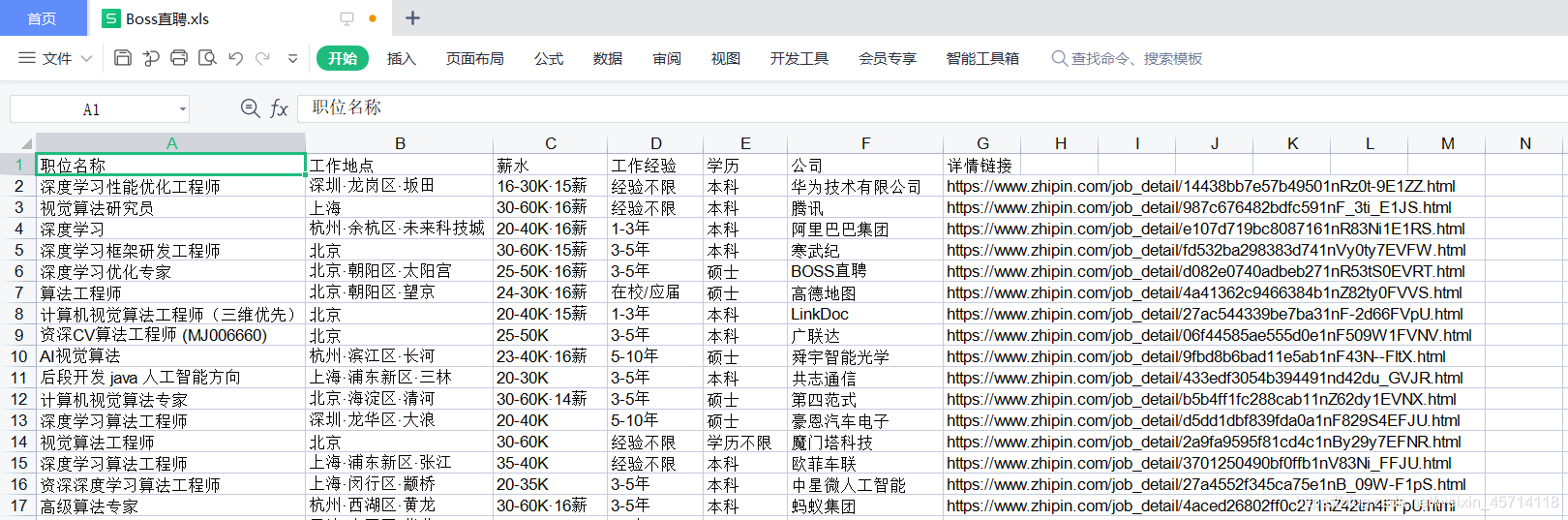
本文主要是介绍python爬虫(二)获取 Boss直聘上的岗位信息并保存到Excel表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 查看该网页的源代码,可以发现相关数据
查看该网页的源代码,可以发现相关数据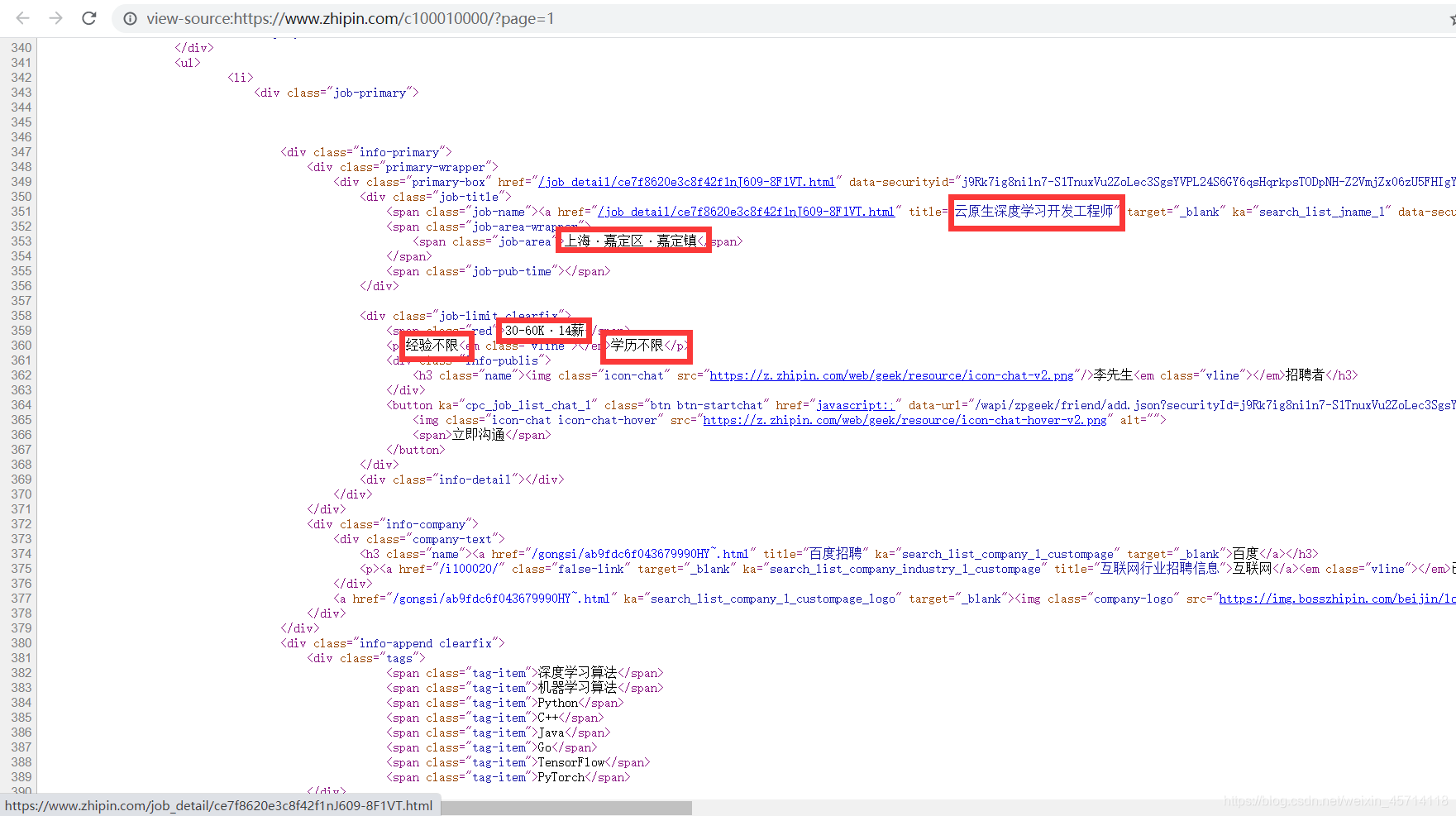
# Boss直聘import requests
import xlwt
from lxml import etreebegin = int(input("输入起始页:"))
end = int(input("输入终止页:"))
url = "https://www.zhipin.com/c100010000/"
base_url="https://www.zhipin.com"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4557.4 Safari/537.36','cookie': '__g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1628342274,1628476062,1628559147; lastCity=100010000; __c=1628559147; __l=l=%2Fwww.zhipin.com%2Fc100010000%2F%3Fpage%3D1%26ka%3Dpage-1&r=&g=&s=3&friend_source=0&s=3&friend_source=0; __a=51751789.1628342272.1628476062.1628559147.80.3.2.80; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1628559375; __zp_stoken__=44fccEA1HA2tYaygfIi87Y39AOV8QMShFLTJsCThyVHN4TQUcEithWCZrdEBRdGB%2BT3s1cRw9fggUJQYnIEMHSE0rHHpfbE0yGiREN2IMbHcNX3s6dg5iIzgCdHxZREcDf1glTGc4AHw%2FcjoH','referer': 'https://www.zhipin.com/c100010000/?page=2&ka=page-2'
}names = []
locations = []
salarys = []
requirements = []
educations = []
companys = []
links = []
items = []for page in range(begin, end+1):param = {'page': page}response = requests.get(url, params=param, headers=headers)html=response.content.decode('utf-8')#print(html)root=etree.HTML(html)name=root.xpath('//*[@id="main"]/div/div[2]/ul/li/div/div[1]/div[1]/div/div[1]/span[1]/a/text()')names.extend(name)location=root.xpath('// *[ @ id = "main"]/div/div[2]/ul/li/div/div[1]/div[1]/div/div[1]/span[2]/span/text()')locations.extend(location)salary=root.xpath('// *[ @ id = "main"] / div / div[2] / ul / li / div / div[1] / div[1] / div / div[2] / span/text()')salarys.extend(salary)requirement=root.xpath('// *[ @ id = "main"] / div / div[2] / ul / li / div / div[1] / div[1] / div / div[2] / p / text()[1]')requirements.extend(requirement)education=root.xpath('//*[@id="main"]/div/div[2]/ul/li/div/div[1]/div[1]/div/div[2]/p/text()[2]')educations.extend(education)company=root.xpath('// *[ @ id = "main"] / div / div[2] / ul / li / div / div[1] / div[2] / div / h3 / a/text()')companys.extend(company)link=root.xpath('//*[@id="main"]/div/div[2]/ul/li/div/div[1]/div[1]/div/div[1]/span[1]/a/@href')for i in range(0,len(link)):link[i]=base_url+link[i]links.extend(link)items.append(names)
items.append(locations)
items.append(salarys)
items.append(requirements)
items.append(educations)
items.append(companys)
items.append(links)#print(items)book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('items')
head = ['职位名称', '工作地点', '薪水', '工作经验', '学历', '公司','详情链接']
for i in range(0, 7):sheet.write(0, i, head[i])
for i in range(0, 7):a = items[i]for j in range(len(a)):sheet.write(j + 1, i, a[j])
book.save('Boss直聘.xls')
cookie需要根据当前网站https://www.zhipin.com/c100010000/?page=1的cookie进行更换
这篇关于python爬虫(二)获取 Boss直聘上的岗位信息并保存到Excel表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





