本文主要是介绍python处理FNL数据的grib文件和nc文件(纬度存储的问题),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在使用python处理FNL数据时,2007年及之前的数据存储为grib文件,2007年以后为grib2文件,在数据处理时,将grib2转化为nc文件处理Windows上python读取grib2文件(不用Linux),对grib文件则安装了Anaconda环境处理Windows下xarray+cfgrib读取grib文件。但在根据经纬度读取变量的时候,发现不同文件的存储不同,而变量是根据经纬度存储的下标去获取值,所以需要注意一下不同的文件的存储内容。
1.python获取FNL的nc文件对应的变量
nc_obj =Dataset('F:/Zhu/download/2000-2015/NC/NC2008/fnl_20080113_06_00.nc')
nc_obj.variables[name][0][lat][lon] 根据变量名,经纬度提取变量值
从FNL的nc文件中获取变量的方式如上,需要根据变量名,第一个是time,这里是一维存储,下标只有0即可。然后是纬度,经度获取变量的值。
先看一下,FNL的nc文件中纬度的存储:
print(nc_obj.variables['latitude'][:])
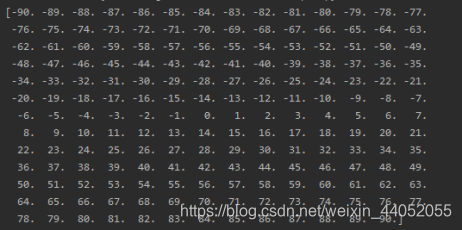
从结果可以看到,纬度是整数存储,从-90到90,共181维。
再看一下FNL的nc文件中经度的存储:
print(nc_obj.variables['longitude'][:])
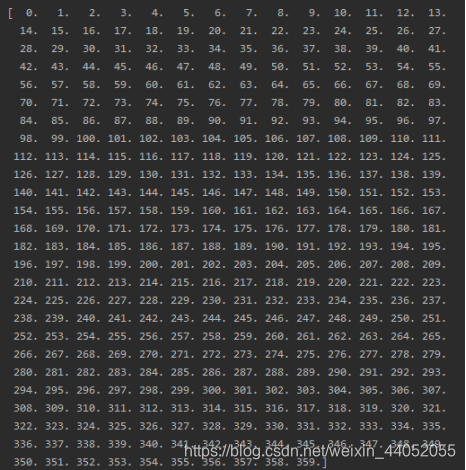
可以从结果看到经度是从0到359度,整数存储,共360维。
所有数据都存储在181x360的整数网格点上。
看一下存储array下标与纬度的关系:
lat = 12
lon = 128
print(nc_obj.variables['latitude'][lat])
print(nc_obj.variables['longitude'][lon])
赋予纬度经度特定的值,观察值在array中的取值
-78.0
128.0
可以发现下标与真实的纬度值之间差了90
print(nc_obj.variables['latitude'][lat + 90])
print(nc_obj.variables['longitude'][lon])
12.0
128.0
经度的下标则与真实的值对应。
所有变量的提取都是根据对应的经纬度下标
以读取UGRD_200mb示例:
print(nc_obj.variables['UGRD_200mb'][:])

结果则是全部网格点上的数据,提取latitude:-90,longitude:0的U200则如下:
print(nc_obj.variables['UGRD_200mb'][0][0][0])
-3.8
因此在计算真实的纬度后,从FNL的nc文件中获取对应变量的的值时,纬度需要加90即真实纬度对应的下标。
2.python获取FNL的grib文件对应的变量
grib文件变量的提取需要根据grib文件以及对应需要提取的level获取数据,
def readgrib_level(filein, lev):data = xr.open_dataset(filein, engine='cfgrib',backend_kwargs={'filter_by_keys': {'typeOfLevel': 'isobaricInhPa', 'level': lev}})return data
获取grib文件的纬度存储
filein = 'F:/Zhu/download/2000-2015/FNL_Data/fnl_20000101_00_00'
nc_obj = readgrib_level(filein, 200)
print(nc_obj.variables['latitude'])
 可以发现FNL的grib文件与nc文件纬度存储不同,从90到-90整数存储,维度为181。
可以发现FNL的grib文件与nc文件纬度存储不同,从90到-90整数存储,维度为181。
再看一下经度存储:
print(nc_obj.variables['longitude'])

可以看到存储与nc文件相同,从0到359,360维。
以读取200hpa的u为例:
print(nc_obj.variables['u'][:])

根据经纬度下标获取变量
print((nc_obj.variables['u'][0][0]).values)
4.4
与nc文件提取变量相同,也是根据经纬度下标提取变量。
因此对于grib文件的数据,在计算真实维度后,需要使用90-真实纬度,得到提取变量对应的下标位置:
lat = 12
print((nc_obj.variables['latitude'][lat]).values)
78.0
print((nc_obj.variables['latitude'][90-lat]).values)
12.0
因此对于FNL的nc文件和grib文件存储不同,需要注意。
这篇关于python处理FNL数据的grib文件和nc文件(纬度存储的问题)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






