本文主要是介绍[正在进行中...] KG object detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- The More You Know: Using Knowledge Graphs for Image Classification
- 模型
- 数据集
- case
- Object Detection Meets Knowledge Graphs
- 方法
- 数据集
- case
- Multi-Label Image Recognition with Graph Convolutional Networks
- 方法
- GCN recap
- multi-label GCN
- ML_GCN的相关矩阵
- 基础
- R-CNN
- SPP Net
- Fast R-CNN
- Faster R-CNN
- 总结一下各大算法的步骤
The More You Know: Using Knowledge Graphs for Image Classification
paper:https://arxiv.org/pdf/1612.04844.pdf
人类和learning-based CV 算法最大的不同是:人类能够依靠背景知识在可视化世界中做推理。人可以只通过少量的样本了解到这个物品的特征、这个物品和其他物品的关系。如下图在预测Elephant Shrew(“象鼩(qú)”)的时候,假设我们之前没有见到过,但是我们看书看过或者是别人告诉过我们“象鼩(qú)是一种长得像是老鼠,然后鼻子又像是大象的动物,经常在灌木丛中活动… ”,然后当我们某一天看到这个的时候,我们就有通过这些特征,这些背景知识就可能判断出这个是象鼩(qú)。(这个想法跟很多基于属性的Zero shot learning image classification的做法很像。好吧,文中提到了他们和这个ZSL的任务相关)。
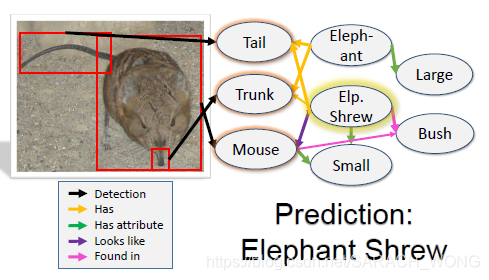
首选,文章将上述的“大象鼻子、老鼠身子”等这些信息叫做evidence,之后的识别过程就像是利用证据进行推理的过程,需要证据一步步传递,直到推出来。那么有什么模型能满足这个想法呢?答案GNN系列网络。本文便是以KG作为背景知识,基于GGNN(Gated Graph Neural Network),提出Graph Search Neural Network(GSNN)进行多标签图片分类。比较GGNN,GSNN不更新整个graph上的点,1)只更新subset,因此计算效率更高, 2)利用importance network为每个结点计算重要程度来挑选subset的,因此有更强的可解释性。
模型
模型由三部分组成:propagation network ,importance network,output network
GGNN
GGNN的思想类似于LSTM,可以从下面propagation network的公式直接看。
- propagation network : N N N个结点的图, h v ( t ) h_v^{(t)} hv(t):表示结点 v v v在时间 t t t的隐层状态, A v T A_v^T AvT是邻接矩阵。
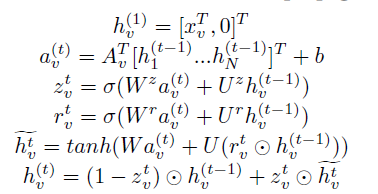
GSNN
- importance network会为已有的active node计算下一步需要扩展的top P个重要的active nodes。(初始active node基于Faster R-CNN得到80类的基础分类结果,设置概率的阈值来判断)
为了训练importance network,我们需要对给定的图像为每个node安排重要度。安排的原则是:如果node是ground truth concept,则重要度为1,若是一跳的,重要度为 λ \lambda λ,若是两跳,重要度为 λ 2 \lambda^2 λ2,即:靠近最终输出在扩展的时候是最重要的。
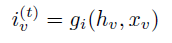
- output network 通过BCE(Binary Cross Entropy)训练。相比GGNN的 g ( h v ( T ) , x v ) g(h_v^{(T)},x_v) g(hv(T),xv),GSNN多了bias term n v n_v nv。
L = g ( h v ( T ) , x v , n v ) L=g(h_v^{(T)}, x_v, n_v) L=g(hv(T),xv,nv)
原因见论文
数据集
目标检测:
-
COCO
-
Visual Genome dataset:100,000张图片,每个被标记为object,attributes and object之间/object和attribute之间的relations.每张图片平均21 labels。
-
VGML:论文构建的数据集,基于Visual Genome dataset中200个最常见的object,100个最常见的attributes,还有coco中多的16个,共316个visual concepts。
KG:通过Visual Genome dataset + WordNet进行构建。因为Visual Genome dataset 包含了scene-level relationships between objects,但是没有包含semantic relation,因此加入wordnet进行扩充。
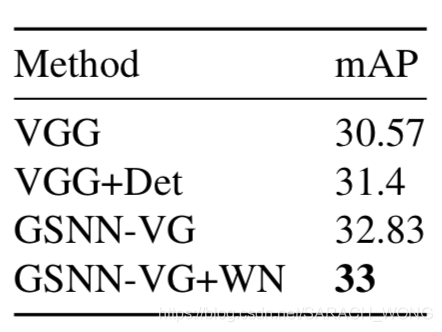
实验结果:
1、 VG:Visual Genome graph ,WN:WordNet graph.
2、训练样本数量对结果的影响
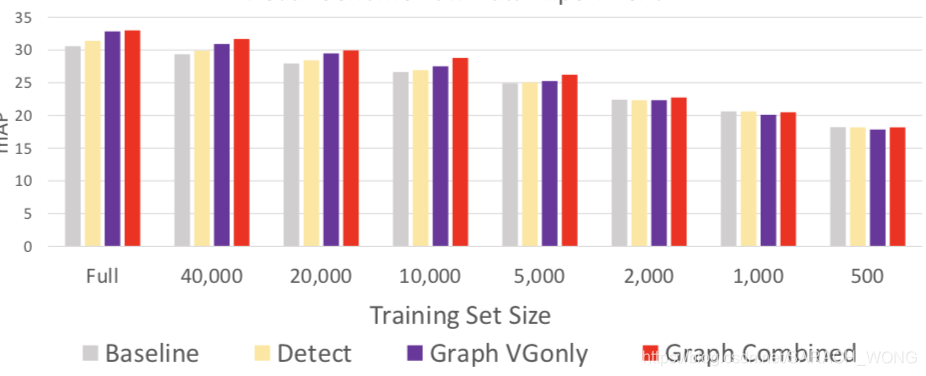
3、在coco上的效果:

case
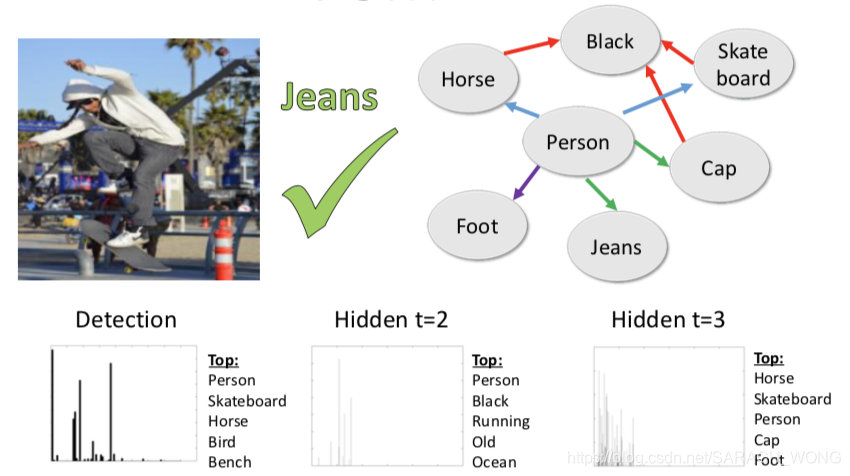
Object Detection Meets Knowledge Graphs
链接:https://www.ijcai.org/proceedings/2017/0230.pdf
在原始目标检测的优化过程中添加“semantic consistency”的约束进行优化,“semantic consistency”来自于背景知识。最终的实验结果是在不降低precision值的情况下recall相比之前提升6.3。
“semantic consistency”的理解:基于“家猫可能会坐在盘子上,而熊不会”这样的背景知识,1)即使训练的时候没有样本是关于 “猫、桌子”的,测试也可能会预测出来;2)当目标检测检测出来“熊”和“桌子”时候,这和背景知识是冲突的,因此会调整这两个的得分,如将某一张图片原始目标检测得到的(bear,0.8) & (table,0.9)调整为(bear,0.01) & (table,0.9)。
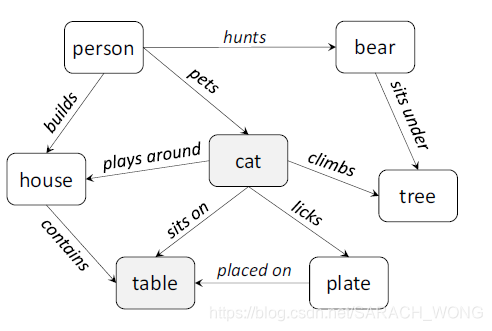
方法的两个技术难点是:
1)如何量化背景知识
因为KG一般是通过symbolic表示,而目标检测算法是基于subsymbolic或numerical表示,因此需要量化。文中提出量化的方式是为每对concepts计算numerical表示的语义一致度。如在KG中有“cat sits on table”(如上图,基于概念知识图谱),说明cat and table是语义一致度比较高,而熊不是。
这里提到“cat licks plate” and “plate placed on table”.需要看下是什么因素保证了这样的传输?
2)如何将语义一致性应用到我们的任务中
基于假设:“语义一致性高的更倾向于在同一张图片中出现”。如果用 ( o , p ) (o,p) (o,p)表示 o o o有 p p p的概率出现在图像中,那么(cat,0.8) & (table,0.9) 看起来会比(bear,0.8) & (table,0.9)更合理,模型可能会将后者纠正为(bear,0.01) & (table,0.9)。论文将这种约束映射为一个优化问题。
方法
原始的目标检测: P = B ∗ L ∈ R P = B * L \in \mathbb{R} P=B∗L∈R ,其中 P b , l = p ( l ∣ b ) P_{b,l}=p(l|b) Pb,l=p(l∣b)表示图像的bounding box b b b被打标为label l l l的概率为 P b , l P_{b,l} Pb,l
KG-aware目标检测: P ^ \hat{P} P^是经过“semantic consistency”纠正后的 P P P,即文章中提到的“ P ^ \hat{P} P^ is a knowledge-aware enhancement of P P P”
目标检测输出: l ^ = a r g m a x l P ^ b , l \hat{l}=argmax_l\hat{P}_{b,l} l^=argmaxlP^b,l
1)这里看到目标检测是需要box的,且box固定的?
2)预测的结果看来是单分类的?不是,是每个box一个label
针对上述两个技术难点:
1、如何量化背景知识。Semantic Consistency, S ∈ R L , L S \in \mathbb{R}^{L,L} S∈RL,L,有“Frequency-based knowledge“和“Graph-based knowledge“两种方式计算。
- Frequency-based knowledge, N N N是KG中总instances数量, n ( l , l ′ ) n(l,l') n(l,l′)是 l l l和 l ′ l' l′共现频率
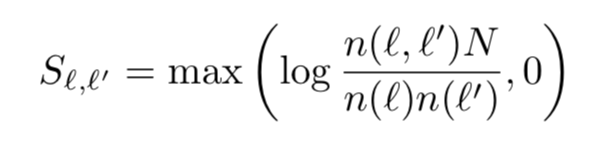
明显这种方式不能处理KG中没有直接相连的实体对,即多跳关系的实体对。
KG中的N是总instance数量是entity数量吗?
- Graph-based knowledge。“random walk with restart”的思想,会构造出从 v 0 v_0 v0到 v t v_t vt的路径 v 0 , v 1 , . . . v t v_0,v_1,...v_t v0,v1,...vt,让 p ( v t = l ′ ∣ v 0 = l ; α ) p(v_t=l'|v_0=l;\alpha) p(vt=l′∣v0=l;α)表示从 l l l到经过 t t t步之后到达 l ′ l' l′的概率。经过很长的游走之后,概率 p p p会收敛到
R l , l ′ = lim t → ∞ p ( v t = l ′ ∣ v 0 = l ; α ) R_{l,l'}=\lim_{t \rightarrow\infty }p(v_t=l'|v_0=l;\alpha) Rl,l′=t→∞limp(vt=l′∣v0=l;α)
这里 R l , l ′ = R_{l,l'}= Rl,l′=不是对称的,上面方法是。 S S S的计算如下:
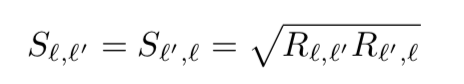
和deepwalk的思想差不多,可能deepwalk是参考这个的?
2、 如何将语义一致性应用到我们的任务中。回想上述假设:“语义一致性高的更倾向于在同一张图片中出现”,有下面的优化目标。第一项保证语义一致性高的得分近似,第二项保证经过KG纠正后的结果不应该太偏离原始目标检测出来的值。
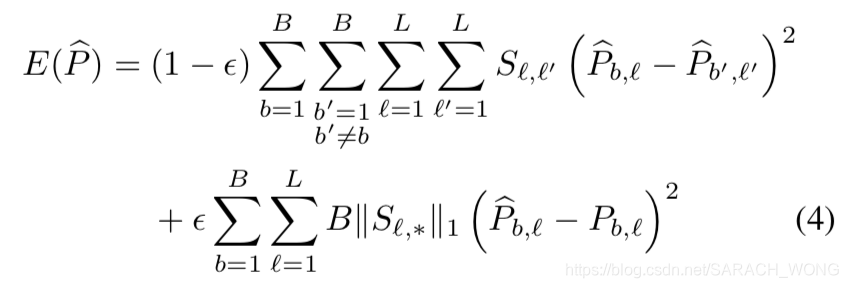
具体的优化过程见论文。
数据集
KG:conceptNet
目标检测:MSCOCO15,PASCAL07
在MSCOCO15上结果
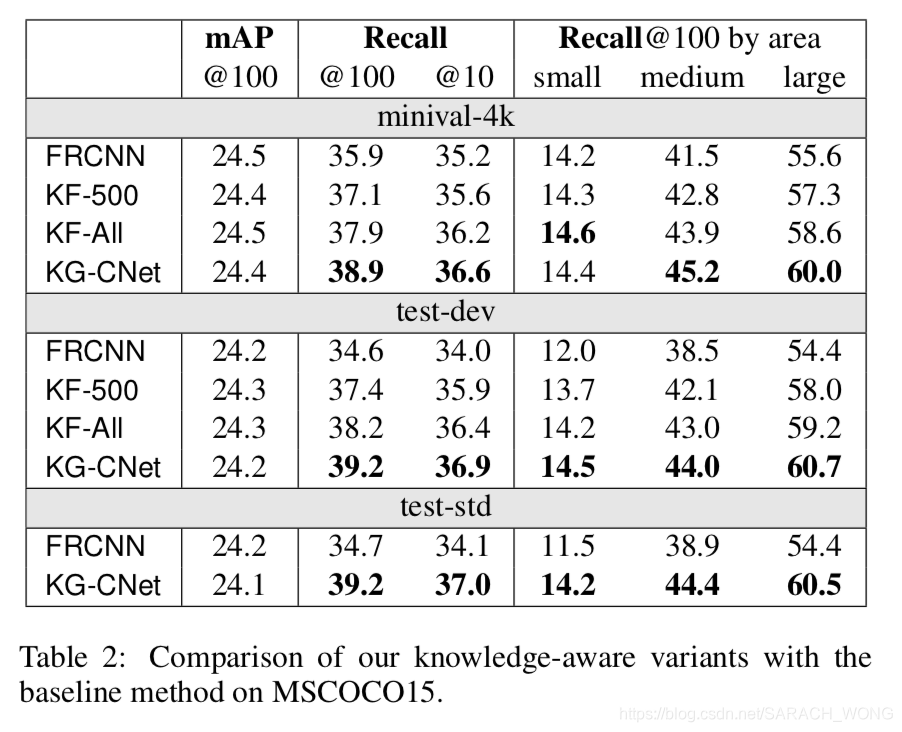
KF-ALL,KF-500是基于frequency-based knowledge,KG-CNet基于graph-based knowledge
case
下面的图像中,橘黄色的ground-truth label,紫色是检测出来的,左边是FRCNN,右边是KG-CNet。

– 文中的“concept”对应KG中的“entity”
restriction for my task:
- 会设置bouding box数量?
- 最大的问题是要求目标在文中出现,即约束条件中设置了两个出现在图片中的object的出现概率差不多。训练的目标更多是让原始的object detection检测的更全一点。
Multi-Label Image Recognition with Graph Convolutional Networks
旷视自己写的:旷视研究院提出ML-GCN:基于图卷积网络的多标签图像识别模型,这里只放了自己需要的部分。
核心是建模标签之间的依赖关系去提升识别的性能。而本文通过GCN去捕获这个依赖关系。整体来说,会先用label构建一张图—label graph,图上每个点(label)用相应的(label’s) embedding进行初始化,通过标记相关矩阵在GCN的过程中指导信息的传播,具体来说是在节点更新的时候平衡节点和其邻居的信息传播量,最终得到一组有依赖关系的目标分类器,相当于GCN建立了从embedding到classifer的映射。和其他GCN不同的点在于构建了一个有效的“label correlation matrix”去指导GCN中节点之间信息的传播。
方法
GCN recap
GCN的核心是通过节点之间信息的传播来更新节点的表示。不像平常的CNN在欧式空间进行操作,GCN在非欧式空间进行。对GCN来说最重要的是从图G上学习函数 f f f, f f f的输入包括两个部分,一个是特征 H l ∈ R n × d H^l \in \mathbb{R}^{n \times d} Hl∈Rn×d和相关矩阵 A ∈ R n × n A \in \mathbb{R}^{n \times n} A∈Rn×n,其中 n n n是结点的数量,通过这两个输入来更新 H l + 1 ∈ R n × d ′ H^{l+1}\in \mathbb{R}^{n \times d'} Hl+1∈Rn×d′,即
H l + 1 = f ( H l , A ) H^{l+1} = f(H^l, A) Hl+1=f(Hl,A)
具体应用了卷积操作的话,上面公式变成:
H l + 1 = h ( A ^ H l W l ) H^{l+1} = h(\hat{A}H^lW^l) Hl+1=h(A^HlWl)
其中, W l ∈ R d × d ′ W^l \in \mathbb{R}^{d \times d'} Wl∈Rd×d′, h ( ⋅ ) h(·) h(⋅)是非线性激活函数,文中用LeakyReLU。及上述的公式堆叠多次得到有label inner-relationship的分类器。
multi-label GCN
multi-label GCN整体框架如下。可以看到由两个部分组成,图像特征表示的学习和 GCN为基础的分类器学习。可以看到feature representation学习到图片的特征维度为 R D \mathbb{R}^D RD,GCN最后一层输出 W ∈ R C × D W \in \mathbb{R}^{C \times D} W∈RC×D,aka,为每个类学到了一个分类器。自然而然预测为
y ^ = W x \hat{y}=Wx y^=Wx
训练基于多标签损失函数:
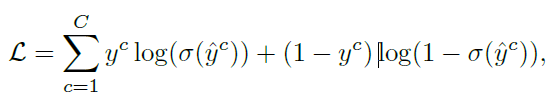
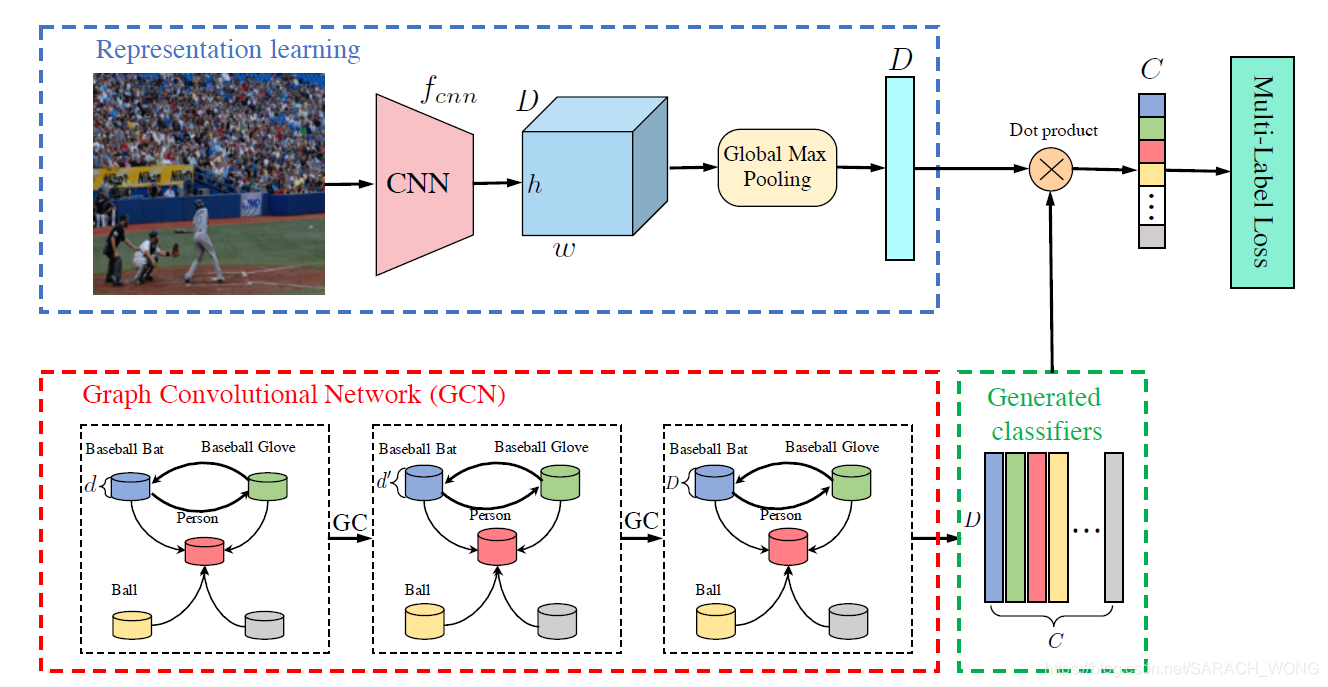
ML_GCN的相关矩阵
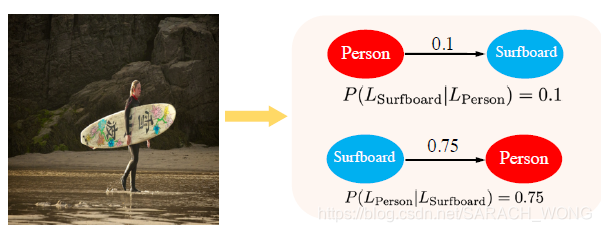
本文基于数据集内的tag的共现来建立相关矩阵 A A A,矩阵非对称,如下检测到滑板情况下,标记为人的概率0.75,反过来是0.1。
BTW:
- gcn的输出不一定是分类器还可以直接是预测结果
# [正在]
从视觉理解的角度,多标签分类是个基础却具有挑战性的任务。存在的方法发现区域级别的线索能够辅助多标签任务的进行,但是,进行多标签标注
基础
建议直接看,以下都是来自于这俩篇
- 一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD,
- 一文读懂Faster RCNN
R-CNN
Region Proposal + CNN。预先找出图中目标可能出现的位置,即候选区域(Region Proposal)。剩下的工作实际就是对候选区域进行图像分类的工作(特征提取+分类)。
R-CNN的简要步骤如下
(1) 输入测试图像
(2) 利用选择性搜索Selective Search算法在图像中从下到上提取2000个左右的可能包含物体的候选区域Region Proposal
(3) 因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征
SPP Net的第一个贡献就是在最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定。
换句话说,在普通的CNN机构中,输入图像的尺寸往往是固定的(比如224*224像素),输出则是一个固定维数的向量。SPP Net在普通的CNN结构中加入了ROI池化层(ROI Pooling),使得网络的输入图像可以是任意尺寸的,输出则不变,同样是一个固定维数的向量。
SPP Net
R-CNN虽然不再像传统方法那样穷举,但R-CNN流程的第一步中对原始图片通过Selective Search提取的候选框region proposal多达2000个左右,而这2000个候选框每个框都需要进行CNN提特征+SVM分类,计算量很大,导致R-CNN检测速度很慢,一张图都需要47s。
有没有方法提速呢?答案是有的,这2000个region proposal不都是图像的一部分吗,那么我们完全可以对图像提一次卷积层特征,然后只需要将region proposal在原图的位置映射到卷积层特征图上,这样对于一张图像我们只需要提一次卷积层特征,然后将每个region proposal的卷积层特征输入到全连接层做后续操作。
但现在的问题是每个region proposal的尺度不一样,而全连接层输入必须是固定的长度,所以直接这样输入全连接层肯定是不行的。SPP Net恰好可以解决这个问题。
SPP-Net是出自2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》。
CNN一般都含有卷积部分和全连接部分,其中,卷积层不需要固定尺寸的图像,而全连接层是需要固定大小的输入。所以当全连接层面对各种尺寸的输入数据时,就需要对输入数据进行crop(crop就是从一个大图扣出网络输入大小的patch,比如227×227),或warp(把一个边界框bounding box的内容resize成227×227)等一系列操作以统一图片的尺寸大小,比如224224(ImageNet)、3232(LenNet)、96*96等。
但warp/crop这种预处理,导致的问题要么被拉伸变形、要么物体不全,限制了识别精确度。没太明白?说句人话就是,一张16:9比例的图片你硬是要Resize成1:1的图片,你说图片失真不?
SPP Net的作者Kaiming He等人逆向思考,既然由于全连接FC层的存在,普通的CNN需要通过固定输入图片的大小来使得全连接层的输入固定。那借鉴卷积层可以适应任何尺寸,为何不能在卷积层的最后加入某种结构,使得后面全连接层得到的输入变成固定的呢?
这个“化腐朽为神奇”的结构就是spatial pyramid pooling layer。
简言之,CNN原本只能固定输入、固定输出,CNN加上SSP之后,便能任意输入、固定输出
Fast R-CNN
R-CNN与Fast R-CNN的区别有哪些呢?
先说R-CNN的缺点:即使使用了Selective Search等预处理步骤来提取潜在的bounding box作为输入,但是R-CNN仍会有严重的速度瓶颈,原因也很明显,就是计算机对所有region进行特征提取时会有重复计算,Fast-RCNN正是为了解决这个问题诞生的。
R-CNN训练过程分为了三个阶段,而Fast R-CNN直接使用softmax替代SVM分类,同时利用多任务损失函数边框回归也加入到了网络中,这样整个的训练过程是端到端的(除去Region Proposal提取阶段)。
也就是说,之前R-CNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression,而在Fast R-CNN中,作者巧妙的把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征,并相互促进。
画一画重点:
R-CNN有一些相当大的缺点(把这些缺点都改掉了,就成了Fast R-CNN)。
大缺点:由于每一个候选框都要独自经过CNN,这使得花费的时间非常多。
解决:共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征
原来的方法:许多候选框(比如两千个)–>CNN–>得到每个候选框的特征–>分类+回归
现在的方法:一张完整图片–>CNN–>得到每张候选框的特征–>分类+回归
Faster R-CNN
Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。那我们能不能找出一个更加高效的方法来求出这些候选框呢?
解决:加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。
所以,rgbd在Fast R-CNN中引入Region Proposal Network(RPN)替代Selective Search,同时引入anchor box应对目标形状的变化问题(anchor就是位置和大小固定的box,可以理解成事先设置好的固定的proposal)。
具体做法:
• 将RPN放在最后一个卷积层的后面
• RPN直接训练得到候选区域
总结一下各大算法的步骤
简言之,即如本文开头所列
R-CNN(Selective Search + CNN + SVM)
SPP-net(ROI Pooling)
Fast R-CNN(Selective Search + CNN + ROI)
Faster R-CNN(RPN + CNN + ROI)
这篇关于[正在进行中...] KG object detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



