本文主要是介绍【论文阅读VLDB23】Online Schema Evolution is (Almost) Free for Snapshot Databases,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Online Schema Evolution is (Almost) Free for Snapshot Databases
对snapshot DB来说可以几乎在线进行schema的演变。
ABSTRACT
在现有数据库系统中,对在线和事务模式演变的支持仍然具有挑战性。之前处理这种schema 演变基本是patches补丁的方式来做,就会导致很多corner case,导致一般需要停止DML来执行DDL。本文基于MVCC数据库可以data-defination-as-modification(DDaM),提出了Tesseract来实现通过并发控制协议来控制DDL操作。Tesseract能够提供在线的事务性模式演化,而不会导致服务停机,并在模式演化进行时保持较高的应用程序性能。
1 INTRODUCTION
MySQL[40]、PostgreSQL[52]、SQL Server[33]和Oracle[41]——都实现了MVCC,以提供快照隔离(SI)或可重复读取作为默认或推荐的隔离级别。
现代DBMS需要优雅地处理模式演变问题,例如,添加列、从现有数据创建表和更改约束。在内部,DBMS通过更新数据库元数据来存储新的模式,并检查(例如,根据新添加的约束)和迁移现有表数据以符合新的模式来处理DDL语句。模式演化过程中的数据验证和迁移可能导致大量数据移动,从而阻塞并发数据操作语言(DML)语句。要求DDL语句以以下方式执行:(1)在线而不阻塞并发数据访问;(2)事务性,以便在DDL语句失败的情况下(例如,试图将包含“非法”字符的tvarchar转换为INT),操作可以安全地回滚以使数据库保持一致状态。
1.1 Ad hoc Schema Evolution in MVCC Systems
已经有一些尝试在单版本和多版本系统中支持在线和事务模式演变,但它们仍然在两个方面存在不足:
- 现有的方案有太多special corner case需要OLTP引擎和应用程序开发人员小心处理。如果一个事务包含任何DDL语句,那么该事务将被静默提交。可以延迟完成DDL操作,也就是延迟迁移数据,但是会引入不兼容的状态,需要提前检查列内容,如果元数据(schema)改变之后很难回滚,因为新版本的应用程序可能已经开始使用新模式,导致某些数据被丢弃或不可用。处理这些特殊情况大大增加了系统设计的复杂性。
- 过去的解决方案通常强烈依赖于特定的DBMS特性,其中一些本质上就是数据库应用程序本身。一些系统依赖于views和triggers,当它们使用禁止并发更新的表级锁定时,会出现性能瓶颈。
根源是设计DDL并不是设计DBMS的头等事,DDL支持通常是事后考虑的,是带有“补丁”的临时解决方案,逐渐应用于DBMS。经常将DDL操作描述为“危险的”和“危险的”,因此,应用程序开发人员经常尽力避免DDL操作,这会限制应用程序功能和最终用户体验。
1.2 Tesseract: Data-Definition-as-Manipulation
Tesseract,这是一种在MVCC系统中实现非阻塞和事务性模式演化的新方法。
Tesseract通过直接调整MVCC数据库引擎中的并发控制(CC)协议,为在线和事务性模式演化提供内置支持。1. 从概念上讲,事务性DDL操作可以通过修改模式和(有时可选地)所涉及的整个表的DML语句来作为“正常”的事务建模。2. 在MVCC系统中,由于其内置的版本控制支持,模式可以存储为版本化的数据记录,并以类似于“正常”数据访问的方式参与并发控制,以确定表数据的可见性。设计了数据定义即操作(DDaM)data-definition-as-manipulation通过稍微调整数据库引擎中的底层SI协议,几乎“免费”地支持在线和事务性DDL,而不必依赖视图和触发器等附加功能。
Tesseract仍然用catalog来将每个表(或其他资源,如数据库)与存储在目录表中的模式记录关联起来,目录表又具有预定义的模式(例如,表名,约束等)。使用系统内置的多版本,可以让schema record也是多版本的。这就支持DDL:1. 像一般的record更新一样来添加新的schema版本。 2. 在并发控制下的一个事务内完成数据验证和迁移(data verification and migration)。要访问表,DML事务只需遵循标准SI协议来读取对事务可见的表的模式记录版本。然后,模式版本记录指示事务应该访问哪些数据记录版本。
DDaM概念简单,但是有以下情况:1. DDL 事务很长 2. 并发事务导致DDL频繁中止 3. 单纯遵循SI协议会增加很多内存来跟踪写操作。3. 小心处理并发DDL和DML操作,确保新模式提交后,基于旧模式版本完成工作的DML事务永远不会提交。宽松的DDaM,调整SI协议以允许更多的并发性并减少不必要的中断,是Tesseract在不牺牲太多DML操作的情况下实现在线模式演化的关键。
单版本系统如果才去一些步骤来支持版本化schema,也可以采用Tesseract。Tesseract还可以与现有的惰性迁移方法[4]一起工作,以支持兼容模式更改的即时部署。对于涉及重量级数据复制(如迫切添加列)的DDL操作,我们通常只观察到高达10%的DML操作下降。
1.3 Contributions and Paper Organization
- 贡献
- 模式演变转化成对整个表的修改,并为事务性和非阻塞DDL操作提出了一种简单但有用的数据定义即操作(DDaM)方法
- 展示了如何将简单的调整应用于常见的快照隔离协议,以便轻松地本地支持事务性和非阻塞DDL,而无需特别的“补丁”
- 基于DDaM,我们构建了Tesseract,展示了Tesseract的可行性
- 编制了一套全面的模式演化基准benchmark
2 MVCC BACKGROUND
2.1 Database Model
MVCC Model:数据库由一组记录组成,每条记录由一个全有序版本序列表示,更新即添加新版本到序列,删除即添加tombstone版本。插入一条记录被视为添加该记录的第一个有效版本的更新。要读取记录,事务将根据所使用的隔离级别选择对其可见的版本。系统维护了一个中央计数器,64 int。在开始(或访问第一条记录)时,事务读取全局计数器以获得开始时间戳,在提交的时候,事务自动增加全局计数器以获得提交时间戳。
2.2 MVCC/SI in Practice and Assumptions
ERMIA是一种内存优化的数据库引擎,本文的实现就是以此为基础的。记录版本可以由dbms管理的堆页面和表空间管理,也可以由堆中的内存定位器管理。Table由内存中的indirection array(简介数组) 或者叫mapping table 映射表来表示,
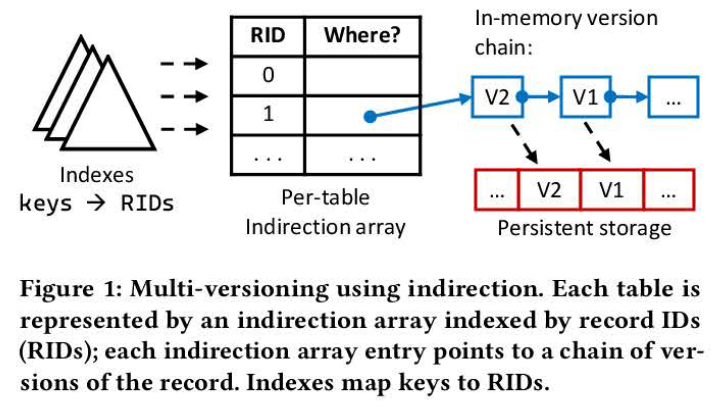
使用间接的多版本管理,由Key经过index索引到RIDs,在间接数组中指向该条记录的版本链in old to new;插入一条记录,事务生成一个新版本的record,然后插入到版本链的头,经过CAS更新table里面的entry。每个事务维护一个写集,在提交时,事务首先执行一个预提交阶段,从中央计数器获取时间戳,给new version贴上这个提交时间戳,然后是一个后提交阶段,在将结果返回给客户端之前持久化日志记录。预提交阶段实际上是在内存中提交事务。如果事务在提交后的检查中失败,则必须终止它。
为了避免日志提交成为瓶颈,一些系统采用流水线提交[21]将日志提交与提交路径解耦。在预提交工作之后,线程将事务传递到提交队列,并继续处理后续的请求。一旦刷新日志记录,事务就会从提交队列中删除,并被认为已完全提交。由于整个工作集都在内存中,所以通常不需要undo log记录。因此,事务只需要生成和保存redo log日志(例如,新版本),从而导致redo-only log。
3 TESSERACT OVERVIEW
DDaM的关键是如何把DDL → 对全表修改的DML。列属性Int → Float可能很直接,但是其他的可能有其他要求。首先对DDL进行分类,然后不同DDL映射到的DML操作,然后展示如何使用DDaM扩展标准SI协议。
3.1 Categorizing DDL Operations
(1)当操作需要实际的数据复制/修改 (2) 修改需要进行验证,例如read-only。分别称为copy and verify。

根据涉及到copy或者verify来分类。
对于INT→FLOAT 或者 FLOAT → INT,需要copy + verify,扫描表数据,确保新旧表格式兼容,然后转化为新格式。如果在转换数据时检测到不兼容的更改,则必须中止DDL操作。某些操作只涉及“验证”维度。例如,要向现有列添加一个非null约束,需要确保整个列不包含null值;否则将终止操作。CREATE … AS SELECT …不需要验证或者复制。DDL操作是否涉及复制或验证也取决于底层系统的设计和实现。例如,像创建/删除表这样的操作可以在没有复制或修改的情况下执行,只需更改系统目录(因此在表1中被列为无复制、无修改)。
如果支持lazy DDL操作:DDL事务只需要修改表模式以包含这个新列,以及一个函数指针,该指针在后续的DML事务访问数据时填充该字段的默认值。即一开始不真去创建列,访问的时候再去把列弄出来,即Lazy。
3.2 Schema Versioning
遵循经典方法schema record存放在catalog table里,catalog table 的schema 是预先定义的,在DDaM下,这意味着每个表都与一个schema record相关联,定义了data types, columns, and constraints。
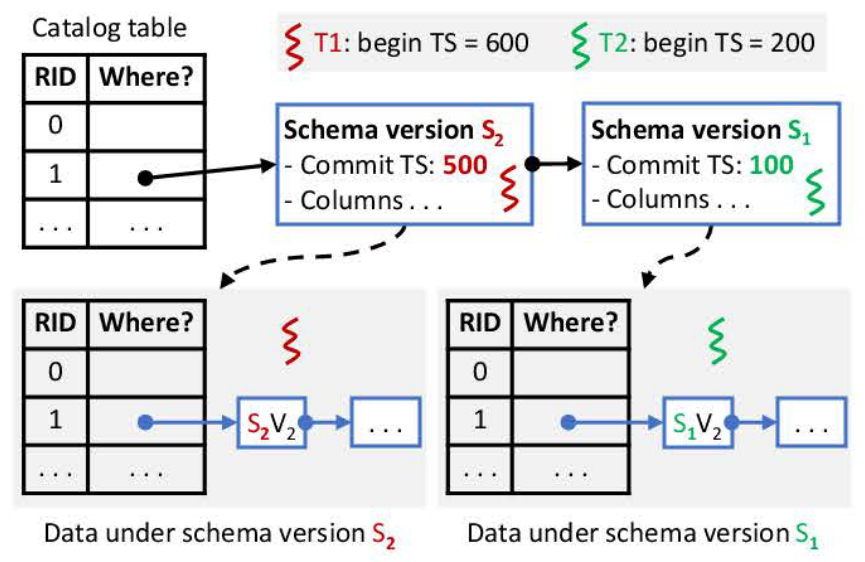
为了访问一条记录,数据和模式必须匹配:事务(1)选择最新的可见模式,(2)重新找到符合schema record的最新version records(tuples)。
catalog记录的每个record,实际是一个schema log 的版本链,每个schema version 还包括携带一个提交时间戳,还有其他信息:列列表、约束和与之相一致的数据的访问路径。要访问一条record,事务需要access a catalog version → 相应的data version(符合SI的可见性)
3.3 Transactional DDL and DML Operations
事务在Tesseract是DDL mixed up with DML的。
对UPDATE,需要保证:确保(1)最新的记录版本和(2)最新的模式版本对事务可见。如果并发DDL操作安装了较新的数据库版本,但在DML事务提交之前没有提交,那么并发DDL可能会更新整个表,从而导致write-write冲突,从而导致事务的中止。如果更新操作(仍在old schema下)的事务提交比并发DDL事务提交的晚,那么新版本的record的TS比将要提交的新schema的时间戳大,这将导致后续读取错误地使用较新的模式解释旧的记录版本,因此必须禁止。
DDL 遵守SI 和普通的DML一样参与并发控制,通过更新schemas records,在执行一些必要的transform / verify
4 DATA-DEFINITION-AS-MODIFICATION
DDaM的一种直接方法是通过严格遵循DML操作的通用SI协议,将模式访问建模为数据记录访问。
4.1 Generic SI Protocols
RID来标识Table,table[rid]存储了一个指针指向由rid标识的元组在版本链上的最新版本(按照从新到旧的顺序)。
generic_read 是 读事务来遍历版本链以查找最新的可见记录版本以及它是否是最新的;
generic_write 是(1)确保事务可以看到最新版本(第11-13行); (2)将当前头部版本链接到新版本之后(第16行);(3)发出CAS,在间接数组项上安装指向新版本的指针(第17行)如果CAS成功,则将更新记录在提交的写集中.
global: catalog # global schema table# t is txn, table rid -> versions about record
def generic_read(t, table, rid):# Traverse the data version chainfor each v in table[rid]:if v.commit_ts < t.begin_ts:return {<v, is_latest(v)}return nildef generic_write(t, table, rid, new_v):v = table[rid]if v.commit_ts > t.begin_ts:return false# Try to install the new version new_v.next = v # link new and old versionssuccess = CAS(&table[rid], v, new_v)if success == true:t.write_set.add(table.id, rid)return successdef ddam_get_schema(t, table):return = generic_read(t, catalog, table.id)def ddam_update_schema(t, table, new_schema):# Perform a normal write to install the new schemaif !generic_write(t, catalog, table.id, new_schema)return false# migrate data (details in Sec. 4.2-4.3)if !migrate(t, table, new_schema):return false
4.2 Basic Data-Definition-as-Modification
对于对schema的读取,对于通用SI协议,读取模式记录与将目录存储为表的经典方法相同,通过使用generic_read来获得可见的模式记录版本(算法1中的第22 - 23行ddam_get_schema)。在这里传入table.id 作为要读的RID。
-
Schema Operations
DDaM下模式演变需要两个阶段:
首先,我们按照正常的SI协议更新模式记录本身:如果最新的模式版本对发出的事务不可见,它将中止(算法1的第27-28行)。
在新模式记录版本成功安装之后,但在事务提交之前,事务将在第31行进入数据迁移阶段(如果需要),该阶段可能涉及由generic_read和generic_write完成的复制和/或验证操作
数据迁移之后进入提交阶段,(用于读取和更新模式记录的两个协议都封装在事务上下文中,因此它们也遵循引擎提供的全有或全无原子性保证,从而支持事务模式演化)。
上面basic的算法不是对一个表的不同schema都单独有个简介数组,而是一整个表就是一个简介数组,这使设计保持简单,但可能导致更多的中止。
-
Data Record Accesses
读取或更新表中的普通数据记录非常简单,只需在实际的记录访问之前添加模式访问即可。算法2显示了完整的协议,并突出显示了与schema相关的步骤。要读或写表记录,对普通SI协议唯一增加的是考虑对访问事务可见的模式版本。此外,对于写操作,每个事务还将维护一个模式集,该模式集记录了事务使用的所有模式版本(第15-16行)。这对于确保提交时验证是必要的.
-
Commit Protocol
在完成所有记录访问之后,事务使用算法2(第19-32行)中所示的ddam_commit来尝试提交。与普通SI协议一样,事务从获取提交时间戳开始(第20行)。它遍历模式集,以验证对于每个更新的记录,事务在更新时使用的schema version 在提交时仍然是最新的,
算法2:
https://www.notion.so
4.3 Issues with Basic DDaM
严格遵循SI协议是一把双刃剑,它可能使DDaM不切实际。观察到基本DDaM有几个问题:
- DDL事务通常是重量级的、长时间运行的事务,因为它们可能导致全表扫描和迁移。长时间运行的DDL事务可能会由于写-写冲突而导致其他并发的DDL事务中止。
- 如果一个早先的事务修改了一条record,然后后面的DDL事务需要访问修改该record,则该DDL事务可能就终止了。这将浪费DDL和/或DML事务所做的大量有用工作。如果一直简单的遵循first-committer / updater-wins protocol,那么模式演变事务能够成功只能看运气了。所以要修改该提交协议。
- 依靠通用SI协议意味着在数据迁移期间完成的写操作也将被跟踪。这反过来又增加了维护(非常大的)写集的重要开销,减慢了提交速度。
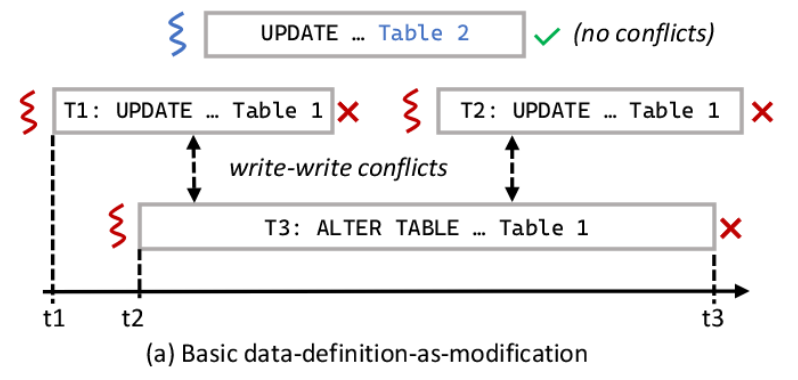
5. TESSERACT WITH RELAXED DDAM
DDaM的问题主要是因为基础SI协议允许并发的写事务太少。
- DDL事务可以与一个并发的DML操作竞争,使用一个间接数组在目标表上安装新版本,导致写-写冲突中止。
- 在默认情况下,事务由一个线程提供服务,由于单个CPU核心的计算能力有限,导致长时间的冲突窗口。
- 大的写集加剧了这个问题
因此,改进目标是
- 允许更多并发(写)事务提交
- 在减少事务元数据跟踪复杂性的同时增加并行性,最终缩短冲突窗口。
要使用relaxed DDaM ,本文实现了下面三个feature
(1)异地迁移机制an out-of-place migration mechanism(2)冲突解决方案和(3)仍然提供相同SI隔离级别的放松快照relaxed snapshots。
下面分别介绍out-of-place migration + CDC + Relaxed Snapshots
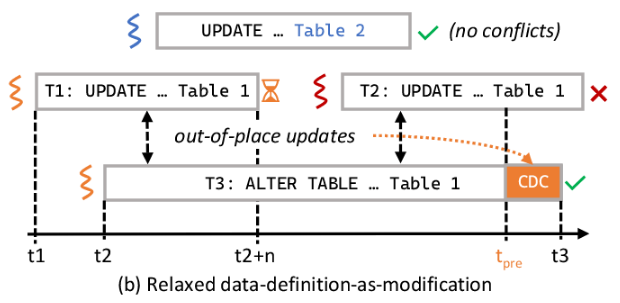
5.1 Out-of-Place Migration
如果是为了兼容格式转换等需要进行copy,数据迁移将成为DDL事务的大部分。宽松的DDaM创建一个新的间接数组来存储由于DDL操作而生成的新记录。如图2所示,其中每个模式记录版本还包括对相应间接数组的引用。在DDL操作完成之前,新的间接数组对其他事务保持不可见…
因此,并发DML事务(如T1和图2 T2)中的2继续使用原始的间接数组来执行读写,而不知道并发DDL操作。允许这些DML事务在内部进行和预提交。并发DML事务在图2中继续使用原始的间接数组来执行读写,而不知道并发DDL操作。允许这些DML事务在内部进行和预提交。为了保证正确性,在并发DDL操作结束之前,它们不会最终确定。
使用pipelined commit来实现,本质上,我们放宽了SI的写-写冲突处理协议,允许更多的“试探性” “tentative”写,并通过更改数据捕获将冲突解决推迟到以后的时间。
如图3b,T1将被添加到提交队列(可以是全局队列,也可以分区以避免成为瓶颈)并等待。正在处理事务T1的底层线程,现在可以切换到处理下一个请求,而不阻塞。
T3 DDL事务通过使用多线程扫描原始间接数组来迁移表数据。对于扫描的每条记录,DDL事务(1)根据新的模式转换记录,(2)在新的间接数组中安装新的记录版本。在迁移过程中,除了更新之外,并发DML事务还可能向原始间接数组添加新记录,这可能会增加必须扫描的数据量。为了限制扫描过程中完成的工作量,DDL事务在启动时捕获间接数组的大小(S),并且只扫描表中最多S条记录。图3(b)中的[t2, tpre]周期表示这个“扫描-转换-安装”过程。
由于DDL事务是唯一可以访问新的间接数组的事务,因此可以保证安装步骤成功。然而,如果预期的模式演变与现有数据不兼容(例如,将FLOAT列转换为INT,但数据有小数点),则转换步骤可能会失败。在这种情况下,DDL事务将中止,所有分配的资源(新记录版本链和间接数组,它们对其他事务不可见)将被回收。
5.2 Change Data Capture
在图3(b)中tpre时刻扫描表之后,系统可能已经根据并发DML事务完成的原始模式版本积累了一系列更新。DDL事务必须检查和转换这些更新以使用新的模式。为此,我们在Tesseract中引入了变更数据捕获Change Data Capture(CDC)阶段;
如果更新和新模式之间发生不兼容的更改,则可以根据应用程序的需要终止DDL或DML事务。
尽管浪费了大量的数据迁移工作, 有时也需要中止DDL事务,在“违反”DML事务提交后,尝试相同更改的后续DDL事务将被中止,因为它与现有数据不兼容。
在某些情况下,如果违规的DML事务是应用程序的一小部分过时的事务,并且应该很快结束,则可能需要中止这些事务。有无pipelined commit,可以中止DML事务,但是会引起cascading aborts 级联中止。处理级联中止可能需要跟踪事务依赖关系,这会增加额外的开销。或者,可以利用提交流水线来避免跟踪依赖关系,方法是在违反DML事务之后,简单地中止所有预先提交的事务。但这可能会导致无辜的交易被中止。因此,尽管我们当前的实现中止了DDL事务,但在实践中,应该通过考虑应用程序的属性来做出这样的权衡决策。
CDC阶段的速度非常关键:如果工作太多,打算使用新模式的DML事务将等待很长时间,从而增加事务延迟。通过(1)限制CDC工作量和(2)为CDC引入更多的并发性和并行性来解决这个问题。
DDL获得precommit timestamp,开始CDC phase,然后DDL事务使新模式可见,但将其置于特殊的“挂起”状态。这样,在Tpre之后启动的任何新事务都应该开始使用新的模式,从而避免了数据转换的新的CDC工作;然后DDL事务继续CDC阶段,扫描日志以发现预先提交到Tpre的并发更新。
为了方便起见,扫描阶段在开始时记录当前日志序列号,该序列号将用作CDC阶段的起点,CDC结束点图三中的t3,标记模式演化事务的完成,解除任何依赖事务的阻塞。
为了加速CDC,(1)为CDC分配多个线程,(2)更重要的是,允许CDC在扫描阶段完成之前启动,以缩短CDC阶段。CDC阶段通常在扫描阶段之后开始,此时DDL事务已经获得了预提交时间戳(Tpre)。因此,CDC阶段可能与扫描阶段重叠,但是DDL事务仍然会在扫描阶段结束后预提交(即,使新模式可见,但挂起)。因此,CDC线程可能与同一DDL事务的扫描线程发生冲突。这种冲突的处理类似于SI协议:CDC和scan线程都必须使用CAS指令来安装新记录,同时观察版本顺序,这样只有当版本是最新的(即头版本较旧)才会安装到版本链中。
5.3 Relaxed Snapshots
Basic DDaM,generic SI,DDL事务根据开始时间戳定义的快照来迁移数据,导致该快照很容易stale?导致CDC很慢
改进:允许DDL事务在扫描阶段始终直接迁移每条记录的最新提交版本,out of place migration 使用一个特定的indirection array来允许relax simplify the SI。新间接数组上的新转换版本继承原始记录的提交时间戳。这样,DDL事务就可以尽可能地迁移新版本,而且实际上不需要为新版本维护写集,因为在迁移后记录被标记为已提交,从而大大减少了DDL事务的元数据跟踪开销。新迁移的版本在DDL事务完全提交之前保持不可见(即,在CDC阶段完成之后)。其次,更重要的是,在模式演化过程结束后,新的间接数组将取代原来的间接数组。因此,在DDL事务预提交之后启动的任何事务都将使用新的间接数组。这反过来意味着只有一个有效的候选版本对这些事务可见。然后,可以安全地使用原始的、较小的时间戳戳新转换的版本,以换取更快的DDL提交,而不必像原始SI协议那样遍历写集。
进一步缩短CDC阶段,允许无关的DML直接执行,如果DDL事务与约束检查相关,那么所有DML事务都应该等待DDL事务完成。如果DDL事务的数据迁移只涉及复制操作,那么无论这些记录是否已经迁移,对目标记录进行盲写(更新和插入)的DML事务都可以继续进行。(隐含的是该DML事务开始时间早于DDL事务?only care about log? CDC再写log吗)
对于具有读操作的DML事务,可以在目标记录已经迁移之后继续执行。?
在访问数据记录时,事务只是在新的间接数组上对迁移的记录进行“偷窥”。如果这样的记录不存在,或者该记录的提交时间戳大于原始间接数组上的时间戳,则打算更新该记录的DML事务应该中止。原因是,前一种情况表明该记录尚未被迁移,而后一种情况表明另一个DML事务已经更新了该记录,但仍有待迁移。否则,如果新的间接数组携带较新的版本,则允许DML事务访问该记录,但在DDL事务中止的情况下,将受到提交流水线和中止的约束。
5.4 Discussions
relax DDaM允许更多的并发事务,可能会导致重量级DDL中止。但是多线程执行DDL,大多数CPU周期将用于执行DDL操作,从而为模式演化提供更高的优先级,这种情况就很罕见。
Tesseract是SI DB,所以存在SI的各种问题,不保证可序列化性。
有些系统evolve schemas lazily,一旦模式更新,它就变得可见(提交),而数据迁移则在后台或在记录访问时按需进行。Tesseract兼容并且可以采用这种方法,通过进一步放宽DDaM来允许新模式的早期可见性,而不使用额外的应用程序级数据结构.
Lazy 的缺点:不兼容的模式更改可以在不进行验证的情况下提交,导致一个分歧。有些DDL操作在本质上是急于执行的,而惰性演化对此没有帮助,范围索引的创建要求在允许任何范围查询之前完成整个DDL操作,以避免丢失记录。
6 EVALUATION
使用微基准测试和标准基准测试对Tesseract进行评估,从以下几个方面进行了探讨:
- DDaM和Tesseract原生地支持非阻塞事务模式演化,包括DDL操作
- Tesseract减轻了模式演化中传统特设方法的缺点
- 与基本DDaM相比,宽松的DDaM可以在事务之间提取更多的并发性。
6.1 Experimental Setup
-
Implementation
在ERMIA[22]中实现了Tesseract,是一个开源的内存优化数据库引擎。
tmpfs:临时文件系统,驻留在内存中。
-
Approaches under Comparison
- NoDDL:没有任何DDL功能的普通ERMIA。我们用它来表示上界。
- Blocking: Baseline,通过表级锁来实现schema的consistency,不涉及schema变化的DML事务获得读锁,DDL事务获得写锁。
- Lazy:只更新 DDL 事务中的模式记录,数据迁移在后台或需求完成
- Tesseract:带relax DDaM
- Tesseract-lazy:在引擎级别使用惰性数据迁移以实现优化,例如第 5.4 节中提到的索引重用。
-
Methodology and Metrics
对于每个工作负载,我们发出一个DDL事务,然后测试各种工作负载和上述方法下DML事务的吞吐量,看模式演变对DML的影响。
6.2 Benchmarks
Microbenchmarks:所有事务都是在三个 8 字节整数列的单个表上执行的,这些列预先加载了 100 万条记录。引入了两个新的 DDL 操作:AddColumn 和 AddConstraint,前者涉及copying/transformer,AddConstraint强调verify。不断发出和完成DML事务,某个时间段之后,提出了一个 DDL 事务来执行上述操作之一,为 DDL 事务分配八个线程(三个用于扫描,五个用于 Tesseract 中的 CDC)和 30 个用于 DML 事务的线程。
TPC-C with Schema Evolution (TPC-CD):
- AddColumn:在 order_line 表中添加一个列 ol_tax,默认值为 0.1
- AddConstraint:对于 order_line 表,添加一个约束需要 1 ≤ ol_number ≤ o_ol_cnt
- AddColumnWithConstraint:除了AddColumn之外,还添加了一个约束,需要ol_amount≥0
- SplitTable:将客户表拆分为两个,一个包含私人客户信息,例如信用、支付和余额,另一个包含公共客户信息,如州、城市、街道等
- Preaggregate:Preaggregate:在order_line表中求和值,结果在oorder表中作为新列添加
- JoinTable:join stock and orderline 表。
- CreateIndex:为 order_line 表创建一个主索引。
6.3 Performance under Schema Evolution
-
Copy-Only AddColumn
主要是数据复制,开始的gap是因为该差距显示了正常记录读/写路径上的访问模式信息的开销。Blocking gap很大是因为要加锁?DML加读锁,在5秒内实际上显示为零吞吐量,因为DDL事务在模式演化期间对整个表具有独占访问权。
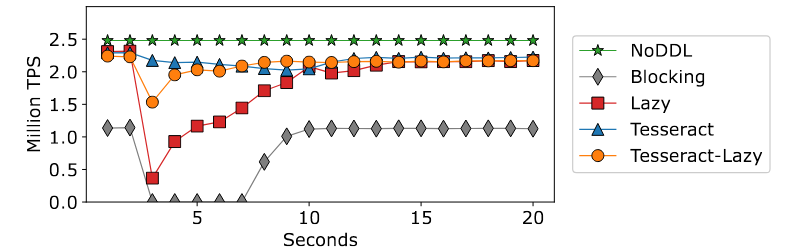
-
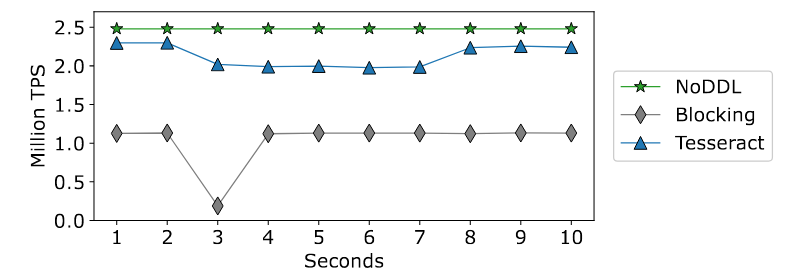
Verify-Only AddConstraint and Mixed DDL
在评估方法中,只有 Blocking 和 Tesseract 可以支持需要verification的 DDL 操作,Lazy 和 Tesseract-Lazy 允许立即提交模式更新,但在不兼容的模式更改的情况下不能保证完全的正确性。所以只显示了Blocking Tesseract和NoDDL。
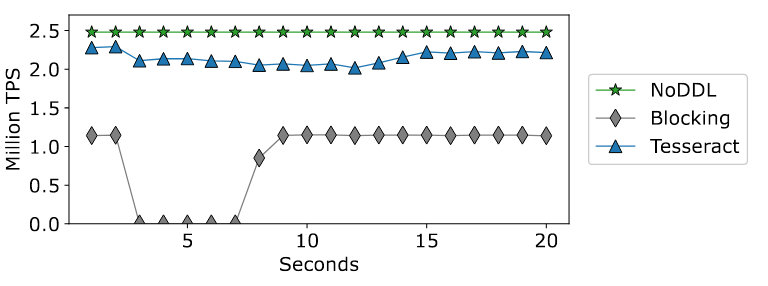
下面是Mixed DDL:
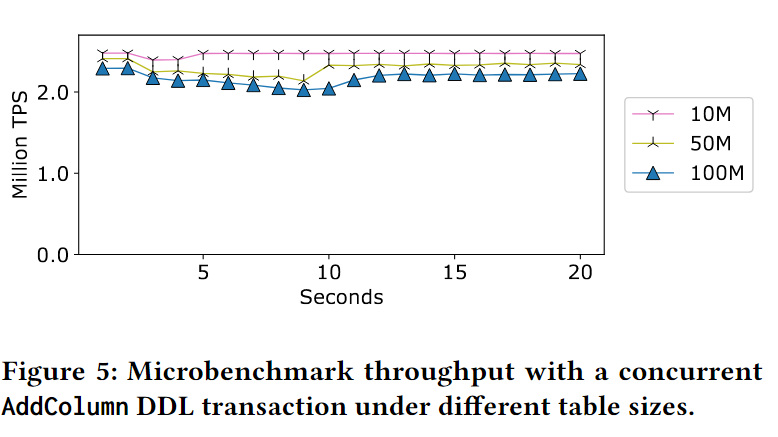
6.4 Impact of Table Size
探索microbenchmark参数影响,表大小是如何影响模式演化性能的。特别是,对于以复制为主的DDL操作,更大的表将需要在迁移记录上投入更多的工作,重复第6.3节中所做的AddColumn实验,但改变表的大小来探索这种效果。Tesseract在不同表大小(从1000万到1亿)下的吞吐量。一般来说,更大的表大小会导致Tesseract下降得稍微多一些,并且需要更长的时间来完成模式演化,但不会像其他协议那样产生重大影响。(不就是几乎线性的关系吗?或者是递减关系)
6.5 Impact of Worker Thread Allocation
Tesseract为DDL操作使用多个线程,因此为DDL操作快速完成的扫描和CDC阶段选择正确数量的线程非常重要。用AddColumn事务运行微基准测试,改变了CDC和scan线程的数量,DDL线程的总数保持在8个,CDC/scan线程的数量在3-5个之间变化
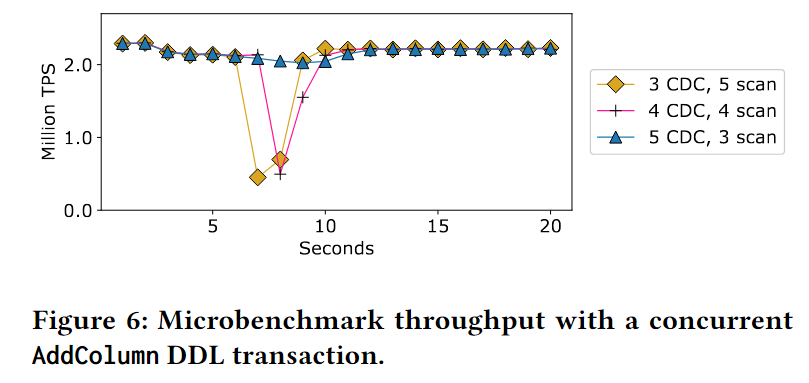
使用更多的CDC线程显然是Tesseract保持高性能的关键,因为当我们有3-4个CDC线程时,就很难跟上并发DML线程的速度。
但是,对于读密集型工作负载DML,可以分配更少的CDC线程,以便为处理DML事务留下更多的资源。上面是
6.6 End-to-End TPC-CD Results
我们运行标准的TPC-C混合,并在两秒钟后启动不同类型的DDL事务
-
Copy-Only DDL Operations.
阻塞仍然会产生最高的开销。随着更多的计算涉及到更现实的工作负载,Tesseract和其他非阻塞方法之间的差距变得越来越小。
Tesseract-Lazy的性能比Lazy要好,这显示了当应用程序确定预期的模式更改与现有数据兼容时,Tesseract使用惰性迁移的潜力,甚至比自身本来都好?
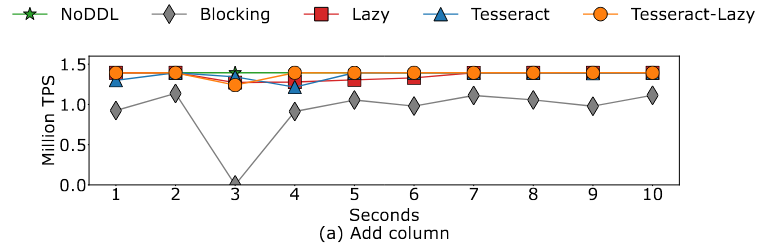
Tesseract可以匹配addcolumn中性能最好的Lazy,并且在其他情况下性能稍好一些
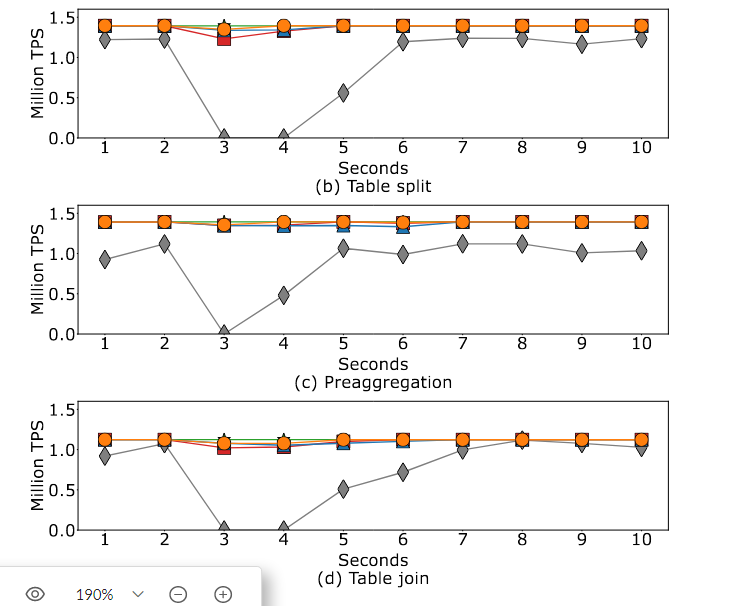
-
DDL Operations with Verification
开始就发出CreateIndexDDL,一开始,系统几乎无法提交任何事务,因为没有新索引,事务必须发出全表扫描,导致每秒提交的事务非常低。在索引创建DDL事务启动后,在阻塞和tesseract下,TPC-C的总体吞吐量开始上升,Tesseract允许更多的并发性,与Blocking相比,它允许提交更多的事务
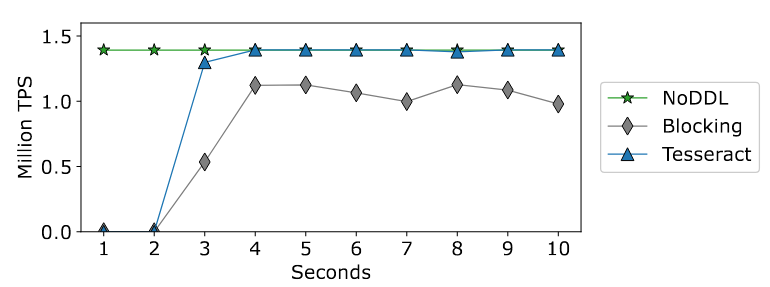
7 RELATED WORK
-
Schema Versioning and Data Migration
如果用多版本的schema,协调数据迁移是很重要的,这样旧事务和新事务可以共存,并相应地使用不同的模式版本
这篇关于【论文阅读VLDB23】Online Schema Evolution is (Almost) Free for Snapshot Databases的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)