本文主要是介绍Oracle Exadata X7-2掉电宕机导致集群无法启动处理过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、当前的状态是什么?
- 二、集群启动异常怀疑对象
- 1.排查心跳网络异常
- ping自己私有IP延迟高
- ping其它主机私有IP不通
- 2.是否发生过重启
- 三、日志信息收集
- ocssd.trc
- 集群crs日志
- cell的griddisk状态及报错
- 四、IB交换机的问题排查处理
- 五、紧急恢复业务
- 在IB完成正常重启后,重新启动所有cell服务
- 拉起集群:
- 六、收尾工作
- check修复第二台IB交换机
- 重新挂载nfs共享目录
- 检查PDU,确实已掉电
- 七、原因调查
- PDU问题由于29日晚操作切电操作导致UPS路跳闸
- 主机等log显示电源切换
- 29日有检测到FAN0风扇数值是0
- 总结
前言
客户突然联系说应用无法连接数据库,报错如下:
[ERROR]-[Thread: Druid-ConnectionPool-Create-26728049]-[com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run()]: create connection error, url: jdbc:oracle:thin:@x.x.x.93:1521:empdb011, errorCode 17002, state 08006
java.sql.SQLRecoverableException: IO 错误: The Network Adapter could not establish the connectionat oracle.jdbc.driver.T4CConnection.logon(T4CConnection.java:774)at oracle.jdbc.driver.PhysicalConnection.connect(PhysicalConnection.java:688)at oracle.jdbc.driver.T4CDriverExtension.getConnection(T4CDriverExtension.java:39)at oracle.jdbc.driver.OracleDriver.connect(OracleDriver.java:691)at com.alibaba.druid.filter.FilterChainImpl.connection_connect(FilterChainImpl.java:148)at com.alibaba.druid.filter.stat.StatFilter.connection_connect(StatFilter.java:220)at com.alibaba.druid.filter.FilterChainImpl.connection_connect(FilterChainImpl.java:142)at com.alibaba.druid.filter.FilterAdapter.connection_connect(FilterAdapter.java:785)at com.alibaba.druid.filter.FilterChainImpl.connection_connect(FilterChainImpl.java:142)at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1463)at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1525)at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2100)
Caused by: oracle.net.ns.NetException: The Network Adapter could not establish the connectionat oracle.net.nt.ConnStrategy.execute(ConnStrategy.java:523)at oracle.net.resolver.AddrResolution.resolveAndExecute(AddrResolution.java:521)at oracle.net.ns.NSProtocol.establishConnection(NSProtocol.java:660)at oracle.net.ns.NSProtocol.connect(NSProtocol.java:286)at oracle.jdbc.driver.T4CConnection.connect(T4CConnection.java:1438)at oracle.jdbc.driver.T4CConnection.logon(T4CConnection.java:518)... 11 more
Caused by: java.io.IOException: Connection timed out: connect, socket connect lapse 20998 ms. /x.x.x.93 1521 0 1 trueat ora
一、当前的状态是什么?
集群状态宕掉了,且无法正常启动!!!
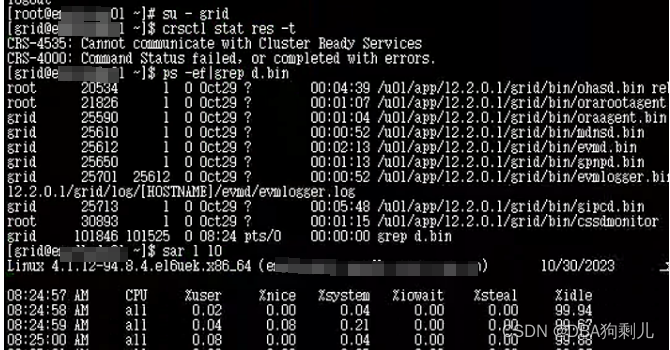
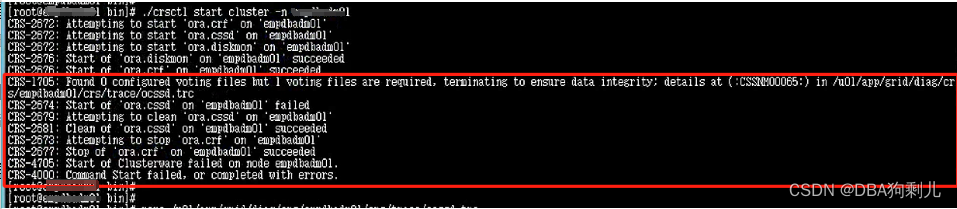
二、集群启动异常怀疑对象
1.排查心跳网络异常
ping自己私有IP延迟高
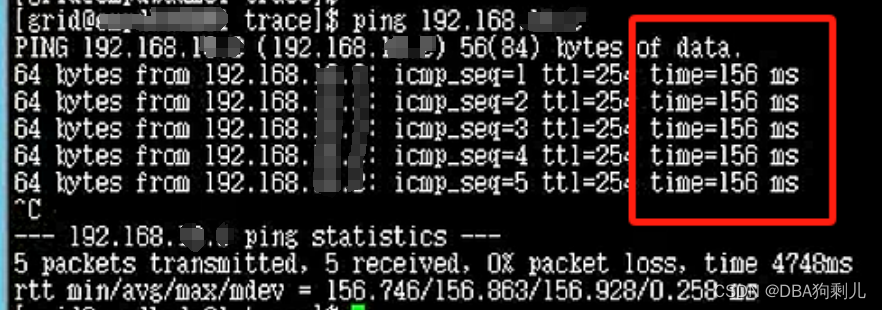
ping其它主机私有IP不通
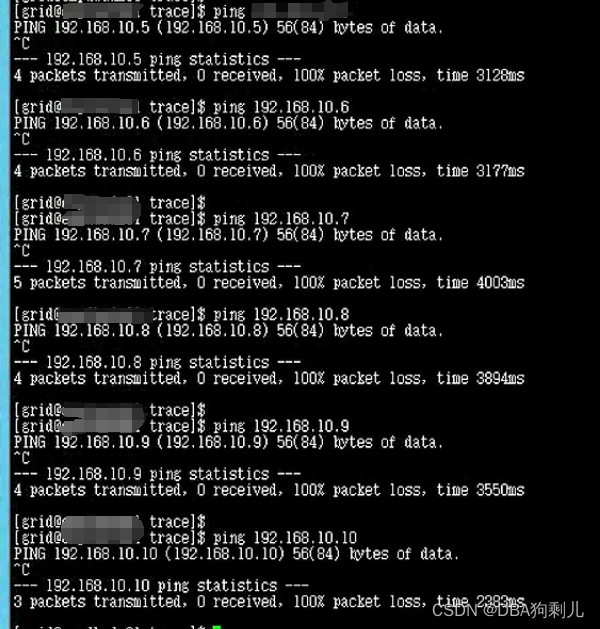
那么问题定位到私有IP不通导致的集群无法启动,一体机内部私有IP交互是通过自身的IB交换机完成的,很有可能是IB交换机问题,下面进行日志查询取证。
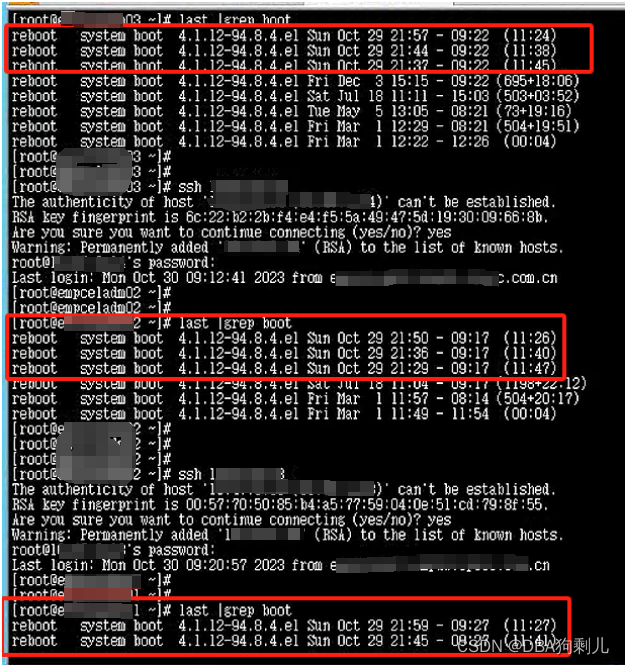
2.是否发生过重启
每台机器都发生过重启,明显掉电情况
三、日志信息收集
ocssd.trc

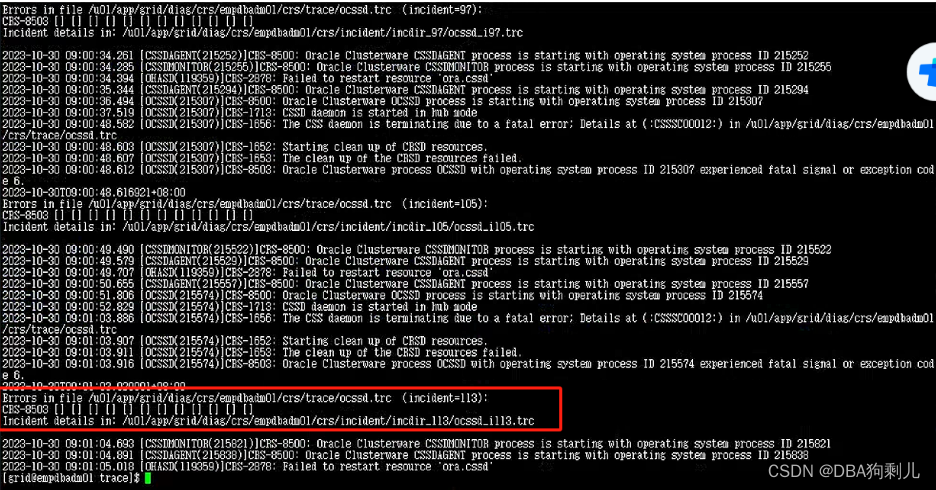
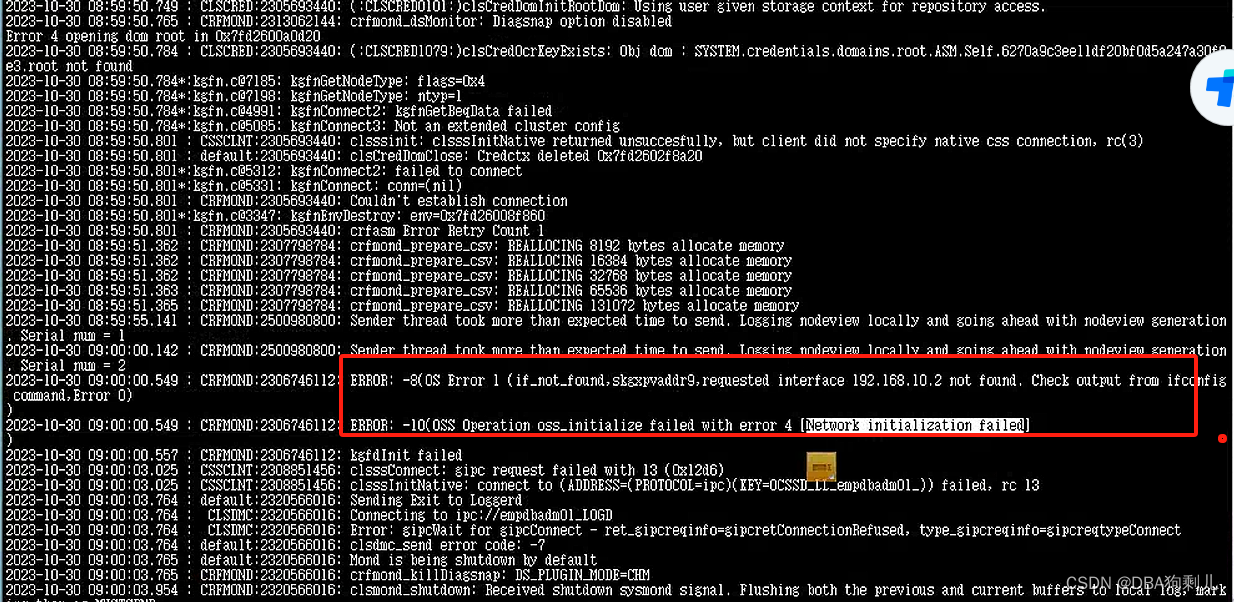
集群crs日志
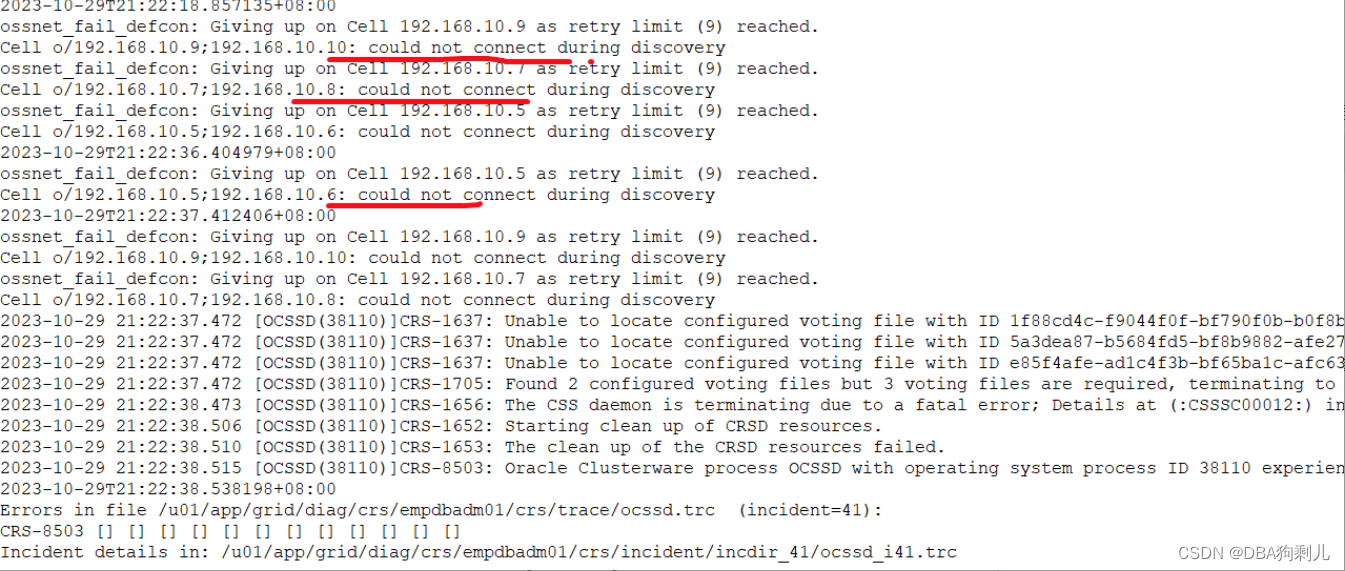
cell的griddisk状态及报错

尝试启动:

那么排查到这里可以断定,是由于上层问题导致的griddisk不正常无法拉起集群,此处上层的IB交换机就成为重要排查对象。
四、IB交换机的问题排查处理
通过融合IP登入ilom管理网页失败,只能通过ssh
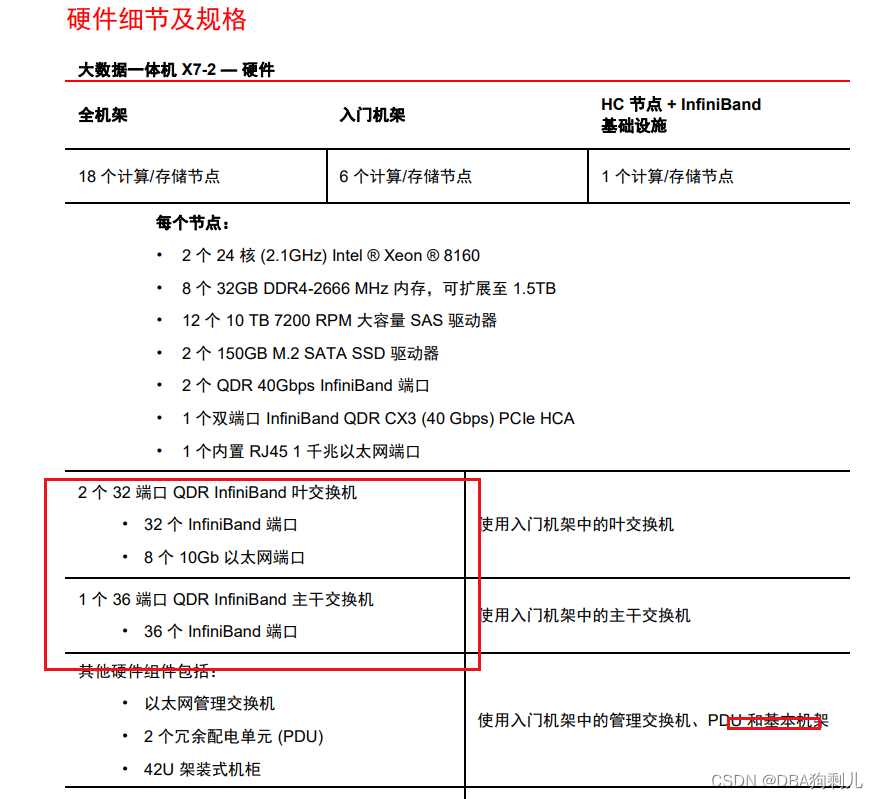
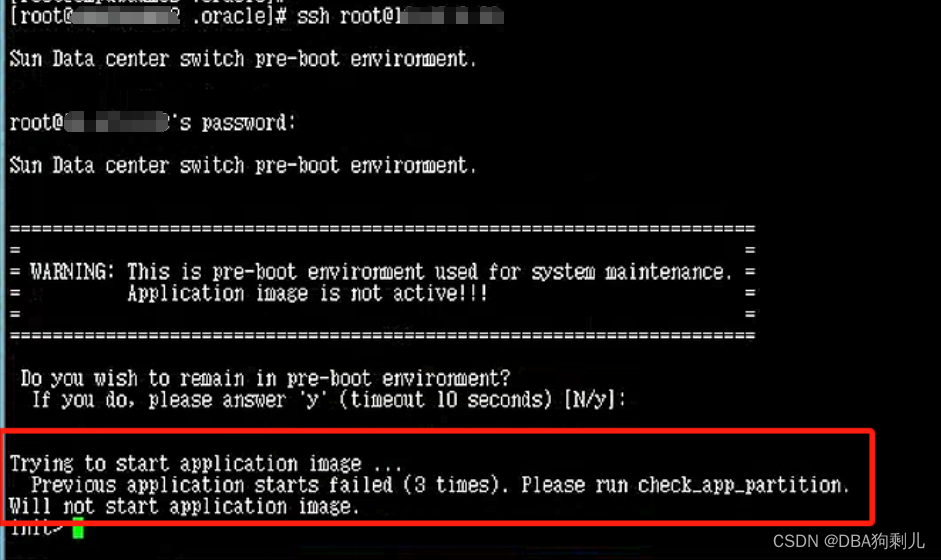
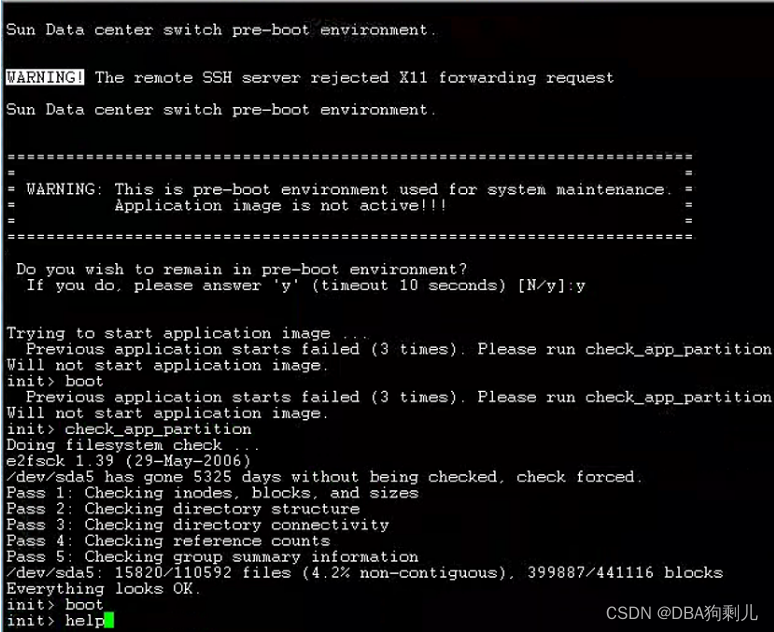
登入后看到明显的提示,尝试boot重启失败:
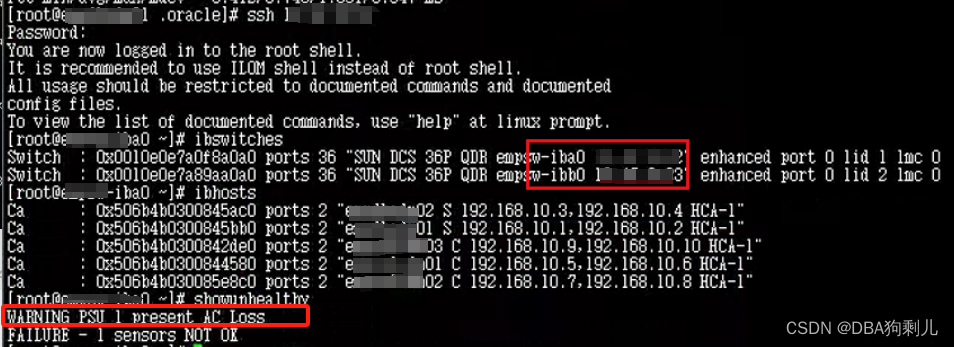
还发现掉了一个PDU,进行确认私有IP通信正常
五、紧急恢复业务
在IB完成正常重启后,重新启动所有cell服务
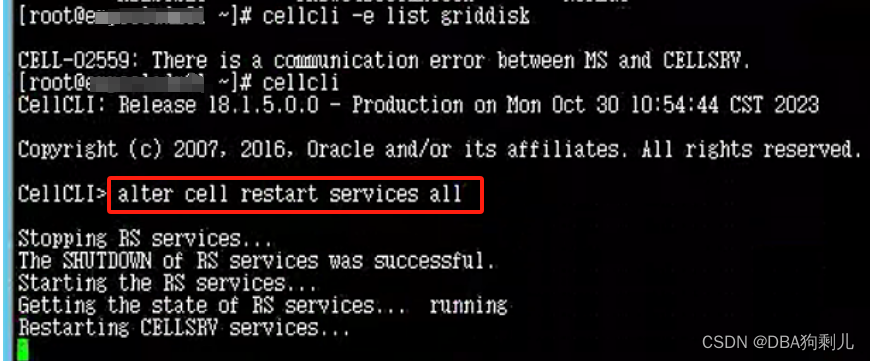
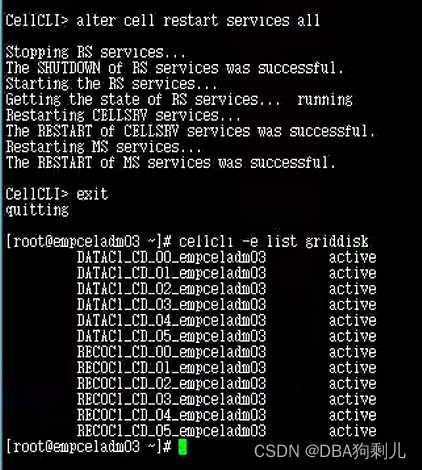
拉起集群:
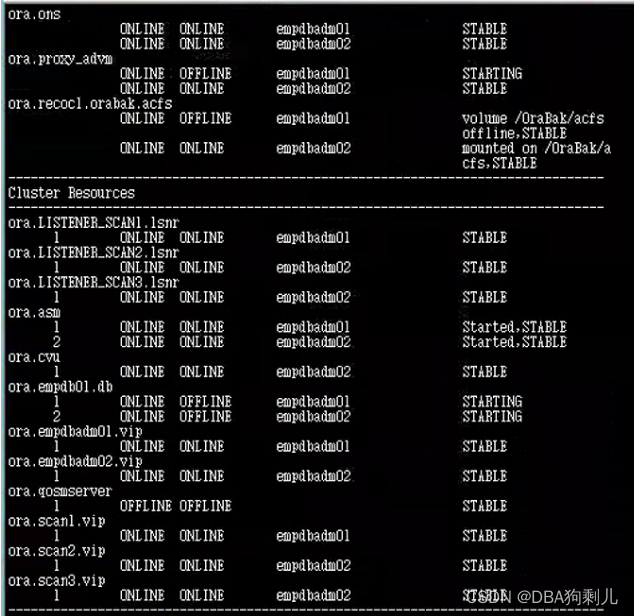
六、收尾工作
check修复第二台IB交换机
重新挂载nfs共享目录
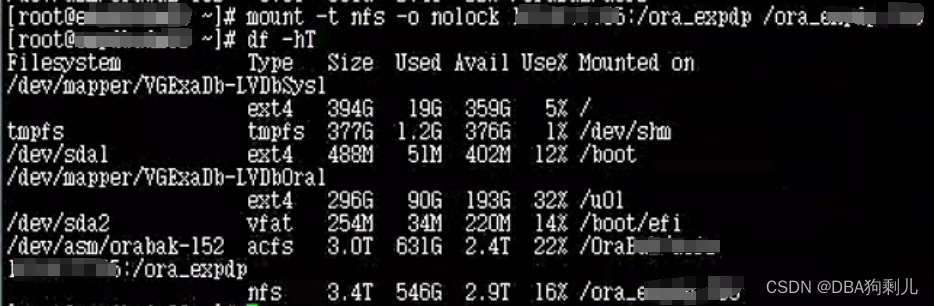
检查PDU,确实已掉电


七、原因调查
PDU问题由于29日晚操作切电操作导致UPS路跳闸
主机等log显示电源切换
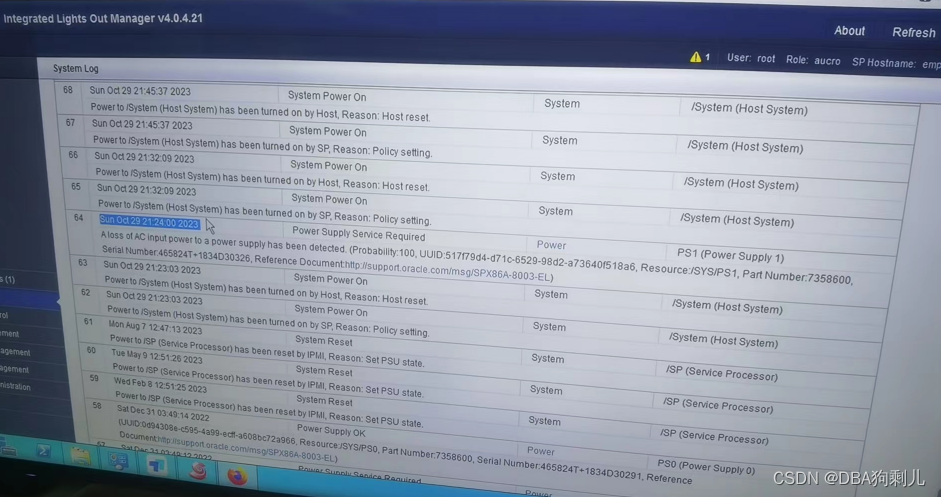
29日有检测到FAN0风扇数值是0
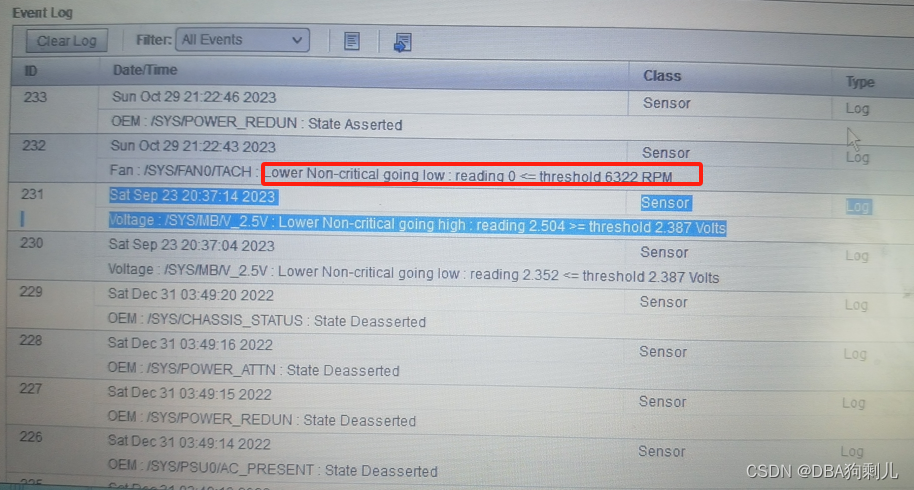
但实际风扇只应该显示FAN1~3才对,出现FAN0也是奇怪,有知道朋友可以留言。
总结
通过整体问题梳理,应该是在用过进行切电作业时候导致UPS跳闸,且市电进行切换导致的整个一体机机柜出现了掉电情况,然后服务器重启后,IB交换机自检硬件有问题导致自检失败所有整体的私有IP和以下的集群服务无法正常启动。
这篇关于Oracle Exadata X7-2掉电宕机导致集群无法启动处理过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







