本文主要是介绍Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
在这篇文章中,我们提出了一个端到端的网络,称为Cycle-Dehaze,为单一图像去雾问题,它配对的有雾图像和其对应的图像进行训练。也就是说,我们通过以不成对的方式加入干净和模糊的图像来训练网络。此外,所提出的方法不依赖于大气散射模型参数的估计。我们的方法通过结合循环一致性和感知损失来增强CycleGAN方法,以提高纹理信息恢复的质量,并生成视觉上更好的无雾霾图像。典型地,用于去雾的深度学习模型将低分辨率图像作为输入并产生低分辨率输出。然而,在NTIRE 2018单幅图像去雾挑战中,提供了高分辨率图像。因此,我们应用双三次降尺度。从网络获得低分辨率输出后,我们利用拉普拉斯金字塔将输出图像提升到原始分辨率。我们在NYU-Depth、, I-HAZE, and O-HAZE数据集上进行了实验。大量实验表明,该方法从定量和定性两个方面改进了CycleGAN方法。
1、简介
诸如雾、薄雾和霾等恶劣天气事件极大地降低了任何景物的可见度,并对计算机视觉应用(例如,物体检测、跟踪和分割)构成重大障碍。虽然从模糊区域捕获的图像通常保留了大部分主要内容,但在将它们输入计算机视觉算法之前,它们需要一些能见度增强作为预处理,计算机视觉算法主要基于在晴朗天气条件下捕获的图像进行训练。这种预处理通常称为图像去雾/去雾。图像去雾技术的目的是生成从恶劣天气事件中净化的无霾图像。图1显示了NTIRE 2018单幅图像去雾挑战赛的模糊和无模糊图像样本[4]。

在最近的文献中,研究人员集中在单图像去雾方法上,该方法可以在不需要任何额外信息的情况下对输入图像去雾,例如深度信息或场景的已知3D模型。单幅图像去雾方法分为基于先验信息的方法和基于学习的方法。基于先验信息的方法主要是基于利用先验的大气散射模型的参数估计,如暗通道先验,颜色衰减先验,霾线先验。另一方面,这些参数是通过基于学习的方法从训练数据中获得的,这些方法主要依赖于深度学习方法。深度神经网络的扩散增加了大规模数据集的使用,因此,研究人员倾向于创建合成去雾数据集,如FRIDA和D-HAZY,它们比真实去雾数据集具有更实际的创建过程。尽管大多数深度学习方法使用中间参数的估计,例如透射图和大气光,但也有其他基于生成对抗网络(GANs)的方法,这些方法建立的模型没有受益于这些中间参数。
Goodfellow等人介绍的GANs在图像生成任务中非常成功,例如数据增强、图像修复和风格转换。他们的主要目标是在目标域上生成与原始图像无法区分的假图像。通过利用GANs,存在用于单幅图像去雾的最先进的方法,其要求以成对的方式模糊输入图像及其背景真相。最近,在CycleGAN提出用于图像到图像翻译的循环一致性损失之后,配对数据的需要被去除。受循环一致性损失的启发,杨等人提出了用于单幅图像去雾的解缠绕去雾网络。与CycleGAN [37]架构不同,DDN通过大气散射模型重建循环图像,而不是使用另一个生成器。因此,在训练阶段需要场景辐射率、介质透射图和全局大气光[34]。
在这项工作中,我们通过聚集aggregating cycle-consistency and perceptual损失,利用CycleGAN结构引入Cycle-Dehaze network。我们的主要目的是建立一个端到端的网络,而不考虑单个图像去雾的大气散射模型。为了将输入图像输入到我们的网络中,它们通过双三次缩小被调整到256 × 256像素的分辨率。在对输入图像去雾之后,双三次向上缩放到它们的原始尺寸不足以估计丢失的信息。为了能够获得高分辨率图像,我们采用了基于拉普拉斯金字塔的简单上采样方法。我们在D-HAZY的NYU-Depth、部分D-HAZY和NTIRE 2018单幅图像去雾挑战数据集上进行实验:I-HAZY和O-HAZY。根据我们的结果,Cycle-Dehaze实现了比CycleGAN架构更高的图像质量指标。此外,我们还分析了Cycle-Dehaze在跨数据集场景下的性能,即在训练和测试阶段使用不同的数据集。
我们的主要贡献总结如下:
- 除了循环一致性损失之外,我们还通过增加循环感知一致性损失来增强单个图像去雾的CycleGAN结构。
- 在训练和测试阶段,我们的方法既不需要模糊和地面真实图像的成对样本,也不需要大气散射模型的任何参数。
- 我们提出了一种简单有效的技术,通过利用拉普拉斯金字塔来放大去杂图像。
- 由于其循环结构,我们的方法提供了一个可推广的模型,并通过跨数据集场景的实验进行了验证。
本文的其余部分组织如下:在第2节中,提供了相关工作的简要概述。第3节描述了建议的方法。实验结果在第4节中介绍和讨论。最后,第五部分给出了结论。
3、提出的方法
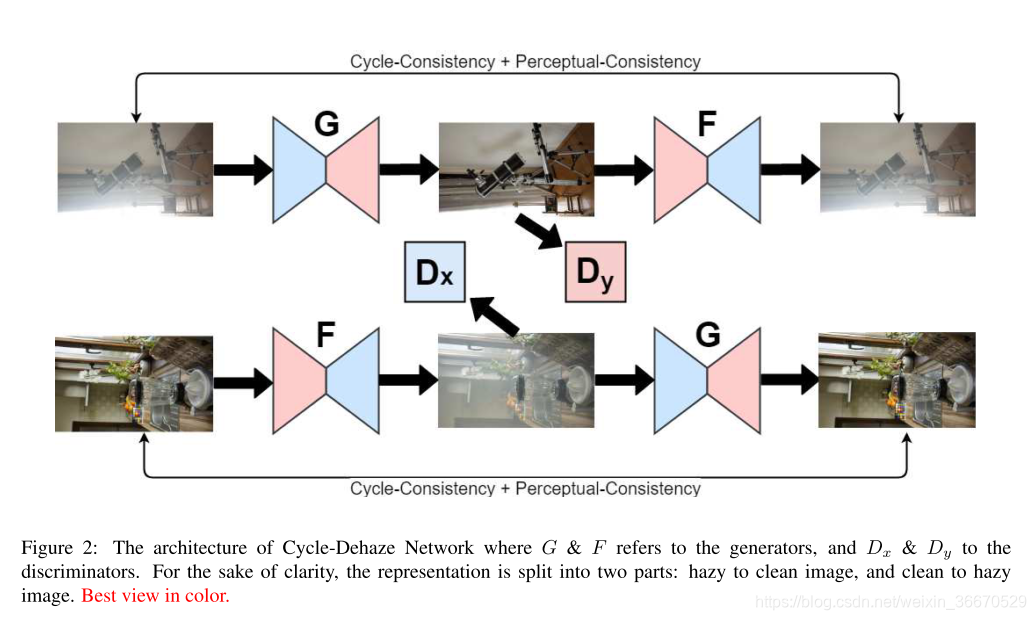
Cycle-Dehaze是CycleGAN架构的增强版本,用于单个图像去雾。为了增加视觉质量指标,SSIM PSNR,它利用了增强网络带来的感知损失。这种损失的主要思想是在特征空间而不是像素空间中比较图像。因此,Cycle-Dehaze在两个空间将原始图像与重建的循环图像进行比较,其中循环一致性损失确保了高PSNR值,而感知损失保持了图像的锐度。此外,Cycle-Dehaze使用传统的拉普拉斯金字塔来提供主去雾过程之后的更好的上采样结果。图2显示了Cycle-Dehaze体系结构的总体表示。
如图2所示,Cycle-Dehaze体系结构由两个生成器G,F和两个鉴别器Dx,Dy组成。除了常规的鉴别器和生成器损失之外,该架构还受益于循环一致性和循环感知一致性损耗的组合,从而有利于清除/增加雾度。因此,该架构被迫保留输入图像的纹理信息,并生成独特的无雾霾输出。另一方面,追求循环一致性和感知一致性损失之间的平衡不是一件小事。过度重视感知损失会导致去雾过程后颜色信息的丢失。因此,周期一致性损失需要比感知损失具有更高的权重。
Cyclic perceptual-consistency loss:
CycleGAN架构引入了循环一致性损失,它为不成对的图像到图像转换任务计算原始图像和循环图像之间的L1范数。然而,这种原始图像和循环图像之间的计算损失不足以恢复所有的纹理信息,因为模糊图像大多严重损坏。循环感知一致性损失旨在通过查看从VGG16架构的第二和第五池化层提取的高级和低级特征的组合来保留原始图像结构。在x ∈ X,y ∈ Y和发生器G : X → Y,发生器F : Y → X的约束下,循环感知一致性损失的公式如下,其中(X,Y)指模糊和背景真实不成对的图像集,φ是来自第二和第五汇集层的VGG16 [29]特征提取器:
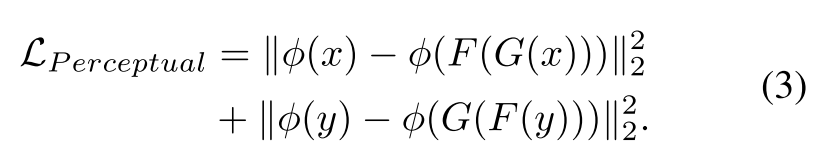
Full objective of Cycle-Dehaze:
与CycleGAN [37]架构相比,Cycle-Dehaze有一个额外的损失。因此,Cycle-Dehaze的目标可以表述如下,其中![]() 是CycleGAN [37]体系结构的全部目标,D代表鉴别器,γ控制循环感知一致性损失的效果:
是CycleGAN [37]体系结构的全部目标,D代表鉴别器,γ控制循环感知一致性损失的效果:
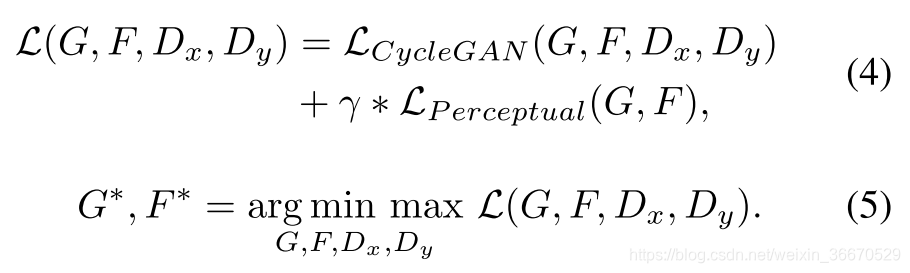
总之,Cycle-Dehaze优化了CycleGAN架构,根据等式4和等式5,在等式3中给出了额外的循环感知一致性损失。为了获得无雾图像,在测试时使用发生器G *。
Laplacian upscaling:
Cycle-Dehaze架构由于GPU限制,取256 × 256像素分辨率输入图像,产生256 × 256像素分辨率输出图像。为了减少图像质量在缩小和放大过程中的恶化,我们利用了拉普拉斯金字塔,它是通过使用高分辨率模糊图像创建的。为了获得高分辨率去杂图像,我们用去杂低分辨率图像改变了拉普拉斯金字塔的顶层,并像往常一样执行拉普拉斯向上缩放过程。拉普拉斯金字塔的这种基本用法在清洁过程中特别保留了模糊图像的大部分边缘,并在放大阶段提高了SSIM值。拉普拉斯放大是处理高分辨率图像时可选的后处理步骤。
Implementation details (indoor/outdoor):
我们在训练和测试阶段使用了TensorFlow框架,在调整图像大小时使用了MATLAB。我们用NVIDIA TITAN X显卡训练了我们的模型。为了确保一致性,我们在每个数据集上执行了大约40个纪元。我们在Intel Core i7-5820K CPU上的测试时间约为每张图像8秒。在我们模型的训练阶段,我们使用了学习率为1e-4的亚当优化器。此外,我们将γ取为0.0001,比循环一致性损失的权重低1e+5倍。
除了循环感知一致性损失和拉普拉斯金字塔作为后处理步骤之外,我们的网络类似于原始的CycleGAN架构。在拉普拉斯金字塔的最高级别,由于网络的要求,我们将图像缩放到256 × 256像素的分辨率。为了计算循环感知一致性损失,我们使用VGG16架构,该架构由ImageNet预训练模型初始化。提议的方法的源代码将通过项目的GitHub第1页公开。
参考Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing - 云+社区 - 腾讯云
这篇关于Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







