本文主要是介绍2021年上半年二级考试python123试题对应知识点总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
易错题加粗,持续更新
第一套
-
数据库设计包括概念设计(概念结构)、逻辑设计(逻辑结构)和建立数据库(物理结构)。
-
将E-R图转换成关系模式时,实体与联系都可以表示成 关系
-
软件需求分析阶段的主要工作 需求获取、需求分析、需求评审
-
深度为n的满二叉树中,叶子节点数为: 2^(n-1) ,例如:在深度为7的满二叉树中,叶子结点的个数为多少? 2^(7-1)= 2^ 6=64
-
设循环队列的存储空间为Q(1:50),初始状态为front=rear=50。现经过一系列入队与退队操作后,front=rear=1,此后又正常地插入了两个元素。最后该队列中的元素个数为______2个_____。
【解析】front=rear表示此时队列为空,按照严教材,front+1=rear表示队列满。所以,初始状态front=rear=50和经过一系列入队与退队操作后,front=rear=1,其实都是队列为空。当后续又插入了两个元素之后,队列中元素就为新插入的两个元素,有两个。 -
黑盒测试:等价类划分法,边界值分析法,因果图法,错误推测法
-
白盒测试:程序结构分析,逻辑覆盖方测试,基本路径测试
-
概念:
python是通用语言,不是通用网络语言
Python语言的生态库既包括官方开发的,也包括各种开源社区开发的,还有各种厂家开发的、
Python语言是一种面向过程,也是面向对象的语言、
Python语言与平台无关,因为不同平台上有不同的Python解释器,写一套python源代码,在不同的平台上,都可以经由解释器解释执行。
变量长度没有限制✔ -
当用户输入一个整数“6”的时候,input()函数返回的是字符“6”,如果需要整数就需要用eval(input())
-
Python的二进制数是在数值的前面加 0b
-
几种错误的数据类型说法:
函数ord(x)是返回字符串x对应的Unicode编码,如下图可以看到函数ord()返回的是字符的Unicode编码值

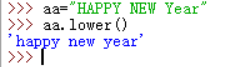
函数lower()和函数upper()能够将字符串所有字符小写或大写(各自对应)
divmod(x,y)的运算结果是一个元组,元组内容是两个整数:x除y的整数商以及余数

-
Python format 格式化函数,参考网址:https://www.runoob.com/python/att-string-format.html
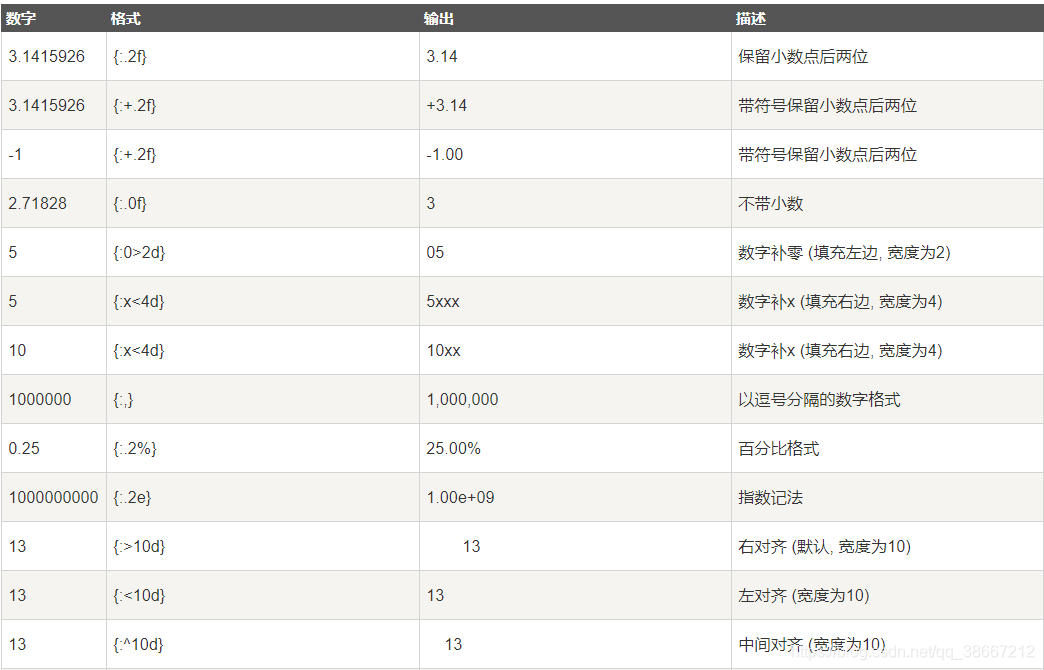
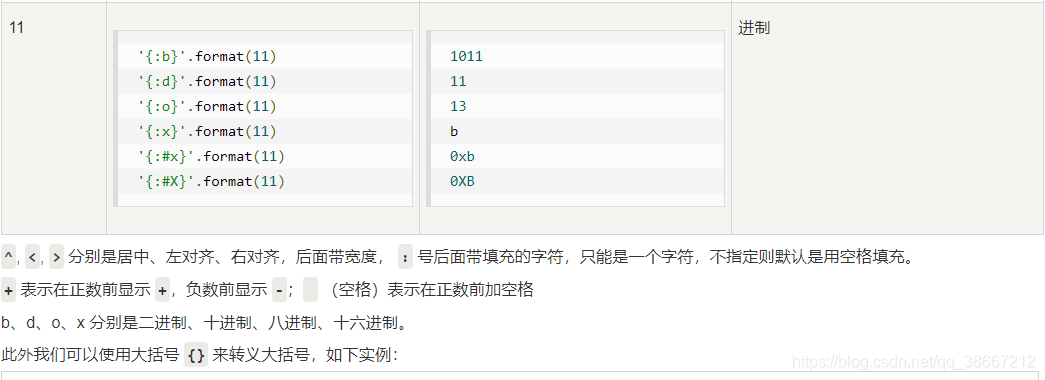
*号表示不限制类型,例如:格式控制信息{:*^10}表示这个位置的宽度为10,不限制数据类型,既可以是字符串,也可以是整数或浮点数 -
两个字符串比较大小,比较的是对应字母的ASCII值。假设x、xy都是字符串,判断x in xy,则要求x的全部都要按在xy中,才返回True
-
调用Python函数的时候,可以指定缺省参数的名称和值,也可以不指定,如果不指定缺省参数的名称和值,就会使用缺省的值。
-
调用函数时,按参数名称传递的参数,要按照定义顺序进行传递 ×
函数调用传递实参方式很多,主要是位置实参和关键字实参,位置实参必须要求一一对应,关键字实参在传递是会写变量名字,因此可以忽略顺序。关键字实参示例:
def fn(a,b,c):print('a =',a)print('b =',b)print('c =',c)fn(b=1,c=2,a=3)
16.一道程序理解题目
def add_Run(L=None):if L is None:L = []L.append('Run')return L
add_Run()
add_Run()
print(add_Run(['Lying']))
思路:当然输出的只有第三次调用函数的时候,但是需要注意的是,函数定义的时候,函数参数是默认参数,但是第三次调用函数的时候没有使用默认的参数,而是使用给定字符串,所以,调用一开始L=‘Lying’,最后输出结果为[‘Lying’,‘Run’].
17.程序理解题目
L = []
x = 3
def pri_val(x): L.append(x) x = 5
pri_val(x)
print('L = {}, x = {}'.format(L, x))
要注意:x是全局变量,函数中的x和全局变量x要区分开,函数外输出的是全局变量x
但如果是if语句改变了全局变量的值 全局变量值也改变
18.正确的切片表达式a:b中,要满足a<b,如果a>=b,则切片的结果返回空;
a、b可以是负数,当它们是负数的时候,确保它们在列表里真实的索引位置,仍然满足a<b,就可以返回有效的元素,否则也会返回空(总结来说就是,确保它们在列表里真实的索引位置,仍然满足a<b就可以正确有结果,无论±)
l = [1,2,3,4,5,6,7]
print(l[3:2])
print(l[-5:-3])
运行结果

最后一次,切片数值来说-3<2,符合要求,但是对应在列表中却不符合,因此仍然返回空字符串。
19.列表的pop操作,是返回列表中的指定位置的元素,所以当参数是0的时候,返回第0个元素,同时列表长度减1.
l = [1,2,3,4,5,6,7]
print(l.pop(0), len(l))
pop(0)是返回列表中0号位置的元素值1
20. popitem(),该函数随机从字典里取出一个键值对,以元组(key, value)的方式返回,同时字典的长度减1,变为3。
ds = {'av':2,'vr':4,'ls':9,'path':6}
print(ds.popitem(), len(ds))
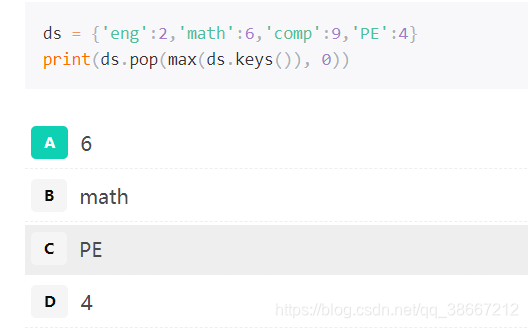
- Ds.Keys()返回字典里所有的key
- max返回其中首字符ascII码最大的key,这里应该是math,比较ASCII码
- Ds.Pop()函数的正常调用方式是Ds.Pop(key, default), 如果字典里存在key的话,返回key所对应的value,如果不存在就返回默认值;
- ‘w’表示写模式打开文件,如果文件存在,就会删除文件已有内容
- ‘a’表示追加模式打开文件,如果文件不存在,就创建一个文件,如果存在就在文件尾追加内容
- ‘b’表示二进制文件模式打开文件,不可以单独作为open函数的参数
23.题目:

read()函数读入后的是字符串,split函数按照‘,’分割字符串后,返回的是被分割后的字符组成的列表
24. readlines(),这个函数一次性读出文件的所有行,以每行作为一个元素,构成一个列表
25. str(aa)当aa只是一个元素的时候,‘;’.join(str(aa))并没有为aa追加上‘;’符号,所以只得到一个单出的数字
例子:
aaa =[8, 5, 2, 2]
with open('output.txt', 'w') as f: for aa in aaa: f.write(';'.join(str(aa)))
aa只是单个字符,所以输出时不加分隔符,输出8522
26. 可用来获取网页内容的Python第三方库是: requests
27. 补充turtle库相关内容:


第二套
- zip():将对象中对应的元素打包成一个个元组
- list():返回一个列表
- round() 方法返回浮点数x的四舍五入值。
x = 520.1314
print(round(x,2),round(x))
520.13
520
-
笛卡尔积的定义是设关系R和S的元数分别是r和s,R和S的笛卡尔积是一个(r+s)元属性的集合,每一个元组的前r个分量来自R的一个元组,后s个分量来自s的一个元组.所以关系T的属性元数是3+4=7.
题目:设关系R和关系S的属性元数分别是3和4,关系T是R与S的笛卡尔积,即T=R×S,则关系T的属性元数是________。 -
数据库的三级模式结构指数据库系统有外模式、模式和内模式3级构成。
数据库管理系统在这3级模式之间提供了两层映射:外模式/模式映射,模式/内模式映射。
这两层映射保证了数据库系统中的数据能够具有较高的逻辑独立性和物理独立性。

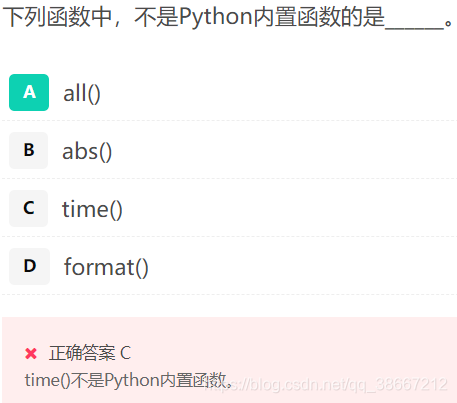
7. Python脚本程序转变为可执行程序的第三方库是 pyinstaller
8. time()不是python 内置函数
9. 引用全局变量,不需要golbal声明,修改全局变量,需要使用global声明,特别地,列表、字典等如果只是修改其中元素的值,可以直接使用全局变量,不需要global声明。
10.想让a.txt结果为‘90’,‘87’,‘93’
y = ['90','87','93']
ls = ''
with open("a.txt","w") as fo:for z in y:ls += "'{}'".format(z) + ','#l += "'{}'".format(z) 缺少分隔符#l =','.join(y) 缺少引号#l +='{}'.format(z)+',' 缺少引号fo.write(ls.strip(","))
关键语句 ls += “’{}’”.format(z) + ‘,’
10. isnumeric()方法语法:如果字符串中只包含数字字符,则返回 True,否则返回 False
11. 字符必须加上引号才合法
>>> str1 = "python"
>>> print(str1.center(10,"*"))
**python**
>>>
>>> print(str1.center(10,*))
SyntaxError: invalid syntax
>>>
- 结构化程序设计方法的主要原则:
自顶向下 逐步细化 模块化 结构化编码
13. pip常用的子命令有:install、download、uninstall、freeze、list、show、search、wheel、hash、completion、help。
14. python程序可以不包含main函数,也可以为main函数更改另外的名字,这个函数和其他函数地位相同
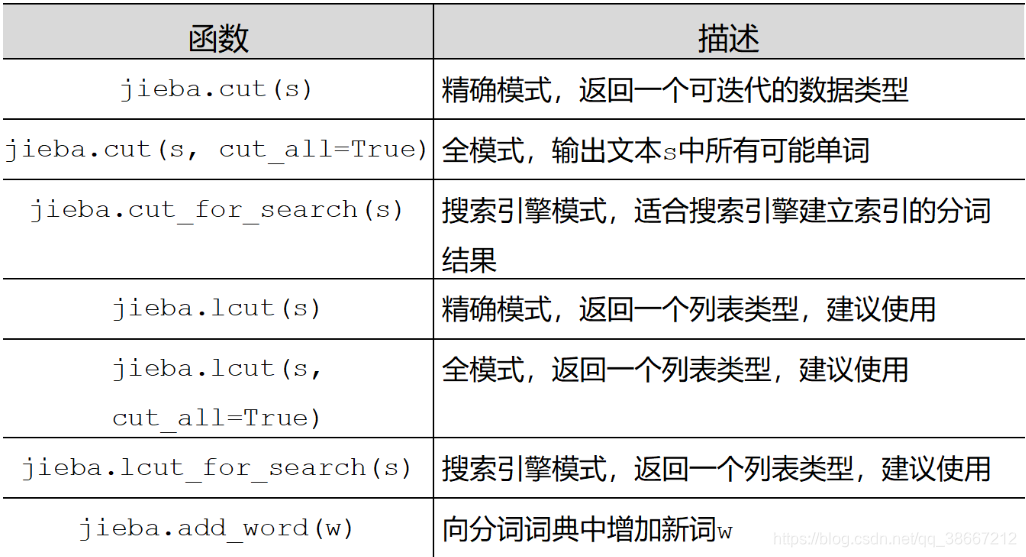
15. jieba库学习:
链接:https://www.cnblogs.com/wkfvawl/p/9487165.html
概述:优秀的中文分词第三方库,提供了三种分词模式:精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
jieba库常用函数:
- 打开文件
with open('data.txt','r',encoding = "utf-8") as f: sl = f.readlines()#print(type(f)) f是<class '_io.TextIOWrapper'>文件句柄的类型
#print(type(sl)) sl是一个列表,包含了文件中每一行内容
#print(type(sl[0])) sl[0]是列表sl中第一个元素,是文件中第一行所有内容
- Python 字典(Dictionary) get()方法
Python 字典(Dictionary) get() 函数返回指定键的值。
语法:dict.get(key, default=None)
参数
- key – 字典中要查找的键。
- default – 如果指定键的值不存在时,返回该默认值。
dk[wo]=dk.get(wo,0)+1 #dk字典中wo为键,get(wo,0)wo为键,对应默认的值为0

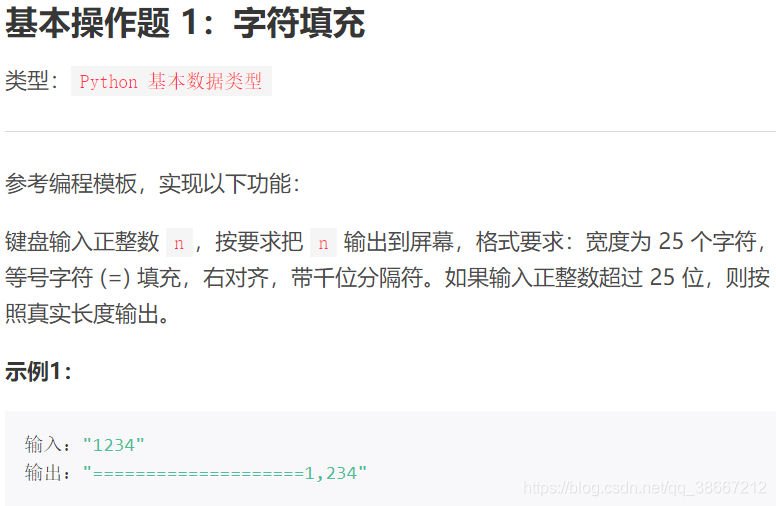
相关代码
print("{:=>25,}".format(eval(s)))
- pow()函数:返回的结果为x的y次方的值
pow(x, y[, z])
函数是计算 x 的 y 次方,如果 z 在存在,则再对结果进行取模,其结果等效于 pow(x,y) %z
第三套

- 链表中,逻辑结果属于非线性结构的是 二叉链表
- 数据库设计中,在需求分析阶段建立数据字典
- 软件测试的目的是发现错误并且改正错误 ❌
软件测试的目的是暴露错误,评价程序的可靠性。软件调试的目的是发现错误的位置,并改正错误。软件测试和调试不是同一个概念。
所以,软件调试的目的才是发现并且改正错误 - 类对象主要特征是 对象唯一性
6. 数据流图中带箭头的线段表示 数据流,程序流程图中箭头表示 控制流 - python的文件操作方法:seek,write,read等,不包含load
- 机器学习领域第三方库pytorch,MXNet,Tensorflow
- Arcade 游戏库
- openpyxl是python语言中文本处理方向的第三方库,PyQt5是Python语言中用户图形界面方向的第三方库
- Beautifulsoup4库,也称为Beautiful Soup库或bs4库,用于解析和处理HTML和XML。
- Python变量名采用大写字母、小写字母、数字、下划线和汉字等字符及其组合进行命名,但是首字母不能是数字
- True是保留字,但是true不是
- zip()函数将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表

zip(x,y)就已经压缩了x和y中所有元素,并且返回元组形式,然后list()函数在元组外边套了一个列表 - 高维数据由键值对类型的数据构成,采用对象方式组织,可以多层嵌套
高维数据适合用字典类型表达 二维数据表示表格类型数据 - &是按位与运算符,&=则是对应的二元操作符。
- 高级语言根据计算机执行机制的不同可分成两类:
静态语言和脚本语言,静态语言采用编译方式执行,脚本语言采用解释方式执行。
C语言是静态编译语言,Python语言是脚本语言
编译是将源代码转换成目标代码的过程
解释是将源代码逐条转换成目标代码同时逐条运行目标代码的过程 - str.strip(chars)表示从字符串str中去掉在其左侧和右侧chars中列出的字符
最左侧和最右侧的字符,不去掉中间的 - **join()**方法用于将序列中的元素以指定的字符连接生成一个新的字符串。二维数据存储为CSV格式,需要将二维列表对象写入CSV格式文件以及将CSV格式读入成二维列表对象。 二维列表对象输出为CSV格式文件方法采用遍历循环和字符串的join()方法相结合。
- 表达式3*42//8%7计算时,先计算xy,因为**运算级别更高
- 设计题
输入一个正整数(范围为65 - 96),请输出对应的 Unicode 字符。
x = eval(input())
print("{:c}".format(x))
c: 表示输出整数和浮点数类型的格式规则,输出数值对应的Unicode字符。
21. 反序字符串的写法是s[::-1]
22. python 中 end="“的意思:
为末尾end传递一个空字符串,这样print函数不会在字符串末尾添加一个换行符,而是添加一个空字符串。
23. random.seed(123)以123作为随机种子
seed()方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数
24. random.randint(a,b)返回一个a至b区间(包含a和b)的整数。
25. split()方法:
split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
语法:str.split(str=”", num=string.count(str))
txt = "Google#Runoob#Taobao#Facebook"# 第二个参数为 1,返回两个参数列表
x = txt.split("#", 1)print (x)
输出:

第四套
- 软件工程的三个要素:方法、工具、过程
- 概念模型面向客观世界和用户,并与具体数据库管理系统无关
- 在读写文件之前,需要打开文件使用的函数是 open而不是fopen
- 易错:

最后输出not found it…因为i是数字类型,‘44’是字符类型 - **replace(old,new)**方法将字符串中的old(旧字符串)替换成new(新字符串),old和new的长度可以不同
- str.split(sep=None):返回一个列表,由str根据sep被分割的部分构成,省略sep默认以空格分割。
str.strip(chars):从字符串str中去掉在其左侧和右侧chars中列出的字符。
str.replace(old,new):返回字符串str的副本,所有old子串被替换为new。
str.center(width,fillchar):字符串居中函数,fillchar参数可选。 - round(x,d):对 x 四舍五入,保留 d 位小数,无参数 d 则返回四舍五入的整数值。
- ls + lt 将两个列表的所有元素合并为一个列表
- 易错
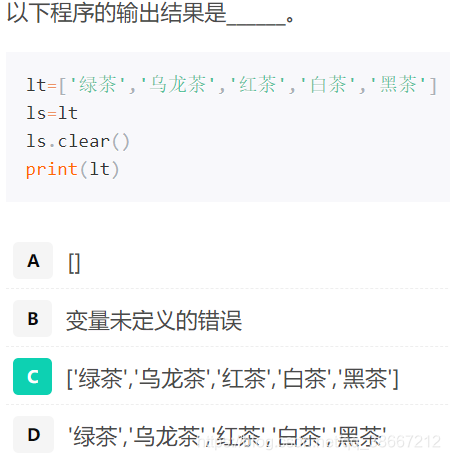
ls.clear():删除 ls 中所有元素。
对于列表元素,直接等号并不能直接赋值,不能产生新列表,而是给原有列表增加了一个新的别名ls,对ls的操作也就是对lt的操作。
第五套
- 数据流图是描述数据处理过程的工具
- 是需求理解的逻辑模型的图形表示
- 它直接支持系统的功能建模,不支持数据建模
- 软件详细设计工具
(1)图形工具:程序流程图、N-S图、PAD图、HIPO图
(2)表格工具:判定表
(3)语言工具:PDL(伪码) - 集成测试是测试和组装软件的过程。它是把模块在按照设计要求组装起来的同时进行测试,主要目的是发现与接口有关的错误。集成测试的依据是概要设计说明书。
- 与确认测试阶段有关的文档是 需求规格说明书
- 数据库的三级模式结构包括:概念模式、内模式、外模式。
概念模式,是数据库系统中全局数据逻辑结构的描述,是全体用户公共数据视图;
外模式也称为子模式或用户模式。它是用户的数据视图,也就是用户所见到的数据模式,它由概念模式推导而出;
内模式又称物理模式,它给出了数据库物理存储结构与物理存取方法。
- 对于关系模式,若其中的每个属性都已不能再分为简单项,则它属于第一范式模式(1NF)。
如果某个关系模式 R 为第一范式,并且 R 中每一个非主属性完全函数依赖于 R 的某个候选键,则称其为第二范式模式(2NF)。
如果关系模式 R 是第二范式,并且每个非主属性都不传递依赖于R的候选键,则称 R 为第三范式模式(3NF)。
比 3NF 更高级的范式是 BCNF,它要求所有属性都不传递依赖于关系的任何候选键。 - 以下的设计准则可以借鉴为设计的指导和对软件结构图进行优化,这些准则为:
①提高模块独立性;
②模块规模适中;
③深度、宽度、扇入和扇出适当;
④使模块的作用域在该模块的控制域内;
⑤应减少模块的接口和界面的复杂性;
⑥设计成单入口、单出口的模块。
⑦设计功能可预测的模块。 - "\0"表示一个空格,长度记为1
- 易错题目:
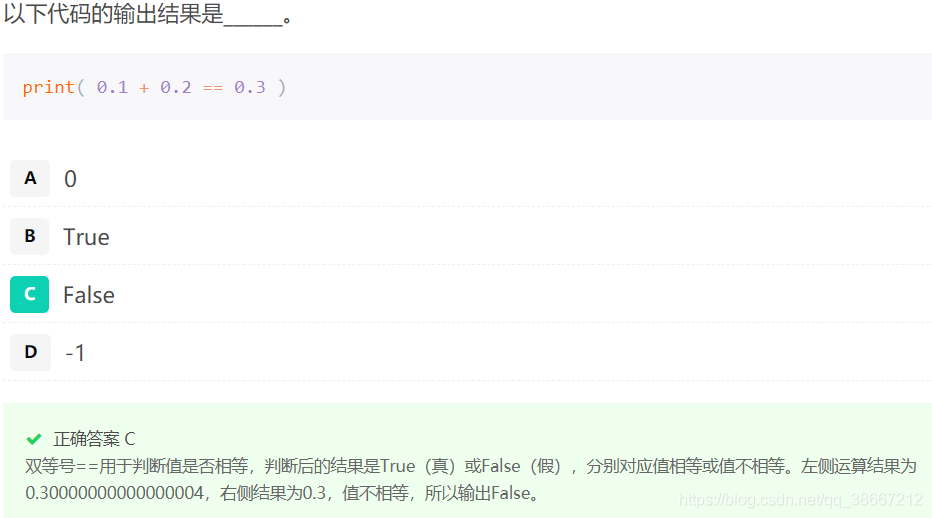
0.1+0.2=0.30000004
s=[4,2,9,1]
s.insert(2,3)
print(s)
s.insert(i,x):在列表第i位置增加元素x。题目中,在2号位置插入数字3,位置标号从0开始。最后结果为[4,2,3,9,1]
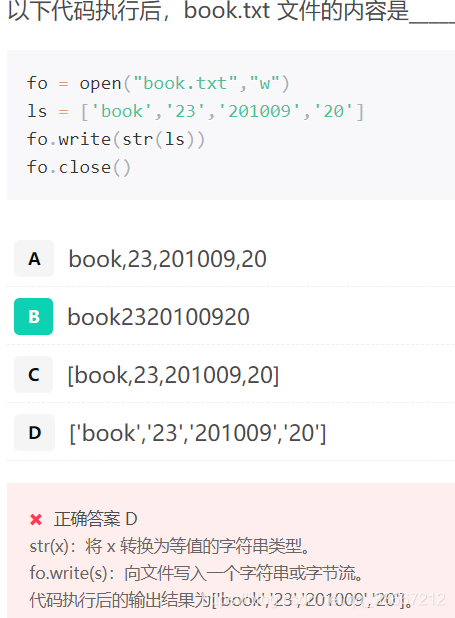
- fo.writelines(lines)方法的含义是将一个元素为字符串的列表整体写入文件。
fo=open("book.txt","w")
ls=['book','23','201009','20']
fo.writelines(ls)
fo.close()
最后输出结果为:book2320100920
- set(x)函数将其他的组合数据类型变成集合类型,返回结果是一个无重复且排序任意的集合。
ss=set("htslbht")
sorted(ss)
for i in ss:print(i,end='')
- https://www.runoob.com/python/python-func-all.html
第六套
- 扇入:调用一个给定模块的模块个数。
扇出:一个模块直接调用的其他模块数。
原子模块:树中位于叶子结点的模块。 - 结构图描述软件系统的层次和分块结构关系,它反映了整个系统的功能实现以及模块与模块之间的联系与通信,是未来程序中的控制层次体系。
- 详细设计的任务,是为软件结构图中的每一个模块确定实现算法和局部数据结构,用某种选定的表达工具表示算法和数据结构的细节。
- 软件测试的目的就是尽可能多地发现程序中的错误。
- 软件测试的对象包括:源程序、目标程序、数据及相关文档。‘
- 循环链表是另一种形式的链式存储结构。它的特点是表中最后一个结点的指针域指向头结点,整个链表形成一个环
- 白盒测试把测试对象看作一个打开的盒子,允许测试人员利用程序内部的逻辑结构及有关信息来设计或选择测试用例,对程序所有的逻辑路径进行测试。白盒测试从检查程序的逻辑着手,可以把白盒测试理解为"内行人"进行软件测试。
- 软件概要设计的基本任务包括:设计软件系统结构;数据结构及数据库设计;编写概要设计文档;概要设计文档评审。
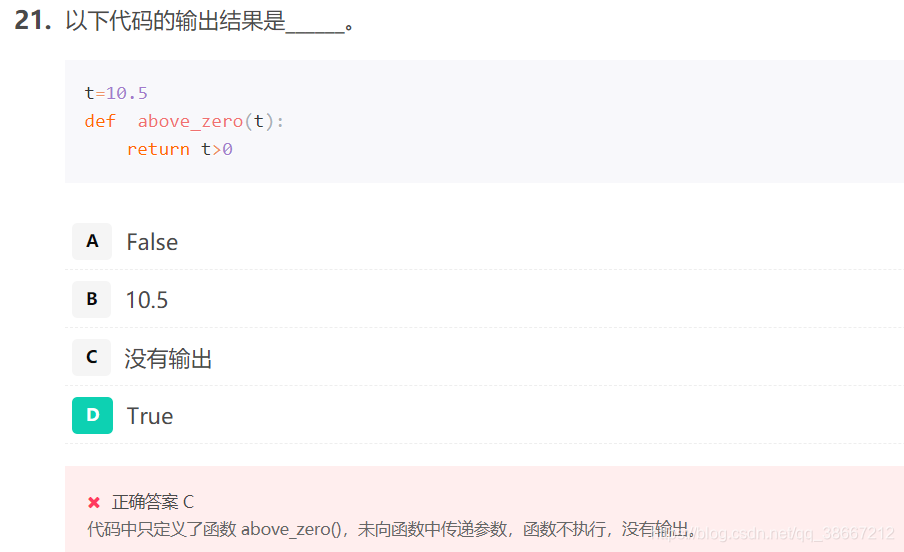
- 函数中可以有多个 return 语句。
函数可以没有 return,此时函数不返回值。当函数使用 return 返回多个值时,可以使用一个变量或多个变量保存结果。 - 并没有调用函数
- str.replace(old,new):返回字符串 str 的副本,所有 old 子串被替换为 new。原来的字符串并不改变
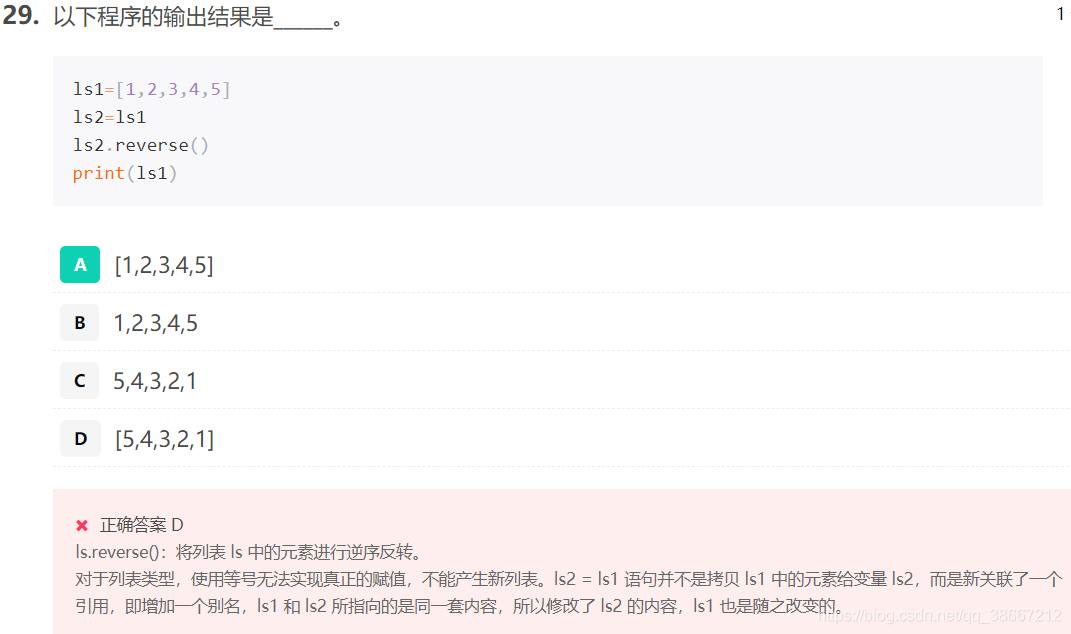
对于列表来说,等号不是赋值的意思,而是关联了一个新的引用,增加了一个别名- all(x):组合类型变量x中所有元素都为真时返回 True,否则返回 False;若 x 为空,返回 True。
any(x):组合类型变量 x 中任一元素都为真时返回True,否则返回 False;若 x 为空,返回 True。
y=['','']
print(all(y),any(y))
输出: False False
- random 库采用更多随机数生成算法是 梅森旋转算法
- turtle.setup():设置主窗体的大小和位置
turtle.penup():提起画笔
turtle.clear():清空当前窗口,但不改变当前画笔的位置
turtle.done() 画图结束后,让画面停顿,不立即关掉窗口的方法是
第七套
- 在任意二叉树中,度为 0 的结点即叶子结点总是比度为 2 的结点多一个。
- 在线性表中寻找最大项时,除了最大项本身以外,其余所有项都需要和相邻的数据进行比较,所以需要比较的次数至少是 n-1。
- 二叉树是非线性结构,而完全二叉树是特殊形态的二叉树。
- 希尔排序的时间复杂度与增量序列的选取有关,最坏情况下比其他三项排序更快。
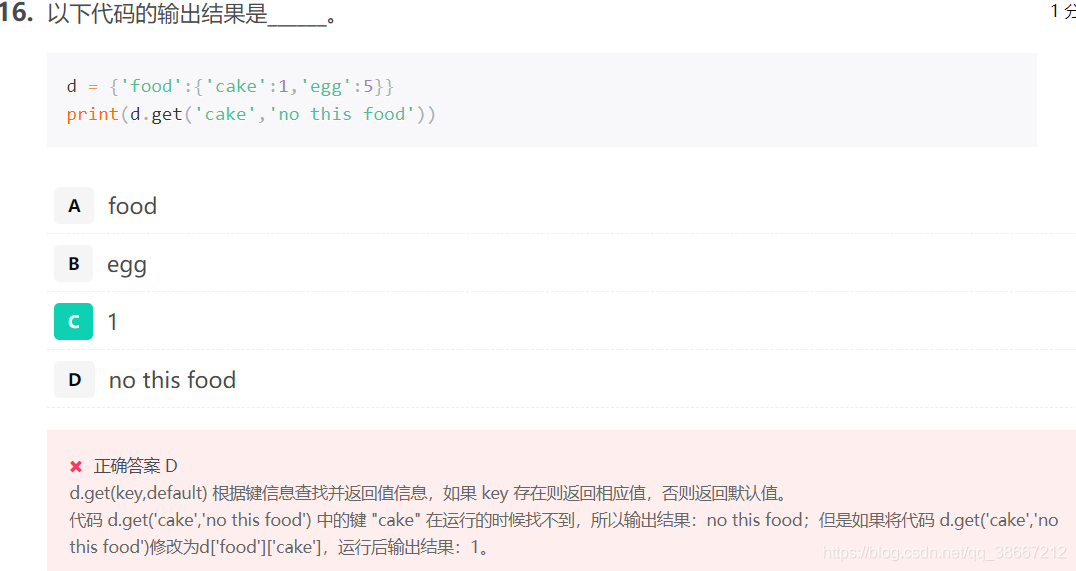
- 当文件以文本方式打开时,读写按照字符串方式;当文件以二进制方式打开时,读写按照字节流方式。
python能够以文本和二进制两种方式处理文件
- 文件包括文本文件和二进制文件两种类型。文本文件一般由单一特定编码的字符组成,如 UTF-8 编码,内容容易统一展示和阅读。二进制文件直接由比特 0 和比特 1 组成,没有统一的字符编码。
- 逗号分隔的存储格式叫做 CSV 格式,是一种通用的、相对简单的文件格式。
- 使用time.time()获取当前时间戳,返回值为数字形式。
- **close()**不是 Python 内置函数。
- NLTK:自然语言处理工具包
Luminoth:计算机视觉工具包
redis-py:用于数据存储领域的python第三方库 - 网络爬虫领域:Scrapy、Requests、PySpider。
SnowNLP 用于处理中文文本内容。 - Web 开发方向:Tornado、Pyramid、Django。
BeautifulSoup 不属于web开发框架的python第三方库
这篇关于2021年上半年二级考试python123试题对应知识点总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







