本文主要是介绍学无止境 之二 王爽老师 16 位汇编语言学习记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以下为汇编学习记录,内容全部出自王爽的16位《汇编语言》,如有错误,可直接去查看原书。
汇编语言
机器语言是机器指令集的集合,机器指令是一列二进制数字,计算机将其翻译成高低电平,从而使器件收到驱动。而程序员很难看懂!例如:8086 CPU 完成运算 s = 768 + 12288 – 1280,对应的机器码是:
10110000000000000000011
00000101000000000110000
00101101000000000000101
汇编语言的主体是汇编指令。汇编指令是机器指令便于记忆的书写格式。其最终由编译器将他们处理成对应的机器语言,由机器执行。
汇编语言的组成:
- 汇编指令:机器码的助记符,有对应的机器码 每条指令语句在汇编时都产生一个供CPU执行的机器目标代码。
- 伪指令:由汇编器执行,没有对应的机器码 它所指示的操作是由汇编程序在汇编源程序时完成的,在汇编时,它不产生目标代码,在将源程序汇编成目标程序后,它就不复存在。
- 宏指令:
- 其他符号:如:+、-、*、等,由汇编器执行,没有对应的机器码
指令和数据存放在存储器中,也就是平常说的内存中。在内存或硬盘上存储的数据和指令没有区别,都是二进制信息。例如:内存中有 1000100111011000,作为数据看是 89D8 H,作为指令看是 mov ax, bx。存储器被划分为若干单元,单元从 0 开始编号,最小信息单位为 bit(位),8 个 bit 组成一个 byte(字节),微机存储器以字节为最小单位来计算。
CPU 对存储器的读写
CPU 从 3 号单元中读取数据过程:

地址总线
CPU 通过地址总线选定存储单元。一个 CPU 有 N 根地址总线,则可以说这个 CPU 的地址总线宽度是 N,其最多可以寻找 2N 个内存单元。地址总线决定了其寻址能力。

注意高低地址。上图实际选定的内存单元是 0000001011(即:11号单元)
数据总线
CPU 和内存或其他器件的数据传送是通过数据总线进行的。
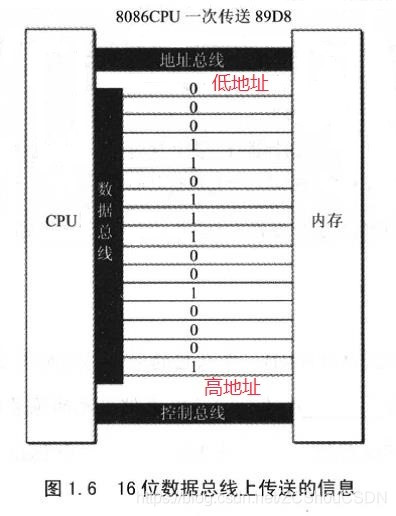
对于不能一次传送的数据,将先传送低字节,后传送高字节。例如:对于 89D82 H,将先传送 9D82,后传送 8。
控制总线
CPU 对外部器件的控制是通过控制总线进行的。CPU 有多少控制总线,对外部器件就有多少种控制。控制总线决定了 CPU 对外部器件的控制能力。
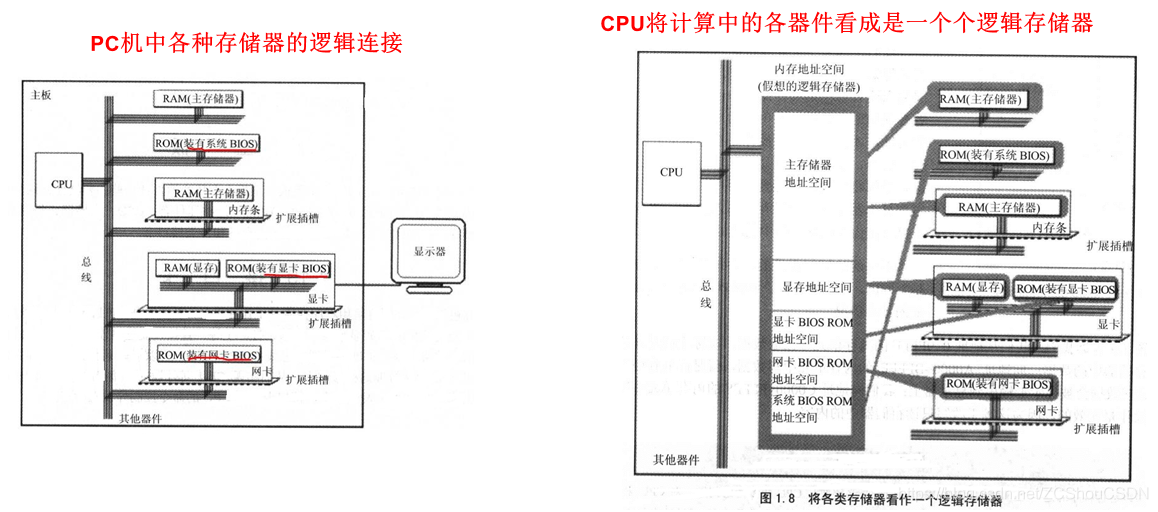
每个物理存储器在逻辑存储器中占据一定的地址空间,CPU 在相应的地址空间中写入数据,实际上就是向该物理存储器中写数据。例如:在 8086PC 中,
- 0 ~ 7fffH 的 32KB 空间为主存储器的地址空间
- 8000H~9fffH 的 8K 空间为显存的地址空间
- A000H~ffffH 的 24K 空间为各个 ROM 的地址空间
那么,向8001H里面写入数据,实际就是把数据写入到显存中
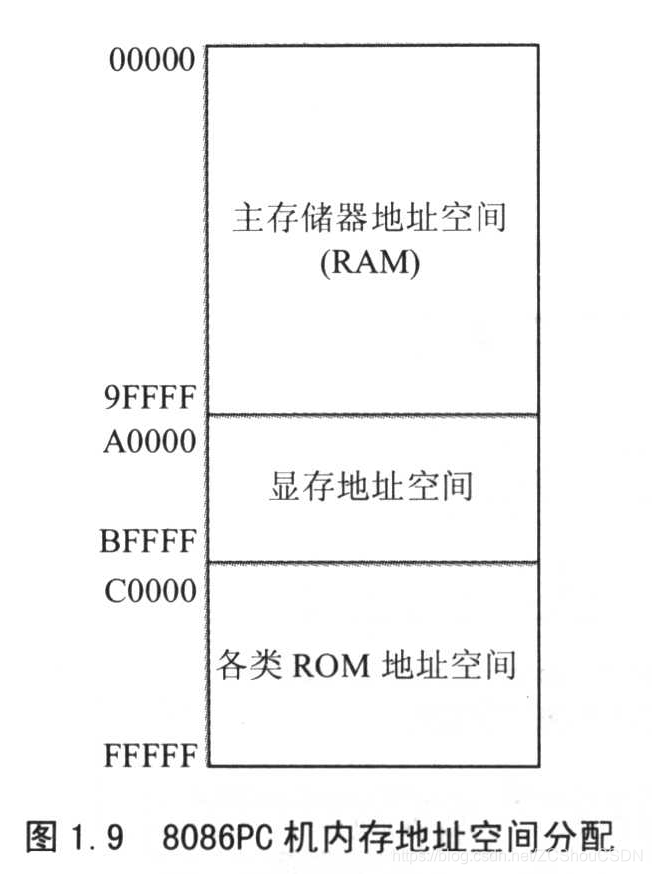
不同的计算机内存地址空间的分配是不同的
寄存器
8086 CPU 共有 14 个寄存器,AX、BX、CX、DX,SI、DI,SP、BP、IP,CS、DS、SS、ES,PSW。
通用寄存器
8086 CPU 中,AX、BX、CX、DX通常用来存放一般性数据,称为通用寄存器。他们均为16位。并且都可以分为两个8位的寄存器(高8位和低为位)使用
- AX 可分为 AH 和 AL
- BX 可分为 BH 和 BL
- CX 可分为 CH 和 CL
- DX 可分为 DH 和 DL

出于兼容性,8086 CPU 可以一次处理两种尺寸的数据:字节型和字型(双字节。高地址存放高字节,低地址存放低地址)。在进行数据传送或运算时,指令操作对象的位数应该一致,例如:不能在字与字节类型之间传送数据:
mov ax, bl (错误的指令)
mov bh, ax (错误的指令)
物理地址
8086 CPU 是 16 位结构:
- 运算器一次最多处理 16 位数据
- 寄存器最大宽度是16 位
- 寄存器和运算器之间的通路是16位
8086 CPU 有 20 根地址线,然而其又是 16 位结构,所以 8086 CPU 内部用两个 16 位地址合成一个 20 位地址

地址加法器采用 物理地址 = 段地址 x 16 + 偏移地址 的方法合成 20 位的物理地址。
段的概念
段的划分源自于 8086 的寻址方式,实际上,内存并不会分段。我们把连续的一段内存用段加以描述,从而方便 8086 的寻址。由计算式可知,段的起始地址一定是 16 的倍数,偏移地址为 16 位,16 位的寻址能力为 64K,则一个段的最大长度为 64K。
段寄存器
8086 CPU 中,用CS、DS、SS、ES 四个段寄存器来存放内存单元的段地址。CS 和 IP 是 8086 CPU 中两个关键的寄存器,他指出了 CPU当前要读取的指令地址。CS 称为代码段寄存器,IP 称为指令指针寄存器 。任意时刻,8086 CPU 将 CS: IP 指向的内容当做指令执行。
8086 CPU 工作过程:
- 从CS:IP指向的内存单元中读取指令,读取的指令进入指令缓冲区
- IP = IP+指令长度,从而指向像一条指令
- 执行指令,转到(1)循环
修改 cs 和 ip 的值
jmp 指令
格式: jmp 段地址:偏移地址 ;执行后, cs = 段地址, IP = 偏移地址
例如: jmp 2AE3H:3 ;执行后,CS =2AE3 , IP = 3
格式: jmp 寄存器 ;执行后 , ip = 寄存器的值
例如: jmp ax ;若执行前,ax = 1000H cs = 2000H ip = 0003H ;则执行后, ax = 1000H cs = 2000H ip = 1000H
注意:mov指令不能修改CS和IP的值
实验一 debug的使用
注意在 Debug 中,数据都是用十六进制表示,且不用加 H
- 用 R 命令查看、修改寄存器的内容
- 显示所有寄存器和标志位状态
- 显示当前 CS:IP指向的指令。
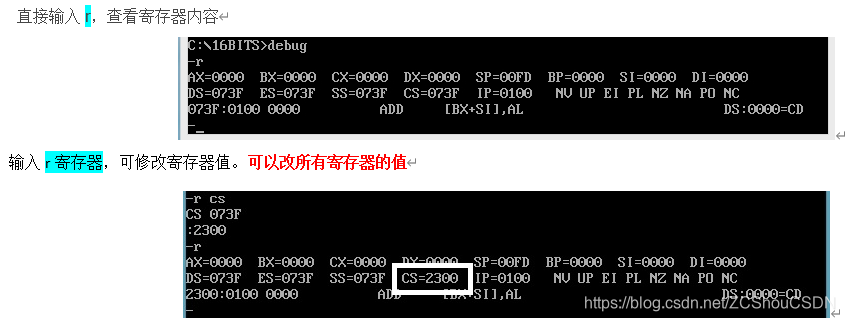
2. 用 D 命令查看内存内容
- debug 默认列出 128 个字节单元的内容
- 若指定的地址不是 16 的倍数(如 d 1000 : 9 ),仍会显示128字节内容( 从1000 : 9到1000 : 88 )
- debug列出了三部分内容: 最左边是每行的起始地址 中间是内容的16进制 最右边是对应的ASCII ( 没有对应时用 . 表示)
- 直接输入
d,查看当前 cs:ip 指向的内存内容,注意:如果继续输入d,则可继续查看后面的内存的内容
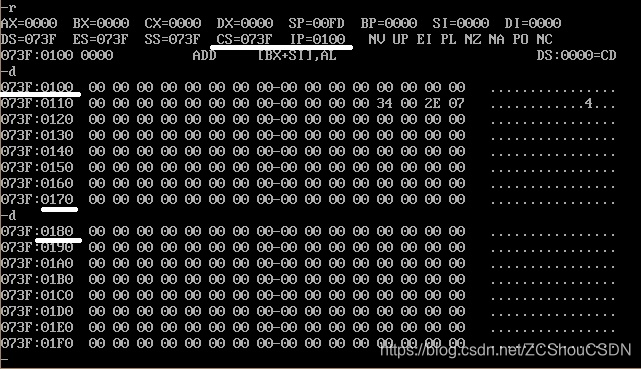
- 输入
d 段地址 : 偏移地址,查看指定的内存地址的内容。如果继续输入d,则可继续查看后面的内存的内容

- 输入
d 段地址: 偏移地址 结束地址,查看指定地址内存内容。如果继续输入d,则可继续查看后面的内存的内容

- 用E命令改写内存中的内容
- 输入
e 段地址: 偏移地址 数据1 数据2 数据3 …,修改指定地址内存中的内容

- 输入
e段地址: 偏移地址,可以逐个字节进行修改,注意:不修改直接输空格,输完数后,按空格输入下一个,回车直接结束

- 使用 e 命令可以输入字符(单引号标识)或字符串(双引号标识),都是存储的ASCII

- 用 e 命令向内存中写入机器码,用U命令查看内存中机器码的含义,用T命令执行内存中的机器码

- 使用 e 命令可以输入字符(单引号标识)或字符串(双引号标识),都是存储的ASCII
- 用 A 命令在内存中输入汇编指令
- 直接输入
a,在当前内存(CS:ip指向的内存)中输入汇编指令

- 输入
a 段地址: 偏移地址,在指定的内存中输入汇编指令

- 输入
a 偏移地址,向 cs:偏移地址 指向的内存中的写入汇编指令

-
用 u 命令查看内存中机器码对应的汇编指令
- 直接输入
u,查看当前内存(CS:ip指向的内存)中机器码对应的汇编指令

- 输入
u 段地址: 偏移地址,查看指定的内存中的机器码对应的汇编指令

- 直接输入
-
使用T命令执行内存中的汇编代码
- 直接输入
t,执行当前指令
- 直接输入
-
使用G命令将程序执行到指定地址处
- 输入
g 偏移地址,表示将指令执行到当前偏移地址处
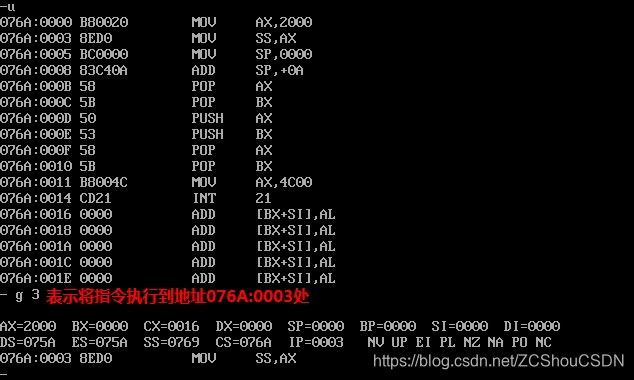
- 输入
-
使用 P 命令可以一次性执行完循环,且int 21H指令必须用P命令执行
- 当遇到循环时,输入p,即可直接执行完循环
-
用 DEBUG 跟踪程序
- 输入
debug 要跟踪的程序全名,debug 将程序加载进内存

注意:
- 输入
-
加载进内存后,cx中存放的是程序的长度(占用机器码的字节数),上图说明3-1.exe占的机器码是22个字节(十六进制表示为16H)
-
debug 中,对于最后的 int 21 指令,需要用 p 命令执行

说明: 当加载进内存后,CS变被赋予SA+10H,IP被赋值0
数据段寄存器DS
mov 指令
mov 寄存器, 立即数 ; 将数据直接送入寄存器 例:mov ax,2
mov 寄存器, 寄存器 ; 将一个寄存器中的值送入另一个寄存器中 mov ax,bx
mov 寄存器, 内存单元 ; 将一个内存单元中的数据送入寄存器 mov ax , [0]
mov 内存单元, 寄存器 ; 将一个寄存器中的数据送入指定的内存单元 mov [1], bx
mov 段寄存器, 寄存器 ; 将一个寄存器的值送入段寄存器 mov ds, ax
mov 寄存器, 段寄存器 ; 将一个段寄存器中的值送入一般寄存器 mov ax, ds
mov 段寄存器, 内存单元
注意:
- [ 偏移地址 ] 表示一个内存单元,8086CPU默认使用ds作为数据段的段寄存器
- 8086CPU规定,不能直接给段寄存器赋值 例如 mov ds, 2 是错误的
- add 和 sub 指令同上
CPU 提供的栈机制
push(进栈)和pop(出栈)都是以字为单位进行的。POP 和 PUSH 指令:
push 寄存器 ;将一个寄存器中的数据入栈
pop 寄存器 ;用一个寄存器接受出栈的栈顶元素
push 段寄存器 ;将一个段寄存器中的数据入栈
pop 段寄存器 ;用一个段寄存器接受出栈的栈顶元素
push 内存单元 ;将一个内存字单元处的数据入栈
pop 内存单元 ;用一个内存字单元接受出栈的栈顶元素
注意:
- push 和 pop 指令对内存单元操作时,自动 ds 中读取数据段的段地址
- push 和 pop 指令与 mov 指令不同,cpu 执行 push 和 pop 指令需要两步,而执行 mov 指令只需要一步。
- push 和 pop 指令只能修改 SP,也就是说,栈顶的最大变化范围是 0~FFFFH
例如: mov ax, 1000H
mov ds, ax ; 存放数据段的段地址
push [0] ; 将1000:0内存字单元中的数据进栈
pop [2] ; 将出栈的数据放到1000:2内存字单元中
8086 CPU 提供 SS 和 SP 两个寄存器来标识栈。SS 存放栈顶段地址,SP 存放偏移地址。任意时刻,SS:SP 指向栈顶。push 和pop 指令执行时,自动从 SS:SP 指向处取得栈顶地址
- PUSH 指令的执行过程
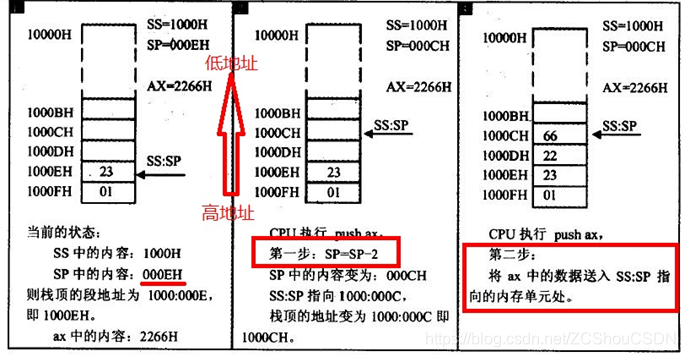
注意:
- 入栈时,栈是从高地址向低地址扩展的
- 栈空时,SS:SP指向栈底的下一个位置

- POP指令的执行过程
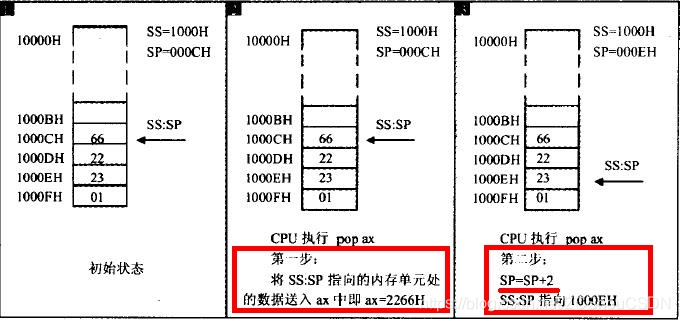
注意:出站后,SS:SP 指向新栈顶,pop 执行前的栈顶元素仍然存在(如上图的 2266H),只是它已不再栈中(栈顶已改变),再一次使用 push 指令时,将覆盖原有数据。
8086 CPU不保证对栈的操作不会越界
- PUSH入栈越界

- POP出栈越界
和上图基本相似
编程实例
要求:
(1)将10000H~1000FH作为栈空间,初始状态栈空
(2)设置 ax = 001AH,bx = 001BH
(3)将ax和bx的值入栈
(4)然后将ax和bx清零
(5)最后从栈中恢复ax和bx的值
程序:
mov ax, 1000H
mov ss, ax ; 设置栈的段地址,不能直接给段寄存器赋值
mov sp, 0010H ; 栈空时,SS:SP指向栈底的下一个位置(000F + 1 = 0010H)注意:栈由高地址向低地址增长
mov ax, 001AH
mov bx, 001BH
push ax
push bx
sub ax, ax ; 此处也可以使用 mov ax, 0 ,但是sub ax, ax 的机器码为2个字节,而占mov ax, 0的机器码为三个字节
sub bx, bx ; 同上
pop bx ; 注意,出栈顺序和进栈顺序相反(先进后出)
pop ax
段的综述
我们可以将一段内存定义为一个段,用一个段地址指示段,用偏移地址访问段内的单元,这完全是我们自己的安排。
- 可以用一个段存放数据,将它定义为“数据段”;
- 可以用一个段存放代码,将它定义为“代码段”;
- 可以用一个段当做栈,将它定义为”栈段“;
我们可以这样安排,但是若要 CPU 按照这种安排来访问这些段,就要:
- 对于数据段,将它的段地址存放在DS中,用mov、add、sub等访问内存单元的指令时,CPU就将我们定义的数据段中的内容当作数据来访问。
- 对于代码段,将它的段地址存放在CS中,将段中第一条指令的偏移地址存放在IP中,这样cpu就将执行我们定义的代码段中的指令。
- 对于栈段,将它的段地址放在SS中,将栈顶单元的偏移地址存放在SP中,这样cpu在需要进行栈的操作时,如执行push, pop指令等,就将我们定义的栈当作栈空间来用。
可见,不管我们如何安排,CPU将内存中的某段内容当作代码,是因为CS:IP指向了那里;CPU将某段内存当作栈,是因为SS:SP指向了那里;我们一定要清楚,什么是我们的安排,以及如何让CPU按我们的安排行事。要非常清楚CPU的工作机理,才能在控制CPU按照我们的安排运行的时候做到游刃有余。
一段内存,可以既是代码段的存储空间,又是数据的存储空间,还可以是栈空间,也可以什么都不是。关键在于CPU中寄存器的设置,即 CS、IP,SS、DS 的指向。
段前缀
在汇编程序中,可以显示给出段地址,这些显示的段地址称为段前缀。例如:ds:[bx] 、ds: [0]、 ss: sp 、cs: sp 、cs: ip 等。显示给出段前缀时,将使用给出的寄存器作为段地址,而不是使用默认段寄存器
第一个汇编程序
基本格式(包含多个段):
assume cs: code, ds: data, ss: stack ; 伪指令,将寄存器和各段联系起来
data segment ; 数据段 ; 伪指令,格式:段名 segment,表示一个段的开始,段名表示一个地址,被编译时翻译成地址dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends ; 伪指令,和他上面的段名 segment成对存在,格式:段名 ends,表示一个段的结束
stack segment ; 栈段 ; 可同时定义多个段(代码段、数据段、栈段)dw 0,0,0,0,0,0,0,0
stack ends
code segment ; 代码段 ; 可以不定义数据段和栈段,但代码段不可少,否则程序根本没意义
start: ; 标号 ; 标号代表一个地址,这个标号在编译时被翻译成地址
mov ax, stack ; 段名表示一个地址,被编译时翻译成地址mov ss, ax mov sp, 16 ; 初始情况,栈底与栈底相同,高地址表示栈底mov ax, data ; 段名表示一个地址,被编译时翻译成地址mov ds, axpush ds: [0] push ds: [2] pop ds: [2] pop ds: [0] mov ax,4c00h int 21h ; 这两条语句为一组,表示程序的返回
code ends
end start ; 伪指令,end标志着一个汇编程序的结束,编译器遇到end就结束对程序的编译,同时指出了程序的入口为start处
注意:在多个段中,各段空间相互独立,地址都是从 0 到段大小。 例如上例:数据段空间 0 ~ 15(字节空间),栈空间 15 ~ 0(字节空间),代码段从 start 开始
基本格式(只有一个段)
assume cs: codesg
codesg segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h dw 0,0,0,0,0,0,0,0,0,0
start: mov ax, codesg ;或mov ax, cs mov ss, ax mov sp, 24h ;上三条指令设置栈顶指针,使指向了codesg:24H ;或mov sp, 36 ; 36是十进制对应的16进制是24Hmov ax,0 mov ds, ax mov bx,0 ; 这三条指令设置数据指针,使其指向了0: 0,即本段数据的开始处mov cx,8 ; 循环次数s: push [bx] ; 将0123H入栈,默认数据段寄存器ds,此处是 ds: [bx]。注意:push和pop指令一次操作一个字(两个字节)pop cs: [bx] ; 或 pop ss: [bx] add bx, 2 ; 注意:push和pop指令一次操作一个字(两个字节)loop s mov ax,4c00h int 21h
codesg ends
end start
注意:只有一个段时,各种代码公用一段空间。例如上例:数据从 dodesg 开始占(0 ~ 15),栈则跟在后面,从 16~31 ,start 处的指令实际是从 32 开始
[bx]和 loop 指令
[bx] 使用:
mov ax, [bx] ; 其中,[bx]表示内存单元,段地址默认ds中,该指令表示将ds:[bx]字单元的内容送入寄存器ax
mov [bx], ax ; 其中,[bx]表示内存单元,段地址默认ds中,该指令表示将寄存器ax的内容送入ds:[bx]字单元
例:指令执行后的内存情况

loop指令:
mov cx, 循环次数
标示符:要循环的指令
loop 标示符 ; CPU执行过程:(1)cx = cx-1 (2)判断cx中的值,不为零则转至标号处,为零时继续往下执行
例:用 loop 指令计算 211
assume cs:code
code segment
strat:mov ax, 2mov cx, 11s: add ax, axloop s
mov ax, 4c00H
int 21H
code ends
end start
DEBUG与汇编编译器对指令的不同处理
- 在 debug 中,mov ax, [0] 表示将 ds:[0] 内存单元中的数据送入 ax 中,而在汇编编译器中表示 mov ax, 0。因此,汇编中使用 mov bx, 0 mov ax,[bx] 来实现。或显示指出段地址 mov ax, ds:[0] 实现。
- Debug中,所有数据都是16进制的,汇编编译器中则不是
实例:计算 ffff:0~ffff:b 中的数据之和,结果存在 dx 中
分析:
- 结果是否会超过 dx 的容量:12 个字节型数据相加不会大于 65535,可以在dx中存放
- 是否将其中数据直接累加到 dx 中:当然不行,因为数据是 8 位的,dx 是 16 位的,类型不匹配
- 是否将其中数据直接累加到 dl 中:当然也不行,dl最大为 255,可能会超出存储范围
解决方法:用一个 16 位寄存器做中介,先将数据存入ax中,用 ax 和 dx 做加法,加过存在 dx 中。程序:
assume cs:code
code segment
start:
mov ax, 0ffffH ; 注意,汇编中数据不能以字母开头,因此要在前面加0
mov ds, ax
mov bx, 0 ; 初始化,使ds: bx指向ffff: 0
mov dx, 0 ; 初始化累加器 dx = 0
mov cx, 12 ; 循环次数
s:
mov ah, 0
mov al, ds: [bx] ; ax作为中间寄存器
add dx, ax
inc bxloop smov ax, 4c00H
int 21H
code ends
end start
更灵活的内存定位方法
and 指令: 按位与运算,通过该指令可以将操作对象的相应位设为0,其他位不变
例如:
mov al, 01100011B
and al, 00111011B
or 指令: 按位或运算,通过该指令可以 操作对象的相应位设为1,其他位不变
mov al, 01100011B
or al, 00111011B
在汇编中,我们可以使用 英文单引号(‘’) 来指明数据是字符。例如:db ’asm‘ ,编译器将他们转换为对应的ASCII码。
大小写转换问题
就 ASCII 码的二进制来看,除第五位外,大小写字母的其他位都相同。大写字母的第五位是 0,而小写的第五位是 1。
[bx+idata] 的寻址方式
SI 和 DI 两个寄存器,功能和 BX 相近,但 SI 和 DI 不能被分成两个 8 位寄存器使用
- 实例分析:用 SI 和DI 将字符串 ’Welcome to masm!’ 复制到他后面的内存空间中。
assume cs: code, ds: data
data segment
db ‘Welcome to masm’
db ‘. . . . . . . . . . . . . . . .
data ends
code segment
start:
mov ax, data
mov ds, ax
mov si, 0
mov di, 16
mov cx, 8 ; 循环8次
s: mov ax, [si] ; 一次传送两个字节(16位寄存器)
mov [di], ax
add si, 2 ; 每次两个字节
add di, 2
loop smov ax, 4c00H
int 21h
code ends
end start
- 实例分析:编程,将datasg段中每个单词的前4个字母改为大写字母。
assume cs: codesg, ds: datasg, ss: stacksg
datasg segmentdb '1. display ' ; 16 Byte ; 注意, 空格也是字符。每个字符串占16个字节db '2. brows ' ; 16 Bytedb '3. replace ' ; 16 Bytedb '4. modify ' ; 16 Byte
datasg ends
stacksg segmentdw 0,0,0,0,0,0,0,0 ; 对于临时数据,我们一般用栈来存放
stacksg ends
codesg segment
start: mov ax, datasgmov ds, axmov bx, 0 ; ds:bx指向数据段开始,即指向第一组数据mov ax,stacksgmov ss,axmov sp,16 ; ss:sp 指向栈底的下一位置mov cx,4 ; 循环次数s0: push cx ; 将cx的值放到上面的栈中mov si,0mov cx,4s: mov al, [bx+3][si] ; 注意,每个字符串中1 和 . 和空格 占三个字节,所以是[bx+si+3], 注意书写形式的区别and al,11011111b ; 使用and指令将小写ASCII码二进制的第五位由1置为0,即由小写变大写mov [bx+3][si],al ; 将转换后的字符放回原位置inc siloop sadd bx,16 ; 指向下一组字符串pop cx ; 重置循环次数,用于第二组字符串中loop s0mov ax, 4c00hint 21h
codesg ends
end start
数据处理的两个基本问题
- 问题一:指令所处理数据的位置
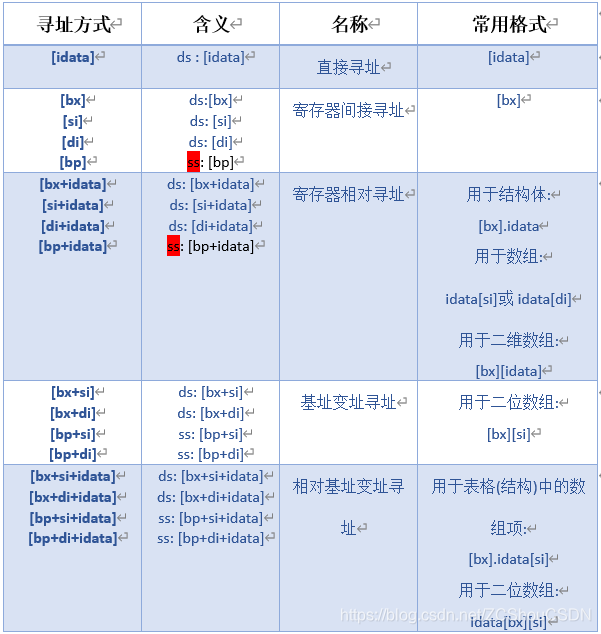
8086 CPU中,只有 si、di、bx、bp 四个寄存器可以在 [ ] 中使用。四个寄存器可以单独使用,也可以以以下组合出现:bx 和 si、bx 和 di、bp 和 si、bp 和 di。下面的指令都是正确的:
mov ax, [bx]
mov ax, [si]
mov ax, [di]
mov ax, [bx+si]
mov ax, [bx+di]
mov ax, [bp+si]
mov ax, [bp+di]
mov ax, [bx+si+idata] ; 默认的段寄存器是SS
mov ax, [bx+di+idata] ; 默认的段寄存器是SS
mov ax, [bp+si+idata] ; 默认的段寄存器是SS
mov ax, [bp+di+idata] ; 默认的段寄存器是SS
注意:
- bx 和 bp 不能搭配,si 和 di 也不能搭配
- 只要使用了 bp,而没有显示给出段寄存器的,默认段寄存器是 ss
8086 CPU 寻址方式:
-
问题二:指令要处理的数据有多长
1. 通过寄存器指明处理数据的长度。在指令所使用的寄存器是多长,数据就是多长。例如: mov ax, [0] ax为16位的,所以处理的是两个字节的内容,即偏移地址[0]和[1]两个字节
2. 在没有寄存器名存在的情况下,用操作符 X ptr 指明操作数的长度,X 可以是 Byte 和 Word。例如:mov word ptr ds:[0], 1 ; 操作字单元 inc word ptr [bx] ; 操作字单元 mov byte ptr ds:[0], 1 ; 操作字节单元 inc byte ptr [bx] ; 操作字节单元 -
某些指令默认长度,如 pop 和 push 指令默认是对字单元操作
-
div 除法指令。格式:
div 除数div 寄存器 div 内存单元div 使用默认寄存器
除数位数 被除数位数 被除数默认存放的寄存器 商 余数 8位 16位 ax al ah 16位 32位 (高位)dx + ax(低位) ax dx 只能出现以上两种组合对应 ,不足时要不足位数。例如: div byte ptr ds:[0] ; al = ax / (ds*16+0) 的商; ah = ax / (ds*16+0) 的余数 div word ptr es:[0] ; ax = (dx*10000H+ax) / (es*16+0)的商; dx = (dx*10000H+ax) / (es*16+0)的余数实例:编程计算100001/100
分析:100001>65535,所以不能用ax存放,只能用dx和ax存放,被除数是32位的,因此除数必须是16位的(尽管100<255)
程序:assume cs: code code segment start:mov dx, 1mov ax, 86A1H ; 注意:100001转换为十六进制为186A1H,高位1给dx,低位86A1H给axmov bx, 100div bx code ends end start
- dd 伪指令: 用来定义double word(双字)
- dup 操作符: 用来进行数据的重复.例如: db 3 dup(0) ; 定义了三个字节,初值都是0。格式:
db/dw/dd 重复次数 dup (重复的数据)
-
实验7 寻址方式在结构化数据访问中的应用

assume cs: code, ds: data, es: tabledata segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的字符串 4 * 21 = 84dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年每年公司总收入的dword型数据 4 * 21 = 84dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年每年公司雇员人数的21个word型数据 2 * 21 = 42
data endstable segment
db 21 dup ('year summ ne ?? ') ; 'year summ ne ?? ' 刚好16个字节
table endscode segment
start:
mov ax, data
mov ds, ax
mov ax, table
mov es, ax
mov bx,0 ;ds:[bx]在data中数据定位(和idata结合,用于年份和收入)
mov si,0 ;es:[si]在table中定位(和idata给合用于定位存放数据的相对位置)
mov di,0 ;ds:[di]在data中用于得到员工数
mov cx,21 ;cx循环次数
s:;将年从data 到 table 分为高16位和低16位mov ax, [bx]mov es:[si], ax ; 高16位mov ax, [bx+2]mov es:[si+2], ax ; 低16位;table 增加空格mov byte ptr es:[si+4],20h ; 0~3的四个字节是年份,第4个字节是空格;将雇员数从data 到 tablemov ax, [di + 168]mov es:[si + 10], ax;table 增加空格mov byte ptr es:[si+12],20h ; 10~11的四个字节是雇员数,第12个字节是空格;将收入从data 到 table 分为高16位和低16位mov ax, [bx+84]mov es:[si+5], ax ; 高16位mov dx, [bx+86]mov es:[si+7], dx ; 低16位;table 增加空格mov byte ptr es:[si+ 9],20h ; 5~8的四个字节是收入,第9个字节是空格;计算工资;取ds处工资,32位;mov ax,[bx + 84]
;mov dx,[bx + 86];计算人均收入, 注意:上面在将收入放到table中时刚好将数据放到了dx和ax中,因此不用再重新设置被除数div word ptr ds:[di + 168] ; ax = (dx*10000H+ax)/ ds:[di + 168]的商mov es:[si+13],ax ;将结果存入table处;table 增加空格mov byte ptr es:[si + 0fh],20h ; 13~14的四个字节是人均收入,第15个字节是空格(15的十六进制是f);改变三个寄存器值add si,16 ; table的下一行add di,2add bx,4loop smov ax,4c00h
int 21h
code ends
end start
转移指令的原理
可以修改 IP 或同时修改 cs 和 ip 的指令称为转移指令。
-
offset 运算符:可以取得标号相对与所在段开始的偏移地址
-
jmp 指令:jmp 是无条件转移指令,可以修改 ip 的值,也可以同时修改 cs 和 ip 的值
-
根据位移进行转移的jmp指令。格式:
jmp short 标号 ; 转到标号处执行指令
注意:- 实现段内短转移,对ip的修改范围是 -128 ~ 127
- cpu 在执行 jmp 指令时并不需要转移的目的地址
- 在 jmp short 标号指令多对应的机器码中并不包含转移的目的地址。而包含的是转移的位移。这个位移是编译器根据标号出来的。转移位移的计算方法:


段内近转移:jmp near ptr标号

注意:以上两条指令的机器码中,并不包含转移的目的地址,而是包含转移的位移
-
转移的目的地址在 jmp 指令中
格式:jmp far ptr 标号 ;实现段间转移,又称远转移。转到标号处执行指令
功能:cs = 标号所在段的段地址,ip = 标号所在段的偏移地址 -
转移的目的地址在寄存器中的 jmp 指令
格式:jmp 16位寄存器
功能: ip = 16位寄存器的值 -
转移的目的地址在内存中的 jmp 指令
格式 1:jmp word ptr 内存单元 ; 段内转移
功能:ip = 该字型内存单元的值(2个字节)
例如:mov ax, 1234Hmov ds:[0], axjmp word ptr ds:[0] ;执行后,IP = 1234H格式 2:
jmp dword ptr 内存单元 ; 段间转移
功能:cs = 该内存单元+2(高16位) ip = 该内存单元(低16位)
-
-
jcxz 指令:jcxz 为有条件转移指令,所有的有条件转移指令都是短转移,对应的机器码中包含转移的位移,而不是目的地址。范围是 -128~127
格式:jcxz 标号 ; 如果cx = 0,则转到标号处执行
操作:若 cx = 0 则 ip = ip + 8 位位移(补码表示);cx != 0 ,继续向下执行 -
loop 指令:循环指令都是短转移,对应的机器码中包含转移的位移,而不是目的地址。范围是-128-127
格式:loop 标号
操作: cx = cx – 1 若cx != 0 ,则ip = ip + 8位位移,转到标号处;cx = 0 ,继续向下执行

注意:编译器会对转移位移的越界进行检查实验 8
; 考察段内转移时jmp指令的机器码中,包含的是转移的位移,而不是目的地址 assume cs:codesg codesg segmentmov ax,4c00h ;该指令占3个字节,机器码是B84c00int 21h ; 该指令占2个字节, start: mov ax,0 ;ax=0,该指令占3个字节,机器码B80000s: nop ;占一字节,机器码90nop ;占一字节,机器码90mov di, offset s ;(di)=s偏移地址,该指令占3个字节mov si,offset s2 ;(si)=s2偏移地址,该指令占3个字节mov ax,cs:[si] ;(ax) = jmp short s1指令对应的机器码EBF6,该指令占3个字节mov cs:[di],ax ;jmp short s1覆盖s处指令2条nop指令,jmp short s1占两个字节,其机器码为跳转位移-8s0: jmp short s ;从此向下未执行,直接跳到2,然后就跳到mov ax,4c00h了s1: mov ax,0int 21hmov ax,0s2: jmp short s1 ;注意:对于jmp short s1指令,机器码中存放的是偏移位移,而不是目的地址,此句的偏移位移为-8(十六进制是F8)nop codesg endsend start实验 9
背景知识
80 X 25 彩色字符模式显示缓冲区的结构:内存地址空间中,B8000H~BFFFFH 共 32KB 的空间,为 80 X25 彩色字符模式的显示缓冲区。想这个地址中写入数据,写入的数据将立即显示在显示器上。
在 80 X 25 彩色模式下,显示器可以显示 25 行,每行 80 个字符(160 个字节),每个字符可以有256种属性(背景色、前景色、闪烁、高亮等组合信息)。这样,一个字符在显示缓冲区中就要占两个字节(一个字空间),低字节存放ASCII码,高字节存放字符的属性。在显示缓冲区中,偶地址存放字符,奇地址存放字符的颜色属性。在 80 X 25 彩色模式下,一屏幕的内容在显示缓冲区中共占 4000 个字节。
显示缓冲区分为 8 页,每页 4KB(约为 4000B),显示器可以显示任意一页的内容。一般情况下,显示第0页的内容
一个在屏幕上现实的字符,具有前景(字符色)和背景(底色)两种颜色。字符还可以以高亮度和闪烁的方式显示。各属性被记录在字节位中。1 表示有效,0 表示无效。属性字节格式

注:
- R表示红色;G表示绿色;B表示蓝色
- 可以使用任意字节位的属性进行搭配
例如:
- 红底绿字: 01000010B
- 闪烁红底绿字:11000010B
- 黑底白字:00000111B ; RGB混合
程序
;编程:在屏幕中间分三行显示绿色、绿底红色、白底蓝色的字符串 welcome to masm! ;黑框为80*25的屏幕,每行的字节数为80*2=160. ;要求显示在屏幕中间,先计算行和列的偏移 ;行偏移:(25(总行数)- 3(字符窜占3行))/2 = 11.所以显示在第11,12,13行。偏移值分别为1760,1920,2080。计算方法为 行数*160(每行的字节数) 。 ;列偏移:由于要显示的字符数为16个,所以开始显示的列偏移为(80-16)/2*2=64。 ;绿色最终位置为 11*160+64 = 1824,转换为16进制为720H;绿底红色最终位置为12*160+64 = 1984,转换为16进制为7c0H;白底蓝色最终位置为13*160+64 = 2144转换为16进制为860H assume cs:code,ds:datadata segmentdb 'welcome to masm!' data endscode segment start:mov ax,datamov ds,axmov bx,0 ;ds:bx指向data字符串mov ax,0b800hmov es,axmov si,0 ;es:si指向显存mov cx,16 ; 字符串长度为16个字节(0~15) s: mov al,[bx] ;字符赋值al,默认使用ds作为段寄存器mov ah,02h ;绿色; 两个字节为一组,高位为字符属性,低位放字符mov es:[si+720h],ax ;写入第11行64列mov ah,14h ;绿底红色mov es:[si+7c0h],ax ;写入第12行64列mov ah,71h ;白底蓝色mov es:[si+860h],ax ;写入第13行64列inc bx ;指向下一字符add si,2 ;指向下一显存单元loop smov ax,4c00hint 21hcode ends end start -
ret 指令:用栈中的数据修改 IP
执行过程:- IP = SS X 16 + SP
- SP = SP+2
相当于POP IP
-
retf 指令:用栈中的数据同时修改CS和IP
执行过程:- IP = SS X 16 + SP ; 低字节
- SP = SP + 2
- CS = SS X 16 + SP ; 高字节
- SP = SP + 2
相当于 POP IP + POP CS
-
call 指令: 不能实现短转移,至少实现近转移
执行过程:- 将当前的IP或先CS和后IP压栈
- 跳转
-
依据位移进行转移的 call 指令 ---- 机器码中包含转移的位移,不包含目的地址。
格式:call 标号 ; 段内近转移
操作:- SP = SP – 2
SS X 16 + SP = IP ; ip进栈 - IP = IP + 16位位移 ;跳转
注意:
- 16位位移 = “标号”处的地址 – call 指令后第一个字节的地址
- 16位位移的范围是:-32768 ~ 32767,用补码表示
- 16位位移由编译程序在编译时计算出。
相当于:push ip + jmp near ptr 标号
实例:下面的程序执行后,ax中的数值为多少?
内存地址 机器码 汇编指令 执行后情况1000:0 b8 00 00 mov ax,0 ax=0 ip指向1000:31000:3 e8 01 00 call s 注意此处,CPU先将call s 读到指令缓冲区中,使得ip增加,实际进栈的IP为call指令之后第一个地址。此处是6进栈1000:6 40 inc ax1000:7 58 s:pop ax ax=6 - SP = SP – 2
-
转移的目的地址在指令中的 call 指令
格式:call far ptr 标号 ; 段间转移
操作:- SP = SP – 2
SS X 16 + SP = CS ; cs进栈
SP = SP – 2
SS X 16 + SP = IP ; ip进栈 - CS = 标号所在段的段地址
IP = 标号相对于所在段的偏移地址 ;完成跳转
相当于:push cs + push ip + jmp far ptr 标号
实例:下面的程序执行后,ax中的数值为多少?
内存地址 机器码 汇编指令 执行后情况 1000:0 b8 00 00 mov ax,0 ax=0,ip指向1000:3 1000:3 9a 09 00 00 10 call far ptr s 注意此处,CPU先将call far ptr s 读到指令缓冲区中,使得ip增加,实际进栈的IP为call指令之后第一个地址。此处是cs = 1000先进栈,然后ip = 8进栈 1000:8 40 inc ax 1000:9 58 s:pop ax ax=8h,从上面的执行可看出add ax,ax ax=10h pop bx bx=1000h add ax,bx ax=1010h - SP = SP – 2
-
转移地址在寄存器中的call指令
格式:call 16位寄存器
操作:- SP = SP – 2
SS X 16 + SP = IP ; ip进栈 - IP = 16位寄存器的值 ; 跳转
相当于:push ip + jmp 16位寄存器
实例:下面的程序执行后,ax中的数值为多少?
内存地址 机器码 汇编指令 执行后情况 1000:0 b8 06 00 mov ax,6 ax=6,ip指向1000:3 1000:3 ff d0 call ax 此处同上,进栈的仍是call指令后第一个字节的地址5 1000:5 40 inc ax 1000:6 58 mov bp,sp bp=sp=fffehadd ax,[bp] ax=[6+ds:(fffeh)]=6+5=0bh - SP = SP – 2
-
转移地址在内存中的call指令
格式 1:call word ptr 内存单元 ; 段内近转移
功能:ip = 该字型内存单元的值(2个字节)
操作:- SP = SP – 2
SS X 16 + SP = IP ; ip进栈 - IP = 内存单元的值 ; 跳转
相当于:push IP + jmp word ptr 内存单元
例如:mov sp, 10H mov ax, 0123H mov ds:[0], ax call word ptr ds:[0] ; 执行后 ip格式 2:
call dword ptr 内存单元 ; 段间转移
功能:cs = 该内存单元+2(高16位) ip = 该内存单元(低16位)
操作:- SP = SP – 2
SS X 16 + SP = CS ; cs进栈
SP = SP – 2
SS X 16 + SP = IP ; ip进栈 - cs = 该内存单元+2(高16位)
ip = 该内存单元(低16位) ;完成跳转
相当于: push cs + push IP + jmp word ptr 内存单元
实例:下面的程序执行后,ax和bx中的数值为多少?assume cs: codesg stack segmentdw 8 dup(0)stack endscodesg segmentstart:mov ax, stack ;占3字节mov ss, ax ;占2字节mov sp, 10h ;占3字节mov word ptr ss:[0],offset s ; 占7字节,(ss:[0])=1ahmov ss:[2],cs ; 占5字节,(ss:[2])=cscall dword ptr ss:[0] ; 占5字节,cs入栈,ip=19h(十进制是25)入栈(此时的IP是call指令后第一个字节的地址),ip = ss:[0] = 1aH转到cs:1ah处执行指令;(ss:[4])=cs,(ss:[6])=ipnops: mov ax, offset s ; ax = 1ah (十进制是26)sub ax, ss:[0ch] ; ax = 1ah-(ss:[0ch]) = 1ah - 19h=1 0cH对应的十进制是12,栈地址为0~15, 12和13字节存放的是call压栈的ip = 19Hmov bx, cs ; bx = cs=0c5bhsub bx, ss:[0eh] ;bx=cs-cs=0 0eH对应的十进制是14,栈地址为0~15, 14和15字节存放的是call压栈的cs 的值mov ax,4c00hint 21hcodesg endsend start利用 call 和 ret 来实现子程序的机制
格式:
……code segmentmain:……call sub1 ; call指令将其后第一个字节地址压栈后,跳转……mov ax, 4c00Hint 21Hsub1:子程序用到的寄存器入栈 ; 主要是为了防止子程序用的寄存器和主程序冲突…call sub2…子程序用到的寄存器出栈 ret ; ret指令恢复之前call压栈的值,注意:此处要保证子程序中没有修改栈中的数据,否则将不能返回sub2:子程序用到的寄存器入栈 ……子程序用到的寄存器出栈 Retcode ends end main - SP = SP – 2
- mul 乘法指令
格式:div 寄存器或div 内存单元
mul 使用默认寄存器
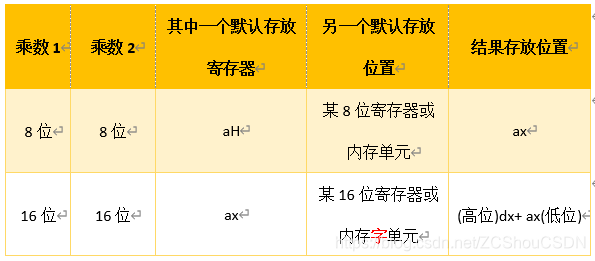
只能出现以上两种组合。例如:mul byte ptr ds:[0] ; ax = ah * (ds*16+0) 的积 mul word ptr es:[0] ; ax = ax * (es*16+0)的低8位; dx = ax * (es*16+0)的高8位
参数和结果传递问题
- 对于少量参数和返回值----------可以使用寄存器来存储参数和返回值
实例:设计一个子程序,计算data段中第一组数的3次方,保存在后面的一组dword单元中
程序:assume cs: code, ds: datadata segmentdw 1, 2, 3, 4, 5, 6, 7, 8dd 0, 0, 0, 0, 0, 0, 0, 0data endscode segmentstart:mov ax, datamov ds, axmov si, 0 ; ds:[si]读取dw数据mov di, 0 ; ds:[di]将数据保存到dd数据中mov cx, 8s:mov bx, [si] ; 用bx传递参数call cubemov ds:[di], ax ; ax是低位,注意dd是双字(占四个字节)mov ds:[di+2], dx ; 高位add si, 2add di, 4loop smov ax, 4c00hint 21h ; 说明:计算n的3次方 ; 参数:bx = n ; 返回值:dx = 结果高位 ; ax = 结果低位 cube:mov ax, bx ; 注意给出的数据时16位的mul bx ; ax中数* bx中数,结果的高位自动放入dx,mul bxret code ends end start - 批量数据传递--------------将数据放到内存中,而将数据地址给寄存器,传个子程序
实例:设计一个子程序,计算data段中中的字符串转化为大写
程序:assume cs: code, ds: datadata segmentdb ’convensation’data endscode segmentstart:mov ax, datamov ds, axmov si, 0 ; ds:[si]z=指向字符串mov cx,12call touppermov ax, 4c00hint 21htoupper:and byte ptr ds:[si], 11011111Binc siloop toupperretcode endsend start - 批量数据传递--------------用堆栈来存放参数和返回值
略
寄存器冲突问题
解决方法:在程序的开始将所用的寄存器中的内容保存起来,子程序返回前在恢复,可以用栈保存寄存器中的数据
未完待续…
这篇关于学无止境 之二 王爽老师 16 位汇编语言学习记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







