本文主要是介绍uie模型微调个人总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
技巧:
六月三十号补充,uie处理3000字的政策文件要占用12G左右的内存,uie处理一万字的文件时运行巅峰要占用28G左右内存,各位部署时,注意out of memory的错误,对应万字的超长文本目前只有加内存的解决方案。
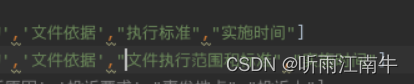
六月二十七号补充,uie的schema定义时尽量一个schema的长度低于7个字,不然有很大概率,模型识别的效果很差,如图:“执行标准”有一个比较好的抽取效果,“文件执行范围和标准”就完全抽不出来,当然我doccano标注数据的schema也是和不同schema之间保持一致的。
为什么能不固定prompt?
传统Prompt模板各有不同,应对少样本能力不一样
UIE用大量数据固定了prompt的构造方式,就是条件加上抽取标签,所以有不固定的特点
标签其实模型压根都没见过,模型照样能看出来
Prompt技巧
1.与原文越相似越好抽
2.尽量符合常识
3.标注的样本尽量要短
训练技巧:
1.预测可以将batch_size设置为2或者更高来提高预测效率
2.uie-tiny 和base效果差距不大,但性能提高巨大
3.需要负样本的
环境配置:
只需要一个paddlepaddle,安装最新版即可,会自动给你安装许多相关包,
openAI尽量不要装在同一个环境,会改变numpy版本导致paddlepaddle不可用
csdn:
pip install paddlepaddle 报错 command ‘/usr/bin/gcc‘ failed with exit code 1 或 command ‘gcc‘ 报错_听雨江南牛的博客-CSDN博客
语料标注:
到目前五月二十四号,doccano已经更新到1.7.0版本,导出已经没有标注消失的问题,但是我手头数据有很多重复数据,我没有二次标注,doccano会以标注空的形式继续导出,但我更希望它忽视掉这些数据,不要导出,我依旧采用程序形式导出
csdn:
doccano标注完后,标注消失问题_听雨江南牛的博客-CSDN博客
项目部署和参数调整
最无脑的环节,全程跟着readme一步步向下执行就可以了,
需要改动一下数据路径:
另外需要改动模型保存和加载的路径,
需要改动用6层的uie-tiny模型,还是调用12层的uie-base,uie-tiny和uie-base效果基本没有差别,但是预测效率高很多,建议uie-tiny
必须改动的: doccano中的:doccano_file 从doccano导出的数据标注文件save_dir: 训练数据的保存目录,默认存储在data目录下finetune中的:train_path`: 训练集文件路径。dev_path`: 验证集文件路径。save_dir`: 模型存储路径,默认为. / checkpoint
可选的: doccano中的:negative_ratio: 负样本与正样本的比例,该参数只对抽取类型任务有效。使用负样本策略可提升模型效果,负样本数量 = negative_ratio * 正样本数量。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]is_shuffle: 是否对数据集进行随机打散,默认为True finetune中的:learning_rate`: 学习率,默认为1e - 5。batch_size`: 批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数,默认为16。max_seq_len`: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。num_epochs`: 训练轮数,默认为100。device`: 选用什么设备进行训练,可选cpu或gpu。model`: 选择模型,程序会基于选择的模型进行模型微调
测试结果在gitee中
不公开,但是94条数据训练完想抽的基本都能抽出来

这篇关于uie模型微调个人总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








