodb临时表的创建代价。
- disk_temptable_row_cost (default 1.0) 内部myisam或innodb临时表的行代价。
在MySQL 5.7中,这些操作代价的默认值都可以进行配置。为了计算出方案的总代价,还需要参考一些统计数据,如表数据量大小、元数据和索引信息等。MySQL的代价优化器模型整体如下图所示:
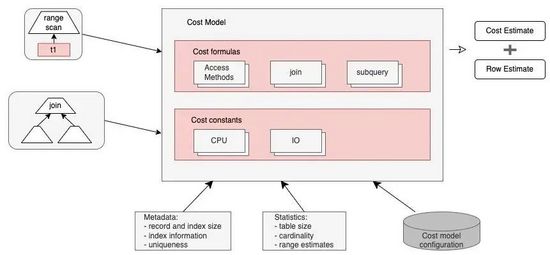
代价模型
3、基于代价的索引选择
还是继续拿上述的 SQL select * from sync_test1 where name like 'Bobby%' and dt > '2021-07-06' 为例,我们看看MySQL优化器是如何根据代价模型选择索引的。首先,我们直接在建表时加入四个候选索引。
复制
Create Table: CREATE TABLE `sync_test1` (`id` int(11) NOT NULL AUTO_INCREMENT,`cid` int(11) NOT NULL,`phone` int(11) NOT NULL,`name` varchar(10) NOT NULL,`address` varchar(255) DEFAULT NULL,`dt` datetime DEFAULT NULL,PRIMARY KEY (`id`),KEY `IX_name` (`name`),KEY `IX_dt` (`dt`),KEY `IX_dt_name` (`dt`,`name`),KEY `IX_name_dt` (`name`,`dt`)) ENGINE=InnoDB通过执行explain看出MySQL最终选择了IX_name索引。
复制
mysql> explain select * from sync_test1 where name like 'Bobby%' and dt > '2021-07-06';
+----+-------------+------------+------------+-------+-------------------------------------+---------+---------+------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-------------------------------------+---------+---------+------+------+----------+------------------------------------+
| 1 | SIMPLE | sync_test1 | NULL | range | IX_name,IX_dt,IX_dt_name,IX_name_dt | IX_name | 12 | NULL | 572 | 36.83 | Using index condit这篇关于每日慢查询上亿,快看美团的SQL急救大法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





