本文主要是介绍Glowworm-高性能轻便的序列化组件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大概介绍一下
别的不说,先上两张图,这两张图是jvm序列化对比测试(https://github.com/eishay/jvm-serializers)的结果。这个对比测试涵盖了适用于java的大部分序列化组件,测试内容包括首先进行一段时间的预热(默认序列化+反序列化3000次),然后分别进行500次序列化和反序列化,最后统计运行时间和序列化之后的大小。
如图所示,我们的glowworm并未名列前茅,可以说只是排名中上游,但你依然可以在glowworm排名的周围看到大名鼎鼎的protobuf。
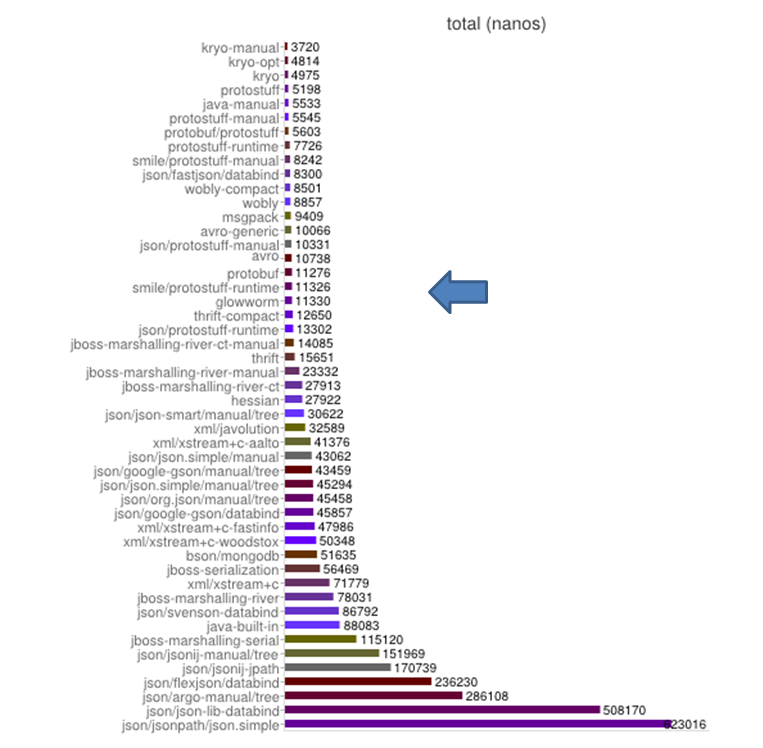 图1.序列化+反序列化的时间
图1.序列化+反序列化的时间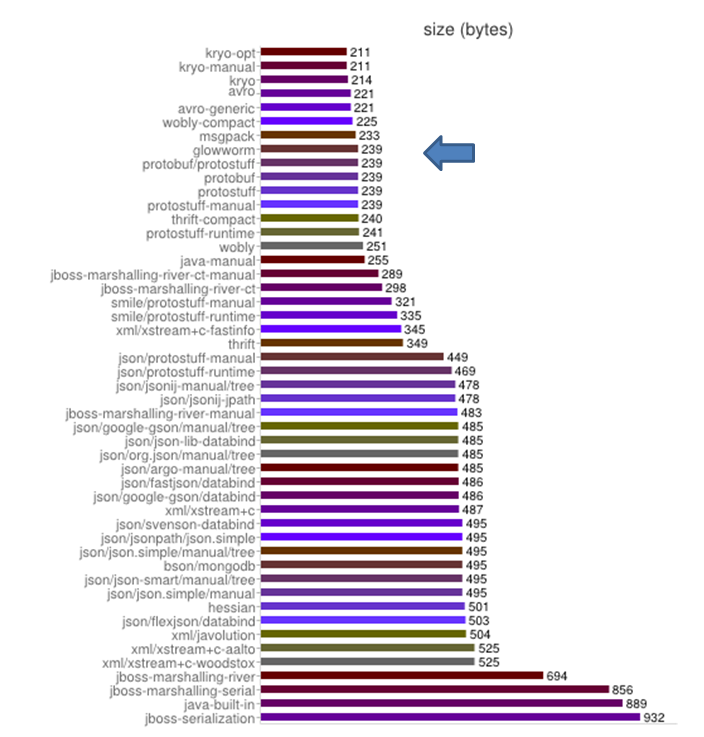 图2.序列化后的大小(byte)
图2.序列化后的大小(byte)
怎么使用glowworm
User user = new User();
byte[] bytes = PB.toPBBytes(user);
User result = (User)PB.parsePBBytes(bytes);这里需要注意一下,glowworm现在的方案是默认写入类名!
这就是最简单的使用方式,PB.toPBBytes(obj)进行序列化,PB.parsePBBytes(bytes, clazz)进行反序列化。反序列化的两个参数分别是序列化之后得到的byte[],和需要反序列化的类型。
如果觉得每次把类名写入到byte[]中比较消耗大小的话,可以手动设定不传类名,那么在反序列化时就需要传入class参数,来告诉glowworm需要反序列化的是哪个类。方法如下:
User user = new User();
Parameters p = new Parameters();
p.setNeedWriteClassName(false);
byte[] bytes = PB.toPBBytes(user, p);
User result = PB.parsePBBytes(bytes,p);需要设定一个参数Parameters,指定needWriteClassName = false即可。
当然如果看了源码的话,发现这个Parameters参数中还可以设定编码,默认为utf-8。Parameters这个参数现在暂时只有这两个用途,如果以后遇到一些特殊的需求,会在这个参数里进行添加。
maven相关
已上传至sonatype.org,如有需要可以配置仓库地址:
<repositories><repository><id>sonatype-nexus-snapshots</id><name>Sonatype Nexus Snapshots</name><url>https://oss.sonatype.org/content/repositories/snapshots</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories>
<groupId>com.jd.dd</groupId>
<artifactId>glowworm</artifactId>
<version>1.0-SNAPSHOT</version>
glowworm是怎么做的
开发glowworm的初衷
众所周知,google的protobuf(http://code.google.com/p/protobuf/)作为老牌的序列化组件在google内部久经考验,在08年时贡献给了开源社区。protobuf无论从性能还是大小来说都是出类拔萃的, 但是我们不得不为每一个user javabean编写对应的proto文件。其实编写proto文件本身无可厚非,序列化就是一个通过解析对象结构把对象转成byte流的过程,解析对象结果本身很是繁琐,耗时耗力。所以protobuf用一个外部文件记录这个对象结构,那么每次遇到相同结构的对象时就省去了再次解析的过程,而且还能跨语言。
对此,fastjson(http://code.alibabatech.com/wiki/display/FastJSON/Home-zh)有不同的看法。不得不说阿里的fastjson是地球上最好的基于json标准的的序列化组件,尤其在性能优化上做了大量的工作。而且用fastjson做序列化不需要写任何idl(Interface description language)文件,对于对象结构的解析会在第一次进行序列化的时候进行,通过asm新建一个这个序列化器的class并保存下来,供以后复用。
但是作为序列化组件fastjson有一个天生的短板,就是json是以字符串进行传输的,而字符串在转化成byte占用了很大的空间,所以即便是强如fastjson也无法把序列化之后的文件大小缩减到很低的水平。从图2中可以看到排名下半部分的都是基于xml或json格式进行序列化的组件,而上半部分多是直接把对象转成byte数组。
为什么不能集合protobuf和fastjson各自的优点开发一个序列化组件,做到既能保证大小又能兼顾性能、而且使用起来轻便快捷呢?。glowworm应运而生。
glowworm的特点
1.不依赖第三方库
2.无需编写idl文件
3.支持各种数据类型
4.整体架构优秀
5.基于byte数组的序列化方案
glowworm支持的类型
1.所有基本类型
2.用户自定义的javabean
3.支持数组,常用的List、Set、Map
4.支持一些特殊类型,现阶段支持的还比较有限,索性就都列在下面了:Date, Time, Timestamp, Enum, InetAddress, AtomicBoolean, AtomicInteger, AtomiceLong, BigDecimal, BigInteger, Class, Exception
5.对泛型有优化,鼓励使用泛型
6.完美支持引用,包括循环引用
glowworm的架构
图3、图4分别是序列化和反序列化的流程
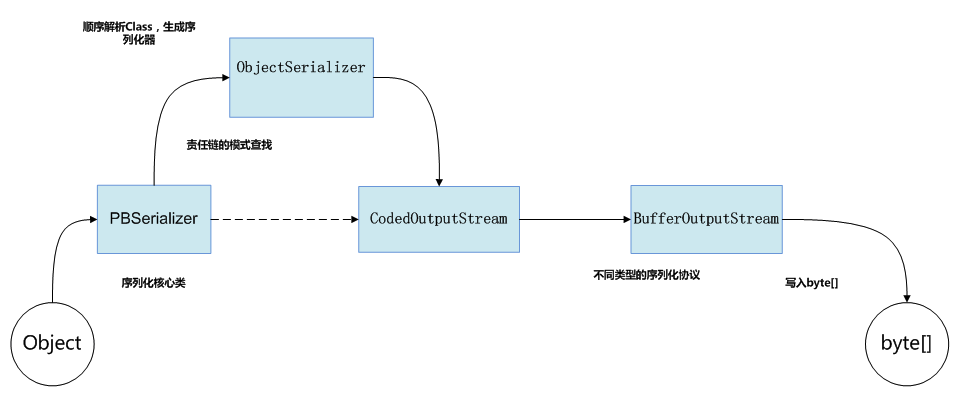 图3.序列化的流程
图3.序列化的流程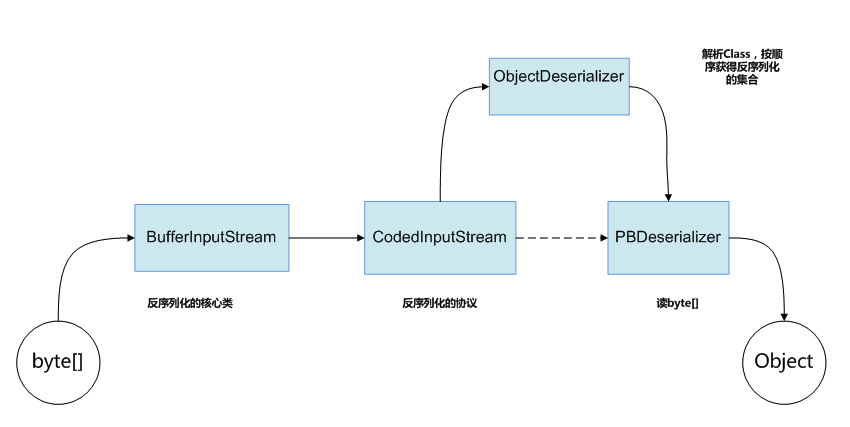 图4.反序列化的流程
图4.反序列化的流程
如图所示,序列化和反序列化其实是对称的。序列化时从object转成byte[]的过程,反序列化是他的逆过程。
以序列化为例,PBSerializer类是序列化的核心类,并且只对序列化器暴露。这样把大部分逻辑都汇总在了一处,方便后续扩展。
在开始进行序列化之前,首先会根据object的类型找到对应的序列化器,如果没有,就使用asm动态生成一个序列化器,并保存在类变量的IdentityHashMap中,和所对应的Class类做映射,以便复用。序列化器中包含了如何针对object结构调用不同方法把内容写入byte[]的逻辑,当然对于一个复杂的javabean而言,外层的序列化器中就是按顺序调用每一个属性的内层序列化器进行序列化,按顺序这点很重要,在下文会提及。
CodedOutputStream内封装了对各种类型进行写入的方法,比如:
public void writeInt(int i) {writeRawVarint32(encodeZigZag32(i));
}
public void writeLong(long l) {writeRawVarint64(encodeZigZag64(l));
}而再往下一层的BufferOutputStream就是实实在在的操作数组了
反序列化的流程就是序列化的逆过程,在此不再赘述。
可以看出,无论是序列化还是反序列化,架构的层级都是一致的,彼此对称的,非常清晰简明,易于理解。
glowworm的技术内幕
因为参考了fastjson的架构,protobuf的协议,这两个著名的序列化组件的一些特点也被glowworm吸收进来。
使用ThreadLocal缓存byte[]
因为每次序列化或反序列化在创建和销毁一个数组以及对数组扩容时都有消耗,所以我们参照fastjson的架构,把这些byte[]包括序列化的内容以及头信息,都保存在ThreadLocal中,便于重复使用。序列化为例,在PBSerializer中声明了ThreadLocal变量,这个变量缓存了所有glowworm中用于保存信息的byte[]。
private final static ThreadLocal<SoftReference<OutputStreamBuffer>> bufLocal = new ThreadLocal<SoftReference<OutputStreamBuffer>>();每次初始化PBSerializer时首先把这个变量从当前线程中取出,进行分析。
//初始化CodedOutputStreamprivate void initBuffer() {SoftReference ref = bufLocal.get();if (ref != null) {outputStreamBuffer = ref.get();if (outputStreamBuffer != null) {theCodedOutputStream = outputStreamBuffer.getTheCodedOutputStream();refStream = outputStreamBuffer.getRefStream();typeStream = outputStreamBuffer.getTypeStream();existStream = outputStreamBuffer.getExistStream();headStream = outputStreamBuffer.getHeadStream();}bufLocal.set(null);}if (theCodedOutputStream == null) {theCodedOutputStream = new CodedOutputStream(new BufferOutputStream(1024));}if (refStream == null) {refStream = new CodedOutputStream(new BufferOutputStream(30));}if (typeStream == null) {typeStream = new TypeOutputStream(50);}if (existStream == null) {existStream = new ExistOutputStream(100);}if (headStream == null) {headStream = new CodedOutputStream(new BufferOutputStream(10));}}在每次序列化结束时会调用close方法,进行把相应的变量暂存入ThreadLocal中
//关闭时缓存bufferpublic void close() {theCodedOutputStream.reset();refStream.reset();existStream.reset();typeStream.reset();typeStream.headReset();headStream.reset();if (outputStreamBuffer == null) {outputStreamBuffer = new OutputStreamBuffer(theCodedOutputStream, refStream, existStream, typeStream, headStream);} else {outputStreamBuffer.setAll(theCodedOutputStream, refStream, existStream, typeStream, headStream);}bufLocal.set(new SoftReference<OutputStreamBuffer>(outputStreamBuffer));theCodedOutputStream = null;refStream = null;existStream = null;typeStream = null;outputStreamBuffer = null;}使用一个特殊的IdentityHashMap优化性能
这个也是fastJson的产物,因为这个map作为类变量存储所有类-序列化器(以及类-反序列化器)的映射,所以会涉及到并发,但采用HashMap在做transfer操作的时候有可能导致死循环,如果采用ConcurrentHashMap性能又不高。所以fastJson使用了IndentityHashMap,其中去掉了key对比过程中的equal操作(实际场景中的key值仅限于Class,用"=="作比较即可),去掉了transfer操作(针对单一系统的常见业务类并不多,无需扩容)。
private static IdentityHashMap theSerializerHMap = new IdentityHashMap();//序列化器的缓存ASM的引入
ASM(http://asm.ow2.org/)是一个字节码操纵框架,可以动态的创建class并加载到java环境中。我们知道为了解析JavaBean的结构,不得不做类反射,而类反射效率不高,很多性能。所以引入了asm,减少了再运行期间的类反射操作。
使用场景就是如果序列化一个用户自定义的JavaBean,我们通过类反射解析这个JavaBean的结构,用asm生成对应的序列化器及反序列化器(其中包括对这个JavaBean属性的调用),以后就可以复用了。达到只做一次类反射的效果。glowworm也参考fastJson从这个框架中把用到的源码直接抠出来,使asm部分的代码不至于太臃肿。
另外,在动态生成序列化器的时候,会把每一个属性的序列化器作为实例变量保存这个javabean的序列化器内部,在第一次进行序列化时为其初始化,以后就可以进行复用了,无需每次都从IdentityHashMap中查找。
序列化协议方面
glowworm现阶段使用的序列化协议基本照搬protobuf的,并不是说protobuf的协议就是最好的,只是暂时还没有发现更好的。比如针对int类型的序列化协议,protobuf就略有不同。我们都知道常规32位int转成byte需要4个byte,但事实上业务中接近Integer.MAX_VALUE大小的整形使用并不多,所以4位byte显然是有浪费的。所以对于正整数使用varint算法,int转成byte的大小是根据int数值大小的不定值。int数值小则有可能只需要2个byte,而Integer.MAX_VALUE则需要6个。而对于负整数,我们首先会先进行ZigZag之后再通过varint转成byte[],同样可以节省int向byte转化之后的大小。
glowworm序列化时是不传属性名的
这也是为什么序列化之后的文件和采用json规范相比大小优势这么明显。glowworm序列化的时候不传属性名,但是会提前对所有属性进行排序,保证序列化与反序列化时属性的写和读的顺序是一致的。这点在之后会提到的对引用的处理上也至关重要。
对于对象类型以及非空与否的优化
如果User user = new User();如此声明一个对象的话,我们自然知道这个对象的结构,但如果遇到用Object进行声明,或者在集合声明时没有加入泛型的话。glowworm在序列化时需要写入Type来标识这个对象的类型。
public class Type {//0~7为所有常用类型public static final int OBJECT = 0;public static final int BOOLEAN = 1;public static final int INT = 2;public static final int LONG = 3;public static final int DOUBLE = 4;public static final int STRING = 5;public static final int LIST_ARRAYLIST = 6;public static final int MAP_HASH = 7;//非常用类型按顺序往下排public static final int CHAR = 8;public static final int BYTE = 9;public static final int SHORT = 10;public static final int FLOAT = 11;public static final int BIGDECIMAL = 12;public static final int BIGINTEGER = 13;//一下省略...
}我们事先约定可以序列化的类型不超过64种。首先筛选出常用的类型8种,非常用类型30多种(以后如果有需要继续添加)。这样用3位bit(注意是bit哦~)就可以标识常用类型,6位bit标识费常用类型。另外加1位bit用来标识是常用类型还是飞常用类型。对比最初的用1位BYTE来标识类型,大小上缩减不少。
下面这个方法就是操作写入对象类型的逻辑
public void write(int i) {if (i < 8) {//如果是常用类型write(true);//typeHead里写0if (bitPos % 8 < 6 || bitPos == 0) {//要加的这3个bit在这个8个bit之内byte b1 = bitPos % 8 == 0 ? 0 : buffer[pos];b1 = (byte) (b1 | (i << (5 - (bitPos % 8))));buffer[pos] = b1;bitPos += 3;if (bitPos % 8 == 0 && bitPos != 0) {pos++;checkCapacity(pos);}} else {//如果需要进位int thisbitNum = 3 - (bitPos + 3) % 8;//拿thisbitNum == 2举例,可以写在当前byte中有两位bit,所以下面算法是,首先把byte左移两位。//把i & 6 >> 1的意思是i这个三位bit,与110这三位bit向与,然后又移1位,获得两位bit//再与之前的计算结果向或if (thisbitNum == 2) {buffer[pos] = (byte) (buffer[pos] | ((i & 6) >> 1));pos++;checkCapacity(pos);buffer[pos] = (byte) ((i & 1) << 7);} else if (thisbitNum == 1) {buffer[pos] = (byte) (buffer[pos] | ((i & 4) >> 2));pos++;checkCapacity(pos);buffer[pos] = (byte) ((i & 3) << 6);}bitPos += 3;}} else {//非常用类型write(false);//typeHead里写1if (bitPos % 8 < 3 || bitPos == 0) {//要加的这3个bit在这个8个bit之内byte b1 = bitPos % 8 == 0 ? 0 : buffer[pos];b1 = (byte) (b1 | (i << (2 - (bitPos % 8))));buffer[pos] = b1;bitPos += 6;if (bitPos % 8 == 0 && bitPos != 0) {pos++;checkCapacity(pos);}} else {//如果需要进位int thisbitNum = 6 - (bitPos + 6) % 8;if (thisbitNum == 5) {buffer[pos] = (byte) (buffer[pos] | ((i & 62) >> 1));pos++;checkCapacity(pos);buffer[pos] = (byte) ((i & 1) << 7);} else if (thisbitNum == 4) {buffer[pos] = (byte) (buffer[pos] | ((i & 60) >> 2));pos++;checkCapacity(pos);buffer[pos] = (byte) ((i & 3) << 6);} else if (thisbitNum == 3) {buffer[pos] = (byte) (buffer[pos] | ((i & 56) >> 3));pos++;checkCapacity(pos);buffer[pos] = (byte) ((i & 7) << 5);} else if (thisbitNum == 2) {buffer[pos] = (byte) (buffer[pos] | ((i & 48) >> 4));pos++;checkCapacity(pos);buffer[pos] = (byte) ((i & 15) << 4);} else if (thisbitNum == 1) {buffer[pos] = (byte) (buffer[pos] | ((i & 32) >> 5));pos++;checkCapacity(pos);buffer[pos] = (byte) ((i & 31) << 3);}bitPos += 6;}}}不仅如此,考虑到javabean的每一个属性都有可能为空。我们用1位bit来标识是否存在这个属性。这样对大小的缩减来看,越复杂的javabean,缩减的越明显。
针对集合的优化
glowworm对于集合的序列化做了很多工作。这里的集合指的是广义上的集合,包括Array,List,Set,Map。在序列化时这四种类型集合的操作其实没本质差异。在我们看来都是对集合做循环,每次循环把集合内的元素写入byte数组(对于map来说,就是指其中的Entry作为元素)。针对这四种类型的集合的序列化,我们提出一个序列化器的基类,作为MultiSerializer
public abstract class MultiSerializer {public abstract Object getEachElement(Object multi, int i);protected boolean isInterface(Object[] extraParams) {return extraParams.length == 2 && (Boolean) extraParams[1];}//无泛型或泛型为Objectprotected void writeObjectElement(PBSerializer serializer, Object multi, int size) {try {ObjectSerializer preWriter = null;Class preClazz = null;for (int i = 0; i < size; i++) {Object item = getEachElement(multi, i);if (item == null) {serializer.writeNull();} else {Class clazz = item.getClass();if (clazz == preClazz) {if (serializer.needConsiderRef(preWriter) && serializer.isReference(item)) {serializer.writeNull();} else {serializer.writeNotNull();if (serializer.isAsmJavaBean(preWriter)) {serializer.writeType(com.jd.dd.glowworm.asm.Type.OBJECT);serializer.writeString("");//写入空类名}preWriter.write(serializer, item, true);}} else {preClazz = clazz;preWriter = serializer.getObjectWriter(clazz);if (serializer.needConsiderRef(preWriter) && serializer.isReference(item)) {serializer.writeNull();} else {serializer.writeNotNull();if (serializer.isAsmJavaBean(preWriter)) {serializer.writeType(com.jd.dd.glowworm.asm.Type.OBJECT);serializer.writeString(clazz.getName());//写入类名}preWriter.write(serializer, item, true);}}}}} catch (Exception e) {e.printStackTrace();}}//有明确泛型protected void writeElementWithGerenic(PBSerializer serializer, Object multi, Class elementClazz, int size) {ObjectSerializer objectSerializer = serializer.getObjectWriter(elementClazz);boolean needConsiderRef = serializer.needConsiderRef(objectSerializer);for (int i = 0; i < size; i++) {Object item = getEachElement(multi, i);if (item == null) {serializer.writeNull();} else {if (needConsiderRef && serializer.isReference(item)) {serializer.writeNull();} else {serializer.writeNotNull();try {objectSerializer.write(serializer, item, false);} catch (IOException e) {e.printStackTrace();}}}}}
}如代码中所示,写入操作明确分为针对泛型和无泛型(包括泛型为Object的情况)两种操作。区别在于如果有泛型,则我们不用对集合中的每一个元素写入Type。而对于无泛型的情况,我们会在写入第一个元素时附带这个元素的type,如果是用户自定义的javabean,我们还会附带类名。然后在写下一个元素时会检查类型是否与前一个元素相同,如果类型相同的话,我们就可以省去上述操作。这样即便对无泛型的集合进行序列化时也能一定程度上对大小进行控制。
对于每一个集合的序列化器只需继承这个父类,然后实现getEachElement方法即可。
针对引用
对于任意一个Javabean来说,引用都是一个很棘手的问题。假设以下这个Javabean:
public class LoopPerson1 {private byte b;private LoopPerson1 brother;public LoopPerson1 getBrother() {return brother;}public void setBrother(LoopPerson1 brother) {this.brother = brother;}public byte getB() {return b;}public void setB(byte b) {this.b = b;}
}有可能属性brother会指向自己的引用,那么常规序列化的时候就会造成死循环。glowworm是如何处理这个问题的呢?我们在每一个对象序列化时会维护这个对象的index,相当于序列化时的写入顺序,并与之前已经被序列化过得对象进行比较,如果发现两个对象引用相同。则记录这个index。在反序列化时根据这个index找到对应的引用即可。
最后提一下
这个组件,我们进行了相关功能测试,测试代码已包含在源码中。
这篇关于Glowworm-高性能轻便的序列化组件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




