本文主要是介绍GO-Python 结构体的应用 - 结构体内存对齐 - go实现ATM存取钱 - python 高阶函数(map映射器函数、filter过滤器函数、sorted排序函数),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、结构体的应用
实现简单的set集合功能
二、结构体内存对齐
查看空结构体的内存:
测试不同结构体的内存大小:
计算机读取字节示意图:
内存对齐方式存储:
内存对齐的目的:
go中如何内存对齐:查看内存对齐系数(规则)
使用工具实现go程序的内存对齐:
步骤:
go练习:
ATM存取钱:
定义标准化返回:
三、python 高阶函数
什么是可迭代对象?
1、map映射器函数
通过map实现求平方的功能
map实现匿名函数的写法:
传输两个参数的map写法
通过map实现求所有数据的绝对值(使用abs绝对值函数)
2、filter过滤器函数
filter过滤器实现偶数就保留,奇数就不保留
filter过滤器实现找到1000以内开平方的结果是整数的数
3、sorted排序函数
简单按照大小进行排序
将列表按绝对值大小进行排序
按字符串长度 降序 排列
按字符串长度 升序 排列
按照字母在前,数字在后面进行排序
按照字母在前,数字在后面进行排序,并且按照小写 -> 大写 -> 奇数 -> 偶数这样的顺序排序
作业:
学生信息管理系统
提取url上对应ip的相关信息
一、结构体的应用
实现简单的set集合功能
// set集合:只有key的集合,没有vlaue的字典
// 用结构体模拟set数据类型
// 实现的功能:1、需要的数据 2、追加值 3、移除值
type Set map[string]struct{}func (s Set) Append(k string){ // 追加值// 空结构体实例不占内存空间,因此可以定义,对程序来说更加便利优秀s[k] = struct{}{}
}
func (s Set) Remove(k string){ // 移除值delete(s, k)
}
func main() { // 定义需要的数据s1 := Set{}s1.Append("aa")s1.Append("bb")s1.Append("cc")fmt.Println(s1)s1.Remove("aa")fmt.Println(s1)
}二、结构体内存对齐
查看空结构体的内存:
package mainimport ("fmt""unsafe"
)// 定义一个空结构体
type Empty struct {
}func main() {// 空结构体实例不占内存空间fmt.Printf("Empty的大小是:%v\n", unsafe.Sizeof(Empty{}))
}输出:Empty的大小是:0测试不同结构体的内存大小:
package mainimport ("fmt""unsafe"
)// 定义出三个测试结构体
type Test1 struct {a boolb stringc int32
}// min(16, 8)type Test2 struct {b stringa boolc int32
}type Test3 struct {c int32b stringa bool
}// 查看他们的对应的结构体的内存大小
func main(){t1 := Test1{}t2 := Test2{}t3 := Test3{}fmt.Printf("t1的大小是:%v\n", unsafe.Sizeof(t1))fmt.Printf("t2的大小是:%v\n", unsafe.Sizeof(t2))fmt.Printf("t3的大小是:%v\n", unsafe.Sizeof(t3))
}输出:
t1的大小是:32
t2的大小是:24
t3的大小是:32发现实例的内存大小是不一样的因为产生实例大小差异的原因是:结构体的内存对齐了
当我们的操作系统在读取数据的时候,他并不是一个一个字节去读取的,系统读取数据是按字长去读取的:32位(读取4字节),64位(读取8字节)计算机读取字节示意图:
图中的a、b、c都是三字节的数据,而我们的计算机一次性读取四字节,因此读取第一次的时候,他会读取到全部的a和部分的b,这相当于把a读取完了,当我们需要读取b的时候,我们需要读取两次才能将b读取完吗,先读取1-4,在读取5-8才能把4-6读取完整,因此我们推荐使用内存对齐的方式存储
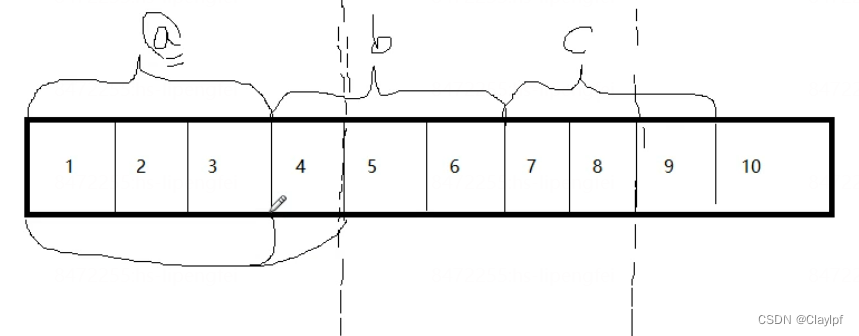
内存对齐方式存储:
将a数据存储在1-3,4位置补位为空,b存储在5-7,c存储子9-11,依此类推,这样当我们读取a、b、c的时候,都只需要读取一次
内存对齐:内存对齐就是根据一定的方法,把我们的数据尽量存储在读字长的首位置,如4的整数倍(32位cpu)或者是8的整数倍(64位cpu),因此可以认为内存对齐就是使用内存空间换程序运行时间,让程序的性能效率更高。
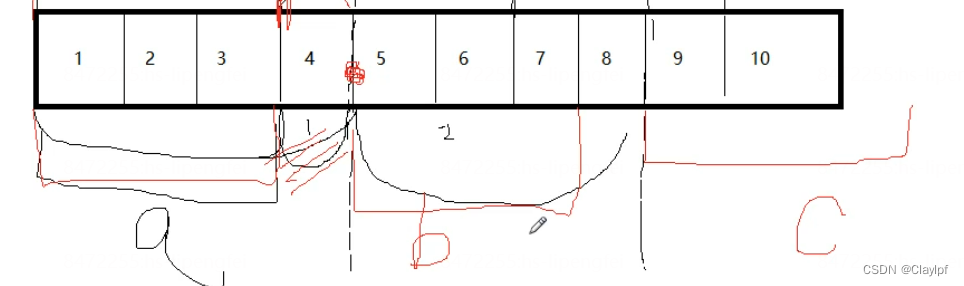
内存对齐的目的:
结构体字段的内存对齐是为了优化内存访问的效率和性能,主要目的是为了使处理器可以更高效地读取内存,提高程序的性能。
go中如何内存对齐:查看内存对齐系数(规则)
规则一:第一个字段偏移量为0, 后面字段的的偏移量min(sizeof,alignof)的整数倍
规则二:空结构体如果在前面或中间不占空间,在最后占的空间等于最后一个字段的空间
规则三:结构体偏移 min(结构体内各个成员大小和,编译器默认对齐系数大小)的整数倍
package mainimport ("fmt""unsafe"
)// 查看他们的对应的结构体的内存大小
func main(){// go中内存如何对齐:规则// bool, string, int32fmt.Printf("bool的大小是:%v, bool的内存对齐系数是%v\n",unsafe.Sizeof(true), unsafe.Alignof(true))fmt.Printf("string的大小是:%v, string的内存对齐系数是%v\n",unsafe.Sizeof("abc"), unsafe.Alignof("abc"))fmt.Printf("int32的大小是:%v, int32的内存对齐系数是%v\n",unsafe.Sizeof(int32(0)), unsafe.Alignof(int32(0)))// 规则一:第一个字段偏移量为0, 后面字段的的偏移量min(sizeof,alignof)的整数倍// 规则二:空结构体如果在前面或中间不占空间,在最后占的空间等于最后一个字段的空间// 规则三:结构体偏移 min(结构体内各个成员大小和,编译器默认对齐系数大小)的整数倍
}输出:
bool的大小是:1, bool的内存对齐系数是1
string的大小是:16, string的内存对齐系数是8
int32的大小是:4, int32的内存对齐系数是4存储规则图:

使用工具实现go程序的内存对齐:
go install golang.org/x/tools/go/analysis/passes/fieldalignment/cmd/fieldalignment@latest
"Field alignment"(字段对齐)是指在结构体或类中,每个成员字段的存储位置相对于结构体或类的起始地址的偏移量应该是特定的字节对齐要求的倍数。
在结构体或类中的成员字段通常具有不同的数据类型和大小。为了提高内存访问的效率,减少额外的空隙和对齐填充,编译器会根据各个成员字段的数据类型和平台要求进行适当的字段对齐。这可以确保每个成员字段存储的起始地址正好是特定对齐要求的倍数。
步骤:
创建:内存对齐测试.go
package mainimport ("fmt""unsafe"
)type Test1 struct {// Test测试a boolb stringc int32
}func main() {t1 := Test1{}fmt.Printf("t1的大小是:%v\n", unsafe.Sizeof(t1))
}
执行 fieldalignment:
fieldalignment -fix 内存对齐测试.go生成: 内存对齐测试.go (它会修改文件本身,如果你需要使用的话最好进行一下备份,因为他会去除你的所有的注释,而且改变变量定义的位置)
package mainimport ("fmt""unsafe"
)type Test1 struct {b stringc int32a bool
}func main() {t1 := Test1{}fmt.Printf("t1的大小是:%v\n", unsafe.Sizeof(t1))
}
go练习:
ATM存取钱:
package mainimport "fmt"// ATM:bank
// User:name,passwd,balance,可以取钱,可以存钱type ATM struct {bank string
}type User struct{name stringpasswd stringbalance int
}func (u *User) Savemaney(maney int){u.balance += maneyfmt.Printf("用户存取的金额为:%v,现在的余额为:%d\n", maney, u.balance)
}func (u *User) Drawmaney(maney int){if u.balance > maney{u.balance -= maneyfmt.Printf("用户取出的金额为:%v,现在的余额为:%d\n", maney, u.balance)}else {fmt.Printf("余额不足!")}
}func main() {atm1 := ATM{bank: "中国农业银行"}user1 := User{name: "lpf",passwd: "123456",balance: 2000,}fmt.Printf("%v用户的基本信息:%+v\n", atm1.bank, user1)user1.Savemaney(1000)user1.Drawmaney(2000)
}定义标准化返回:
package mainimport ("encoding/json""fmt"
)/*
Web API => 返回数据给使用者 => json// 定义返回的数据格式,将返回的数据用json的方式打印出来
// Code, Message, Data
// s.json() => 将它转换成json格式(string)后端开发:API => 访问url => 返回数据(无页面) => 访问者
标准化返回:
{”code": 1001,"message": "参数不完整“,"data": {}/[]/other
}
*/// 定义返回的数据格式,将返回的数据用json的方式打印出来
type ResponseData struct {Code int `json:"code"`Message string `json:"message"`Data interface{} `json:"data"`
}// 将它转换成json格式(string)
func (r ResponseData) json() (string, error){data, err := json.Marshal(r)return string(data), err
}// 访问测试
func main(){r := ResponseData{1001, "失败了", ""}data, err := r.json()fmt.Printf("数据:%v,错误:%v\n", data, err)
}输出:
数据:{"code":1001,"message":"失败了","data":""},错误为:<nil>三、python 高阶函数
高阶函数:把函数作为参数传入这样的函数,称为高阶函数(map、filter、sorted等)
什么是可迭代对象?
可迭代对象是指可以被迭代(遍历)的对象。它们通常用于循环结构,比如
for循环。可迭代对象可以包含多个元素,每次迭代都返回其中的一个元素,直到所有元素都被访问完为止。就是可以把其中的元素一个个取出来的对象
常见的可迭代对象:列表(Lists)、元组(Tuples)、字符串(Strings)、集合(Sets)、字典(Dictionaries)、文件对象(File Objects)等
1、map映射器函数
map的作用 => 映射
通过map实现求平方的功能
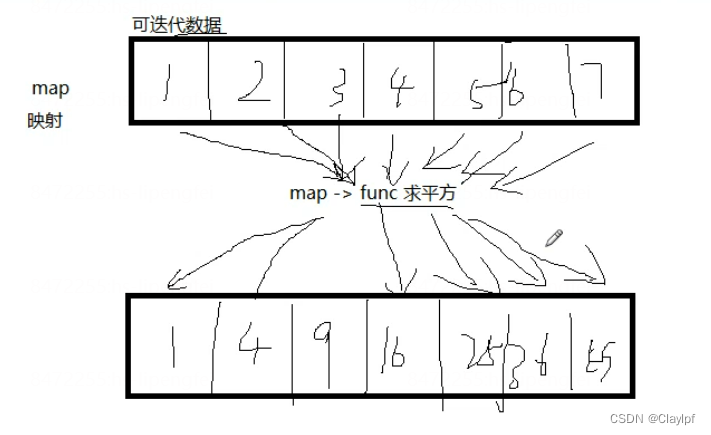
# map => 映射def func1(item):return item*item # 实现求平方功能的函数
li = [1,2,3,4,5,6,7]result = map(func1, li) # map映射的作用
print(list(result))输出:
[1, 4, 9, 16, 25, 36, 49]map实现匿名函数的写法:
map => 迭代器 => 只能取一次值
# 匿名函数的写法: map => 迭代器 => 只能取一次值
li = [1,2,3,4,5,6,7]
result = map(lambda x:x*x,li)
print(type(result), list(result))
print(list(result))输出:
<class 'map'> [1, 4, 9, 16, 25, 36, 49]
[] # 只能取一次值,因此第二次取值为空传输两个参数的map写法
li1 = [1, 2, 3]
li2 = [2, 3, 4]
result = map(lambda x,y:x*y, li1, li2)
print(list(result))通过map实现求所有数据的绝对值(使用abs绝对值函数)
li3 = [1,2 ,-1, 4, 6, -4]
result = map(abs, li3) # abs是一个将所有值转换为绝对值的函数
print(list(result))2、filter过滤器函数
函数会返回True/False,其中函数返回True表示保留该数据,函数返回False表示不保留该数据(不影响原数据),它可以过滤掉一些自己不需要的,保留一些自己需要的。
filter过滤器实现偶数就保留,奇数就不保留
li4 = [1,2,3,4,5,6,7]
result = filter(lambda x: not x%2, li4)
print(type(result), list(result))输出:
<class 'filter'> [2, 4, 6]filter过滤器实现找到1000以内开平方的结果是整数的数
# 1 => 1, 4 => 2, 9, 16, 25, 36 ....
# range(1000)
result = filter(lambda x: not x**0.5%1, range(1000))
print(type(result), list(result))输出:
<class 'filter'> [0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361, 400, 441, 484, 529, 576, 625, 676, 729, 784, 841, 900, 961]
3、sorted排序函数
将数据交给key对应的函数进行处理,使用处理完的数据进行排序,排序完成后,输出我们原本的数据
简单按照大小进行排序
li5 = [1,2,3,-1,10]
print(sorted(li5))输出:
[-1, 1, 2, 3, 10]将列表按绝对值大小进行排序
li5 = [1,2,3,-4,10]
print(sorted(li5, key=abs))输出:
[1, 2, 3, -4, 10]按字符串长度 降序 排列
li6 = ["abc", "def", "a", "ahahsdf", "saldfjew"]
print(sorted(li6, key=len, reverse=True))输出:
['a', 'abc', 'def', 'ahahsdf', 'saldfjew']按字符串长度 升序 排列
li6 = ["abc", "def", "a", "ahahsdf", "saldfjew"]
print(sorted(li6, key=len, reverse=False))输出:
['a', 'abc', 'def', 'ahahsdf', 'saldfjew']按照字母在前,数字在后面进行排序
str1 = "aA324KD132fs12F3l"
print("".join(sorted(str1, key=str.isalpha, reverse=True)))
# 表示判断输入的字符是否为字母,如果为字母就输出True,就会排列在前面,但是是以单个字符排列,我们使用"".join()可以将单个字符拼接回来,又形成字符串输出:
aAKDfsFl324132123str.isalpha() --》判断是否为字母str.isdigit() --》判断是否为数字str.isalnum() --》判断是否为数字和字母"".join()可以将得到的字符拼接回来按照字母在前,数字在后面进行排序,并且按照小写 -> 大写 -> 奇数 -> 偶数这样的顺序排序
方法一:
str1 = "aA324KD132fs12F3l"
lst2 = sorted(str1, key=lambda x: ord(x) + 100 if x.islower() else ord(x) + 200 if x.isupper() else ord(x)+300 if int(x) % 2 else ord(x)+400)
print(''.join(lst2))输出:
aflsADFK113332224ord(x)是一个内置函数,用于获取字符 x 对应的 Unicode 码点(整数值)
如:
print(ord('A')) # 输出 65
print(ord('a')) # 输出 97
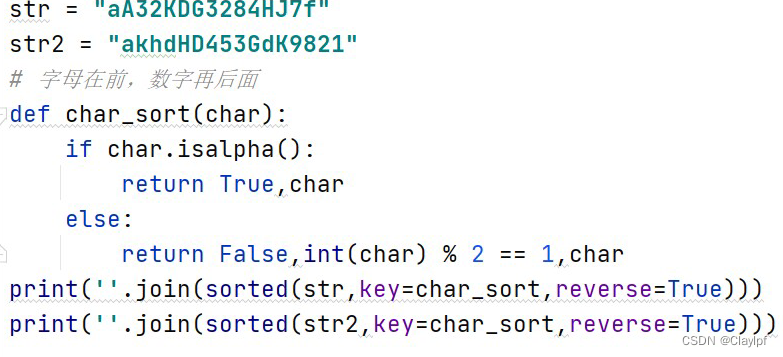
print(ord('1')) # 输出 49通过ord(x) + 100和if else判断等操作来将不同的数据通过添加不同大小的数据来进行排序方法二:
作业:
学生信息管理系统
### 2. 学生信息管理系统 id 、name、age、address (id不能重复)
1、添加学生信息
2、修改学生信息
3、删除学生信息
4、查看当前所有学生信息
5、退出
### 2. 学生信息管理系统 id 、name、age、address (id不能重复)
"""
1、添加学生信息
2、修改学生信息
3、删除学生信息
4、查看当前所有学生信息
5、退出
"""
# 学生信息管理系统
student_data = []def add_student(id, name, age, address):for student in student_data:if student['id'] == id:print("学生ID已存在,请重新输入。")returnstudent_data.append({'id': id, 'name': name, 'age': age, 'address': address})print("学生信息添加成功。")def update_student(id, name, age, address):if not student_data:print("无学生信息,无法修改信息。")for student in student_data:if student['id'] == id:student['name'] = namestudent['age'] = agestudent['address'] = addressprint("学生信息更新成功。")returnprint("找不到学生ID,无法更新信息。")def delete_student(id):if not student_data:print("无学生信息,无法删除。")for student in student_data:if student['id'] == id:student_data.remove(student)print("学生信息删除成功。")returnprint("找不到学生ID,无法删除信息。")def view_students():if not student_data:print("当前没有学生信息。")else:print("当前所有学生信息:")for student in student_data:print(f"ID: {student['id']}, 姓名: {student['name']}, 年龄: {student['age']}, 地址: {student['address']}")def inputinfo(flag):if flag == "1":id = input("请输入学生ID:")name = input("请输入学生姓名:")age = input("请输入学生年龄:")address = input("请输入学生地址:")return id, name, age, addresselif flag == "2":id = input("请输入要修改的学生ID:")name = input("请输入新的学生姓名:")age = input("请输入新的学生年龄:")address = input("请输入新的学生地址:")return id, name, age, addressdef main():while True:print("学生信息管理系统")print("1、添加学生信息\n2、修改学生信息\n3、删除学生信息\n4、查看当前所有学生信息\n5、退出")choice = input("请选择操作(1/2/3/4/5):")if choice == '1':# 输入基本信息id,name,age,address = inputinfo(choice)add_student(id, name, age, address)elif choice == '2':# 输入基本信息id,name,age,address = inputinfo(choice)update_student(id, name, age, address)elif choice == '3':id = input("请输入要删除的学生ID:")delete_student(id)elif choice == '4':# 查看所有学生信息view_students()elif choice == '5':print("退出学生信息管理系统。")breakelse:print("无效的选择,请重新输入。")if __name__ == "__main__":main()提取url上对应ip的相关信息
### 提取ip相关信息
- 接口:https://ip.taobao.com/outGetIpInfo?accessKey=alibaba-inc&ip=要查询的ip地址
- 给一个ip地址,可以通过该接口获取到省份和运营商
- 实现一个ip查询功能
- 用户输入一个ip地址,将查询到的结果显示给用户
- 并将结果用以下格式写入到文件:ip,国家,省份,运营商
### 提取ip相关信息
"""
- 接口:https://ip.taobao.com/outGetIpInfo?accessKey=alibaba-inc&ip=要查询的ip地址
- 给一个ip地址,可以通过该接口获取到省份和运营商
- 实现一个ip查询功能- 用户输入一个ip地址,将查询到的结果显示给用户- 并将结果用以下格式写入到文件:ip,国家,省份,运营商
"""
import requests# 获取IP地址对应的url信息
def get_ip_info(ip):url = f"https://ip.taobao.com/outGetIpInfo?accessKey=alibaba-inc&ip={ip}"response = requests.get(url)data = response.json()if data['code'] == 0:ip_info = data['data']country = ip_info['country']region = ip_info['region']isp = ip_info['isp']return country, region, ispelse:return Nonedef main():ip = input("请输入要查询的IP地址:")ip_info = get_ip_info(ip)if ip_info:country, region, isp = ip_inforesult = f"IP: {ip}, 国家: {country}, 省份: {region}, 运营商: {isp}"print(result)# 将得到的数据保存到文件当中with open("ip_info.txt", "a") as file:file.write(result + "\n")print("结果已写入文件。")else:print("无法获取IP信息。")if __name__ == "__main__":main()这篇关于GO-Python 结构体的应用 - 结构体内存对齐 - go实现ATM存取钱 - python 高阶函数(map映射器函数、filter过滤器函数、sorted排序函数)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




