本文主要是介绍python爬取csdn的文章内容,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天写了一个爬取csdn文章的
初学不太会,下面代码有时间可以自行优化
新建python文件,把我的代码复制进去保存
把依赖python install 一下
import re
import urllib.error
import urllib.request
import os
import tkinter as tk
from bs4 import BeautifulSoupdef main():baseurl = entry_url.get()# baseurl = "https://blog.csdn.net/qq_57420582/article/details/133796601?spm=1001.2014.3001.5502"getDate(baseurl)# print(''.join(datelist))win.destroy()def getDate(baseurl):html = askURL(baseurl)soup = BeautifulSoup(html,"html.parser")datelist = []pattern = r'src="(.*?)"'htmlname = soup.find('h1', class_="title-article")htmlname = str(htmlname).replace("<p>", "").replace("</h1>", "")datelist.append(htmlname[48:] + "\n")htmledit = soup.find('div',class_="htmledit_views")for item in htmledit:item = str(item).replace("<p>","").replace("</p>","\n").replace("<br/>","\n").replace("<h2>","").replace("</h2>","\n").replace("<blockquote>","").replace("<!-- -->","").replace("</blockquote>","\n")# datelist.append(item)match = re.search(pattern, item)if match:url = match.group(1)datelist.append(url+"\n")else:datelist.append(item)desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") # 找到用户桌面的路径savepath = os.path.join(desktop_path, "csdn爬取文件") # 文件夹名称saveDate(''.join(datelist),savepath,htmlname[48:])return datelistdef askURL(url):head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36"}request=urllib.request.Request(url,headers=head)html=""try:response=urllib.request.urlopen(request)html=response.read().decode("utf-8")# print(html)except urllib.error.URLError as e:if hasattr(e,"code"):print(e.code)if hasattr(e,"reason"):print(e.reason)return htmldef saveDate(datalist,savepath,savename):if not os.path.isdir(savepath): # 判断是否存在该文件夹,若不存在则创建os.mkdir(savepath) # 创建with open(savepath + "\\" + savename +".txt", 'w', encoding='utf-8') as file: # 打开这个文件file.write(datalist) # 打印文字def frame_center(window, width, height):screen_width = window.winfo_screenwidth()screen_height = window.winfo_screenheight()x = (screen_width - width) // 2y = (screen_height - height) // 2window.geometry(f"{width}x{height}+{x}+{y}")if __name__ == '__main__':win = tk.Tk()win.title('csdn爬取器') # 窗口名字frame_center(win, 400, 200) # 窗口大小win.resizable(False, False)label = tk.Label(win, text='请输入网址:') # 窗口内文字label.pack(pady=10) # 窗口内容间距label1 = tk.Label(win, text='(爬取需要一些时间哦!)')label1.pack(pady=0)entry_url = tk.Entry(win, width=30) # 窗口内输入框entry_url.pack(pady=5)btn_record = tk.Button(win, text='开爬!', command=main) # 窗口内按钮btn_record.pack(pady=40)print("爬取完毕")win.mainloop()
然后下载Axialis IconWorkshop
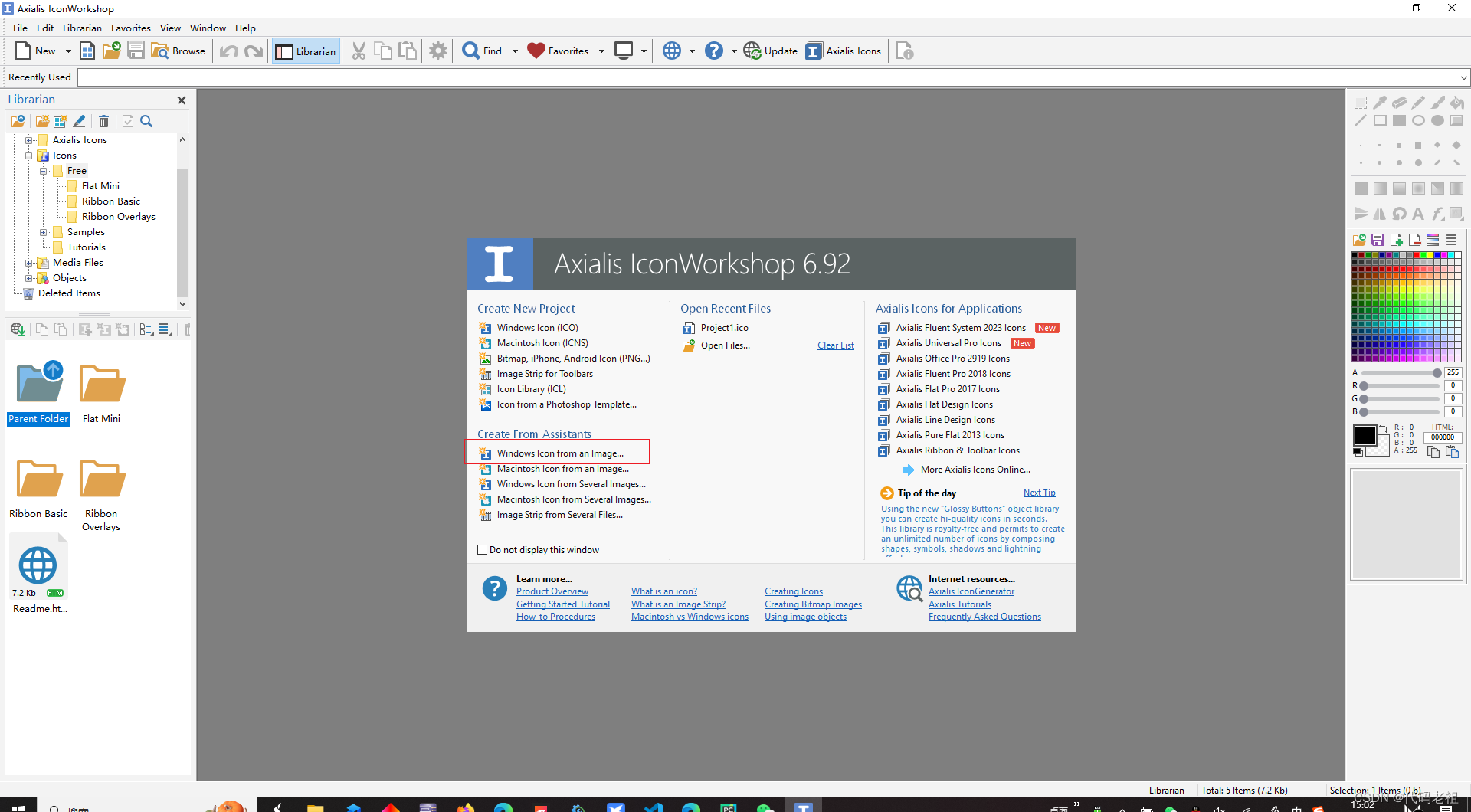
这是从本地选取一个图片
确定
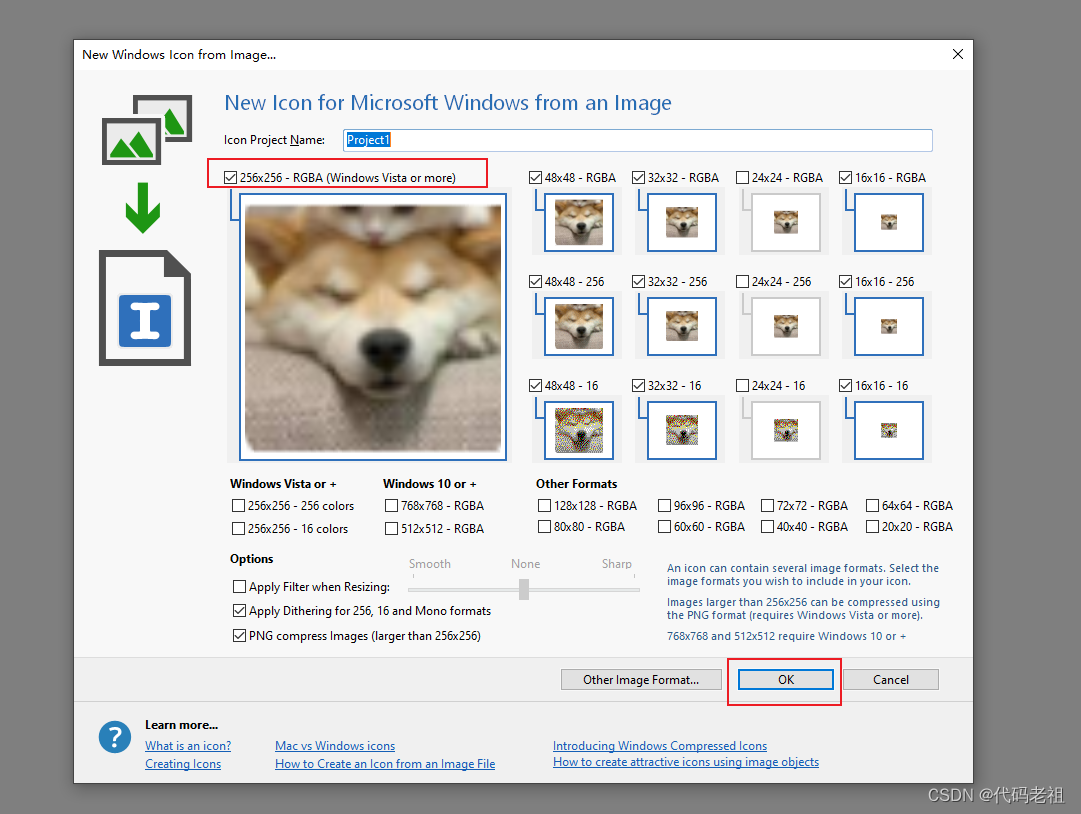
保存
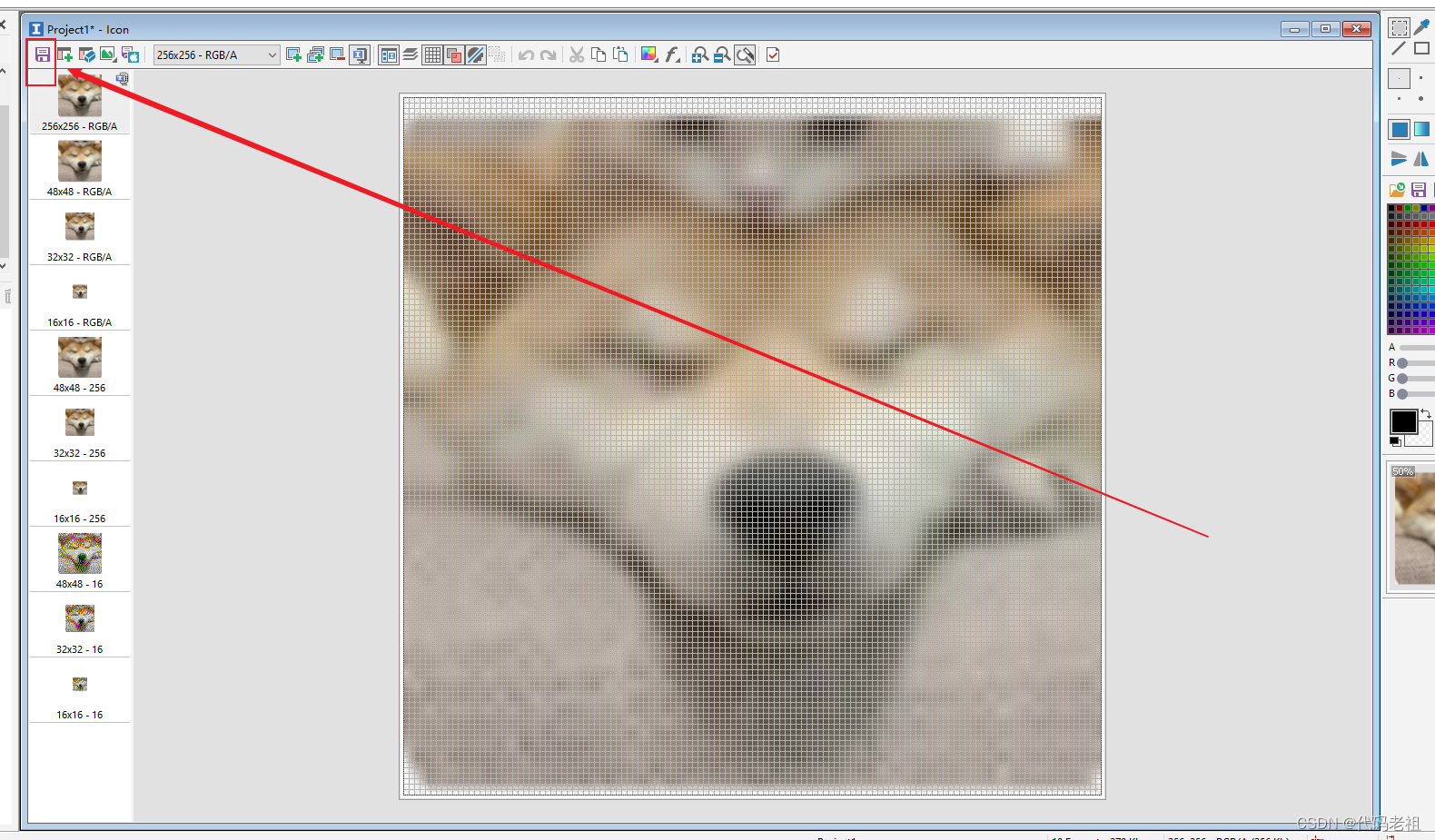
然后我们就有了一个图标文件
新建文件夹,把图片和python文件放进去

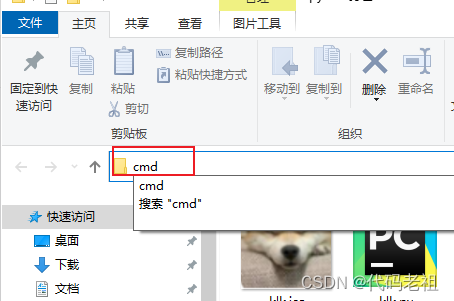
在上面输入cmd回车,打开命令行窗口
pip install Pyinstaller
Pyinstaller -F -w -i klk.ico klk.py

然后我们就获得了,exe文件就在dist文件夹里面
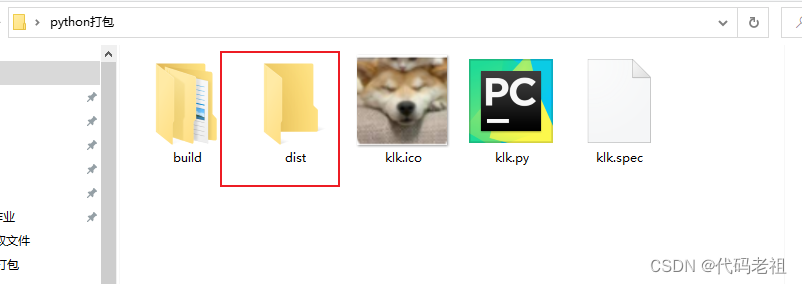
我们运行exe程序
弹出这个窗口

在csdn选择一篇文章,复制url粘贴到这里
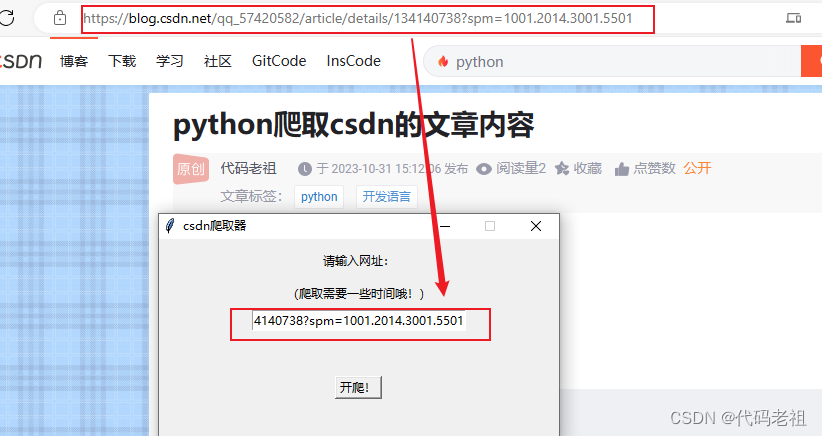
点击 开爬
可以在电脑桌面看到生成了一个csdn爬取文件
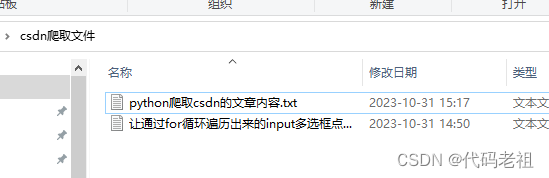
这里面就是爬到的内容了
这篇关于python爬取csdn的文章内容的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




