本文主要是介绍学了1年大数据,来测测你大数据技术掌握程度?大数据综合复习之面试题15问(思维导图+问答库),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我正在参加年度博客之星评选,请大家帮我投票打分,您的每一分都是对我的支持与鼓励。
2021年「博客之星」参赛博主:Maynor大数据 (感谢礼品、红包免费送!)
https://bbs.csdn.net/topics/603955366

前言
大家好,我是ChinaManor,直译过来是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。
时隔一年,终于把主流的大数据组件全部学完了,学成之时,便是出师之日,
那为师便来考考你学的如何:

问题1:Rowkey如何设计,设计规则是什么?
- 业务原则:贴合业务,保证前缀是最常用的查询字段
- 唯一原则:每条rowkey唯一表示一条数据
- 组合原则:常用的查询条件组合作为Rowkey
- 散列原则:rowkey构建不能连续
- 长度原则:满足业务需求越短越好
口诀:月尾煮散肠
又到了月尾业务达不到,唯一不挨饿的办法是煮超市散落的香肠吃。
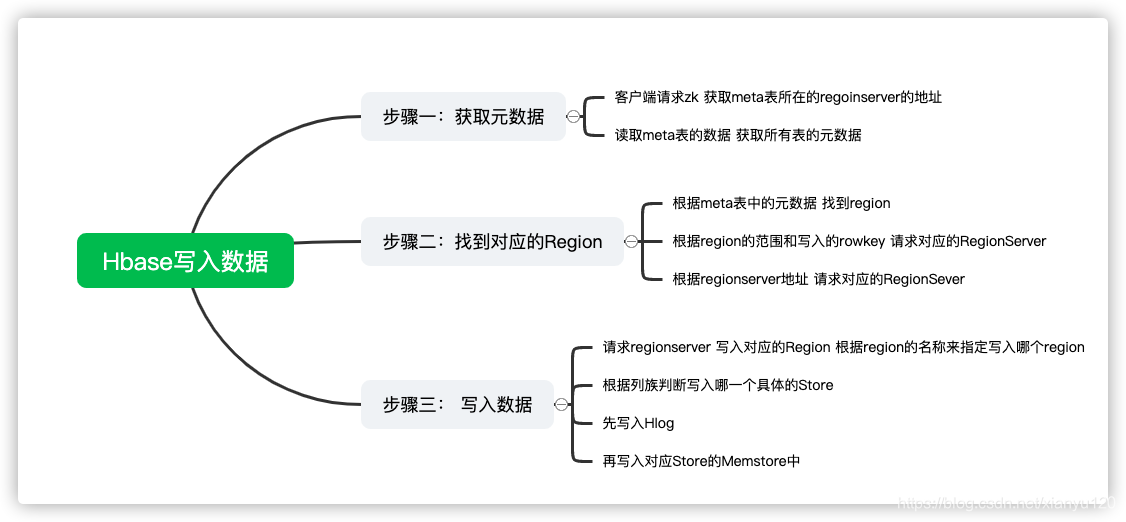
问题2:请简述Hbase写入数据的流程
-
step1:获取元数据
- 客户端请求Zookeeper,获取meta表所在的regionserver的地址
- 读取meta表的数据:获取所有表的元数据
-
step2:找到对应的Region
- 根据meta表中的元数据,找到表对应的所有的region
- 根据region的范围和写入的Rowkey,判断需要写入具体哪一个Region
- 根据region的Regionserver的地址,请求对应的RegionServer
-
step3:写入数据
-
请求RegionServer写入对应Region:根据Region的名称来指定写入哪个Region
-
根据列族判断写入哪一个具体的Store
- 先写入WAL:Hlog预写日志中
-
写入对应Store的MemStore中
-
问题3:协处理器是什么?Hbase中提供了几种协处理器?
- 协处理器指的是Hbase提供了一些开发接口,可以
自定义开发一些功能集成到Hbase中 - 类似于Hive中的UDF
- 协处理器分为两类
Observer:观察者类,类似于监听器的实现Endpoint:终端者类,类似于存储过程的实现
以上面试题出自之前发布的Hbase专栏
Hbase专栏链接
问题4:为什么Kafka读写会很快?
- 写很快
- 应用了PageCache的
页缓存机制 顺序写磁盘的机制
- 应用了PageCache的
- 读很快
- 优先基于PageCache内存的读取,使用
零拷贝机制 - 按照Offset有序读取每一条
- 构建Segment文件段
- 构建index索引
- 优先基于PageCache内存的读取,使用
问题5:请简述Kafka生产数据时如何保证生产数据不丢失?
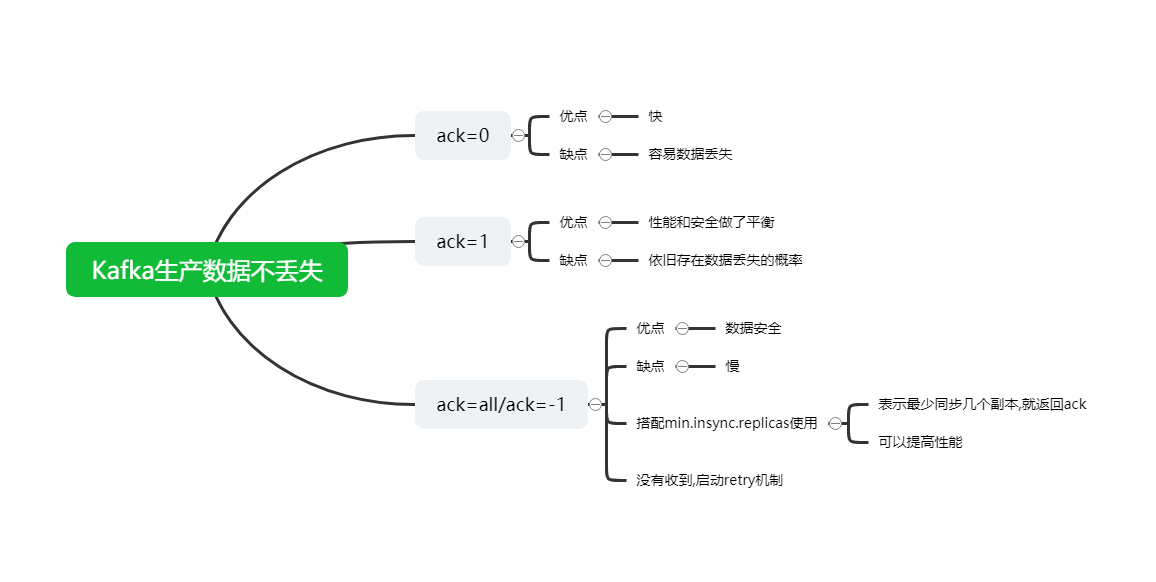
- acks机制:当接收方收到数据以后,就会返回一个确认的ack消息
- 生产者向Kafka生产数据,根据配置要求Kafka返回ACK
- ack=0:生产者不管Kafka有没有收到,直接发送下一条
- 优点:快
- 缺点:容易导致数据丢失,概率比较高
- ack=1:生产者将数据发送给Kafka,Kafka等待这个分区leader副本写入成功,返回ack确认,生产者发送下一条
- 优点:性能和安全上做了平衡
- 缺点:依旧存在数据丢失的概率,但是概率比较小
- ack=all/-1:生产者将数据发送给Kafka,Kafka等待这个分区所有副本全部写入,返回ack确认,生产者发送下一条
- 优点:数据安全
- 缺点:慢
- 如果使用ack=all,可以搭配min.insync.replicas参数一起使用,可以提高效率
- min.insync.replicas:表示最少同步几个副本以后,就返回ack
- ack=0:生产者不管Kafka有没有收到,直接发送下一条
- 如果生产者没有收到ack,就使用重试机制,重新发送上一条消息,直到收到ack
问题6:Kafka中生产者的数据分区规则是什么,如何自定义分区规则?
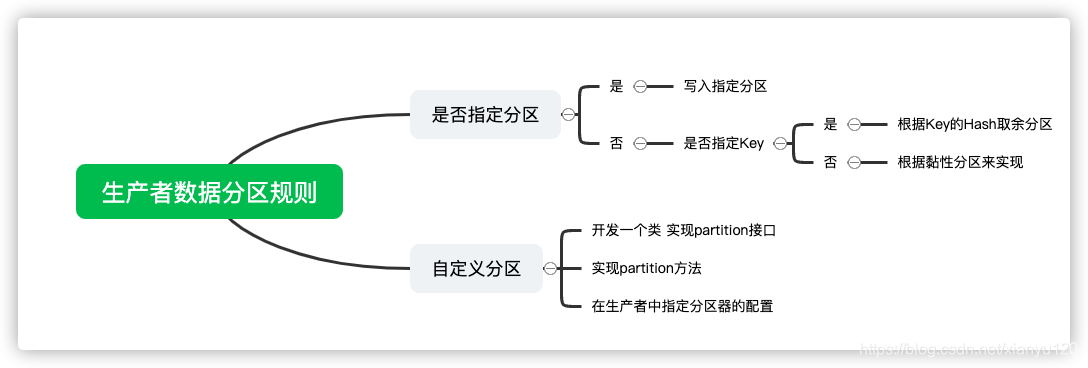
- 如果指定了分区:就写入指定的分区
- 如果没有指定分区,就判断是否指定了Key
- 如果指定了Key:根据Key的Hash取余分区
- 如果没有指定Key:根据黏性分区来实现
- 自定义分区
- 开发一个类实现Partitioner接口
- 实现partition方法
- 在生产者中指定分区器的配置
以上面试题出自之前发布的Kafka专栏
Kafka专栏链接
问题7:简述Spark on yarn的作业提交流程(YARN Cluster模式)
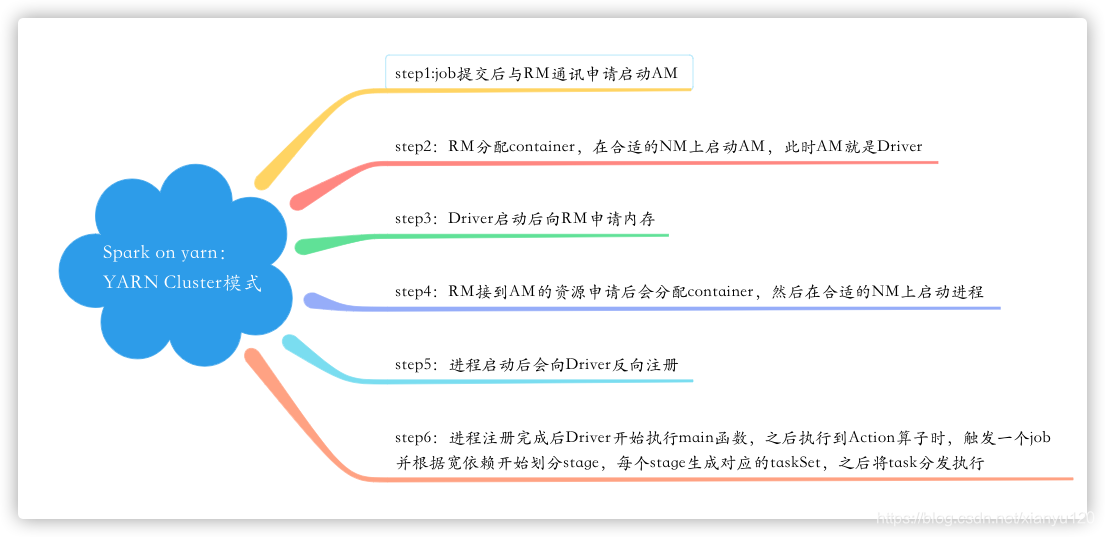
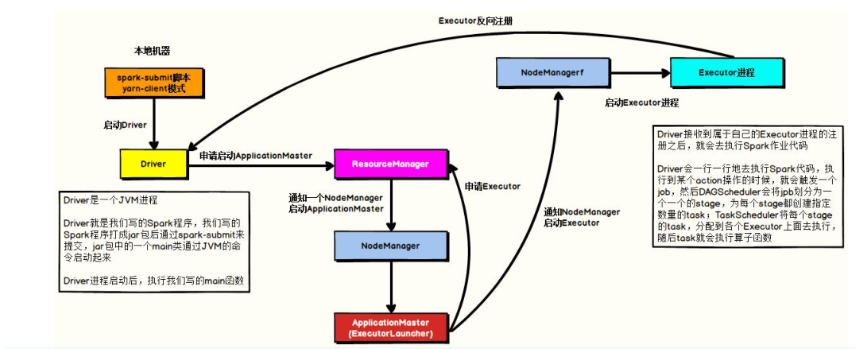
1、任务提交后会和ResourceManager通讯申请启动ApplicationMaster
2、随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
3、Driver启动后向ResourceManager申请Executor内存
4、ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程
5、Executor进程启动后会向Driver反向注册
6、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
问题8:简述Spark on yarn的作业提交流程(YARN Client模式)
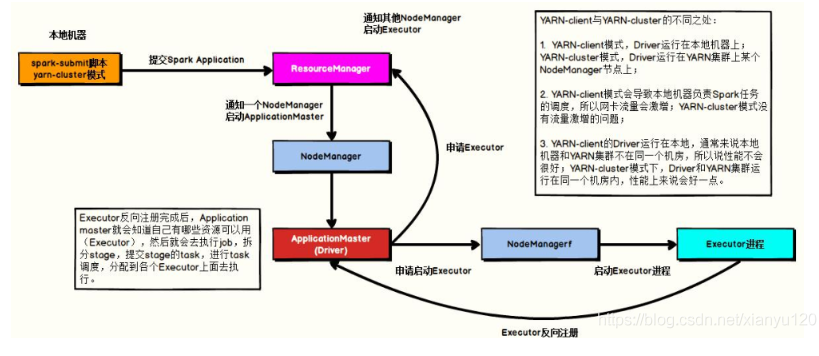
1、Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster
2、随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster
3、此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存
4、ResourceManager接到ApplicationMaster的资源申请后会分配container,ApplicationMaster在资源分配指定的NodeManager上启动Executor进程
5、Executor进程启动后会向Driver反向注册
6、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
问题9:Repartition和Coalesce关系与区别
1)关系:
两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法
2)区别:
repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
问题10:cache和pesist的区别?
cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省 程序运行时间
1) cache只有一个默认的缓存级别MEMORY_ONLY ,cache调用了persist,而persist可以根据情况设置其它的缓存级别;
2) executor执行的时候,默认60%做cache,40%做task操作,persist是最根本的函数,最底层的函数。
以上面试题出自之前发布的Spark专栏
Spark专栏链接
问题11:flink中的水印机制?
1、首先什么是Watermaker?
Watermaker就是给数据再额外的加的一个时间列,也就是Watermaker是个时间戳!
2、其次如何计算Watermaker?
Watermaker = 当前窗口的最大的事件时间 - 最大允许的延迟时间或乱序时间
3、窗口计算的触发条件为:
- 1.窗口中有数据
- 2.Watermaker >= 窗口的结束时间
问题12:Flink的四大基石都有什么?
Checkpoint、State、Time、Window
问题13:Flink的重启策略有哪些?
固定延迟重启策略
失败率重启策略
回调重启策略
无重启策略
古诗会晤
固定的古诗会晤即将在沭阳举行
问题14:请描述一下flink的双流join
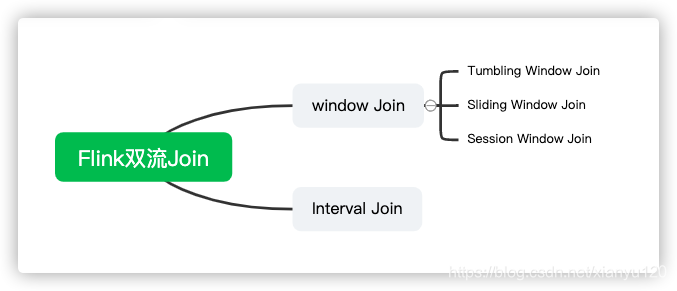
Flink Join大体分类只有两种:Window Join和Interval Join。
- Window Join又可以根据Window的类型细分出3种:
Tumbling Window Join、
Sliding Window Join、
Session Widnow Join
Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作。
- interval join也是利用state存储数据再处理,区别在于state中的数据有失效机制。
问题15:flink on yarn执行任务的两种方式
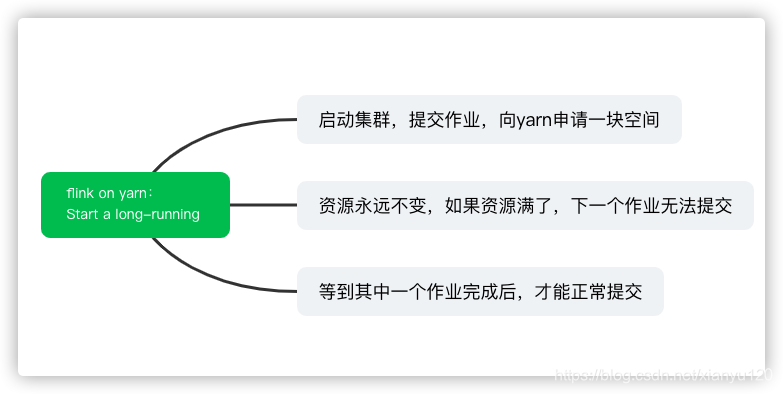
第一种yarn seesion(Start a long-running Flink cluster on YARN)
这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间后,资源保持不变。
如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交.
比较适合特定的运行环境或者测试环境。
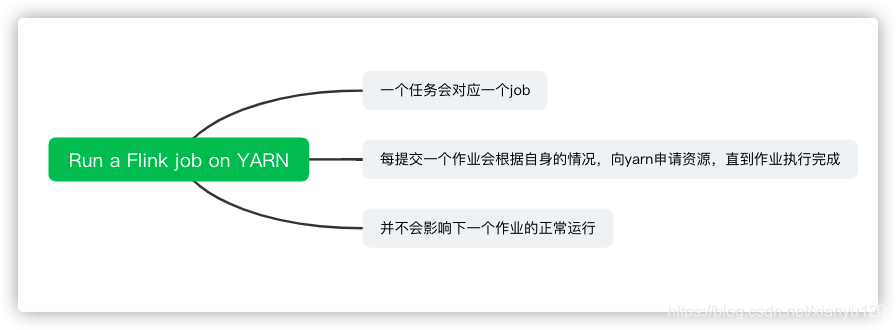
第二种Flink run直接在YARN上提交运行Flink作业(Run a Flink job on YARN),
一个任务会对应一个job,即每提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,
并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。
一般生产环境是采用此种方式运行
以上面试题出自之前发布的Flink专栏
Flink专栏链接
问答库已制作完成
问答库
总结
以上便是大数据综合复习之面试题15问,你都掌握了吗?
愿你读过之后有自己的收获,如果有收获不妨一键三连,我们下期再见👋·

这篇关于学了1年大数据,来测测你大数据技术掌握程度?大数据综合复习之面试题15问(思维导图+问答库)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




