本文主要是介绍用视频给珠峰建了个三维模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前段时间,大疆《飞越珠穆朗玛》刷爆了朋友圈,DJI联合影像团队8KRAW成功登顶珠穆朗玛峰,并使用大疆Mavic3飞越珠峰留下了震撼的珠峰峰顶画面。飞越8848.86m留下的视觉盛宴,隔着屏幕都觉震撼!

对于如此震撼的珠峰画面,不少行业人士看后表示想给珠穆朗玛建个模型。那今天我们就来安排,用现有的素材给珠峰建个模!
视频与图文教程
提取珠峰视频
《飞越珠穆朗玛》视频一共2分41秒,我们需要在视频中剪辑提取涉及珠峰画面的片段,使用的软件是剪映,通过剪映分割功能挑选出适合建模的视频画面最后导出所需视频。
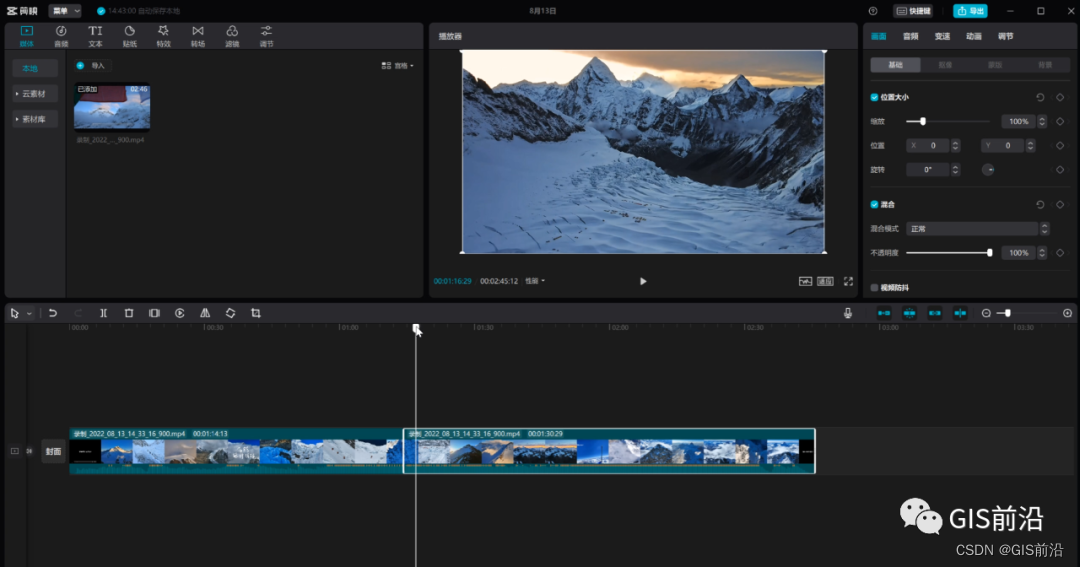
经过筛选,适合建模的视频。为了保证画面质量,视频导出4K、60帧、MP4格式。

视频生成模型
有了视频下面就要开始建模,主要步骤是通过视频提取照片再通过照片生成模型。
所需软件:
ContextCapture
大疆智图

//
CC提取视频照片
打开CC,新建工程导入视频帧(注意不能带中文字符),通过CC截取帧的方式,输出每一帧的照片。
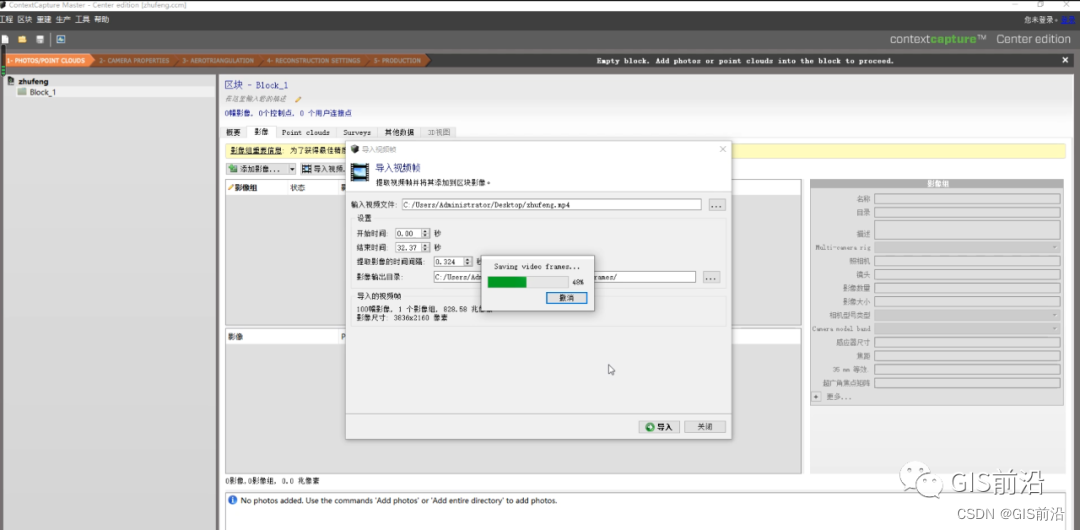
32秒视频一共生成100张珠峰影像,这些就是珠穆朗玛峰的原始数据了。
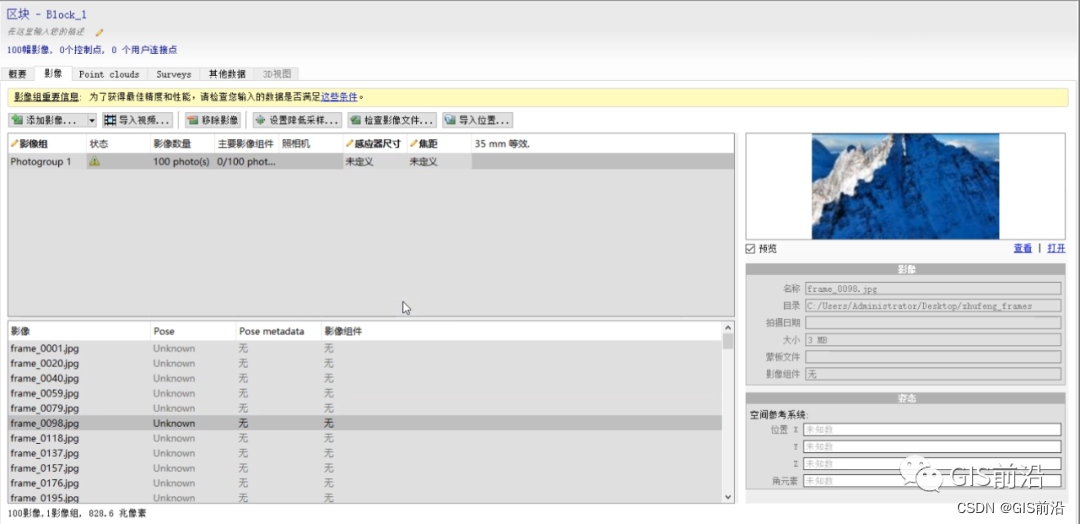

//
大疆智图生成模型
打开大疆智图,新建可见光项目。
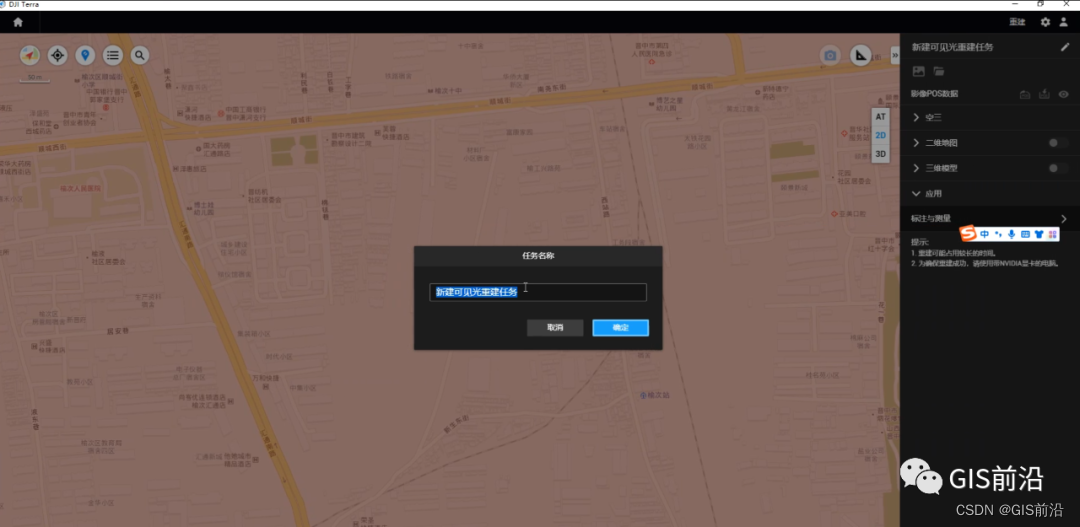
将刚才CC提取的珠峰原始数据导入.
进入空三页面,开始空三,看下三维空三结果,还是不错的。
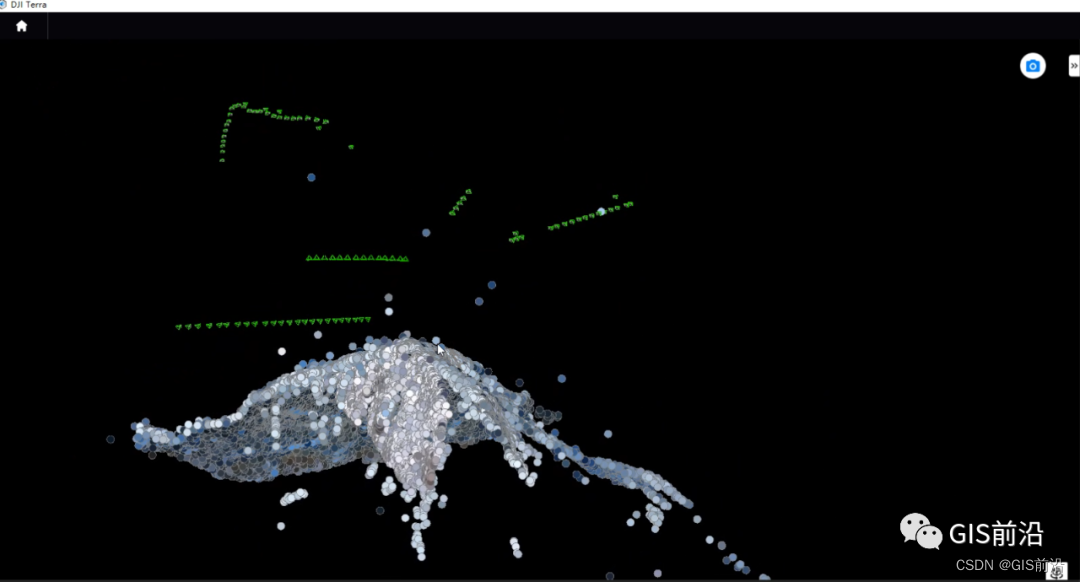
空三出来后开始建模,不过在三维建模前,我们进行一下范围约束,这样可提升建模速度和建模范围更精确。
一切设置完成后,选择大疆智图三维模型模块,选择模型格式。
点击开始重建,然后就静静等待珠峰三维模型的生成。

等待生成模型
模型效果
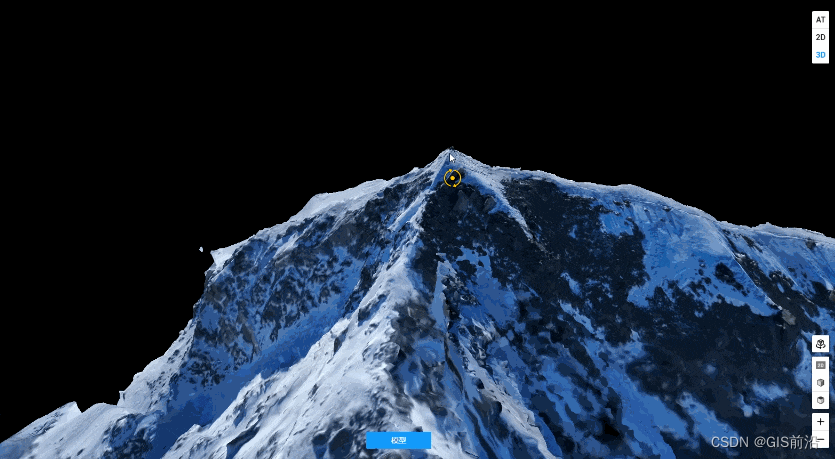
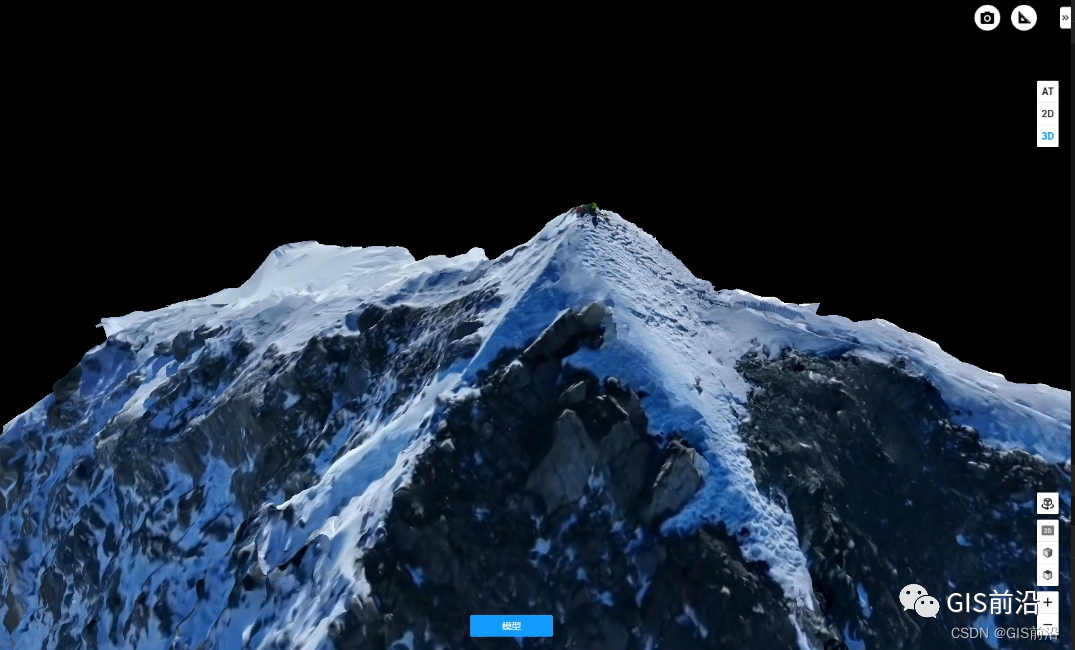


本文原始素材由视频号:山西文达通信息技术有限公司&航测实验室提供
- END -
这篇关于用视频给珠峰建了个三维模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








