本文主要是介绍并发工具类:使用线程池有什么好处?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

使用工具类创建线程池
上一节我们已经自己实现了一个线程池,本节我们看看JDK提供的线程池是如何实现的?
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
其实JDK提供的线程池创建和执行过程和我们的基本一样。你看构造函数都一摸一样
参数| 含义 |
- | :-: |
corePoolSize| 核心线程数|
maximumPoolSize|最大线程数 |
keepAliveTime| 非核心线程的空闲时间|
TimeUnit| 空闲时间的单位 |
BlockingQueue<Runnable>| 任务队列|
ThreadFactory| 线程工厂 |
RejectedExecutionHandler| 拒绝策略|
可能由于创建线程池太麻烦了,JDK提供了一个Executors工具类,帮我们快速创建各种各样的线程池
方法| 特点 |
- | :-: | -:
newCachedThreadPool | 可缓存线程池,线程池长度超过处理需要,可回收线程,线程池为无限大,当执行第二个任务的时候,第一个任务已经完成,会复用第一个任务的线程,而不用重新创建|
newFixedThreadPool | 定长线程池,可控制线程最大并发数,超出的线程会在队列中等待 |
newScheduledThreadPool | 定长线程池,支持定时及周期性任务执行 |
newSingleThreadExecutor | 单例线程池,用唯一的工作线程执行任务,保证所有任务按照指定顺序执行(FIFO或者LIFO) |
根据描述你能猜一下他们构造函数中设置的7个属性分别是啥吗?
如果猜对了,那你对线程池已经掌握的很熟练了
我们来演示一下这几个方法
public class Task extends Thread{@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + " is running");try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}
}
public class TestCachedThreadPool {public static void main(String[] args) {ExecutorService executorService = Executors.newCachedThreadPool();for (int i = 0; i < 5; i++) {Task task = new Task();executorService.execute(task);}//pool-1-thread-1 is running//pool-1-thread-5 is running//pool-1-thread-2 is running//pool-1-thread-4 is running//pool-1-thread-3 is running//必须显式结束,不然程序永远不会结束executorService.shutdown();}
}
这个看起来好像没有用到线程池,其实是因为没有可复用的线程,所以就一直创建新的线程了
public class TestFixedThreadPool {public static void main(String[] args) {ExecutorService executorService = Executors.newFixedThreadPool(2);for (int i = 0; i < 5; i++) {Task task = new Task();executorService.execute(task);}//pool-1-thread-1 is running//pool-1-thread-2 is running//pool-1-thread-1 is running//pool-1-thread-2 is running//pool-1-thread-1 is runningexecutorService.shutdown();}
}
public class TestScheduledThreadPool {public static void main(String[] args) {ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);//任务,第1次任务延迟的时间,2次任务间隔时间,时间单位executorService.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {System.out.println("task 1 " + System.currentTimeMillis());}}, 1, 5, TimeUnit.SECONDS);//两者互不影响executorService.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {System.out.println("task 2 " + System.currentTimeMillis());}}, 1, 2,TimeUnit.SECONDS);//task 1 1521949174111//task 2 1521949174112//task 2 1521949176106//task 2 1521949178122//task 1 1521949179104//task 2 1521949180114}
}
public class TestSingleThreadExecutor {public static void main(String[] args) {ExecutorService executorService = Executors.newSingleThreadExecutor();for (int i = 0; i < 5; i++) {Task task = new Task();executorService.execute(task);}//pool-1-thread-1 is running//pool-1-thread-1 is running//pool-1-thread-1 is running//pool-1-thread-1 is running//pool-1-thread-1 is runningexecutorService.shutdown();}
}
既然是工具类,肯定内置了各种参数的实现,比如,ThreadFactory(线程工厂类),RejectedExecutionHandler(拒绝策略)
先来看ThreadFactory的实现
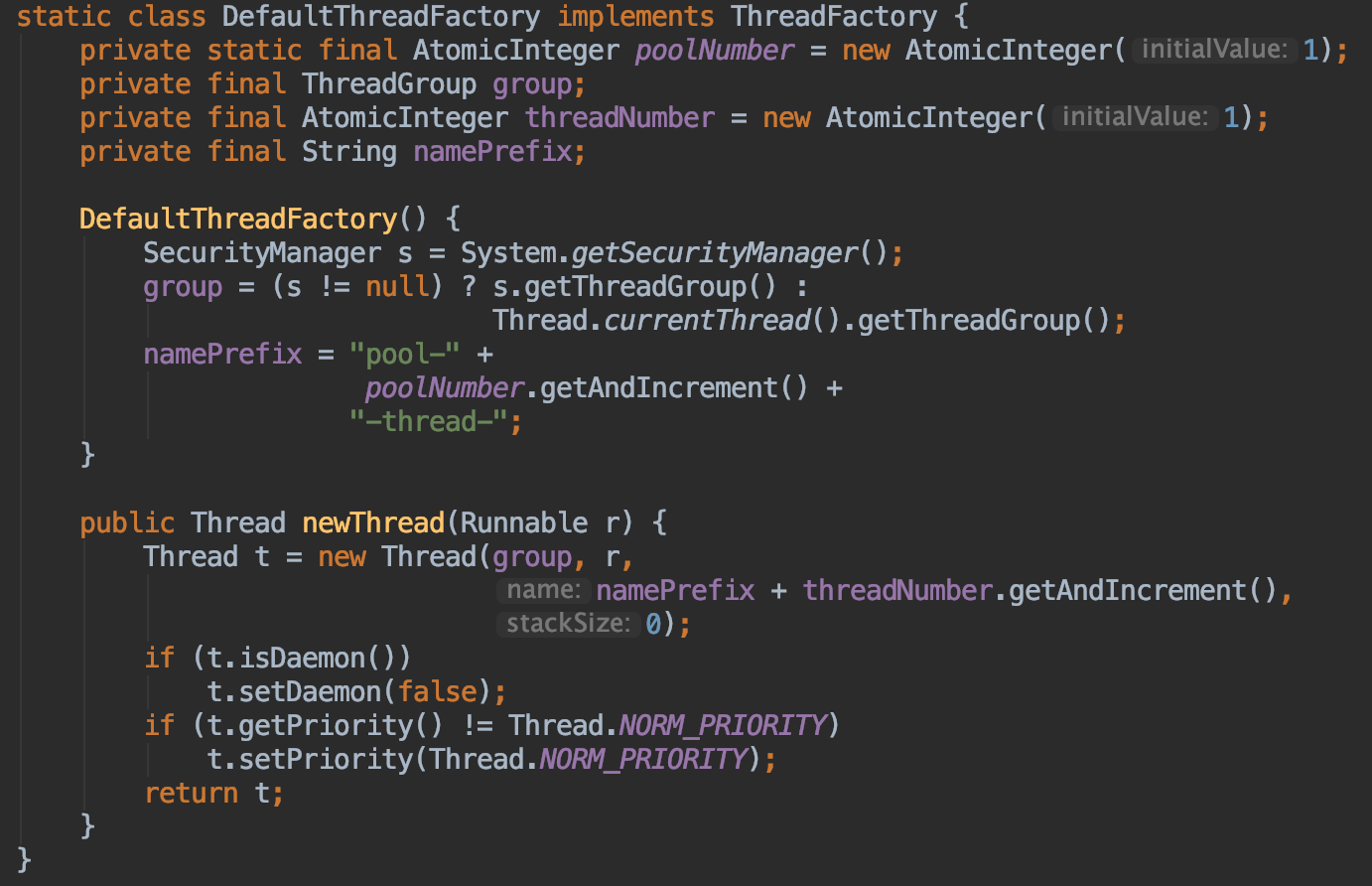
设置了一下线程的名字和优先级等。
接着看RejectedExecutionHandler,Executors内置了四种实现
类| 策略 |
- | :-: |
AbortPolicy| 丢弃任务,抛运行时异常(默认的处理策略)|
CallerRunsPolicy|用放任务的线程执行任务(相当于就是同步执行了) |
DiscardPolicy| 忽视,什么都不会发生 |
DiscardOldestPolicy| 丢弃队列里最近的一个任务,并执行当前任务 |
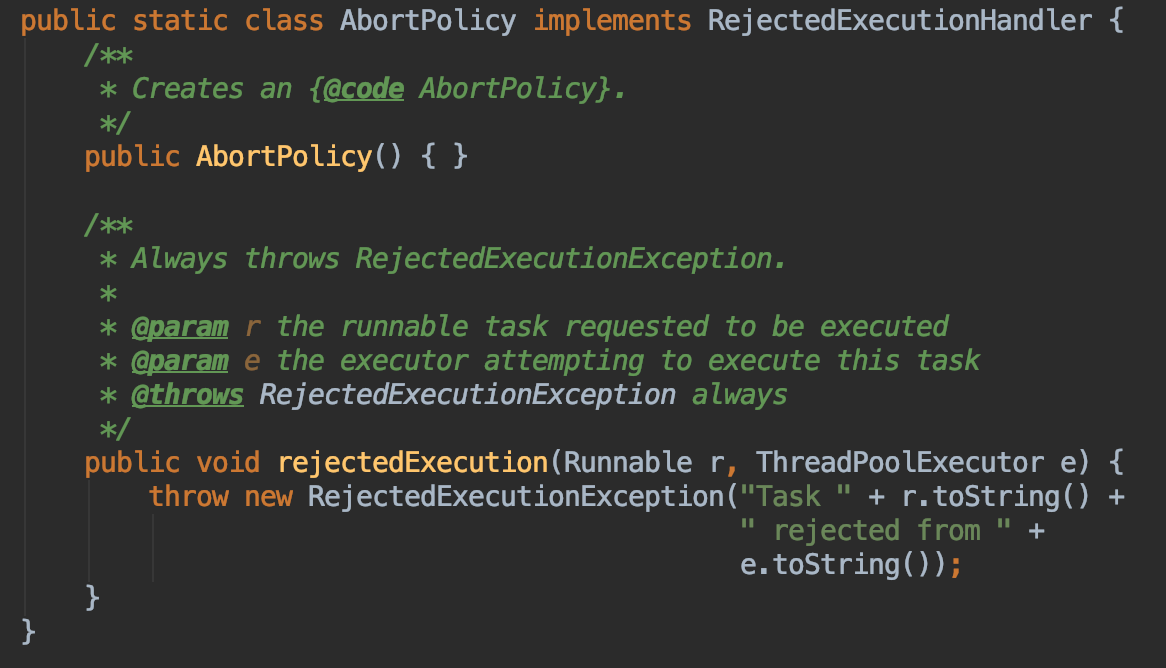
执行任务
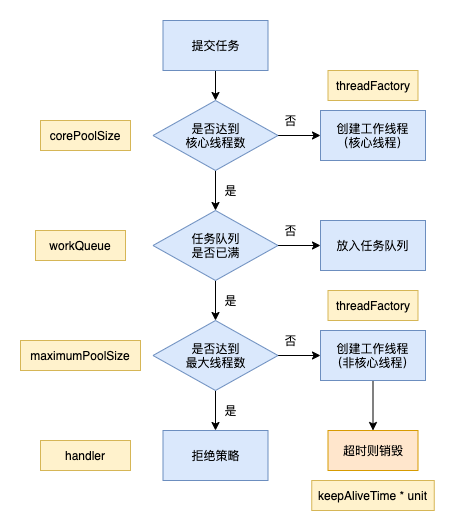
- 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行他们。
- 当调用execute()方法添加一个任务时,线程池会做如下判断:
a)如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务
b)如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列
c)如果这时候队列满了,而且正在运行的线程数量小于maximunPoolSize,那么还是要创建非核心线程立刻运行这个任务
d)如果队列满了,而且正在运行的线程数量大于或等于maximunPoolSize,那么线程池会根据拒绝策略来处理任务 - 当一个线程完成任务时,它会从队列中取下一个任务来执行
- 当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小
public void execute(Runnable command) {if (command == null)throw new NullPointerException();int c = ctl.get();// 当前线程数 < corePoolSizeif (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}// 线程池处于RUNNING状态,并且任务成功放入阻塞队列if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))reject(command);// 线程池处于RUNNING状态,但是没有线程,创建线程else if (workerCountOf(recheck) == 0)addWorker(null, false);}else if (!addWorker(command, false))// 队列满了,根据拒绝策略处理任务reject(command);
}
执行到addWorker(null, false)这个方法说明,任务刚来的时候核心线程都在工作,结果它就被放到阻塞队列中了,然后核心线程都执行完了(并且都被销毁了),如果不调用一下这个方法,则放到阻塞队列中的任务就不会被执行
核心线程不是一直都存在的吗?为什么会被销毁了,这还得从一个属性allowCoreThreadTimeOut说起,这个属性默认是false,意思是核心线程不会被销毁,如果设置为ture,则在workQueue为空的时候,核心线程有可能全被销毁了
addWorker实现
在看addWorker方法之前,我们先看一个例子,了解一下retry的使用
- break retry 跳到retry处,且不再进入循环
- continue retry 跳到retry处,且再次进入循环
public static void main(String[] args) {breakRetry();continueRetry();
}private static void breakRetry() {int i = 0;retry:for (; ; ) {System.out.println("start");for (; ; ) {i++;if (i == 4)break retry;}}//start 进入外层循环//4System.out.println(i);
}private static void continueRetry() {int i = 0;retry:for(;;) {System.out.println("start");for(;;) {i++;if (i == 3)continue retry;System.out.println("end");if (i == 4)break retry;}}//start 第一次进入外层循环//end i=1输出//end i=2输出//start 再次进入外层循环//end i=4输出//4 最后输出System.out.println(i);
}
这里说一下Runnable 参数的含义
- firstTask != null 说明任务被添加了,我们需要启动一个线程去执行它
- fistTask == null 说明我只想启动一个线程去消费阻塞队列中的任务
// core为ture表示是核心线程,否则非核心线程
private boolean addWorker(Runnable firstTask, boolean core) {retry:for (;;) {int c = ctl.get();int rs = runStateOf(c);// Check if queue empty only if necessary./*** 将条件改为如下形式,方便理解* rs >= SHUTDOWN && (rs != SHUTDOWN || fistTask != null || workQueue.isEmpty)* 1.如果当前线程池的状态>SHUTDOWN,addWorker返回false,添加任务失败* 2.如果当前线程池的状态=SHUTDOWN,分为如下2种情况* (1)workQueue为空,fistTask == null 和fistTask != null的任务都不能* (2)workQueue不为空,可以添加fistTask != null的任务*/if (rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty()))return false;for (;;) {int wc = workerCountOf(c);if (wc >= CAPACITY ||// 1.是核心线程 >= corePoolSize// 2.非核心线程 >= maximumPoolSizewc >= (core ? corePoolSize : maximumPoolSize))return false;// 成功将线程数+1,跳到retry处,并且不再进入死循环if (compareAndIncrementWorkerCount(c))break retry;// 否则重新读取ctlc = ctl.get(); // Re-read ctl// 线程状态发生改变,跳到retry处,并且进入死循环if (runStateOf(c) != rs)continue retry;// else CAS failed due to workerCount change; retry inner loop}}// 线程是否启动的标志位boolean workerStarted = false;// 线程封装成Worker对象,是否添加到线程池中的标志位boolean workerAdded = false;Worker w = null;try {w = new Worker(firstTask);final Thread t = w.thread;if (t != null) {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// Recheck while holding lock.// Back out on ThreadFactory failure or if// shut down before lock acquired.int rs = runStateOf(ctl.get());// 1.rs < SHUTDOWN 即 rs = RUNNING// 2.rs == SHUTDOWN && firstTask == nullif (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {if (t.isAlive()) // precheck that t is startablethrow new IllegalThreadStateException();workers.add(w);int s = workers.size();// 刷新了largestPoolSizeif (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {mainLock.unlock();}if (workerAdded) {// 留心一下这里,后面会从这里开始讲起t.start();workerStarted = true;}}} finally {if (! workerStarted)addWorkerFailed(w);}return workerStarted;
}
仔细理解一下这段代码,其实就能理解,当线程池处于RUNNING 接受新任务,并且处理进入队列的任务,处于SHUTDOWN 不接受新任务,处理进入队列的任务,剩余状态都不会处理任务
if (rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty()))return false;线程池在执行任务的时候,会把任务对象包装成一个Worker对象,Worker对象是ThreadPoolExecutor的一个内部类,继承了AbstractQueuedSynchronizer,实现了一个独占锁,status值为0表示未锁定状态,status值为1表示锁定状态,实现了Runnable接口,在执行run方法的时候,它执行完初始化的firstTask后,还会从workQueue中取出任务执行,这样就不用新建一个线程执行任务,而是在一个线程中执行了好几个任务
Worker内部类
// 省略了一部分对锁的操作,简单的对AQS的一个实现
private final class Workerextends AbstractQueuedSynchronizerimplements Runnable
{/** Thread this worker is running in. Null if factory fails. */final Thread thread;/** Initial task to run. Possibly null. */Runnable firstTask;/** Per-thread task counter */volatile long completedTasks;/*** Creates with given first task and thread from ThreadFactory.*/Worker(Runnable firstTask) {setState(-1); // inhibit interrupts until runWorkerthis.firstTask = firstTask;this.thread = getThreadFactory().newThread(this);}/** Delegates main run loop to outer runWorker */public void run() {runWorker(this);}}
runWorker实现
当t.start()被执行后,run方法会执行runWorker方法,来看runWorker方法
final void runWorker(Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;// 允许中断w.unlock(); // allow interrupts// 标识线程是不是异常终止的boolean completedAbruptly = true;try {// 先执行初始化的fistTask,执行完成后还会无限循环获取workQueue里的任务来执行while (task != null || (task = getTask()) != null) {w.lock();// If pool is stopping, ensure thread is interrupted;// if not, ensure thread is not interrupted. This// requires a recheck in second case to deal with// shutdownNow race while clearing interrupt// 配合shutdownNow 方法if ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {// 线程开始开始执行之前执行此方法beforeExecute(wt, task);Throwable thrown = null;try {task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {// 线程执行后执行afterExecute(task, thrown);}} finally {// 运行过的置为nulltask = null;w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly);}
}
这个方法需要注意的就是
- getTask()从阻塞队列中获取任务,如果队列中没有任务会被阻塞,并不会占用CPU资源
- 可以根据业务需要自定义beforeExecute和afterExecute方法
getTask实现
private Runnable getTask() {// 标记获取头结点并且移除头结点的方法是否超时boolean timedOut = false; // Did the last poll() time out?for (;;) {int c = ctl.get();int rs = runStateOf(c);// Check if queue empty only if necessary.// 1.rs >= STOP// 2.rs == SHUTDOWN && workQueue.isEmpty()if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {// 用CAS将线程池中的数量-1,直到成功才会退出decrementWorkerCount();return null;}int wc = workerCountOf(c);// Are workers subject to culling?// 1.核心线程允许被销毁// 2.核心线程数 > corePoolSizeboolean timed = allowCoreThreadTimeOut || wc > corePoolSize;// 1.timeOut为true,表示超时获取,workQueue没有任务,说明线程应该被销毁,但是还是要 && timed// 2.wc > maximumPoolSize肯定要删除线程了// 3.workQueue为空可以销毁线程,此时有可能所有线程都被销毁了// 4.workQueue不为空,只有wc > 1才能被删除if ((wc > maximumPoolSize || (timed && timedOut))&& (wc > 1 || workQueue.isEmpty())) {if (compareAndDecrementWorkerCount(c))return null;continue;}try {// timed为true,超过keepAliveTime还是没有任务,返回null// timed为false,则一直阻塞等待任务Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take();if (r != null)return r;timedOut = true;} catch (InterruptedException retry) {timedOut = false;}}
}
processWorkerExit实现
线程执行完毕执行的方法
// processWorkerExit在runWorker结束之后被调用
private void processWorkerExit(Worker w, boolean completedAbruptly) {// 如果是异常终止,或者被中断,减少workerCountif (completedAbruptly) // If abrupt, then workerCount wasn't adjusteddecrementWorkerCount();final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {completedTaskCount += w.completedTasks;workers.remove(w);} finally {mainLock.unlock();}// Transitions to TERMINATED state if either (SHUTDOWN and pool// and queue empty) or (STOP and pool empty)tryTerminate();int c = ctl.get();// 状态为RUNNING或者SHUTDOWNif (runStateLessThan(c, STOP)) {if (!completedAbruptly) {int min = allowCoreThreadTimeOut ? 0 : corePoolSize;if (min == 0 && ! workQueue.isEmpty())min = 1;// 目前核心线程已经够用了,不用再创建if (workerCountOf(c) >= min)return; // replacement not needed}// 增加一个消费的线程addWorker(null, false);}
}
shutdown实现
public void shutdown() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 检查能否操作线程checkShutdownAccess();// 确保状态 >= SHUTDOWNadvanceRunState(SHUTDOWN);// 中断所有的空闲线程interruptIdleWorkers();// ScheduledThreadPoolExecutor会重写这个方法,做一些其他的运算onShutdown(); // hook for ScheduledThreadPoolExecutor} finally {mainLock.unlock();}tryTerminate();
}
// 中断空闲线程
private void interruptIdleWorkers() {interruptIdleWorkers(false);
}
// onlyOne为true则只中断一个空闲线程,否则全部中断
private void interruptIdleWorkers(boolean onlyOne) {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {for (Worker w : workers) {Thread t = w.thread;// 遍历Worker并执行中断操作,w.tryLock()保证了正在执行的Worker不会被中断// 因为正在运行的Worker再次获取锁会失败if (!t.isInterrupted() && w.tryLock()) {try {t.interrupt();} catch (SecurityException ignore) {} finally {w.unlock();}}if (onlyOne)break;}} finally {mainLock.unlock();}
}
这里需要注意的是不会中断正在运行的线程,因为正在运行的线程w.tryLock()会返回false
shutdownNow实现
public List<Runnable> shutdownNow() {List<Runnable> tasks;final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();// 确保状态 >= STOPadvanceRunState(STOP);// 中断所有线程interruptWorkers();// 获取所有没有执行完成的task// 即将阻塞队列中的任务放到tasks中 tasks = drainQueue();} finally {mainLock.unlock();}tryTerminate();return tasks;
}
private void interruptWorkers() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {for (Worker w : workers)w.interruptIfStarted();} finally {mainLock.unlock();}
}
// 这个是Worker内部类的方法
void interruptIfStarted() {Thread t;if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {try {t.interrupt();} catch (SecurityException ignore) {}}
}
shutdownNow会中断所有的线程,因为和shutdown相比在中断之前,不用获取锁
tryTerminate实现
// 将状态转换到TERMINATED
final void tryTerminate() {for (;;) {int c = ctl.get();// 以下几种状态不能转换为TERMINATED// 1.RUNNING状态// 2.TIDYING或TERMINATED// 3.SHUTDOWN状态,但是workQueue不为空if (isRunning(c) ||runStateAtLeast(c, TIDYING) ||(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))return;if (workerCountOf(c) != 0) { // Eligible to terminateinterruptIdleWorkers(ONLY_ONE);return;}final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {try {// 让子类去实现,做一些操作terminated();} finally {ctl.set(ctlOf(TERMINATED, 0));termination.signalAll();}return;}} finally {mainLock.unlock();}// else retry on failed CAS}
}
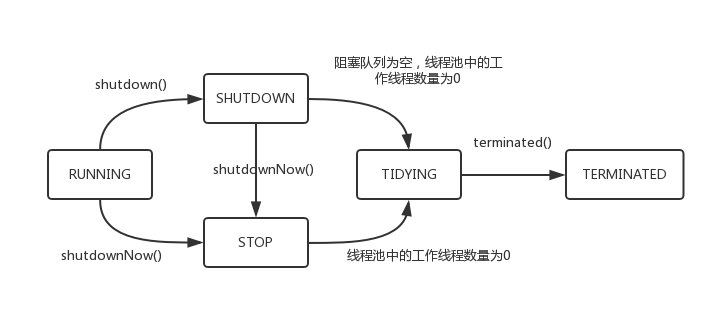
从上面可看出状态转换的条件
- SHUTDOWN想转化为TIDYING,需要workQueue为空,同时workerCount为0。
- STOP转化为TIDYING,需要workerCount为0
状态
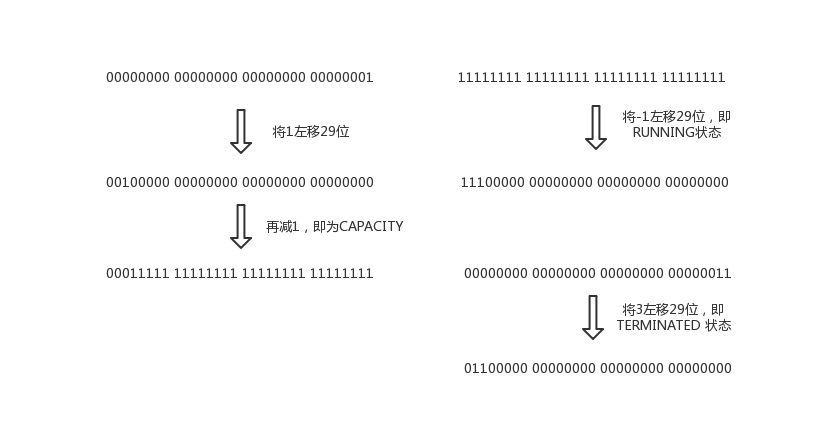
先了解一下线程池的状态及线程数量的表示方式
状态| 含义 | 值|
- | :-: | :-: |
RUNNING| 接受新任务,并且处理进入队列的任务| -536870912|
SHUTDOWN|不接受新任务,处理进入队列的任务 | 0|
STOP| 不接受新任务,不处理进入队列的任务,并且中断正在执行的任务| 536870912|
TIDYING| 所有任务执行完成,workerCount为0。线程转到了状态TIDYING会执行terminated()钩子方法 | 1073741824|
TERMINATED| terminated()已经执行完成 | 1610612736|
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
AtomicInteger类型的ctl代表了ThreadPoolExecutor的控制状态,是一个复合类型的变量,借助高低位包装了2个概念
- runState 线程池运行状态,占据ctrl的高三位
- workerCount 线程池中当前活动的线程数量,占据ctl的低29位
COUNT_BITS代表了workerCount所占的位数,即29,而CAPACITY表示线程池理论的最大活动线程数量,即536870911
0在Java底层是由32个0表示的,无论左移多少位,还是32个0,即SHUTDOWN的值为0,TIDYING则是高三位为010,低29为0
private static int runStateOf(int c) { return c & ~CAPACITY; }
是按位取反的意思,CAPACITY表示的是高位的3个0,和低位的29个1,而CAPACITY则表示高位的3个1,和低位的29个0,然后再与入参c执行按位与操作,即高3位保持原样,低29位全部设置为0,也就获取了线程池的运行状态runState。
private static int ctlOf(int rs, int wc) { return rs | wc; }
传入的rs表示线程池运行状态runState,其是高3位有值,低29位全部为0的int,而wc则代表线程池中有效线程的数量workerCount,其为高3位全部为0,而低29位有值的int,将runState和workerCount做按位或,即用runState的高3位,workerCount的低29位填充的数字
使用线程池的好处
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
参考博客
如何实现线程池
[0]https://mp.weixin.qq.com/s?src=11×tamp=1646287965&ver=3653&signature=Mly2yxEx2VLRnKbanWreavhOl1LNS2ghhHGbqNAxxQIaGYj73fs8Sv7RGrK0GUheg7O4YwRppPeACerWuGIT54NPPVgRgxWiLTR47Wi4-SZD5hpD0bs8eauo8sGrL4Zy&new=1
Java线程池的分析和使用
[1]http://ifeve.com/java-threadpool/
[2]https://blog.csdn.net/lipeng_bigdata/article/details/51232266
[3]https://blog.csdn.net/qq_19431333/article/details/59030892
[4]https://blog.csdn.net/programmer_at/article/details/79799267
[5]https://www.cnblogs.com/dolphin0520/p/3932921.html
[6]https://blog.csdn.net/u010723709/article/details/50372322
[7]https://blog.csdn.net/evankaka/article/details/51489322
四种Java线程池用法解析
[8]https://www.cnblogs.com/ruiati/p/6134131.html
比较好的文章
[1]https://www.jianshu.com/p/ade771d2c9c0
[2]https://www.jianshu.com/p/87bff5cc8d8c
[3]https://www.cnblogs.com/qingquanzi/p/8146638.html
[4]https://www.cnblogs.com/trust-freedom/p/6681948.html
这篇关于并发工具类:使用线程池有什么好处?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





