本文主要是介绍Hikari源码分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
总结
连接池关系
1、HikariDataSource构建函数->生成HikariPool对象->调用HikariPool的getConection得到连接
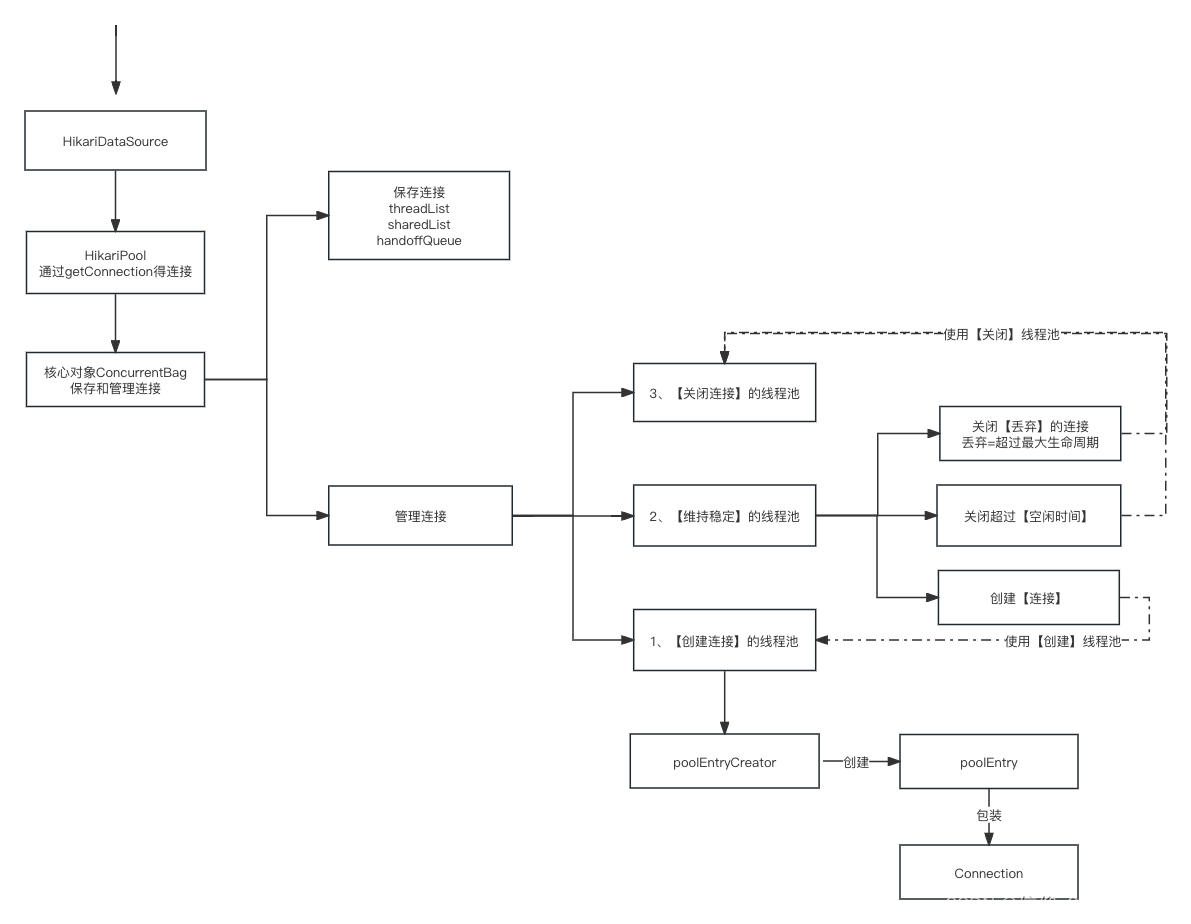
2、HikariPool包含ConcurrentBag
3、ConcurrentBag保存连接:三个集合threadList、sharedList、handoffQueue
4、ConcurrentBag管理连接:创建连接的线程池,探活的线程池,关闭连接的线程池、阻塞队列
5、探活的线程池:调用关闭连接的线程池,调用创建链接的线程池。
6、连接Connection被包装成了poolEntry,通过poolEntryCreator->得到poolEntry->添加到shareList里面去。
7、释放链接:判断是否人等待获取链接的请求,如果有塞到handoffQueue,如果没有添加到自己线程的threadList里面去。
数据库连接池主要分为两大内容
1、连接的获取,主要涉及三个容器: threadList、sharedList、handoffQueue
2、连接池的管理:主要包含连接的创建,连接的定期检测,是否有效是否空闲,连接的关闭
源码分析
HikariDataSource常用的参数配置
connectionTimeou:客户端创建连接等待超时时间,如果30秒内没有获取连接则抛异常,不再继续等待
idleTimeout:连接允许最长空闲时间,如果连接空闲时间超过1分钟,则会被关闭
maxLifetime:连接最长生命周期,当连接存活时间达到30分钟之后会被关闭作退休处理
minimumIdle:连接池中最小空闲连接数
maximumPoolSize:连接池中最大连接数
validationTimeout:测试连接是否空闲的间隔
leadDetectionThreshold:连接被占用的超时时间,超过1分钟客户端没有释放连接则强制回收该连接,防止连接泄漏
1、HikariPool
Hikari中的核心类为HikariDataSource,表示Hikari连接池中的数据源,实现了DataSource接口的getConnection方法,获取链接主要是为了拿到Connection,而拿到Connection就是要通过HikariPool的实例对象来获取。
所以在HikariDataSource的构造函数里面会创建HikariPool对象。为了在调用getConnection方法时,从HikariPool里面拿到Connection
private final HikariPool fastPathPool;
private volatile HikariPool pool;public HikariDataSource(HikariConfig configuration){pool = fastPathPool = new HikariPool(this);
}/** 获取连接*/
public Connection getConnection() throws SQLException{if (fastPathPool != null) {return fastPathPool.getConnection();}pool = result = new HikariPool(this);/** 调用pool的getConnection()方法获取连接*/return result.getConnection();
}
小结:HikariDataSource->生成HikariPool对象->HikariPool对象得到Connection。
重点看HikariPool的getConnection()方法逻辑时如何得到connection
/** 获取连接*/
public Connection getConnection(final long hardTimeout) throws SQLException{/** 获取锁*/suspendResumeLock.acquire();try {do {/** 1、从ConcurrentBag中借出一个PoolEntry对象 */PoolEntry poolEntry = connectionBag.borrow(timeout, MILLISECONDS);if (poolEntry == null) {break;}/** 判断连接是否被标记为抛弃 或者 空闲时间过长, 是的话就关闭连接*/if (......) {closeConnection(poolEntry, poolEntry.isMarkedEvicted() ? EVICTED_CONNECTION_MESSAGE : DEAD_CONNECTION_MESSAGE);}/** 2、拿到poolEntry,通过Javassist创建代理连接*/return poolEntry.createProxyConnection(leakTaskFactory.schedule(poolEntry), now);} while (timeout > 0L);throw createTimeoutException(startTime);} finally {/** 释放锁*/suspendResumeLock.release();}
}
核心步骤只有两步,一个是调用ConcurrentBag的borrow方法借用一个PoolEntry对象,第二步调用调用PoolEntry的createProxyConnection方法动态生成代理connection对象。
这里涉及到了两个核心的类,分别是ConcurrentBag和PoolEntry
2、ConcurrentBag
1、PoolEntry :PoolEntry顾名思义是连接池的节点,里面有个connection属性,实际也可以看作是一个Connection对象的封装,连接池中存储的连接就是以PoolEntry的方式进行存储。
2、ConcurrentBag:ConcurrentBag本质就是连接池的主体,存储对象PoolEntry(PoolEntry主要是封装了connection),另外做了并发控制来解决连接池的并发问题。里面有锁对象,缓存PoolEntry集合,sharedList、threadList等。
/** 借出一个对象 */
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException {/** 1.从ThreadLocal中获取当前线程绑定的对象集合 */final List<Object> list = threadList.get();/** 1.1.如果当前线程变量中存在就直接从list中返回一个*/for (int i = list.size() - 1; i >= 0; i--) {......如果bagEntry不为空。尝试将bagEntry的状态从未被使用更新成已使用。成功返回PoolEntryif (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {return bagEntry;}}/** 2.遍历当前缓存的sharedList, 如果当前状态为未使用,则通过CAS修改为已使用*/for (T bagEntry : sharedList) {if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {return bagEntry;}}do {/** 3.从阻塞队列中等待超时获取元素,如果获取元素失败或者获取元素且使用成功则均返回 */final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {return bagEntry;}} while (timeout > 10_000);//如果超时没有拿到PoolEntry,在再拿,应该有个最大超市次数。return null;
}
1、从ThreadLocal中获取或者说从threadList里面获取。注意一般存在ThreadLocal的数据都是弱引用类型。
ThreadLocal里面的PoolEntry什么时候存进去的?没有人使用时那么将连接存入ThreadLocal中,每个ThreadLocal最多会存储50个连接
2、从sharedList中获取:ThreadLocal中获取连接失败之后,会再次尝试从sharedList中获取
sharedList的PoolEntry是什么时候存进去的?
在ConcurrentBag初始化的,会初始化指定数量的PoolEntry对象存入sharedList
3、handoffQueue从阻塞队列获取
什么时候会有连接往里面塞?
其实在创建ConcurrentBag的对象的时候,他的构造函数,已经对这三个集合对象初始化,但是并没有塞数据进去。
public ConcurrentBag(...){//1、threadListif (是否为弱引用) {this.threadList = ThreadLocal.withInitial(() -> new ArrayList<>(16));} else {this.threadList = ThreadLocal.withInitial(() -> new FastList<>(IConcurrentBagEntry.class, 16));}//2、初始化sharedListthis.sharedList = new CopyOnWriteArrayList<>();//3、初始化阻塞队列handoffQueuethis.handoffQueue = new SynchronousQueue<>(true);
}
小结:borrow方法从下面三个对象中获取
1、threadList
2、sharedList
3、handoffQueue 指定超时时间,没有拿到结束请求。
3、管理【连接池】
HikariPool内部属性包含了ConcurrentBag对象,在HikariPool初始化时会创建ConcurrentBag对象,所以ConcurrentBag的构造函数是在HikariPool初始化时调用,HikariPool构造函数如下:
public HikariPool(final HikariConfig config) {//1、初始化ConcurrentBag对象this.connectionBag = new ConcurrentBag<>(this);/** 2、【创建连接】的线程池*/this.addConnectionExecutor = createThreadPoolExecutor(addQueue, poolName + " connection adder", threadFactory, new ThreadPoolExecutor.DiscardPolicy());/** 3、【探活】的线程池,通过定时检测,保持固定数量的"有效连接", 怎么的Connection属于有效? */this.houseKeepingExecutorService = initializeHouseKeepingExecutorService();this.leakTaskFactory = new ProxyLeakTaskFactory(config.getLeakDetectionThreshold(), houseKeepingExecutorService);/**【保持连接池连接数量】的任务,通过【探活】线程池来执行的,执行任务【HouseKeeper】,houseKeeperTask只是执行的返回结果,重点在于提交的任务类【HouseKeeper】 */this.houseKeeperTask = houseKeepingExecutorService.scheduleWithFixedDelay(new HouseKeeper(), 100L, housekeepingPeriodMs, MILLISECONDS);/** 4、【关闭连接】的线程池 */this.closeConnectionExecutor = createThreadPoolExecutor(config.getMaximumPoolSize(), "xx", threadFactory, new ThreadPoolExecutor.CallerRunsPolicy());/** 5、【阻塞队列】根据配置的最大连接数, 当连接数不够时,需要获取链接的线程就在这里等待 */LinkedBlockingQueue<Runnable> addQueue = new LinkedBlockingQueue<>(config.getMaximumPoolSize());this.addConnectionQueue = unmodifiableCollection(addQueue);
}
这里有一个定时任务houseKeeperTask,该定时任务的作用是定时检测【连接池中的连接】,保持连接池中的【连接数】稳定在一个固定的值,执行的内容就是HouseKeep的run方法
private final class HouseKeeper implements Runnable {@Overridepublic void run(){/** 关闭连接池中需要【被丢弃】的连接,每个链接有个【最大生命周期】,超过这个周期都视为被丢弃的连接 */if (plusMillis(now, 128) < plusMillis(previous, housekeepingPeriodMs)) {softEvictConnections();return;}/** 获取当前连接池中【不是使用中】的连接集合 */ final List<PoolEntry> notInUse = connectionBag.values(STATE_NOT_IN_USE);int toRemove = notInUse.size() - config.getMinimumIdle();for (PoolEntry entry : notInUse) {/** 当前空闲的连接如果超过【最大空闲时间idleTimeout】则关闭空闲连接 */if (toRemove > 0 && elapsedMillis(entry.lastAccessed, now) > idleTimeout && connectionBag.reserve(entry)) {closeConnection(entry, "(connection has passed idleTimeout)");toRemove--;}}/** 填充连接池,保持连接池数量至少保持【minimum个连接】数量 */fillPool(); // Try to maintain minimum connections}
}
最大生命周期和空闲时间是2个概念。
该定时任务主要是为了维护连接池中连接的数量,首先需要将被标记为需要丢弃的连接进行关闭,然后将空闲超时的连接进行关闭,最后当连接池中的连接少于最小值时就需要对连接池进行补充连接的操作。所以在初始化连接池时,初始化连接的操作就是在fillPool方法中实现的。fillPool方法源码如下:
/** 填充连接池 */
private synchronized void fillPool() {//计算需要添加的连接数量final int connectionsToAdd = Math.min(config.getMaximumPoolSize() - getTotalConnections(), config.getMinimumIdle() - getIdleConnections())- addConnectionQueue.size();for (int i = 0; i < connectionsToAdd; i++) {/** 向【创建连接】的线程池,提交创建连接的任务 */addConnectionExecutor.submit(poolEntryCreator);}
}
先计算需要创建的连接数量,向创建连接的线程池中提交任务 poolEntryCreator,PoolEntryCreator创建PoolEntry对象的逻辑如下:
/** 创建PoolEntry对象线程 */
private final class PoolEntryCreator implements Callable<Boolean> {@Overridepublic Boolean call() {/** 1.当前连接池状态正常并且需求创建连接时 */while (poolState == POOL_NORMAL && shouldCreateAnotherConnection()) {/** 2.创建PoolEntry对象 */final PoolEntry poolEntry = createPoolEntry();if (poolEntry != null) {/** 3.将PoolEntry对象添加到ConcurrentBag对象中的sharedList中 */connectionBag.add(poolEntry);return Boolean.TRUE;}/** 如果创建失败,睡眠指定时间,回到循环在尝试创建 */quietlySleep(sleepBackoff);}return Boolean.FALSE;}
}
createPoolEntry方法逻辑如下:
/** 创建PoolEntry对象 */
private PoolEntry createPoolEntry() {/** 1.初始化PoolEntry对象,newPoolEntry里面会先创建Connection对象,PoolEntry再把Connection封装一下返回 */final PoolEntry poolEntry = newPoolEntry();/** 获取连接最大生命周期时长 */final long maxLifetime = config.getMaxLifetime();if (maxLifetime > 0) {/** 2.给PoolEntry添加定时任务,当PoolEntry对象达到最大生命周期时间后触发定时任务将连接标记为被抛弃 */poolEntry.setFutureEol(houseKeepingExecutorService.schedule(() -> {/** 判断刚创建的连接poolEntry,是否达到最大生命周期,如果满足则抛弃连接 */if (softEvictConnection(poolEntry, "xx", false)) {/** 丢弃一个连接之后,调用addBagItem补充新的PoolEntry对象 */addBagItem(connectionBag.getWaitingThreadCount());}}, lifetime, MILLISECONDS));}return poolEntry;
}PoolEntry newPoolEntry() throws Exception{return new PoolEntry(newConnection(), this, isReadOnly, isAutoCommit);
}
首先创建一个新的PoolEntry对象,PoolEntry构造时会创建Connection对象,另外如果连接设置了最大生命周期时长,那么需要给每个PoolEntry添加定时任务,为了防止多个PoolEntry同时创建同时被关闭,所以每个PoolEntry的最大生命周期时间都不一样。当PoolEntry达到最大生命周期后会触发softEvictConnection方法,将PoolEntry标记为需要被丢弃,另外由于抛弃了PoolEntry对象,所以需要重新调用addBagItem方法对PoolEntry对象进行补充。
上面会调用addBagItem方法,我们看下addBagItem的做了什么?
public void addBagItem(final int waiting) {/** 判断是否需要创建连接 */final boolean shouldAdd = waiting - addConnectionQueue.size() >= 0; // Yes, >= is intentional.if (shouldAdd) {/** 向创建连接线程池中提交创建连接的任务 */addConnectionExecutor.submit(poolEntryCreator);}
}
总结:
从ConcurrentBag中获取连接一共分成三步,首先从当前线程的ThreadLocal中获取,如果有直接返回一个连接,如果ThreadLocal中没有则从sharedList中获取,sharedList可以理解为ConcurrentBag缓存的连接池,每当创建了一个PoolEntry对象之后都会添加到sharedList中去,如果sharedList中的连接状态都不是可用状态,此时就需要通过IBagStateListener提交一个创建连接的任务,交给创建连接的线程池去执行,创建新的连接。
新的连接创建成功之后会将PoolEntry对象添加到无容量的阻塞队列handoffQueue中,当请求线程进来,如果ThreadLocal和sharedList都没有拿到,就不断尝试从handoffQueue队列中获取连接直到成功获取或者超时返回。
HikariPool包含->ConcurrentBag->包含threadList、sharedList、handoffQueue
释放连接
当客户端释放连接时会调用collection的close方法,Hikari中的Connection使用的是代理连接ProxyConnection对象,调用close方法时会调用关联的PoolEntry对象的回收方法recycle方法,PoolEntry的recycle方法源码如下,主要还是通过hikariPool拿到connectionBag,嗲用connectionBag的requite方法。
void recycle(final long lastAccessed) {if (connection != null) {hikariPool.recycle(this);}
}
/** 调用HikariPool的recycle方法,回收当前PoolEntry对象 */
void recycle(final PoolEntry poolEntry) {/** 调用ConcurrentBag的回收方法 */connectionBag.requite(poolEntry);
}/** 回收元素方法 */
public void requite(final T bagEntry) {/** 1.设置状态为未使用 */bagEntry.setState(STATE_NOT_IN_USE);/** 2.如果当前存在等待线程,则优先将元素给等待线程 */for (int i = 0; waiters.get() > 0; i++) {/** 2.1.将元素添加到无界阻塞队列中,等待其他线程获取 */if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {return;} else {/** 当前线程不再继续执行,让出CPU执行权 */yield();}}/** 3.如果当前连接没有被其他线程使用,则添加到当前线程的ThreadLocal中,当这个线程再次执行DB操作时,会优先从ThreadLocal里面拿 */final List<Object> threadLocalList = threadList.get();if (threadLocalList.size() < 50) {threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);}
}
回收连接最终会调用ConcurrentBag的requite方法,方法逻辑不复杂,首先将PoolEntry元素状态设置为未使用,然后判断当前是否存在等待连接的线程,如果存在则将连接加入到无界阻塞队列中去,由等待连接的线程从阻塞队列中去获取;
如果当前没有等待连接的线程,则将连接添加到本地线程变量ThreadLocal中,等待当前线程下次获取连接时直接从ThreadLocal中获取。
源码分析:跳转
这篇关于Hikari源码分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







