本文主要是介绍顶刊IJCV 2023!北理工普林斯顿提出:暗光实例分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【图像分割和Transformer】交流群
作者:Uno Whoiam(源:知乎,已授权)| 编辑:CVer公众号
https://zhuanlan.zhihu.com/p/656570195
在CVer微信公众号后台回复:暗光实例分割,可以下载本论文pdf、代码和数据集

Instance Segmentation in the Dark
单位:北理工&普林斯顿
作者:Linwei Chen· Ying Fu · Kaixuan Wei· Dezhi Zheng· Felix Heide
论文:arxiv.org/abs/2304.14298
https://link.springer.com/article/10.1007/s11263-023-01808-8
代码:https://github.com/Linwei-Chen/LIS
TL; DR 太长不看版
这篇论文开辟了一个新的研究方向,即在低光条件下进行实例分割。它是第一篇系统性地建立了低光条件下实例分割的训练和测试验证框架的论文(划重点,可以卷的新方向!)。
本论文收集制作了一个Low-light Instance Segmentation (LIS) 数据集,它包括低光、正常曝光,下配对的JPEG和RAW的四组数据,并且提供8类实例像素标注,可以用于实例分割、目标检测任务。(新数据集!)
本论文观察到,RAW图像具有比JPEG图像更好的潜力来实现更高实例分割精度,并且作者进一步分析,这和RAW能提供更多比特位深的信息有关(RAW is all you need!)。
本论文观察到,暗光条件下,图像噪声会对深度神经网络中的特征造成高频扰动,这是导致现有实例分割方法在暗光条件下表现不好的一个重要原因(Noise is the key!)。
效果如何?使用该论文的方法框架,基于Mask R-CNN-ResNet50的结果,和在大量数据上训练的大模型Segment Anything相比,该论文提出的方法仍然表现出色。
摘要
现有的实例分割技术主要针对正常光照下高质量图像输入进行处理,但在极低光环境下,它们的性能显著下降。在这项工作中,我们深入研究了暗光条件下的实例分割,并引入了几种显著提高低光推断准确性的技术。所提出的方法是基于以下观察而提出的,即低光图像中的噪声会对神经网络的特征图引入高频干扰,从而显著降低性能。为了抑制这种“特征噪声”,我们提出了一种新颖的学习方法,依赖于自适应加权下采样层、平滑定向卷积块和干扰抑制学习。这些组件在下采样和卷积操作期间有效减少了特征噪声,使模型能够学习具有抗扰动性的特征。此外,我们发现,与典型的相机sRGB输出相比,高比特深度的RAW图像可以更好地保留低光条件下更丰富的场景信息,因此支持使用RAW输入算法。我们的分析表明,高比特深度对于低光实例分割至关重要。为了缓解标注的RAW数据集的稀缺性,我们利用低光RAW合成流水线生成了逼真的低光数据。此外,为了促进这一方向的进一步研究,我们捕捉了一个真实世界的低光实例分割数据集,包括两千多个配对的低光/正常光图像,带有实例级像素级注释。值得注意的是,在没有任何图像预处理的情况下,我们在非常低的光照条件下实现了令人满意的实例分割性能(比最先进的竞争对手高4%的AP),同时为未来的研究开辟了新的机会。我们的代码和数据集对社区公开可用(https://github.com/Linwei-Chen/LIS)。
一、观察与动机
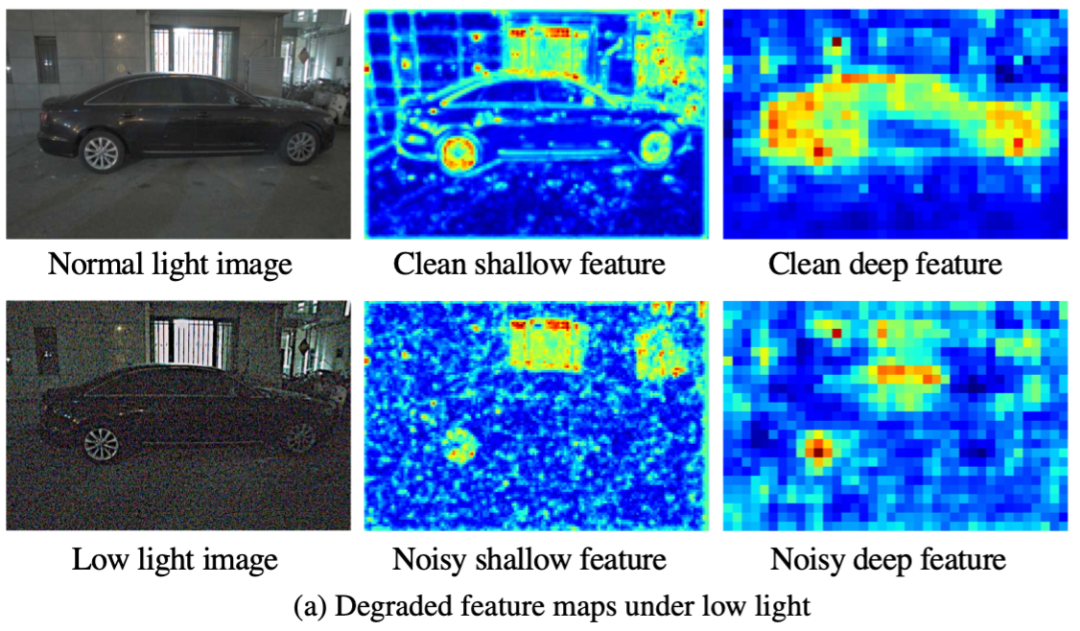

两个关键的观察:
a. 低光下的特征图退化。对于清晰的正常光图像,实例分割网络能够清晰地捕捉浅层和深层中对象的低级(例如,边缘)和高级(即,语义响应)特征。然而,在嘈杂的低光图像中,浅层特征可能会受到污染并充满噪声,而深层特征对对象的语义响应较低。
b. 在黑暗中相机的sRGB输出和RAW图像之间的比较。由于信噪比显著降低,8位相机输出失去了许多场景信息,例如,座椅靠背结构在相机输出中几乎无法辨认,而在RAW图像中仍然可以识别(放大以获得更好的细节)。
Illustration of our key observations under dark regimes that drive our method design: a Degraded feature maps under low light. For clean normal-light images, the instance segmentation network is able to clearly capture the low-level ( e.g., edges) and high-level ( i.e., semantic responses) features of objects in shallow and deep layers, respectively. However, for noisy low-light images, shallow features can be corrupted and full of noise, and the deep features show lower semantic responses to objects. b Comparison between camera sRGB output and RAW image in the dark. Due to significantly low SNR, the 8-bit camera output loses much of the scene information, for example, the seat backrest structure is barely discernible, whereas is still recognizable in the RAW counter- part (Zoom in for better details)
二、挑战与方法
整体方法如下
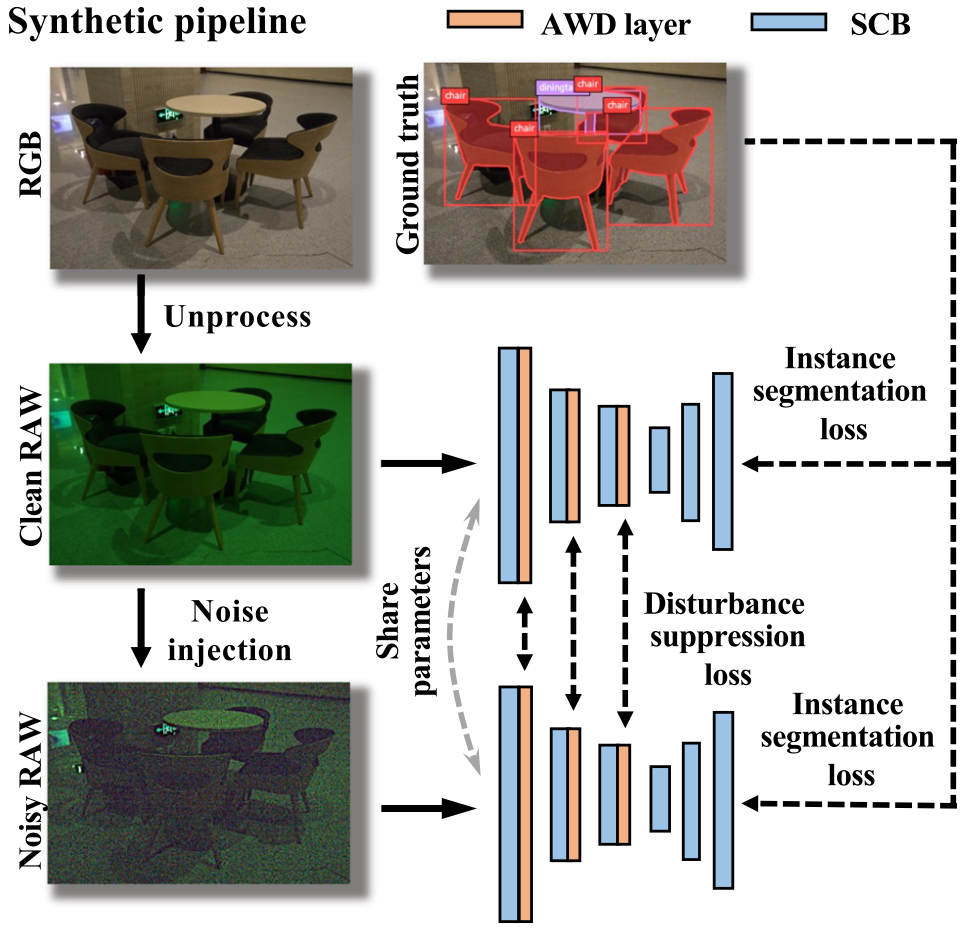
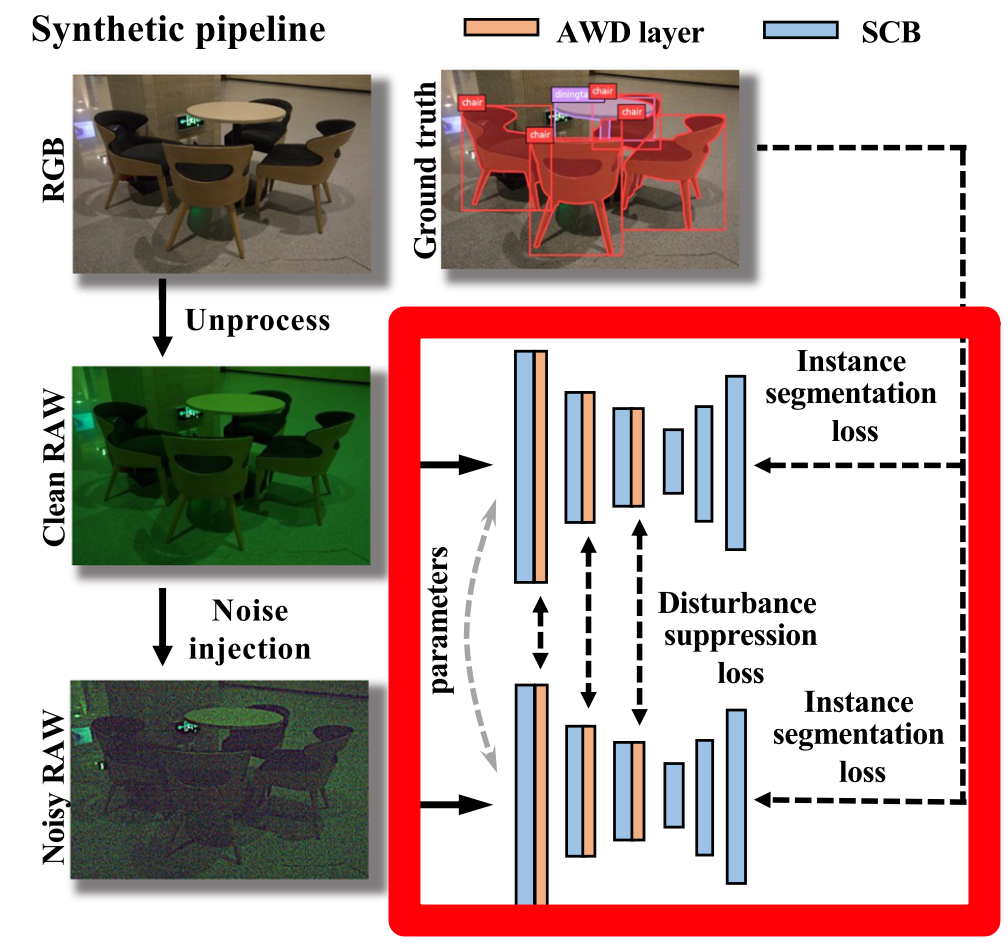
2.1 Low-Light RAW Synthetic Pipeline
挑战:训练一个分割模型需要海量带实例分割标注的数据,而目前并没有此类数据集,额外收集暗光图像并标记大规模暗光数据集成本昂贵,同时,现有RAW数据也十分稀少
解决方案:设计一个从RGB图像到带噪暗光RAW图像的pipeline,从而可以零成本利用现有的实例分割数据集训练得到暗光条件下针对RAW输入的实例分割模型。
我们的低光RAW合成流水线包括两个步骤,即未处理和噪声注入:
逆处理。收集大规模的RAW图像数据集既昂贵又耗时,因此我们考虑利用现有的sRGB图像数据集(Everingham等人,2010年;Lin等人,2014年)。sRGB图像是通过一系列相机内部图像信号处理(ISP)的图像变换操作获得的,例如色调映射、伽马校正、色彩校正、白平衡和去马赛克等。通过未处理操作(Brooks等人,2019年),我们可以反转这些图像处理变换,从而获得RAW图像。通过这种方式,我们可以零成本创建一个RAW数据集。
噪声注入。在通过未处理操作获得干净的RAW图像后,为了模拟真实的嘈杂低光图像,我们需要向RAW图像注入噪声。为了产生更准确的复杂噪声结果,我们采用了最近提出的基于物理的噪声模型(Wei等人,2020年,2021年),而不是广泛使用的Poissonian-Gaussian噪声模型(即异方差高斯模型(Foi等人,2008年))。该模型可以准确地描述真实的噪声结构,考虑了许多噪声源,包括光子射击噪声、读取噪声、带状图案噪声和量化噪声。
Our low-light RAW synthetic pipeline consists of two steps, i.e., unproccessing and noise injection. We introduce them one by one.
Unprocessing. Collecting a large-scale RAW image dataset is expensive and time-consuming, hence we consider utilizing existing sRGB image datasets (Everingham et al., 2010; Lin et al., 2014). The sRGB image is obtained from RAW images by a series of image transformations of on-camera image signal processing (ISP), e.g., tone mapping, gamma correction, color correction, white balance, and demosaicking. With the help of the unprocessing operation (Brooks et al., 2019), we can invert these image processing transforma- tions, and RAW images can be obtained. In this way, we can create a RAW dataset with zero cost.
Noise injection. After obtaining clean RAW images by unprocessing, to simulate real noisy low-light images, we need to inject noise into RAW images. To yield more accurate results for real complex noise, we employ a recently proposed physics-based noise model (Wei et al., 2020, 2021), instead of the widely used Poissonian-Gaussian noise model (i.e., heteroscedastic Gaussian model (Foi et al., 2008)). It can accurately characterize the real noise structures bytakingg into account many noise sources, including photon shot noise, read noise, banding pattern noise, and quantization noise.
2.2 Adaptive Weighted Downsampling Layer
挑战:如何解决图像噪声带来的特征“噪声扰动”

一个简单的观察是,由于图像的平滑先验特性,使用低通滤波下采样图像即可降低噪声水平。
考虑到现有网络通常有多个下采样层,那么岂不是可以充分利用这些下采样过程?实验证明简单插入mean filter就能几乎白嫖到暗光实例分割的性能。
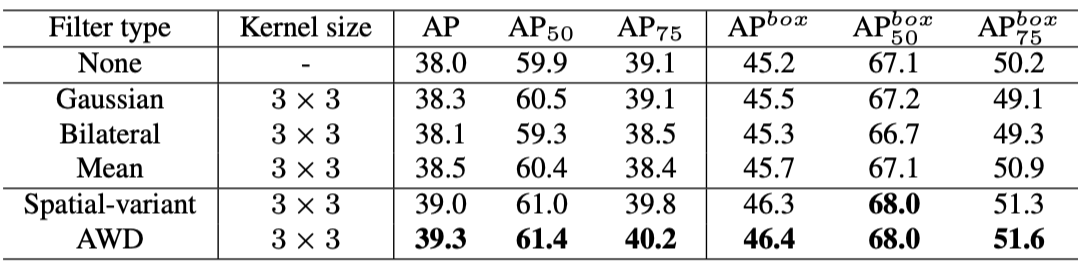
虽然有效,但mean filter之类的固定滤波无法根据特征自适应调整,从而有可能抹除了细节信息,对此作者提出Adaptive Weighted Downsampling Layer,AWD,自适应对特征逐通道逐点预测低通滤波,从而对噪声区域加大力度低通,而细节区域降低低通水平保留细节
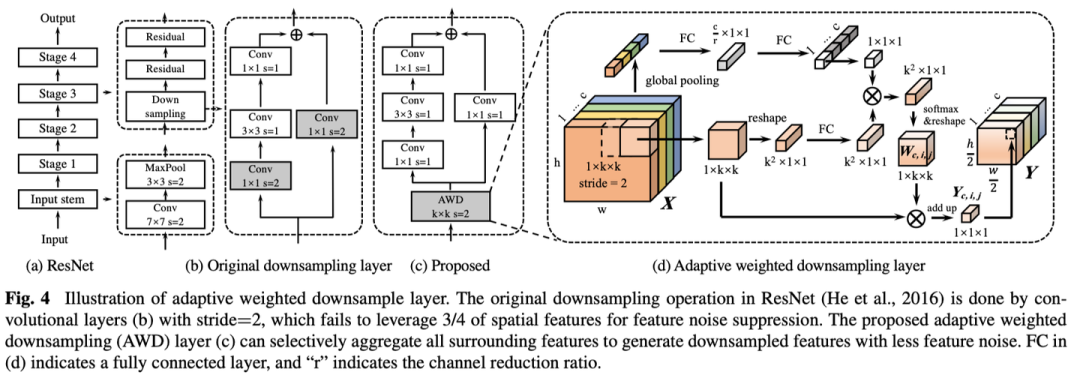
看了源码FC是用Depth-wise替代的,效果等价。公式就不列了,感兴趣可以看原文。
2.3 Smooth-Oriented Convolutional Block
为了进一步降低特征受图像中高频噪声的扰动影响,作者还提出使用重参数化技术,在训练时同时训练一组平滑的卷积核,并在推理时融合到原始卷积核中,这样一来卷积在面对噪声时就更加鲁棒。值得注意的是,这不增加推理时的参数量和计算量!纯纯的白嫖!
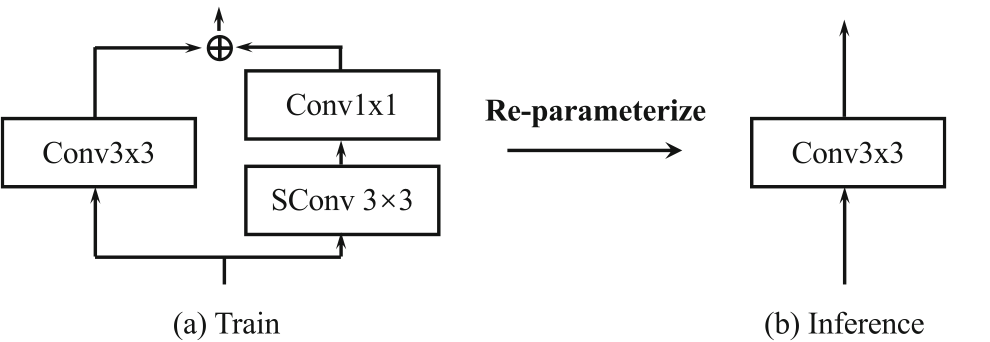
2.4 Disturbance Suppression Learning
同时作者还在模型学习的时候做了一些调整,让模型同时学习干净和带噪图像,并约束输入为带噪图像时的特征更接近干净图像,有点类似知识蒸馏,但无需teacher。这样使得模型不仅提高了暗光下的鲁棒性,同时对光照正常的图像也有提升,这非常符合实际应用情景,即一个模型同时应对白天和黑夜的下的应用。
三、LIS数据集

数据集由Canon EOS 5D Mark IV拍摄,具有如下特性:
- 配对样本。在LIS数据集中,我们提供了sRGB-JPEG(典型相机输出)和RAW格式的图像,每种格式都包括配对的短曝光低光和相应的长曝光正常光图像。我们将这四种类型的图像称为sRGB-暗、sRGB-正常、RAW-暗和RAW-正常。为了确保它们在像素级别对齐,我们将相机安装在坚固的三脚架上,并通过手机应用程序远程控制以避免振动。
- 多样化场景。LIS数据集包括2230对图像,这些图像在各种场景中收集,包括室内和室外。为了增加低光条件的多样性,我们使用一系列ISO级别(例如800、1600、3200、6400)拍摄长曝光参考图像,并故意通过一系列低光因素(例如10、20、30、40、50、100)减少曝光时间,拍摄短曝光图像,以模拟非常低光条件。
- 实例级像素级标签。对于每一对图像,我们提供精确的实例级像素级标签,标注了我们日常生活中8个最常见的物体类别的实例(自行车、汽车、摩托车、公共汽车、瓶子、椅子、餐桌、电视)。我们注意到LIS包含在不同场景(室内和室外)以及不同光照条件下拍摄的图像。在图7中,物体遮挡和密集分布的物体使LIS在低光条件之外更具挑战性。
– Paired samples. In the LIS dataset, we provide images in both sRGB-JPEG (typical camera output) and RAW formats, each format consists of paired short-exposure low-light and corresponding long-exposure normal-light images. We term these four types of images as sRGB- dark, sRGB-normal, RAW-dark, and RAW-normal. To ensure they are pixel-wise aligned, we mount the camera on a sturdy tripod and avoid vibrations by remote control via a mobile app.
– Diverse scenes. The LIS dataset consists of 2230 image pairs, which are collected in various scenes, including indoor and outdoor. To increase the diversity of low-light conditions, we use a series of ISO levels ( e.g., 800, 1600, 3200, 6400) to take long-exposure reference images, and we deliberately decrease the exposure time by a series of low-light factors ( e.g., 10, 20, 30, 40, 50, 100) to take short-exposure images for simulating very low-light conditions.
– Instance-level pixel-wise labels. For each pair of images, we provide precise instance-level pixel-wise labels annotate instances of 8 most common object classes in our daily life (bicycle, car, motorcycle, bus, bottle, chair, dining table, tv). We note that LIS contains images captured in different scenes (indoor and outdoor), and different illuminationconditionss. In Fig.7, object occlusion and densely distributed objects make LIS more challenging besides the low light.
四、实验结果
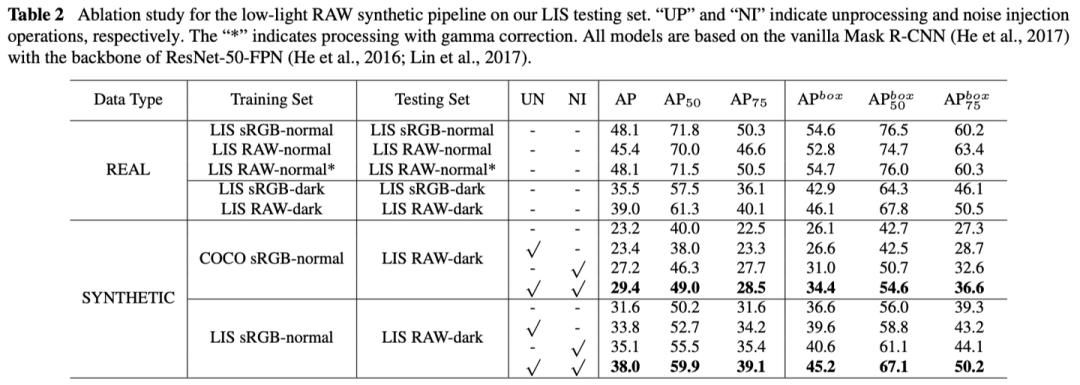
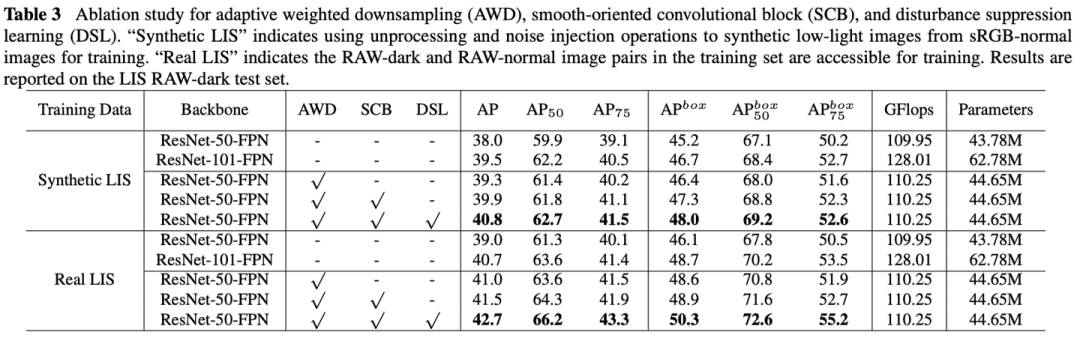
3.1 Ablation
3.2 Main results
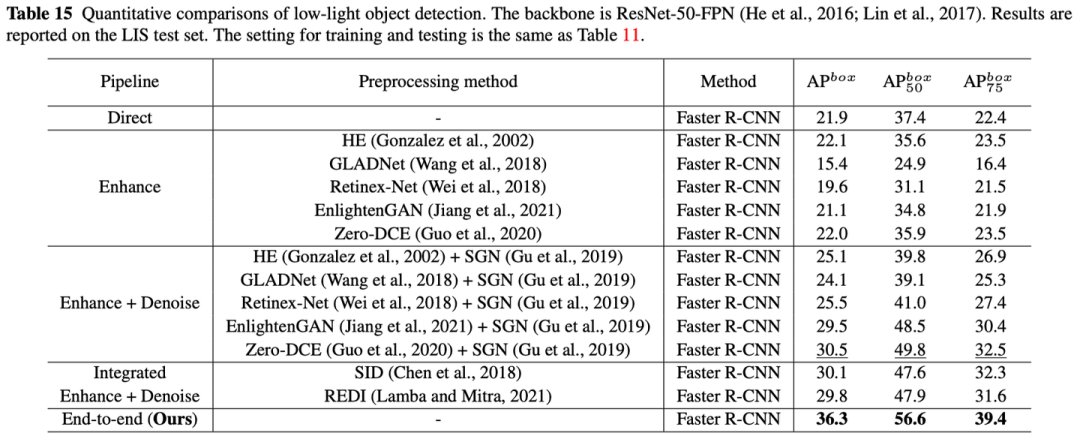
提供了使用Mask R-CNN、PointRend、Mask2Former、Faster R-CNN方法以及主干网络ResNet-50、Swin-Transformer、ConvNeXt在实例分割、目标检测两个任务上证明了有效性:
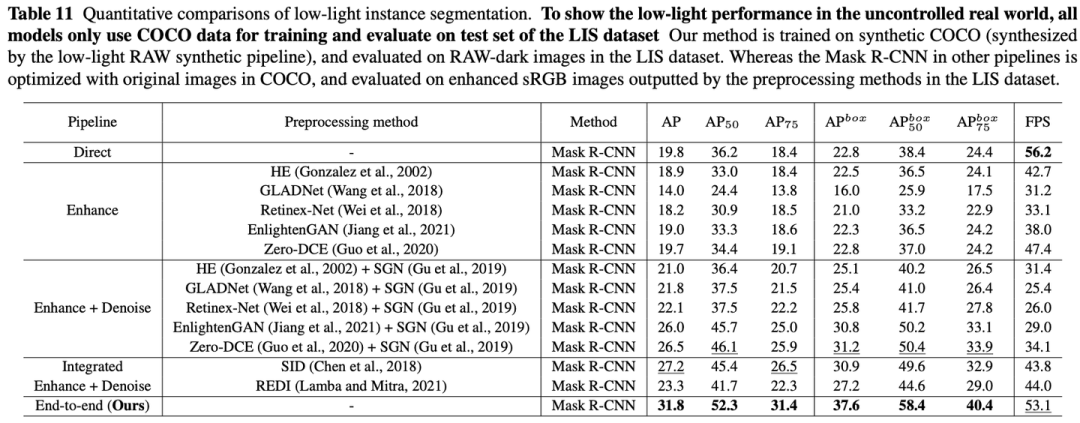
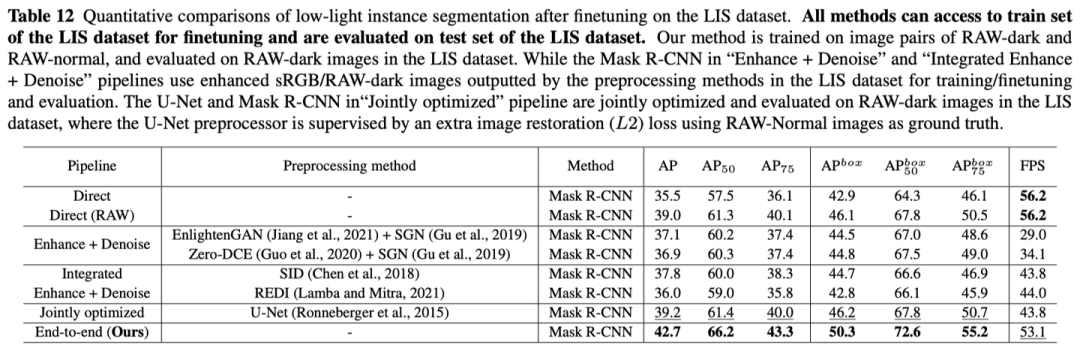
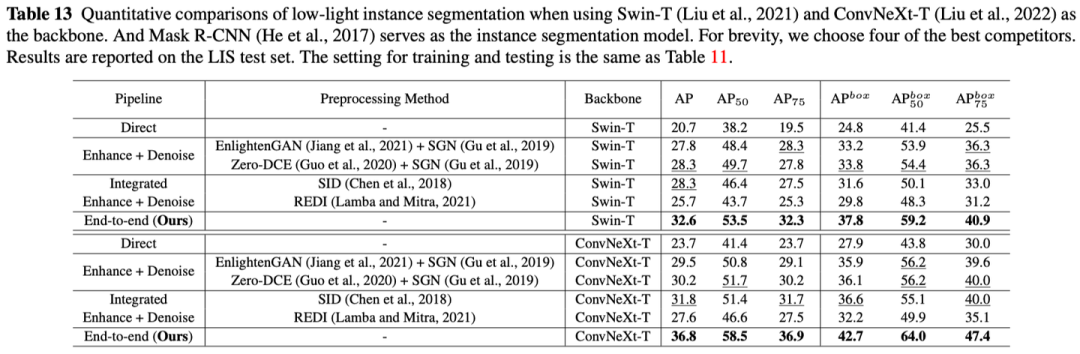
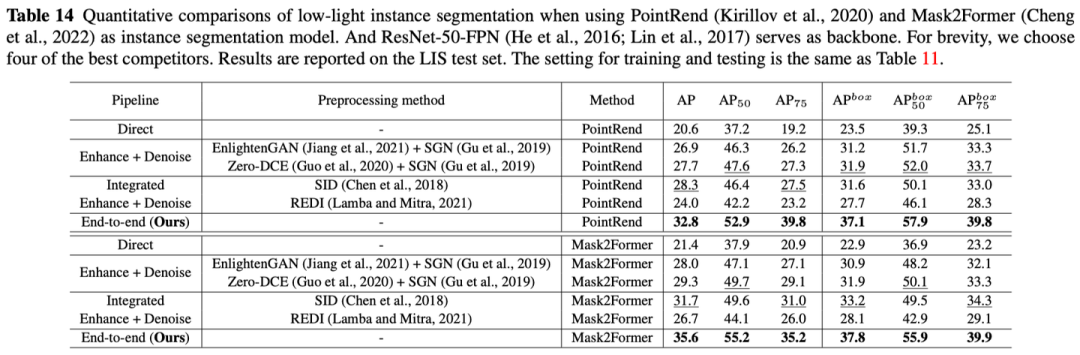
3.3 可视化结果

五、启发
检测分割作为一个大热的主流研究方向,论文层出不穷,要想在红海中闯荡,最好的方式是自己开创一片蓝海。这篇论文找到了实例分割一个新的应用情景,搭建了一套暗光条件下实例分割训练、验证的框架,并从关键的现象观察中得到了一系列简单却有效的方法。可以见得,观察是科研的基础,好的观察能让人发现有趣的现象和问题,从而引导向全新的问题,开辟新的道路。
在CVer微信公众号后台回复:暗光实例分割,可以下载本论文pdf、代码和数据集
点击进入—>【图像分割和Transformer】交流群
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集图像分割和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-图像分割或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!▲扫码进星球▲点击上方卡片,关注CVer公众号这篇关于顶刊IJCV 2023!北理工普林斯顿提出:暗光实例分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








