本文主要是介绍简单四招,快速提升数据洞察力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很多同学抱怨:每天对着大堆数字,却看不出个名堂。反而有些做业务的人,看几个数字就能马上做出准确判断。咋回事!看着数据没有感觉,是缺少数据洞察力的表现。数据洞察力和操作工具没有关系,完全是一种思维习惯。
建立起来以后,不单单对工作有帮助,在生活中用处也很大,今天我们系统讲解下。
01
感受下啥叫洞察力
数字本身没有啥含义,数字+业务场景,才有了具体业务含义(如下图):

注意,上图的小帅哥会暴走,并不是因为姑娘180身高,而是因为姑娘180把他比得太矮了(且因此受过嘲讽)。“比”才是问题的关键。所以数据本身不形成判断,数据+标准才能形成判断。想读懂数据的含义,一定得看具体业务场景下,业务判断的标准是什么(如下图)。
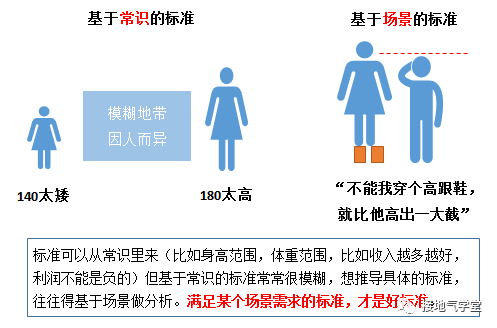
n 有了数据、业务场景、判断标准,我们才能形成基本的数据洞察。这三者缺一不可。
n 少了数据,就会陷入:“我看到一个黑苹果,所以全天下苹果都是黑色的”这种窘境。
n 少了业务场景,就会出现:“一个女人十个月生娃,十个女人一个月就能生出来吧”这种糗事。
n 少了判断标准,就会鸡同鸭讲,大家扯了半天,发现说的“好/坏”根本不是一类。
02
培养洞察力的基本思路
既然洞察力来自数据、业务场景、判断标准的组合,培养洞察力,也是从这三个方向出发,包括:
1、遇事找数据
2、细致了解业务场景
3、清晰判断标准
4、积累特定场景下,数据判断的结论
5、在新场景中使用结论,检验效果
6、持续积累正确结论,修正错误结论
这一段话看起来很官方,可实际操作起来非常简单,并且我们每个人、每天都在实践。就比如找对象,懵懂的小男生都是挑剔热巴太胖、幂幂头秃,幻想自己找个仙女下凡。可真自己约会相亲追过几个女生,就发现“哦,原来现实中找个美女那么难呀!”

然后真找个“美女”相处一段时间,就发现比起长相,性格、爱好、生活能力、工作能力哪个都更重要。半夜,小哥一个人独自抽着烟,对着月亮,思考:“为毛我要花钱花力气请个姑奶奶回来伺候,我欠抽吗!”的时候,他的洞察力就有了质的飞跃。即使以后再看到漂亮小姑娘,他也会立即明白:这不是我的菜!
在现实生活中,制约洞察力的关键,往往是数据。因为生活中信息不对称问题严重,收集数据的难度太高,还要付出时间、金钱甚至前途、未来这种高额成本。
所以在生活中,我们常采用的是有限理性的策略。在可行范围内,尽量用少的数据做决策。或者干脆采用跟随策略,跟着那些比我们优秀的人混。但在企业里,则是完全不同的另一幅场景。
03
培养数据洞察力的难点
在企业工作中,培养数据洞察力最大的难点,是数据、业务场景、标准三者是相互分离的。
n 做数据分析的同学们不了解业务场景,只能对着数据瞎猜;
n 业务部门的人自己稀里糊涂,或者各怀鬼胎,故意扭曲判断标准;
n 对数据重视度不够,基础数据采集不全,遇到事都喜欢讲个案,不看数据全貌;
这些糟糕状况,都会导致做数据分析的同学们很难积累经验。
于是我们常常发现,企业里最有洞察力的人往往是老板。因为在老板那里这三者是透明的,所以即使不操作基础数据,他老人家也能明察秋毫。
但这对数据分析师可不是件好事。因为老板还等着我们给意见呢,事事都让老板跑在我们前边,会引发不满的。所以做数据的同学们还是得自己锻炼下洞察力。
04
培养数据洞察力的步骤
很多同学一说要提升洞察力,最喜欢干这三件事:
n 找《XX行业2020-2025全景洞察报告(重磅深度!)》
n 找XX行业数据指标体系思维导图,挑个最密密麻麻的保存在D盘-干货文件夹
n 加各种数据分析群,问:“有没有牛X的数据分析报告看看,有洞察那种,发来看看”
这三种方法完全没用。这就像一个想谈恋爱的小伙,每天在网上看美女图片一样,自己不动手练,不具体思考,是不可能提升洞察力的。永远不动,永远不会。得想办法自己动手才行。而且往往这些东西内容太多,最后保存在D盘的玩意,你也永远不会看。所以最好从一个具体小点出发。
▌第一步:从一个场景一个指标开始
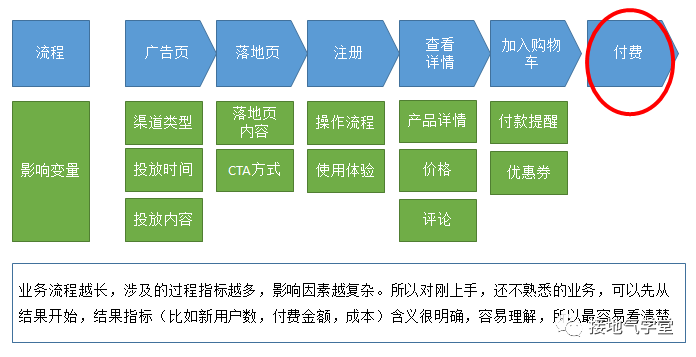
做数据的同学,优势在于手上有数据,可以随时查。劣势在于不了解业务场景。因此把数据结合到业务场景中,是破题的关键。最好找一个自己熟悉的业务,有好朋友的部门入手。从理解结果指标开始(如下图)。
▌第二步:从极值到中间值
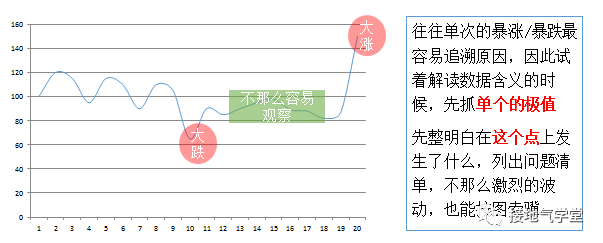
理解了指标业务含义,想要形成判断,可以从白犀牛开始——先看指标极大、极小值的时候。这些情况是什么场景,发生什么问题,有什么应对。
有了对极值的了解,就行掌握基础的判断标准,也能积累分析假设和分析逻辑。当遇到没有那么极端的情况时,可以顺着已经积累的分析逻辑去理解。实在解读不了,也可以选择再观察观察,看看数据往哪个极端方向发展(如下图)。
▌第三步:从静态到动态
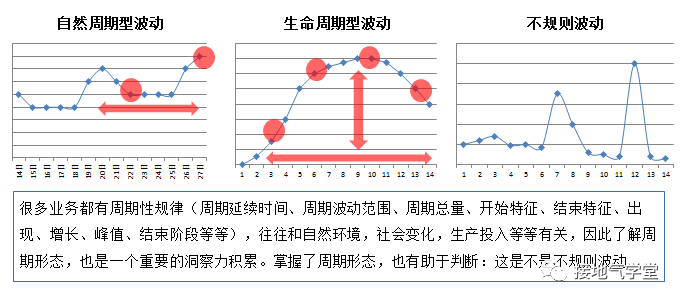
当我们对静态场景积累的足够的洞察的时候,就能解读动态场景。本质上,动态场景只是一系列静态场景的合集。要额外提醒的是:一个业务变化往往有规律性。一个连续的规律,本身是具有业务含义的。积累周期形态的规律,可以从点到线,提升洞察能力。
▌第四步:从单指标到多指标
对单指标有了洞察积累,可以往多指标扩展,掌握了结果指标的判断,可以联系过程指标一起看。注意:多指标不是单指标的堆积,拼在一起的时候,也不是每个指标越多越好的。多指标组合时,在特定业务场景下会形成特定的形态,基于形态的解读能做出更准确的判断(如下图)。
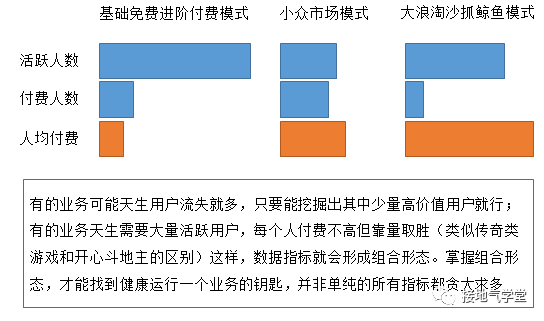
掌握了基础形态,后续还能持续观察形态变化,积累更多经验,这样就慢慢能由简入繁,越来越多积累经验,积累多了自然能举一反三了。
要注意的是,换个行业,换个公司,换个产品,换个发展阶段,具体场景都会变化。所以企图追求“万古不变的数据分析真理”,只会让自己在玄学道路上越走越远。想提升洞察力,就多多积累具体场景碎片,提升具体分析能力。具体问题,具体分析,这句话永远不过时。
然而有些同学会问:本篇讲的更多是如何读懂数据,如果是基于数据做分析呢?该怎么提升?分析能力是个很宏大的话题,如果大家感兴趣,本篇集齐60在看。下一篇我们从源头开始,先讲《如何梳理复杂问题》,敬请期待哦。
原创精选推荐:
想跟陈老师一起,解决你的数据分析难题,提升数据分析能力?学习陈老师本人的《商业分析全攻略》视频课程,加入学员群,和陈老师一对一讨论,让陈老师手把手教你提升分析能力。

《商业分析全攻略》
长按扫描二维码
了解陈老师的视频课程
还可加入学员群
享受陈老师一对一咨询服务
点击左下角“阅读原文”听陈老师讲课
这篇关于简单四招,快速提升数据洞察力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







