本文主要是介绍机器学习入门实例-加州房价预测-2(数据整理),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
计算相关性
使用corr()计算standard correlation coefficient(Pearson’s r)。矩阵不是很方便观察,可以直接排序median_house_value列,可以看出median_house_value与median_income的相关性挺大的。
corr_matrix = visual_data.corr()print(corr_matrix)# 这句是直接排序了,降序print(corr_matrix["median_house_value"].sort_values(ascending=False))[9 rows x 9 columns]
median_house_value 1.000000
median_income 0.687151
total_rooms 0.135140
housing_median_age 0.114146
households 0.064590
total_bedrooms 0.047781
population -0.026882
longitude -0.047466
latitude -0.142673
Name: median_house_value, dtype: float64绘图也可以看到这种相关性:
from pandas.plotting import scatter_matrix# 因为其它属性的相关性值比较小,同时因为空间有限,所以只选4个绘制图像attributes = ["median_house_value", "median_income", "total_rooms","housing_median_age"]scatter_matrix(visual_data[attributes], figsize=(12, 8))plt.show()
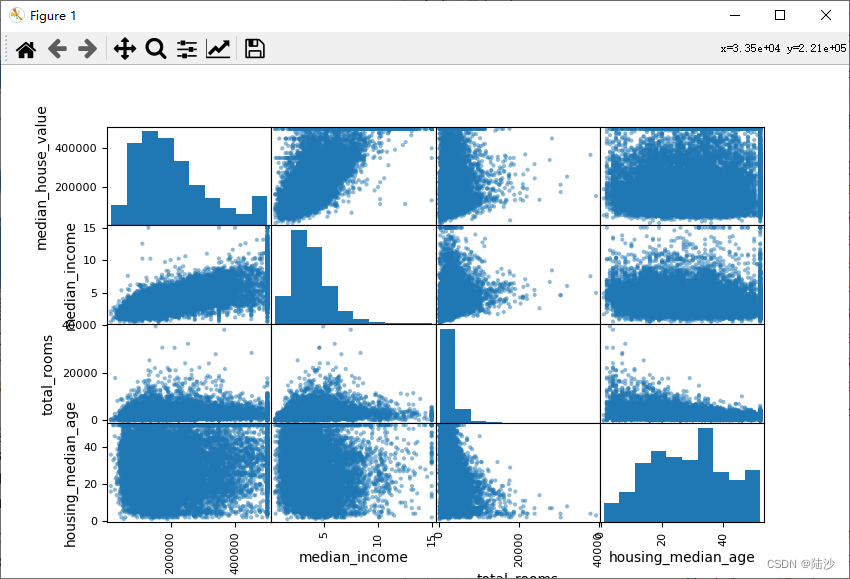
因为total_rooms相关性不太显著,考虑引入几个新特性:
visual_data["rooms_per_household"] = visual_data["total_rooms"] / visual_data["households"]visual_data["bedrooms_per_room"] = visual_data["total_bedrooms"] / visual_data["total_rooms"]visual_data["population_per_household"] = visual_data["population"] / visual_data["households"]corr_matrix = visual_data.corr()print(corr_matrix["median_house_value"].sort_values(ascending=False))median_house_value 1.000000
median_income 0.687151
rooms_per_household 0.146255
total_rooms 0.135140
housing_median_age 0.114146
households 0.064590
total_bedrooms 0.047781
population_per_household -0.021991
population -0.026882
longitude -0.047466
latitude -0.142673
bedrooms_per_room -0.259952
Name: median_house_value, dtype: float64可以看到rooms_per_household比total_rooms和households的相关性都要高一点,bedrooms_per_room也是,但是population_per_household反而变差了,大概是不适合这种特征组合方式。
数据整理
取得数据和标签
housing = train_set.drop("median_house_value", axis=1)
housing_labels = train_set["median_house_value"].copy()
处理有空缺值的列
三种常见方法:
# 第一种,去掉有空缺值的行
housing.dropna(subset=["total_bedrooms"])# 第二种,去掉有空缺值的列
housing.drop("total_bedrooms", axis=1)# 第三种,使用某种方法获得一个值,填入空缺位置。这里使用中位数
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median, inplace=True)
使用scikit learn的方法:
from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy="median")# median不能计算非数据列,ocean_p是字符串housing_num = housing.drop("ocean_proximity", axis=1)imputer.fit(housing_num)# 此时imputer会计算每一列的中位数。因为实时运行时可能不止total_bedrooms列有空缺,所以最好直接全部计算# imputer.statistics_中存放了各列的中位数,与housing_num.median().values是完全一致的# print(imputer.statistics_)# print(housing_num.median().values)X = imputer.transform(housing_num)housing_tr = pd.DataFrame(X, columns=housing_num.columns, index=housing_num.index)Imputer的说明
- Estimators
基于某个数据集估算参数的对象称为estimator,使用时用fit()函数进行估算,它本身的参数称为hyperparameter。比如SimpleImputer就是estimator,strategy就是它的hyperparameter。 - Transformers
某些estimator可以修改数据集,所以也叫transformer,使用时用transform()进行修改。比如SimpleImputer就是。Transformer有一个函数fit_transform(),等于先fit()再transform(),有时候比俩函数写在一起更快。 - Predictiors
某些estimator可以进行预测,使用predict()进行预测,使用score()计算预测质量。 - 规定
所有estimator的超参数都是公共属性,比如imputer.strategy,所有估算完的参数也是公共属性,以下划线结尾,比如imputer.statistics_
处理字符串类型列
ocean_proximity这列只包含几个有限字符串值,为了进行处理,需要把字符串转换为数字,比如0,1,2…
housing_cat = housing[["ocean_proximity"]]from sklearn.preprocessing import OrdinalEncoderordinal_encoder = OrdinalEncoder()housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)print(ordinal_encoder.categories_)[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],dtype=object)]
one-hot encoding:其实就是二进制表示。比如INLAND就是01000,ISLAND是00100,这样把原本1列变成5列,新属性也被称为dummy attributes。scikit learn也提供了这种方法:
from sklearn.preprocessing import OneHotEncodercat_encoder = OneHotEncoder()housing_cat_1hot = cat_encoder.fit_transform(housing_cat)print(housing_cat_1hot)# (0, 1) 1.0# (1, 4) 1.0# ... 该类型是稀疏矩阵,因为里面大部分是0,所以只存储了1的位置。(row, col)# toarray()可以转为二维数组print(housing_cat_1hot.toarray())
但如果这列有非常多种标签,one-hot方式就会引入大量数据。此时应该改为数字型编号,或者干脆改成数字型的列,比如ocean_proximity就可以改成与海洋之间的距离。
自定义Estimator
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6class CombinedAttributesAdder(BaseEstimator, TransformerMixin):def __init__(self, add_bedrooms_per_room=True):self.add_bedrooms_per_room = add_bedrooms_per_roomdef fit(self, X, y=None):return selfdef transform(self, X):return selfdef fit_transform(self, X, y=None):rooms_per_household = X[:, rooms_ix] / X[:, households_ix]population_per_household = X[:, population_ix] / X[:, households_ix]if self.add_bedrooms_per_room:bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]return np.c_[X, rooms_per_household, population_per_household, bedrooms_per_room]else:return np.c_[X, rooms_per_household, population_per_household]
...
#使用:
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attrs = attr_adder.fit_transform(housing.values)
注意
- fit和transform虽然没有实现,但也要写,不然后面组装成pipeline运行时会报错:
TypeError: All intermediate steps should be transformers and implement fit and transform or be the string ‘passthrough’ ‘CombinedAttributesAdder()’ - fit_transform要写y参数,不然pipeline中也会报错:
TypeError: fit_transform() takes 2 positional arguments but 3 were given
当然,如果不组装pipeline,只是单独调用的话,这两点可以忽略掉。
特征缩放
Feature Scaling:如果两列的数据范围差距很大(比如total_rooms在6~39320之间,但income_median只在0 ~ 15之间),机器学习算法的表现可能受影响。
- min-max scaling:也叫normalization,指将数据压缩到0-1之间,原理是减去最小值,再除以最大值与最小值的差。scikit learn提供了一个transformer叫MinMaxScaler,其超参数feature_range可以指定非0-1的范围。
- standardization:原理是减去均值,然后除以标准差。scikit learn提供一个transformer叫StandardScaler
组装pipeline
如果很多列需要相似的处理流程,那可以组装成一个pipeline,然后把数据整个扔进去。
from sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScaler# 每个元组的格式为:(name, estimator object),最后一个必须是transformer,即要有fit_transform()# name要求唯一且不能包含双下划线__。要求有名称是为了后期可以调整超参数num_pipeline = Pipeline([('imputer', SimpleImputer(strategy='median')),('attribs_adder', CombinedAttributesAdder()),('std_scaler', StandardScaler()),])housing_num_tr = num_pipeline.fit_transform(housing_num)#print(housing_num_tr)
其中housing_num = housing.drop(“ocean_proximity”, axis=1),就是纯数据列。
更高级的pipeline则可以包含Pipeline对象和estimator。
from sklearn.compose import ColumnTransformer# 这实际是列名listnum_attribs = list(housing_num)cat_attribs = ["ocean_proximity"]drop_attribs = ["longitude"]# 每行指定name、pipeline或者estimator对象和列名# 也可以使用drop或passthrough处理某些列。drop表示直接删除,passthrough是不做处理# 对于没有经过full_pipeline处理的列,默认是会被删除的,但是可以给任意transformer# 设置超参数 remainder="passthrough"full_pipeline = ColumnTransformer([# ("dr", "drop", drop_attribs),# ("pass", "passthrough", drop_attribs),("num", num_pipeline, num_attribs),("cat", OneHotEncoder(), cat_attribs),])housing_prepared = full_pipeline.fit_transform(housing)print(housing_prepared)
总结数据整理:
def transform_data(housing):from sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import StandardScalerfrom sklearn.compose import ColumnTransformerfrom sklearn.preprocessing import OneHotEncoder# 自定义pipelinenum_pipeline = Pipeline([('imputer', SimpleImputer(strategy='median')),('attribs_adder', CombinedAttributesAdder()),('std_scaler', StandardScaler()),])# 制作列名listhousing_num = housing.drop("ocean_proximity", axis=1)num_attribs = list(housing_num)cat_attribs = ["ocean_proximity"]# 构造总pipelinefull_pipeline = ColumnTransformer([("num", num_pipeline, num_attribs),("cat", OneHotEncoder(), cat_attribs),])housing_prepared = full_pipeline.fit_transform(housing)return housing_prepared
这篇关于机器学习入门实例-加州房价预测-2(数据整理)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






