本文主要是介绍网信内容安全实验三笔记(python实现文本分类),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:作为实验笔记,部分资料和图片选自浩瀚网络,侵权必删
任务一:
1.使用逻辑斯蒂回归做二分类
2.SGD随机梯度下降算法
3.采用正则化
先导入几个常用的机器学习的库
import pandas as pd
import numpy as np
import numpy.random
from scipy.sparse import csr_matrix
获取数据集(特征和标签都是由实验一获得,其中特征是实验一中的Headline域经过处理,标签是实验一中的Topic域)
处理数据集 ( 计算tfidf为特征向量)
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
#制造数据集,内容为tf/df
def doatxt():data_set = []with open("simple.txt","r") as file:data_set = file.readlines() # 调用文件的 readline()方法 #测试成功print(data_set[0]+data_set[1])countfidf = TfidfVectorizer()tfidf = countfidf.fit_transform(data_set)data_tfidf=tfidf.toarray()#print(tfidf)#print(data_tfidf[3][1031])#稀疏向量变成普通矩阵,太大了出了点问题,导致以为输出全0,事实上经过验证不是全0return (tfidf,data_tfidf,data_set)
#读label.txt进入test列表
with open("label.txt", "r") as file:ls=[]for line in file:line=line.strip('\n') #将\n去掉ls.append(line.split(' ')) #将空格作为分隔符将一个字符切割成一个字符数组ls=np.array(ls) #将其转换成numpy的数组
#测试成功print(ls[3][0]) #第i行数据ls[i][0]test=[]
for i in range(1000):test.append(ls[i][0])#化成一维 print(test)
#测试成功print("\n"+ test[3])for i in range(1000):if(test[i]== "economy"):test[i]=1else: test[i]=0
#测试成功print(test[3])doatxt()
#数据处理完毕
前面是实验一未完成的部分,下面进入正题
首先,定义M值(特征向量的长度),特征权重向量,和步长
m = 100#暂定100之后改1000
#生成一个w随机数矩阵
theta=np.random.rand(m,1) #返回[0, 1)之间的随机浮点数矩阵。size为int型
#print(theta.T)
learning_rate = 0.01
随机切割数据集
from sklearn.model_selection import train_test_split
#切割数据集,分为训练集和测试集
#切分训练集和测试集
c1,c2,c3=doatxt()
c1=c1[:,:m]
#print(c2)
x_train, x_test, y_train, y_test = train_test_split(c1, test, test_size=0.25, random_state=42)
运用逻辑回归实现分类问题
1.逻辑回归

在sklearn中的类

导入相关的包
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
LogisticRegression是逻辑回归模型,共14个参数,具体含义LogisticRegression参数
classification_report是分类报告,具体介绍classification_report简介
#逻辑回归
logitmodel=LogisticRegression()#定义回归模型
logitmodel.fit(x_train,y_train)#训练模型
#print(x_test.shape)
print(classification_report(y_test,logitmodel.predict(x_test)))
#(1) 其中列表左边的一列为分类的标签名,右边support列为每个标签的出现次数.avg / total行为各列的均值(support列为总和).
#(2) precision recall f1-score三列分别为各个类别的精确度、召回率、 F1值
结果

2.SGD随机梯度下降和正则化

正则化

官方解释

SGDClassifier参数含义:

导入相关的包
from sklearn.linear_model import SGDClassifier
#随机梯度下降SGD(逻辑斯蒂损失函数,正则化用的L2规范)
clf = SGDClassifier(loss="log", penalty="l2", max_iter=5)#log代表逻辑斯蒂,l2代表正则项选则二范数平方,max_iter是算法收敛的最大迭代次数
clf.fit(x_train,y_train)
print(classification_report(y_test,clf.predict(x_test)))
#classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息


通过两次实验的结果对比可以发现,随机梯度和正则化后的逻辑回归准确率更高了
任务二:
使用卡方检验选择N个特征(如N=100)
使用交叉验证选择正则化的系数,并输出每一个测试样本的预测类别值并分类评估:准确率、召回率和F-Score
多类分类,只考虑Microsoft, economy, Obama, Palestine四类,其他不考虑
1.卡方检验-特征选择
卡方公式

具体内容指路卡方检验
在sklearn.feature_selection中,用到chi2时,在fit时需要传入X、y,计算出来的卡方值是 单个特征变量对目标变量y的卡方值
feature_selection.SelectKBest([score_func,k]):根据k个最高得分选择特征
还可以查看特征得分和p值(.scores和.pvalue)
这里的pvalue应该也是单个特征的p值

导入库
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
卡方检验特征选择
#卡方检验 这里使用时记得将前面截取前n个特征的命令去掉
model1 = SelectKBest(chi2, k=m)#选择k个最佳特征
x_train_new=model1.fit_transform(x_train, y_train)#该函数可以选择出k个特征
suoyin=model1.fit(x_train,y_train).get_support(indices=True)
#print(suoyin)
#print(x_test.shape)
xT=x_test.T
xT=xT[suoyin][:]#经过多次试验,这个索引只能选行,所以要先转置了(可能有别的方法没找到吧)
x_test_new=xT.T
clf = SGDClassifier(loss="log", penalty="l2", max_iter=1000)
clf.fit(x_train_new,y_train)
print(classification_report(y_test,clf.predict(x_test_new)))
结果

2.交叉验证选择正则化的系数,并输出每一个测试样本的预测类别值并分类评估:准确率、召回率和F-Score
上一次实验的交叉验证要求:

官网资料:


c是惩罚参数,也就是题目所说的正则项系数的倒数,按照题目要求分别设置0.1,0.2,0.3…1这10个数值,取得分最小的c值

导入库
from sklearn import svm
from sklearn.model_selection import cross_val_score开始循环
accuracy_a=0.0#准确率,选最大
loss_a=1.0#损失函数值 选最小
for i in [0.00001,0.0001,0.001,0.01,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1]: clf = SGDClassifier(loss="log", penalty="l2",max_iter=1000,alpha=i) #这里的alpha是惩罚参数不是步长 accuracy = cross_val_score(clf, x_train_new, y_train, cv=5,scoring='accuracy')#cv=5表示5折#这里注意用的是训练数据集#loss = cross_val_score(clf, x_train, y_train, cv=5,scoring='neg_log_loss')#用损失函数最小 选择if(accuracy.mean()>accuracy_a):accuracy_a=accuracy.mean()aaa=iprint("Accuracy: %0.2f (+/- %0.2f)" % (accuracy.mean(), accuracy.std() * 2))#测试成功,选准确率最大的#if(loss.mean()<loss_a):# loss_a=loss.mean()# aaa=i#print("Loss: %0.2f (+/- %0.2f)" % (loss.mean(), loss.std() * 2))#测试成功,选损失函数最小的print("c: %0.5f"% aaa)#输出选择的惩罚参数
分类评估即加入选出的惩罚参数上面的代码再来一次
clf = SGDClassifier(loss="log", penalty="l2", max_iter=1000,alpha=aaa)#这里的alpha不是指步长而是惩罚参数,即正则项系数的倒数
clf.fit(x_train_new,y_train)
print(classification_report(y_test,clf.predict(x_test_new)))
结果如下:

还可以尝试一个这个函数:

3.多类分类,只考虑Microsoft, economy, Obama, Palestine四类,其他不考虑
在test处理前对原始标签备份
testmore=test[:]#多分类备用,切片产生新对象
#多分类
for i in range(1000):if(testmore[i]== "microsoft"):testmore[i]=0elif(testmore[i]== "economy"):testmore[i]=1elif(testmore[i]== "obama"):testmore[i]=2elif(testmore[i]== "palestine"):testmore[i]=3
#print(testmore[:20])
x_train, x_test, y_train, y_test = train_test_split(c1, testmore, test_size=0.25, random_state=42)model = LogisticRegression()
model.fit(x_train, y_train)
print(classification_report(y_test,logitmodel.predict(x_test)))

怀疑是样本数量太少才会出现问题
将样本数量由1000扩充到10000试试

可以发现虽然几个分类结果都可以显示出来,但是2,3的各个数据还是为0
这里有一些警告,可以按照它的指示操作一番
model = LogisticRegression()
model.fit(x_train, y_train)
clf = SGDClassifier(loss="log", penalty="l2", max_iter=1000)#log代表逻辑斯蒂,l2代表正则项选则二范数平方,max_iter是算法收敛的最大迭代次数
clf.fit(x_train,y_train)
print(classification_report(y_test,clf.predict(x_test)))
加入梯度下降就可以了(迭代次数1000)虽然还有警告,但结果显示正常
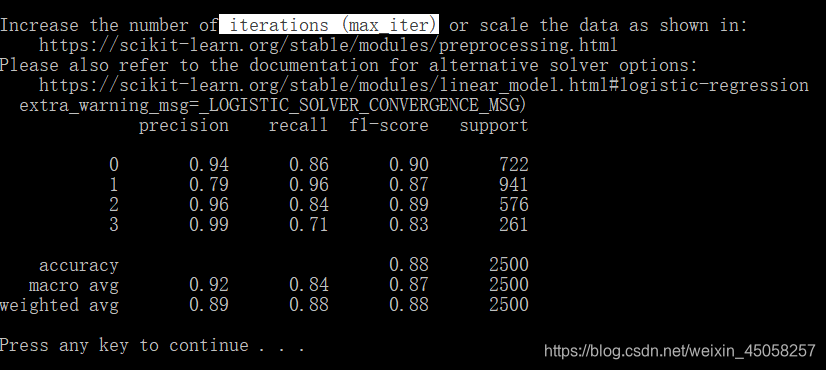
后面可以尝试调一些参数观察
任务三:实验报告
1 随机梯度下降算法
画图给出交叉验证过程中损失函数的变化
import matplotlib.pyplot as plt
alpha_range=[0.00001,0.0001,0.001,0.01,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1]
log_scores = [] #用来放每个模型的结果值
loss = cross_val_score(clf, x_train, y_train, cv=5,scoring='neg_log_loss')#用损失函数最小 选择 很奇怪会得到负值log_scores.append(loss.mean())
plt.plot(alpha_range,log_scores)
plt.xlabel('alpha')
plt.ylabel('Loss') #化出损失函数变化的图像
plt.show()

这里可能有问题,感觉怪怪的
2 特征选择
提供一个表格,给出卡方检验分值最高的十个词语(不是ID,是词语的原词)
把卡方检验代码中的改成10,然后获得索引,根据索引得到k最高的10个词语
ls=np.array(ls) #将其转换成numpy的数组
#测试成功print(ls[3][0]) #第i行数据ls[i][0]#读out.txt进入dic列表
with open("out.txt", "r") as file:dic=[]for line in file:line=line.strip('\n') #将\n去掉dic.append(line.split(' ')) #将空格作为分隔符将一个字符切割成一个字符数组dic=np.array(dic) #将其转换成numpy的数组
print(suoyin)
#print(x_test.shape)
kmax=dic[suoyin]
print(kmax)

3 实验结果与分析
如果完成了二分类问题:提供一个3列表格,展示不同的正则化系数下的分类结果(召回率,精度,Fscore)。
print("二分类不同正则项系数:")
for i in [0.00001,0.0001,0.001,0.01,0.1,1]:clf = SGDClassifier(loss="log", penalty="l2", max_iter=1000,alpha=i)#log代表逻辑斯蒂,l2代表正则项选则二范数平方,max_iter是算法收敛的最大迭代次数clf.fit(x_train,y_train)print("正则项系数为%0.5f时:\n"%i)print(classification_report(y_test,clf.predict(x_test)))

如果完成了多分类问题:提供两个表格,分别是二分类下和多分类下对Economy类的分类结果(召回率,精度,Fscore),并比较二分类和多分类的效果好坏

关于本实验的一些包和模块,官网上可以找到具体的源代码和用户指南,可以帮助更好理解
PS:真的感觉越做越不对劲,就这样先~
这篇关于网信内容安全实验三笔记(python实现文本分类)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






