本文主要是介绍10月以太坊DApp数据报告:交易市场类DApp活跃度最高、吸金能力最强 | 链塔智库...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
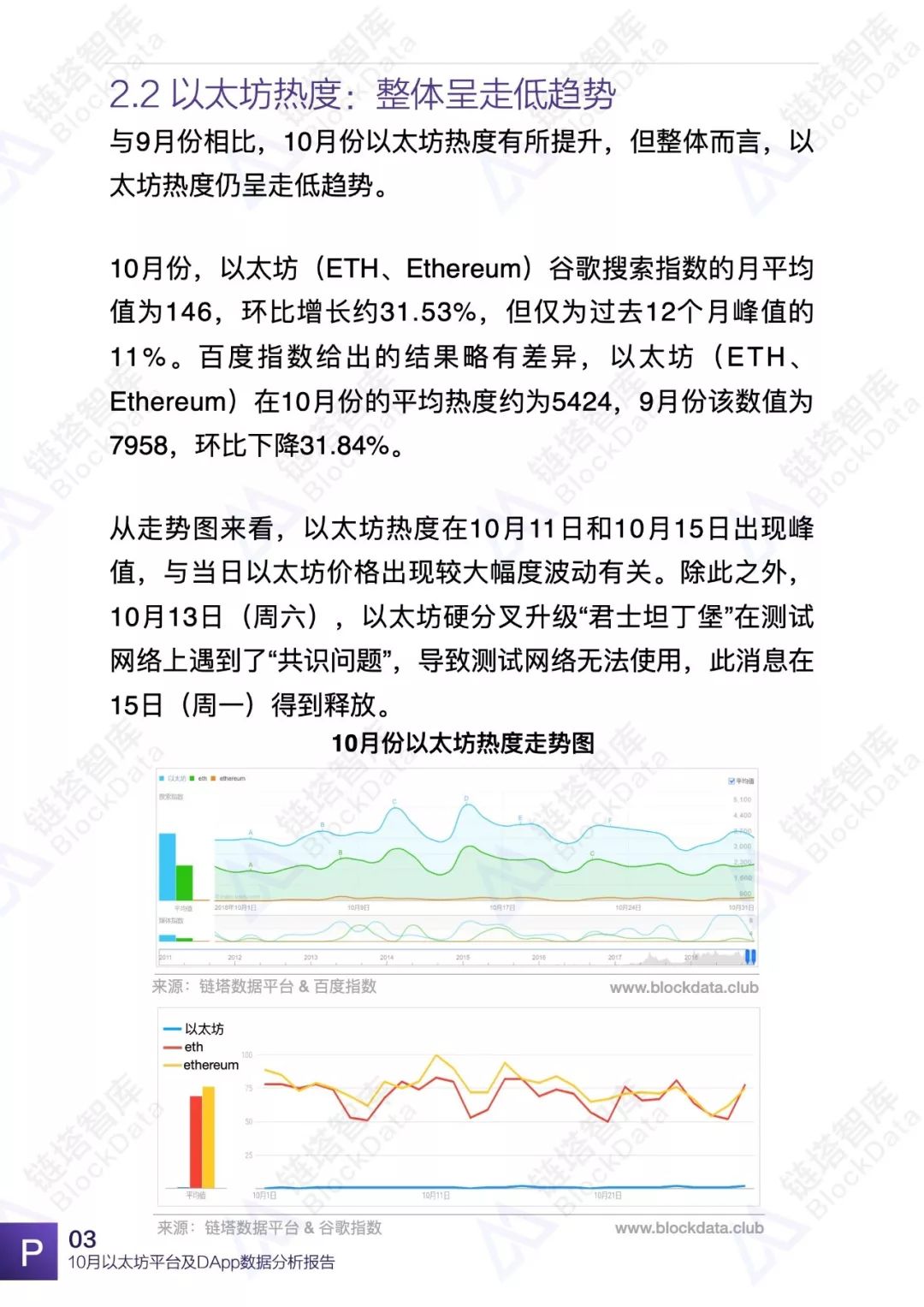
2018年10月份,由于在测试网络上遇到“共识问题”,导致原定于10月底至11月底在以太坊区块链主网上启动的君士坦丁堡硬分叉被推迟到2019年1月下旬。
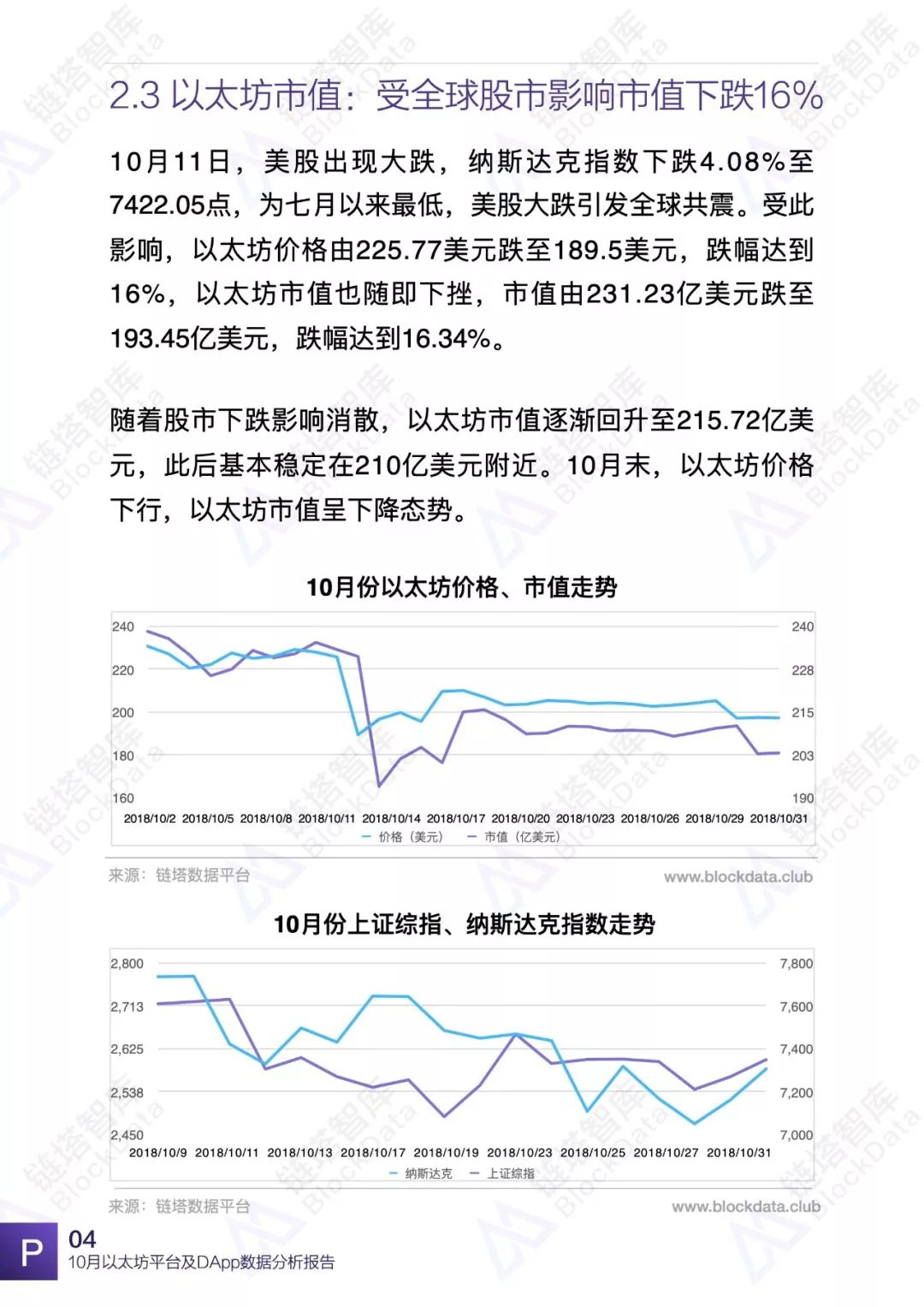
10月份,美股重挫引发全球股市动荡。10月10日,纳斯达克指数下跌4.08%,报7422.05点,创7月3日以来的收盘新低,众多明星科技股纷纷暴跌。11日,亚欧股市继续下行,上证综指下跌超过5%。据英媒报道,10月全球股市行情为6年以来最糟。
受股市影响,以太坊价格由225.77美元下跌至189.5美元,市值也随之下跌超过16%。随着股市影响消散,以太坊市值有所回升,稳定在210亿美元左右。
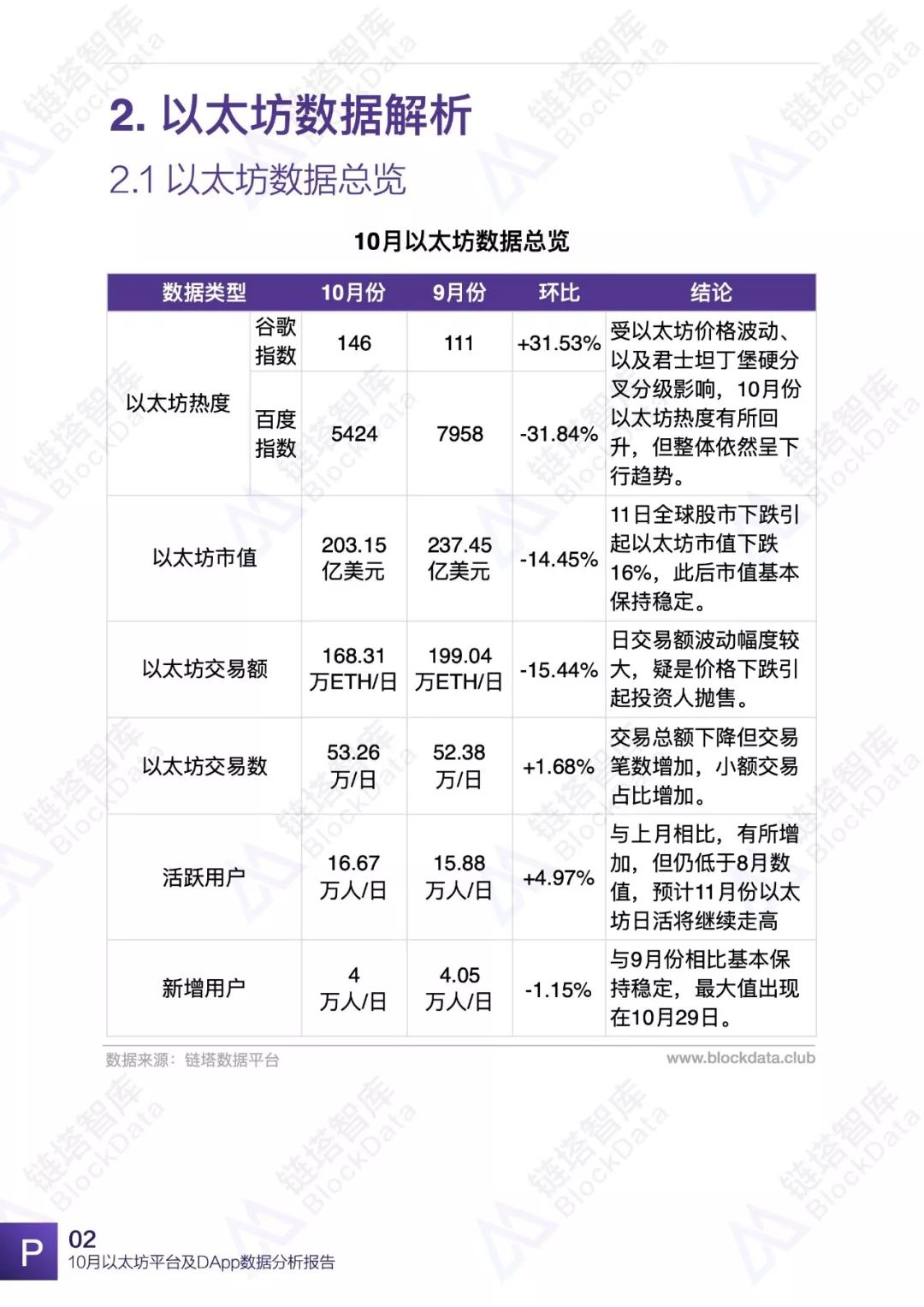
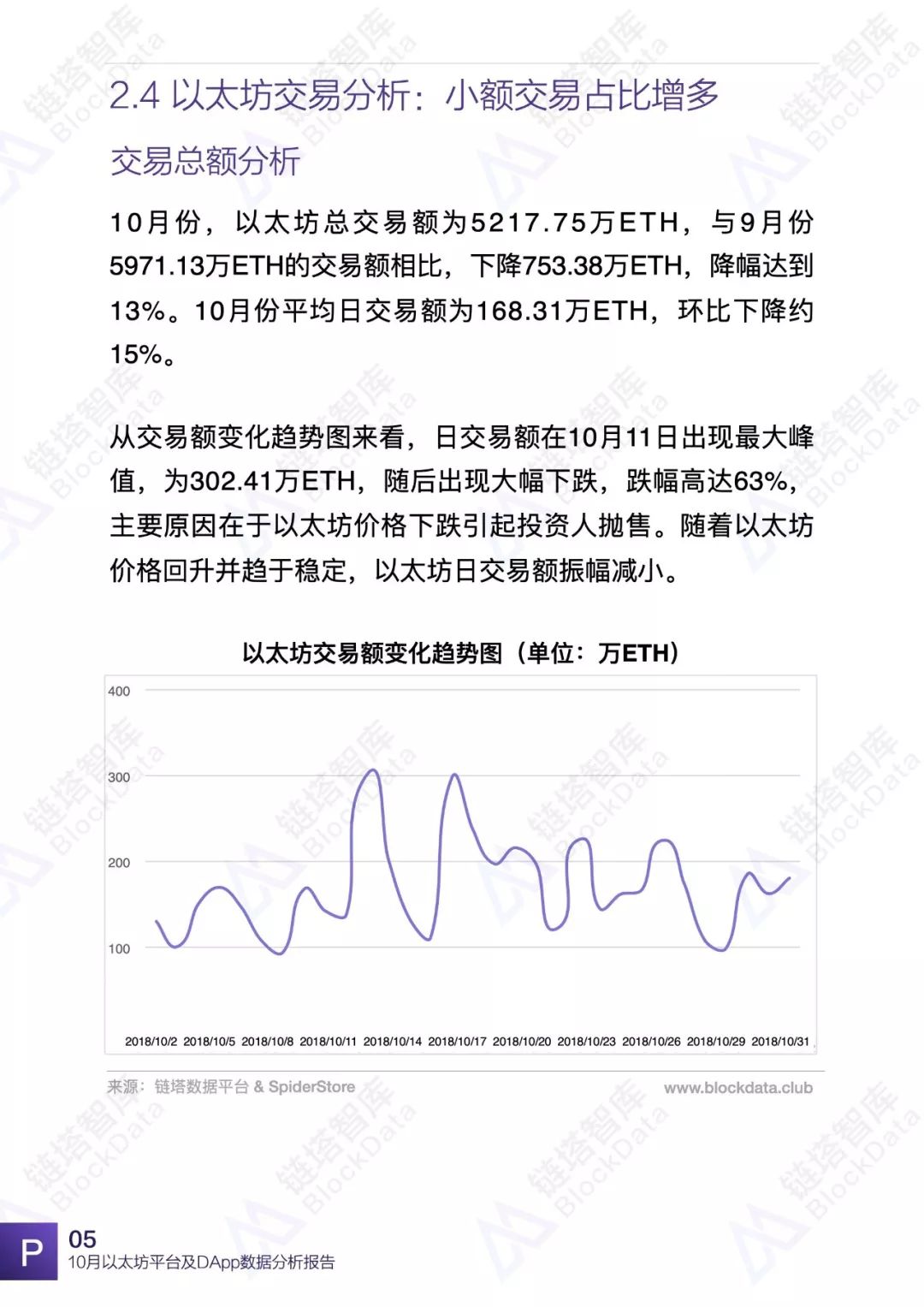
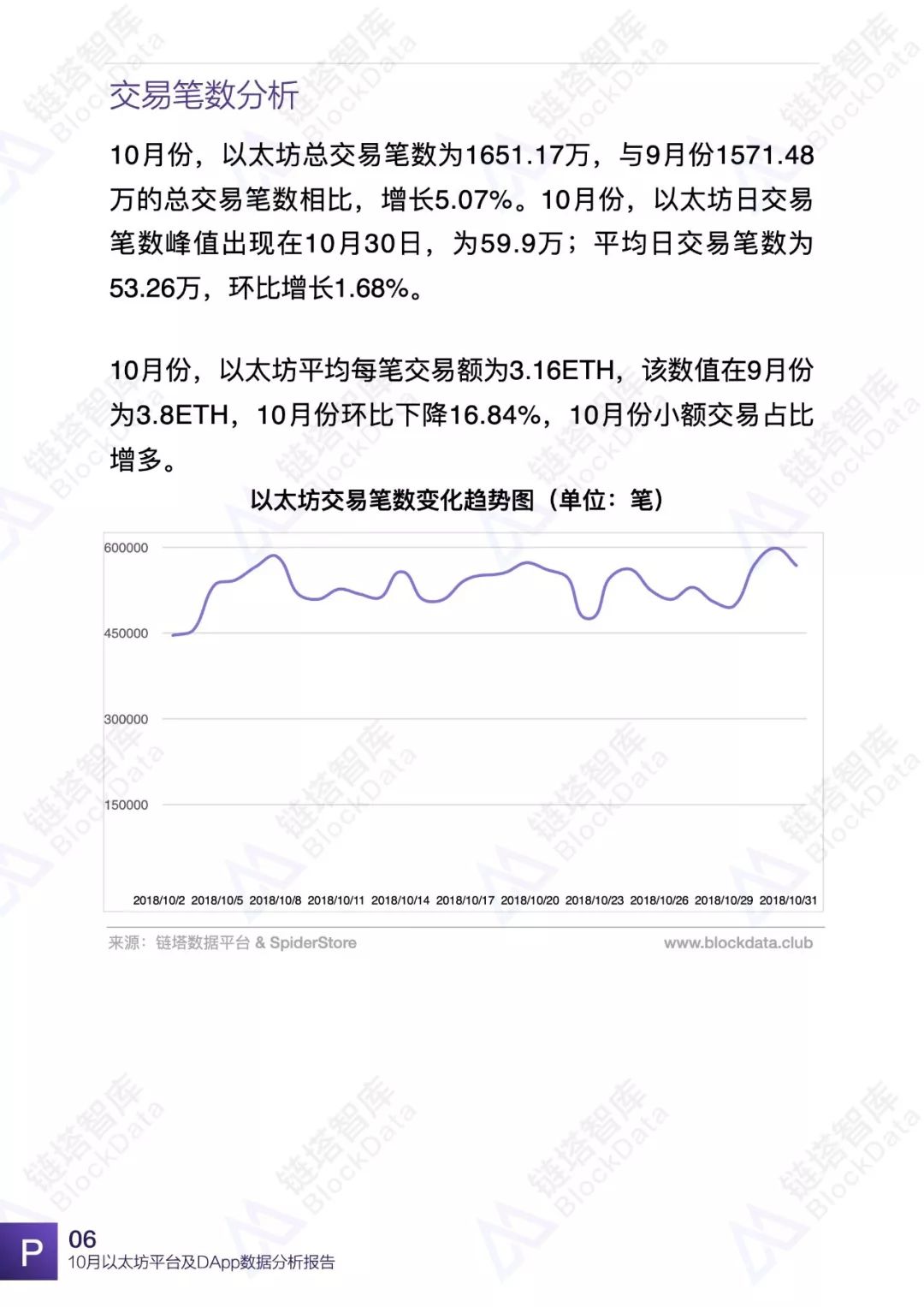
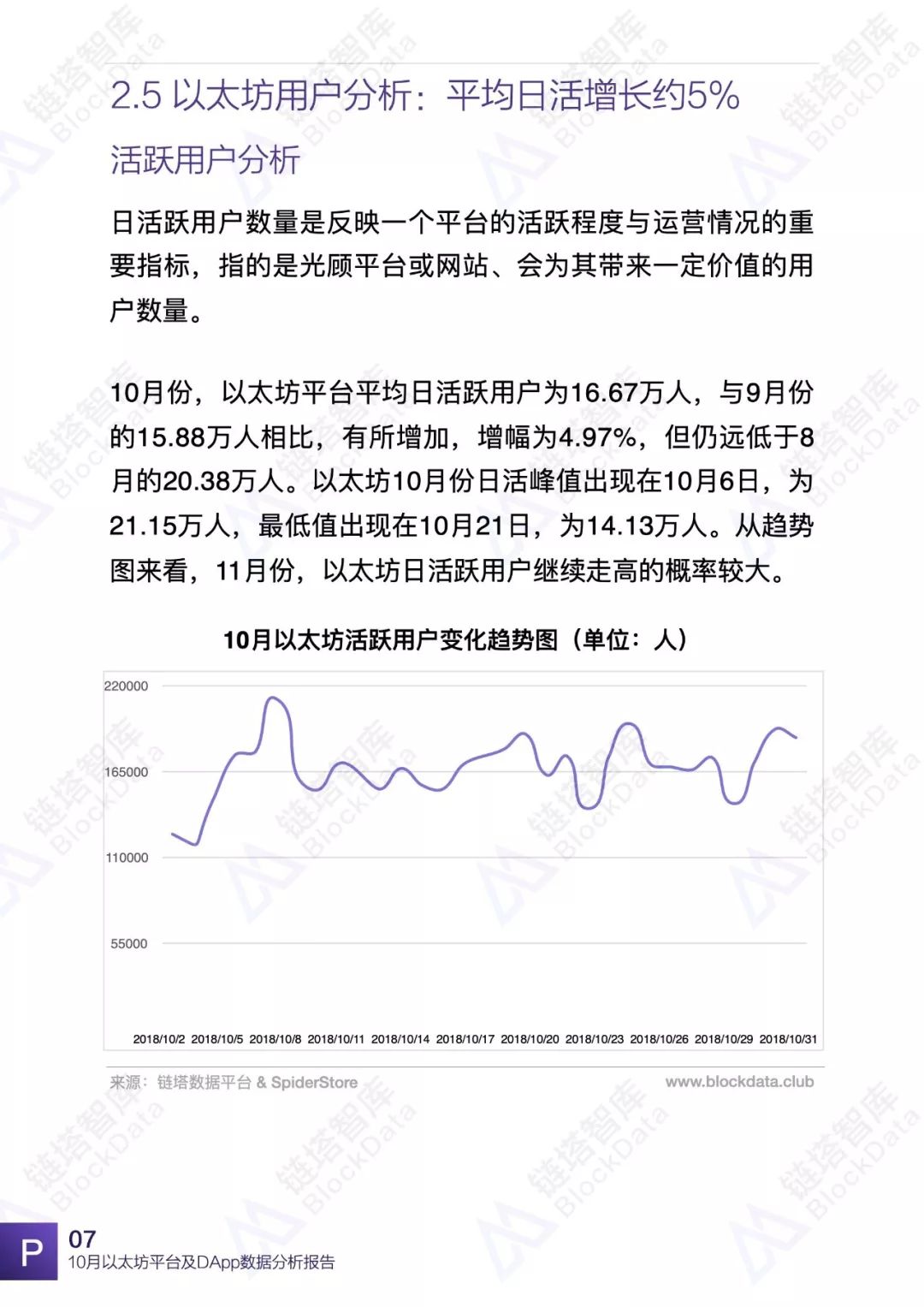
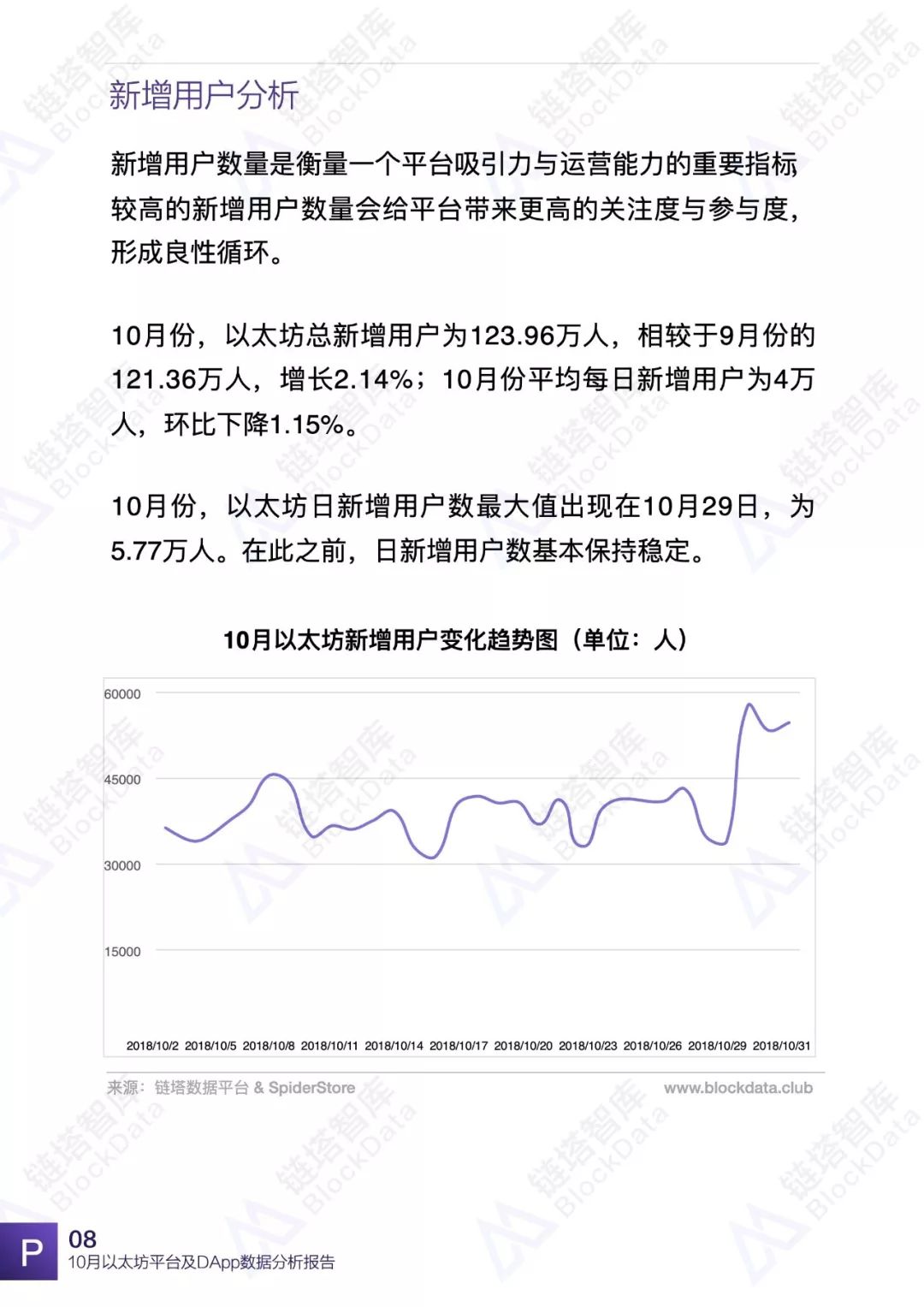
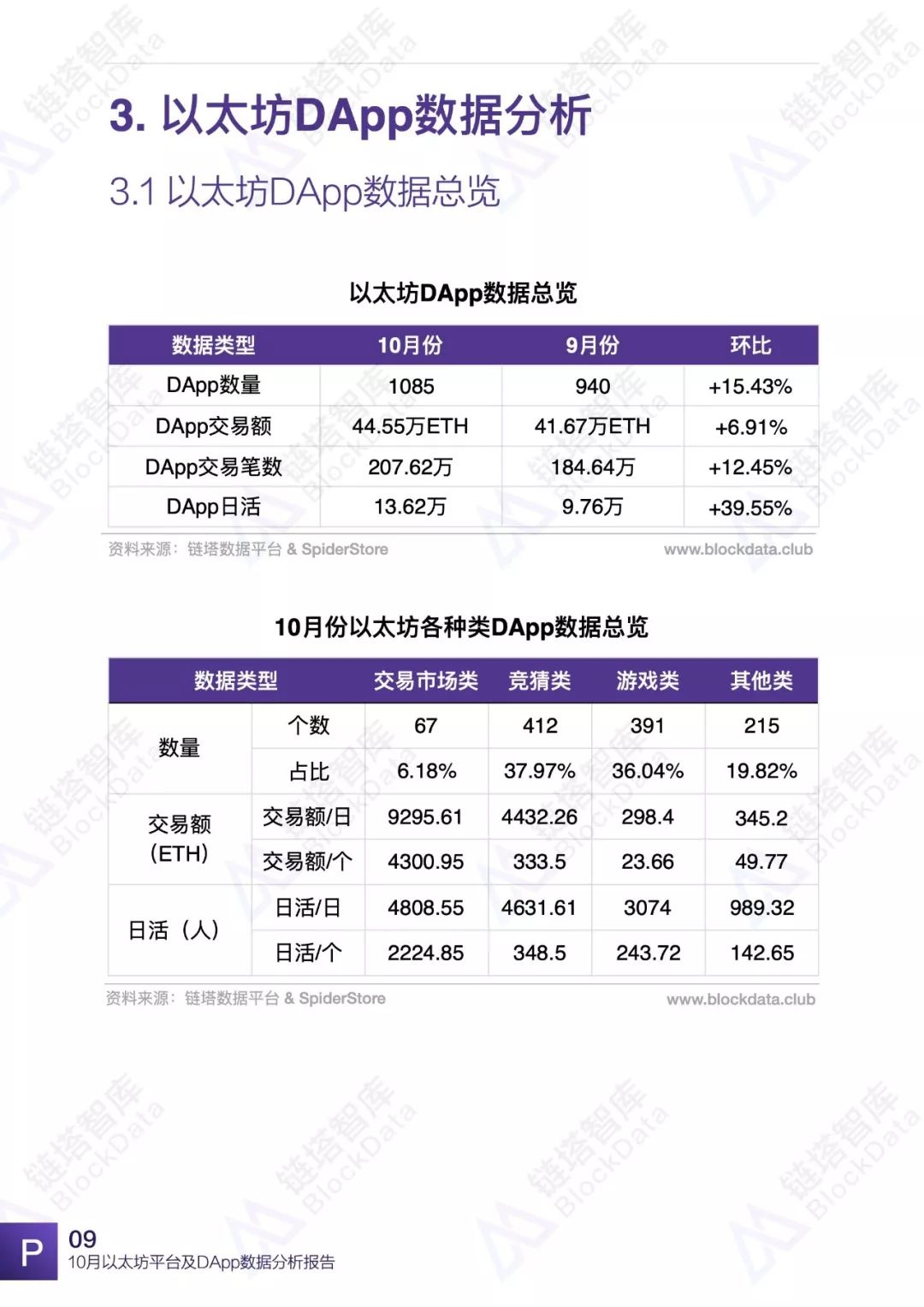
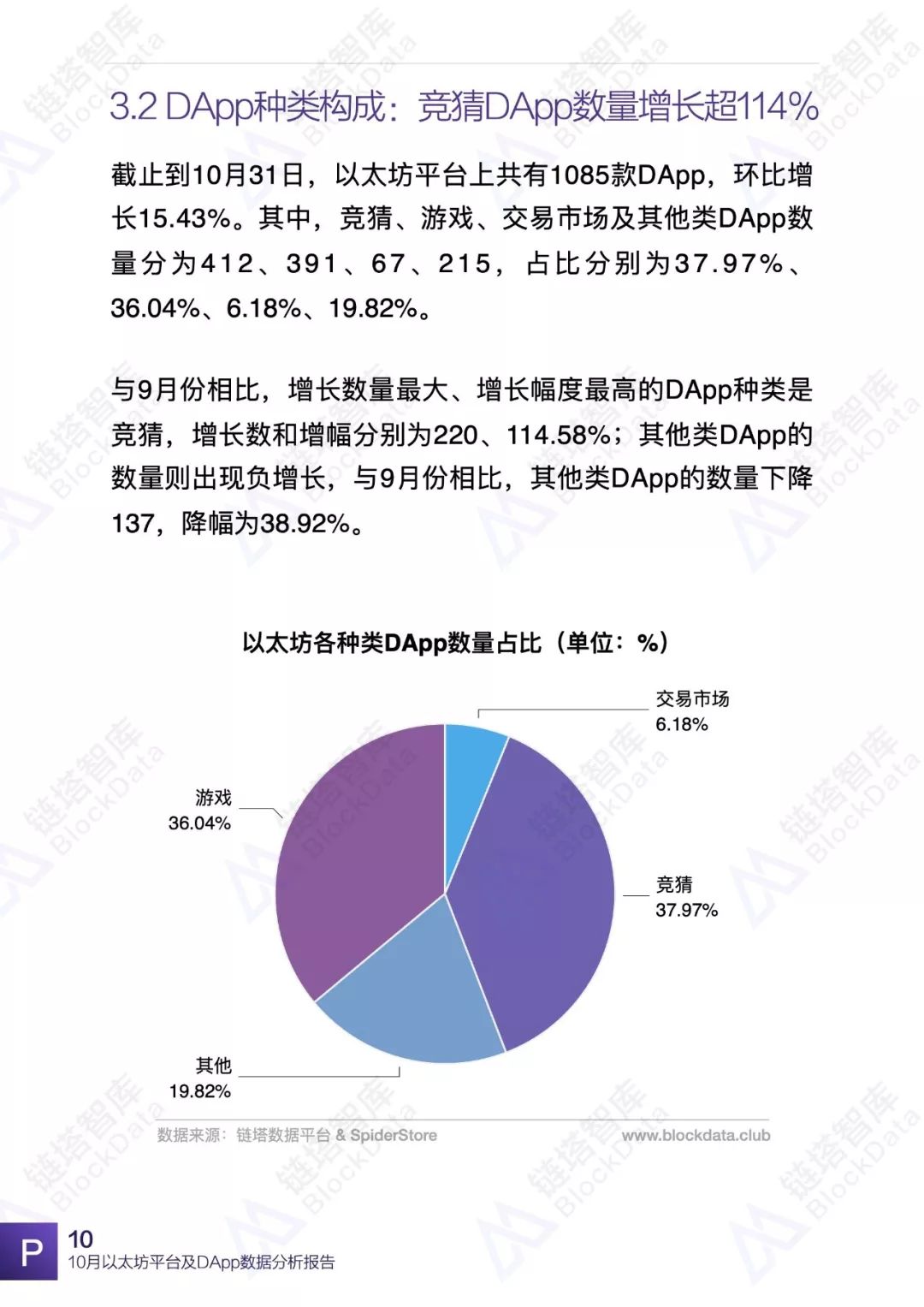
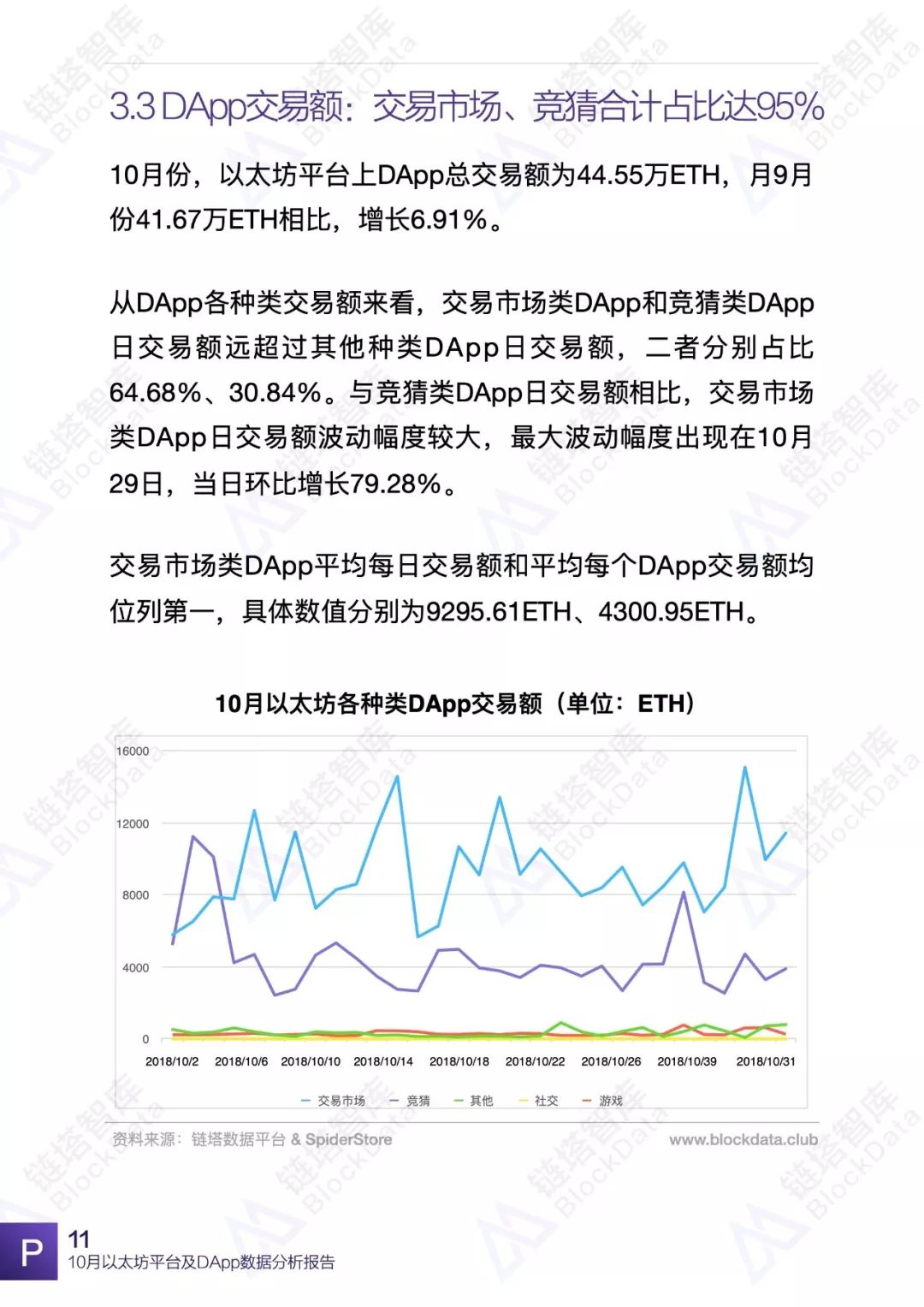
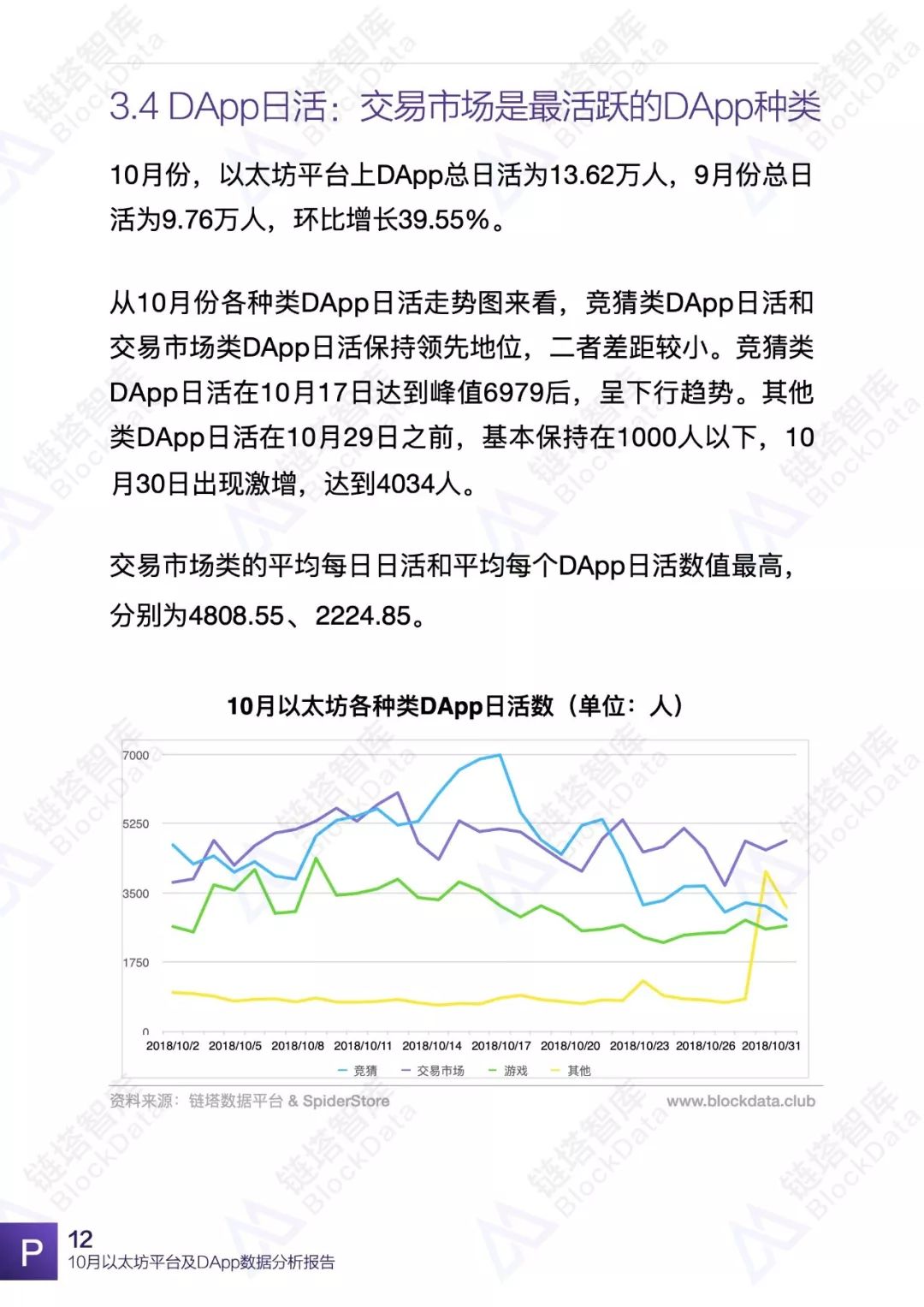
10月份,以太坊平台交易额、交易数、日活以及平台内DApp相关数据均有不同程度的变化,以太坊依然是目前最受欢迎的DApp开发平台之一。链塔智库BlockData对以太坊平台数据进行了深入研究和分析,形成完整报告。

点击以上图片查看项目详情






关注链塔评级
(ID:BDRating),免费获得10篇区块链行业深度报告+所有链塔已有评级报告。
长按识别二维码关注


*本文为“链塔智库”订阅号原创,转载请联系:
小楠(ID:BlockDataLianta)
*加入社群请联系:
小楠(ID:BlockDataLianta)
*项目入库请联系:小陸(ID:jkas8963)
*项目方免费申请链塔评级:
联系人:南楠(ID:nanyasheng)
项目资料发送邮箱至:nanys@blockdata.group
后台回复“以太坊10月”或得本期报告PDF版。

往期精选
???
链塔快评:
《Tether销毁5亿USDT快评》
《中本聪比特币白皮书十周年快评》
行业发展报告系列:
《2018中国区块链移动应用发展研究报告》
《2018中国区块链应⽤生态发展报告发布》
《2018第三季度区块链产业研究报告》
《2018中国区块链人才现状白皮书》
《链塔DApp数据分析报告》
《2018中国区块链专利报告》
《2018区块链招聘分析报告》
《区块链3.0共识蓝皮书》
区块链行业榜单系列:
《公有链安全性TOP20》
《2018区块链投资机构20强》
《5月份区块链媒体公众号50强》
点击进入链塔智库小程序
???
法律声明
知识产权声明
本报告为链塔智库BlockData制作,报告中所有数据、表格、图片均受有关商标和著作权法律保护,部分数据采集自公开信息,知识产权为原作者所有。我们相信数据的价值,我们同样相信分享也能创造价值,我们欢迎各组织和个人采用我们的报告和数据,在此之前告知我们即可。
免责条款
本报告中所载所有内容为链塔智库分析师通过访谈、市场调查、信息调研整理及其他方式方法获得,并结合链塔智库独有的数据和分析资源,建立相关预测模型估算而得,为区块链行业从业者提供基本参考,受研究方法和数据获取渠道所限,本报告只提供受众作为各类市场活动参考资料,不构成任何投资或交易买卖建议。如果访问者依据本报告信息进行投资或进行交易买卖而遭受损失,本公司对此不承担责任。
点击“阅读原文”,查看更多区块链行业报告。
这篇关于10月以太坊DApp数据报告:交易市场类DApp活跃度最高、吸金能力最强 | 链塔智库...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






