本文主要是介绍大数据(4c)Kafka理论知识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高吞吐的目录
- 1、基础理论
- 1.1、什么是消息队列
- 1.2、消息队列的两种模式
- 1.3、高可用原理
- 2、Kafka概述
- 3、主题和分区
- 4、数据存储原理
- 5、Kafka读写如何高效?
- 6、生产数据的可靠性
- 6.1、应答机制
- 6.2、领导候选
- 6.3、数据一致性
- 6.4、容错机制
- 附录
1、基础理论
1.1、什么是消息队列
- Message Queue
- 消息的传输过程中保存消息的容器
- 应用场景:程序解耦、异步消息、流量削锋…
1.2、消息队列的两种模式
点对点模式(消费者主动拉取数据,拉取成功后删除队列上的数据)
一个消息 只能有一个消费者可以消费

发布/订阅模式(消费者消费数据之后,队列上的数据不会被马上清除)

1.3、高可用原理
- High Availability
- 目标:减少停工时间
- 策略:消除单点故障
工作模式

2、Kafka概述
- 基于发布/订阅模式的 分布式的 消息队列
- 主用场景:大数据实时处理、流量削峰
架构图

| 英文名 | 译名 | 说明 |
|---|---|---|
| Producer | 生产者 | 生产消息 |
| Consumer | 消费者 | 消费消息 |
| Consumer Group | 消费者组 | 由多个Consumer组成 是逻辑上的一个订阅者 |
| Broker | 经纪人 | 一台Kafka服务器就是一个Broker 一个集群由多个Broker组成 一个Broker可以容纳多个topic的partition |
| Topic | 主题 | 可以理解为一个存放消息的逻辑上的队列 一个topic可以分布到多个Broker |
| Partition | 分区 | 一个topic可以分存多个partition 每个partition是一个有序的队列 |
| Replica | 复制品 | 数据副本 |
| Leader | 首领 | 对接生产者和消费者 |
| Follower | 追随者 | 实时同步leader的数据 leader故障时,某follower会成为新的leader |
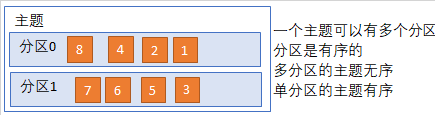
3、主题和分区
- 主题是逻辑上的概念
- 分区是物理上的概念,以文件夹的方式
一个主题下可以有多个分区;分区有序,主题不一定有序
消费者组是逻辑上的一个订阅者,由多个消费者组成
各个分区可以被消费者并行消费
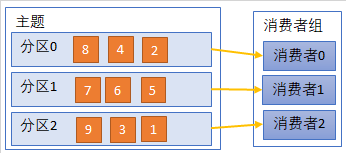
多个消费者组可以订阅同一个主题
1个消费者可以消费多个分区
对于1个消费者组,1个分区 只能被 该消费者组内的1个消费者 消费
建议 某主题的分区数=订阅该主题的消费者组的消费者数

一台服务器有Broker,一个集群由多个Broker组成
一个Topic可以分布到多个Broker

4、数据存储原理
Kafka将 生产者发送的消息 暂存到硬盘
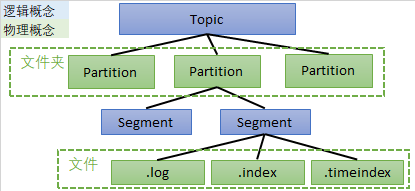
下面使用命令查看具体的文件夹和文件
1、把
segment改小,使得容易产生大量segment
vi $KAFKA_HOME/config/server.properties
log.segment.bytes=102400
2、创建分区,两个副本,三个分区
kafka-topics.sh \
--zookeeper hadoop100:2181/kafka \
--create \
--replication-factor 2 \
--partitions 3 \
--topic topicA
3、生产数据(Kafka内置的生产者,可用于压测)
kafka-producer-perf-test.sh --topic topicA \
--num-records 4000 --record-size 1024 \
--producer-props bootstrap.servers=hadoop100:9092 --throughput -1
| 参数 | 说明 |
|---|---|
--num-records | 写多少个数据 |
--record-size | 每个数据多大(单位:byte) |
--producer-props | 指定数据写到哪个集群 |
--throughput | 写数据速率限制,-1表示不限 |
4、查看数据目录下名为
topicA的主题
ls $KAFKA_HOME/logs | grep topicA
ssh hadoop101 'ls $KAFKA_HOME/logs | grep topicA'
ssh hadoop102 'ls $KAFKA_HOME/logs | grep topicA'
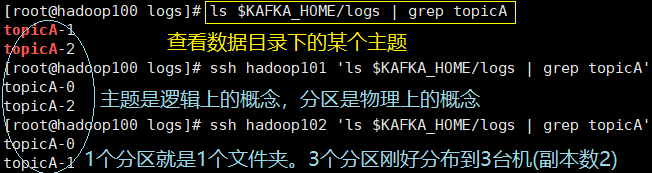
5、查看分区(文件夹)内的文件
ll topicA-1

6、查看索引文件以及偏移量(offset)
kafka-dump-log.sh --print-data-log --files 00000000000000000000.index

7、数据查找
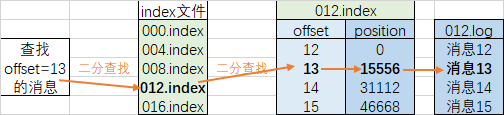
5、Kafka读写如何高效?
- 多分区并行
- 顺序写磁盘
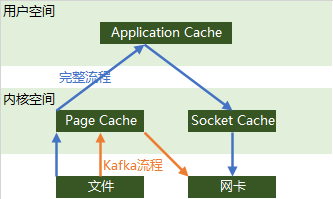
顺序写 速度 远大于 随机写 - 使用了page cache(译名:页高速缓冲存储器)
在Linux读写文件时,page cache用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问 - 零复制技术
6、生产数据的可靠性
6.1、应答机制
- ACK
- 全称:acknowledgement character
- 译名:命令正确应答
- 应答等级
ack=0:Leader接收数据后 应答
ack=1:Leader接收数据并写入后 应答
ack=-1:Leader接收和写入数据,Follower同步数据 后应答

6.2、领导候选
- ISR
- 全称:in-sync replica set
- 与
leader同步到一定程度的follower - 长期没同步的
follower将被踢出ISR leader挂掉后就从ISR中选举新leader
kafka-topics.sh --describe --topic topicA --bootstrap-server hadoop100:9092
查看主题信息,如:分区数、领导者、追随者、Isr……

6.3、数据一致性
只能保证副本之间的数据一致性,并不能保证数据不丢失或不重复
-
LEO
log end offset
当前日志数据(副本)最后一个偏移量 -
HW
high watermark
所有副本的LEO中 最小的那一个

6.4、容错机制
| 容错等级 | 语义 | 说明 |
|---|---|---|
| at most once | 数据最多一条 | 数据可能会丢,但不会重复 |
| at least one | 数据至少一条 | 数据绝不会丢,但可能重复 |
| exactly once | 数据有且只有一条 | 数据不会丢,也不会重复 |
如何实现【exactly once】
1、ack=-1,实现数据不会丢
2、开启幂等性
3、给消息添加唯一标识【生产者ID、分区号、该分区的数据的偏移量】,据此防止数据重复
4、生产者不要挂(生产者挂掉重启后,生产者编号可能变)或 固定生产者编号
附录
| en | 🔉 | cn |
|---|---|---|
| broker | ˈbroʊkər | n. 经纪人 |
| acknowledgement | əkˈnɑːlɪdʒmənt | n. 承认;确认;感谢 |
| replica | ˈreplɪkə | n. 复制品,仿制品;摹本 |
| bootstrap | ˈbuːtstræp | n. (靴筒后的)靴襻;[计] 引导程序;vt. 启动(电脑) |
| watermark | ˈwɔːtərmɑːrk | n. 水印;vt. 印水印;(water mark 两单词合体) |
| exactly | ɪɡˈzæktli | adv. 恰好地;精确地;正确地 |
这篇关于大数据(4c)Kafka理论知识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




