本文主要是介绍4.10论文阅读 ICLR2023,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Adversarial Training of self-supervised Monocular Depth Estimation Against Physical-World Attacks
摘要
作者首先表明了针对MDE的对抗攻击,尤其是物理世界的真实攻击对深度估计系统是个巨大的威胁。传统的对抗训练需要真实标注,这并不适用于自监督深度估计。一些强化自监督模型的技术,例如对比学习,忽略了MDE本身的域内知识从而很难达到良好的性能。本文作者提出了一种基于视角合成的针对自监督单目深度估计对抗训练方法。作者在训练中使用 L 0 L_0 L0约束提升了针对物理攻击的鲁棒性,且作者对比了自身方法与有监督学习,和对比学习,在两个有代表性的网络上,作者的方法取得了良性结果几乎没有退化的结果,也证明了其方法具有更好的鲁棒性。
1.引言
首先还是阐明MDE的重要性,它在autonomous driving, visual
SLAM, visual re-localization等领域有着广泛的应用。其中自监督MDE又迅速发展[^1]。近年来探索MDE鲁棒性的工作,像素层面,物理世界层面都出现了很多,所以现在防御这些攻击十分紧迫。
现在的对抗训练需要深度标注,这是个缺陷;对比学习无法关注到MDE的域内知识,也有缺陷;还有些方法没有没有考虑真实世界的攻击,所以有了本文。
一个使MDE算法鲁棒的直接办法是干扰3D实物,确保它仍然能正确估计深度,但是这种对抗训练比较难实现。首先现实世界中很难干扰3D实物,另外,因为没有深度标注,就算实现了这种方法,模型也不一定能收敛到正确的深度估计。
传统的对抗训练假设添加的 L 2 L_2 L2或 L ∞ L_\infty L∞扰动是有约束的,然而真实攻击不会有这种约束。对于对抗样本,作者选择了使用 L 0 L_0 L0范式作为损失函数生成的对抗样本,他的说法是这种损失函数可以很好地模拟物理世界的攻击。本文贡献如下:
- 作者提出了 一种合成2D图像,并在其中加入噪声来进行对抗训练的方法,减少了物理世界对抗的开销。
- 利用了重建误差去做深度监督,来进行对抗训练。
- 使用可微的 L 0 L_0 L0范式来生成对抗样本,并通过随机化相机和物体来模拟真实的物理攻击,并提升鲁棒性。
- 实验表明作者方法具有更好的鲁棒性,模型性能几乎没有退化,1/10的区域干扰,原来的深度误差从6.08米经过本文的对抗训练后降为0.25米,优于有监督的1.18米。
2.相关工作
略
3.方法
3.1视角合成来避免物理世界的突变(mutation)
概念上本文把一个打印有3D物体的板子放在街上,并通过双目相机去拍照。 作者提到板子的宽高和真实的物体是相同的,这一点十分重要。然后作者构建了一个带有参数的映射,来将板子放入图片中。这些参数包括板子的长H宽W,角度 α \alpha α,和深度z。通过修改这些参数来获得大量的图像数据,避免了现实世界中的大量开销。该带有参数的映射通过下列公式构建:
作者提到板子的宽高和真实的物体是相同的,这一点十分重要。然后作者构建了一个带有参数的映射,来将板子放入图片中。这些参数包括板子的长H宽W,角度 α \alpha α,和深度z。通过修改这些参数来获得大量的图像数据,避免了现实世界中的大量开销。该带有参数的映射通过下列公式构建:



3.2鲁棒的对抗扰动
这一节是将如何添加扰动的。作者认为,要实现物理世界的对抗攻击,应该使用 L 0 L_0 L0约束,也就是约束添加扰动的像素数目,而并不约束每个像素添加扰动的强度。因为现实世界中的攻击,由于光照角度等等物理因素的变化往往需要很强的扰动来确保攻击成功率,所以也就不约束扰动强度了。但是偏偏 L 0 L_0 L0是不可导的,后来作者使用了Tao等人提出的软性 L 0 L_0 L0约束。

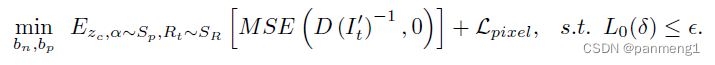
这里主要是用了tanh的长尾效应讲 L 0 L_0 L0可微化了,但是这个 L p i x e l L_{pixel} Lpixel正则化项 没看太懂。
3.3对抗训练
这节讲对抗训练了,主要是用的重映射投影,添加噪声的图像重映射回目标图像时会有扭曲,用的就是这一点。
4实验
作者做了非常详尽的实验,在两个基础模型,monodepth2和depthhints上做了黑白盒和物理世界的攻击实验。论文题目是against physical world,但是实际上作者的对抗训练仍然是针对像素层面的攻击进行的,之所以像素层面的对抗训练可以鲁棒物理世界中的攻击,作者的解释是,物理世界的攻击因为光照等因素会降低攻击的有效性,所以还是数字层面的攻击最有效,所以能防御数字层面的攻击,就能防御物理世界的攻击。
5个人总结
物理世界的攻击还是有热度,像素攻击没什么意思,本文通过像素攻击去模拟物理攻击,这个思路可以用,能像作者那样解释通就行,并且物理世界实验要有,但是能防御像素攻击就能防御物理攻击,这个观点存疑。
[^1]作者提到了一篇Tesla Autopilot,后续看一下,Andrej Karpathy. Tesla use per-pixel depth estimation with self-supervised learning, 2020. https://youtu.be/hx7BXih7zx8?t=1334.由此看来特斯拉还是坚定不移地走摄像头技术路线。
这篇关于4.10论文阅读 ICLR2023的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
