本文主要是介绍Java正则表达式介绍和使用规则(Pattern类、Matcher类、PatternSyntaxException类),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. Java正则表达式机制说明(入门案例)
- 1.1 提取上述文本所有的英文单词
- 1.2 提取上述文本所有的数字
- 1.3 提取上述文本中所有的文本和英文单词
- 1.4 查找热搜消息
- 1.5 查找IP地址
- 2. 正则表达式介绍(regular expression,简称regex)
- 3. Java中正则表达式的语法
- 3.1 RegEx字符匹配符
- 3.1.1 RegEx字符匹配符说明
- 3.1.2 案例
- 3.2 RegEx匹配时不区分大小写
- 3.3 RegEx选择匹配符
- 3.4 限定符
- 3.4.1 限定符说明
- 3.4.2 限定符案例
- 3.4.3 Java贪婪匹配策略
- 3.4.4 非贪婪匹配实现
- 3.5 定位符
- 3.5.1 定位符介绍
- 3.5.2 定位符案例
- 3.6 分组
- 3.6.1 捕获组说明
- 4. Java正则表达式常用类
- 4.1 Pattern类
- 4.1.1 matches方法:用于整体匹配,在验证输入的字符串是否满足条件使用
- 4.2 Matcher类
- 4.2.1 索引方法
- 4.2.2 查找方法
- 4.2.3 替换方法
- 4.2.4 start 和 end 方法
- 4.2.5 matches 和 lookingAt 方法
- 4.2.6 replaceFirst 和 replaceAll 方法
- 4.3 PatternSyntaxException类
1. Java正则表达式机制说明(入门案例)
Java对正则表达式的支持是从1.4版本开始的,此前的JRE(Java RuntimeEnvironment, Java运行环境)版本不支持正则表达式。
入门实例:
假设现在有这么一段文本:
String content = "万维网WWW(World Wide Web)发源于欧洲日内瓦量子物理实验室CERN,正是WWW技术的出现使得因特网得以超乎想象的速度迅猛发展。这项基于TCP/IP的技术在短短的10年时间内迅速成为已经发展了几十年的Internet上的规模最大的信息系统,它的成功归结于它的简单、实用。在WWW的背后有一系列的协议和标准支持它完成如此宏大的工作,这就是Web协议族,其中就包括HTTP超文本传输协议。\n" +"在1990年,HTTP就成为WWW的支撑协议。当时由其创始人WWW之父蒂姆·伯纳斯·李(Tim Berners-Lee)提出,随后WWW联盟(WWW Consortium)成立,组织了IETF(Internet Engineering Task Force)小组进一步完善和发布HTTP。 \n" +"HTTP是应用层协议,同其他应用层协议一样,是为了实现某一类具体应用的协议,并由某一运行在用户空间的应用程序来实现其功能。HTTP是一种协议规范,这种规范记录在文档上,为真正通过HTTP进行通信的HTTP的实现程序。\n" +"HTTP是基于B/S架构进行通信的,而HTTP的服务器端实现程序有httpd、nginx等,其客户端的实现程序主要是Web浏览器,例如Firefox、Internet Explorer、Google Chrome、Safari、Opera等,此外,客户端的命令行工具还有elink、curl等。Web服务是基于TCP的,因此为了能够随时响应客户端的请求,Web服务器需要监听在80/TCP端口。这样客户端浏览器和Web服务器之间就可以通过HTTP进行通信了。";
1.1 提取上述文本所有的英文单词
public static void main(String[] args) {/** 1.1 先创建一个Pattern对象,模式对象(正则表达式对象)*/Pattern pattern = Pattern.compile("[a-zA-Z]+");/** 1.2 创建一个匹配器对象()* 理解:就是 matcher匹配器按照pattern(模式/样式),到 content文本中去匹配找到就返回true,否则就返回false*/Matcher matcher = pattern.matcher(content);/** 3. 开始循环匹配*/while (matcher.find()) {// 匹配内容,文本,放到 m.group(0)System.out.print(matcher.group(0) + " ");}}
运行结果:

1.2 提取上述文本所有的数字
按照上面的代码,只需要改一下正则表达式就行了。
Pattern pattern = Pattern.compile("[0-9]+");
运行结果:

1.3 提取上述文本中所有的文本和英文单词
按照上面的代码,只需要改一下正则表达式就行了。
Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-Z]+)");
运行结果:

1.4 查找热搜消息
假设现在文本的内容变为了下面这个,我们需要找到里面所有的title。
String content = " <a target=\"_blank\" title=\"热搜新闻1\" href=\"#\">热搜新闻1</a>\n" +" <a target=\"_blank\" title=\"热搜新闻2\" href=\"#\">热搜新闻1</a>\n" +" <a target=\"_blank\" title=\"热搜新闻3\" href=\"#\">热搜新闻1</a>\n" +" <a target=\"_blank\" title=\"热搜新闻4\" href=\"#\">热搜新闻1</a>";
public static void main(String[] args) {/** 1.1 先创建一个Pattern对象,模式对象(正则表达式对象)*/Pattern pattern = Pattern.compile("<a target=\"_blank\" title=\"(\\S*)\"");/** 1.2 创建一个匹配器对象()* 理解:就是 matcher匹配器按照pattern(模式/样式),到 content文本中去匹配找到就返回true,否则就返回false*/Matcher matcher = pattern.matcher(content);/** 3. 开始循环匹配*/while (matcher.find()) {// 匹配内容,文本,放到 m.group(1)System.out.print(matcher.group(1) + " ");}}
运行结果:

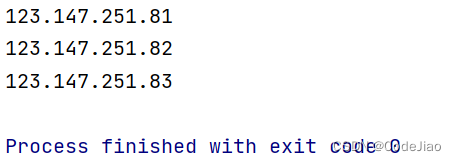
1.5 查找IP地址
假设现在文本的内容变为了下面这个,我们需要找到里面所有的IP地址。
String content = "本机IP: 123.147.251.81重庆市重庆 联通 " +"本机IP: 123.147.251.82重庆市重庆 联通 " +"本机IP: 123.147.251.83重庆市重庆 联通 ";
public static void main(String[] args) {/** 1.1 先创建一个Pattern对象,模式对象(正则表达式对象)*/Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+");/** 1.2 创建一个匹配器对象()* 理解:就是 matcher匹配器按照pattern(模式/样式),到 content文本中去匹配找到就返回true,否则就返回false*/Matcher matcher = pattern.matcher(content);/** 3. 开始循环匹配*/while (matcher.find()) {// 匹配内容,文本,放到 m.group(0)System.out.println(matcher.group(0));}}
运行结果:
2. 正则表达式介绍(regular expression,简称regex)
正则表达式(regular expression,简称regex)是文本处理方面功能最强大的工具之一,正则表达式语言用来构造正则表达式(最终构造出来的字符串就称为正则表达式),正则表达式用来完成搜索和替换操作。
3. Java中正则表达式的语法
如果要想灵活的运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为:
- 限定符
- 选择匹配符
- 分组组合符
- 反向引用符
- 特殊字符
- 字符匹配符
- 定位符
在Java的正则表达式中,两个\\代表其他语言中的一个\
示例:
public static void main(String[] args) {String content = "abc(def(g";/** 1.1 先创建一个Pattern对象,模式对象(正则表达式对象)*/Pattern pattern = Pattern.compile("\\(");/** 1.2 创建一个匹配器对象()* 理解:就是 matcher匹配器按照pattern(模式/样式),到 content文本中去匹配找到就返回true,否则就返回false*/Matcher matcher = pattern.matcher(content);/** 3. 开始循环匹配*/while (matcher.find()) {// 匹配内容,文本,放到 m.group(0)System.out.println(matcher.group(0));}}
运行结果:

3.1 RegEx字符匹配符
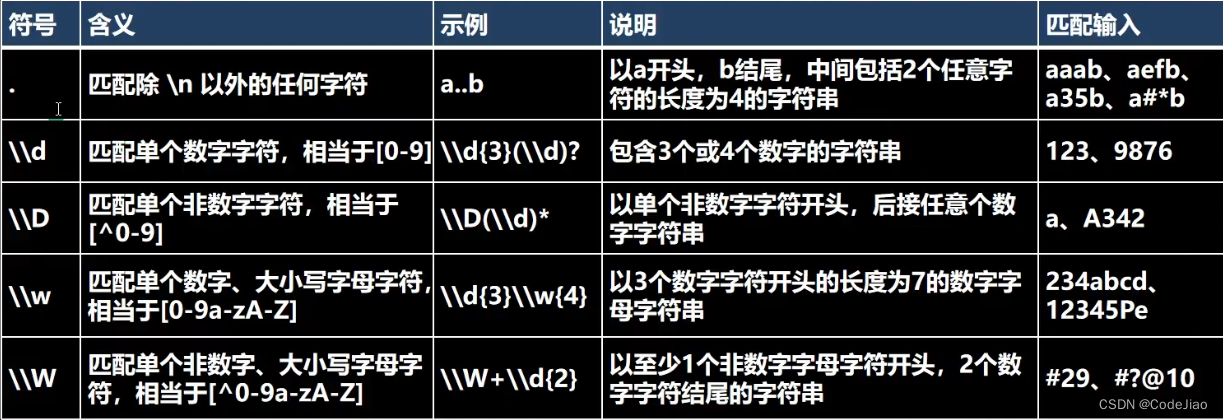
3.1.1 RegEx字符匹配符说明


3.1.2 案例
匹配a-z直接的任意一个字符:
public static void main(String[] args) {String content = "$ztj2000317LOL?";// 匹配a-z直接的任意一个字符Pattern pattern = Pattern.compile("[a-z]");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

匹配A-Z直接的任意一个字符:
public static void main(String[] args) {String content = "$ztj2000317LOL?";// 匹配A-Z直接的任意一个字符Pattern pattern = Pattern.compile("[A-Z]");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

匹配A-Z中连续的3个字符:
public static void main(String[] args) {String content = "$ztj2000317LOL?";// 匹配A-Z中连续的3个字符Pattern pattern = Pattern.compile("[A-Z]{3}");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:
匹配特殊字符:
public static void main(String[] args) {String content = "$ztj2000317LOL?";// 匹配特殊字符Pattern pattern = Pattern.compile("\\W");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

3.2 RegEx匹配时不区分大小写
Java正则表达式默认是区分字母大小写的,下面几种方式可以实现不区分大小写。
- 使用
(?i)表达式

- 在构建正则表达式的时候选择不区分大小写:
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
示例:使用
(?i)表达式
public static void main(String[] args) {String content = "CodeJiao";// 匹配CodeJiaoPattern pattern = Pattern.compile("(?i)codejiao");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group());}}
运行结果:

示例:在构建正则表达式的时候选择不区分大小写
public static void main(String[] args) {String content = "CodeJiao";// 匹配CodeJiaoPattern pattern = Pattern.compile("codejiao", Pattern.CASE_INSENSITIVE);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group());}}
运行结果:

3.3 RegEx选择匹配符

示例:匹配Code或者Jiao
public static void main(String[] args) {String content = "CodeJiaoYYDS";// 匹配Code或者JiaoPattern pattern = Pattern.compile("Code|Jiao");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

3.4 限定符
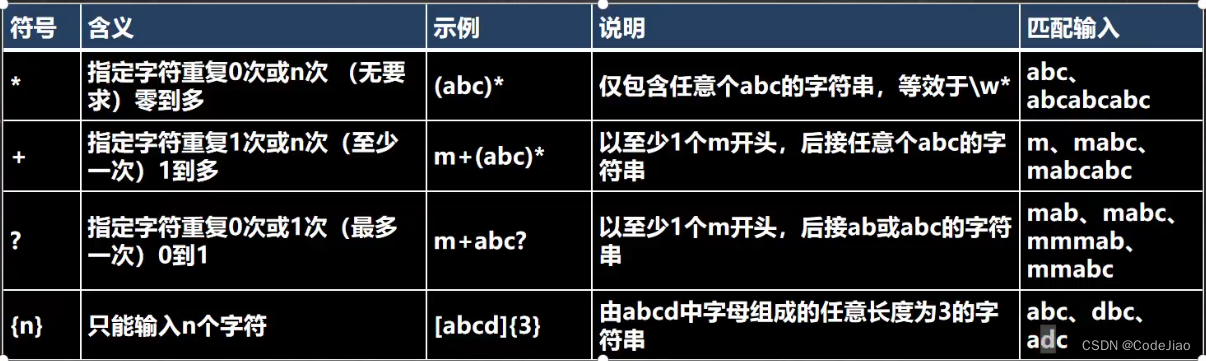
3.4.1 限定符说明
用于指定其前面的字符和组合项连续出现多少次

3.4.2 限定符案例
匹配连续的2个数字:
public static void main(String[] args) {String content = "11aaaabbccccc22";// 匹配连续的2个数字Pattern pattern = Pattern.compile("\\d{2}");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

匹配aaa
public static void main(String[] args) {String content = "11aaaabbccccc22";// 匹配aaaPattern pattern = Pattern.compile("a{3}");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

cc…
public static void main(String[] args) {String content = "11aaaabbccccc22";// 匹配cc...Pattern pattern = Pattern.compile("c{2,}");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

匹配一个及以上的1
public static void main(String[] args) {String content = "11aaaabbccccc22";// 匹配一个及以上的1Pattern pattern = Pattern.compile("1+");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

匹配0个及以上的1
public static void main(String[] args) {String content = "11aaaabbccccc22";// 匹配0个及以上的1Pattern pattern = Pattern.compile("1?");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
y
3.4.3 Java贪婪匹配策略
示例代码
public static void main(String[] args) {String content = "11aaaabbccccc22";// 匹配aaa 或者 aaaaPattern pattern = Pattern.compile("a{3,4}");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:上面的正则表达式可以匹配aaa或者aaaa,但是默认是贪婪匹配,意思是优先匹配较长元素。

3.4.4 非贪婪匹配实现
示例代码
public static void main(String[] args) {String content = "11aaaabbccccc22";// 在正则表达式后面加一个?即可实现非贪婪匹配Pattern pattern = Pattern.compile("a{3,4}");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

3.5 定位符
3.5.1 定位符介绍
定位符,规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置,这个也是相当有用的。
3.5.2 定位符案例
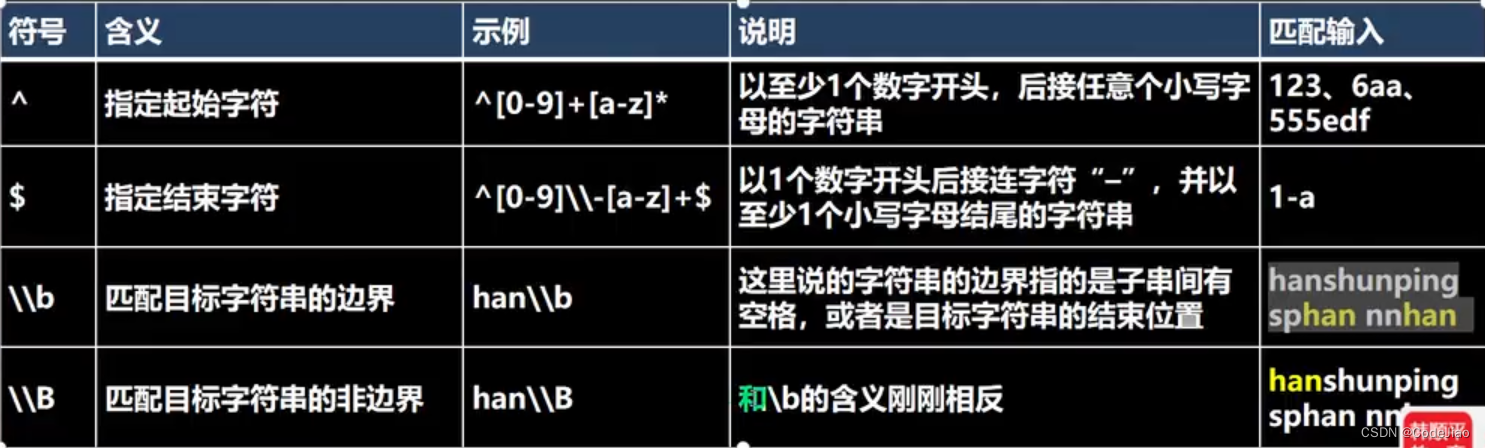
示例1:以至少1个数字开头,后接任意个小写字母的字符串。
public static void main(String[] args) {String content = "123-abc";// 以至少1个数字开头,后接任意个小写字母的字符串。Pattern pattern = Pattern.compile("^[0-9]+[a-z]*");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:
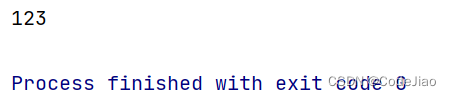
示例2:匹配边界值codejiao
public static void main(String[] args) {String content = "codejiao yyds codejiao";// 匹配边界值codejiao。Pattern pattern = Pattern.compile("codejiao\\b");Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println(matcher.group(0));}}
运行结果:

3.6 分组

示例代码:非命名捕获
public static void main(String[] args) {String content = "code1234 jiao5678 317G";// 匹配边界值以至少一个数字开头。Pattern pattern = Pattern.compile("(\\d\\d)(\\d\\d)");/** 1. matcher.group(0) 得到匹配到的字符串* 2. matcher.group(1) 得到匹配到的字符串的第1个分组内容* 3. matcher.group(2) 得到匹配到的字符串的第2个分组内容*/Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("匹配到的字符串:" + matcher.group(0));System.out.println("得到匹配到的字符串的第1个分组内容:" + matcher.group(1));System.out.println("得到匹配到的字符串的第2个分组内容:" + matcher.group(2));}}
运行结果:

示例代码:命名捕获
public static void main(String[] args) {String content = "code1234 jiao5678 317G";// 匹配边界值以至少一个数字开头。Pattern pattern = Pattern.compile("(?<group1>\\d\\d)(?<group2>\\d\\d)");/** 1. matcher.group(0) 得到匹配到的字符串* 2. matcher.group("group1") 得到匹配到的字符串的第1个分组内容* 3. matcher.group("group2") 得到匹配到的字符串的第2个分组内容*/Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("匹配到的字符串:" + matcher.group(0));// 这个也可以用用matcher.group(1)获取System.out.println("得到匹配到的字符串的第1个分组内容:" + matcher.group("group1"));// 这个也可以用用matcher.group(2)获取System.out.println("得到匹配到的字符串的第2个分组内容:" + matcher.group("group2"));}}
运行结果:

3.6.1 捕获组说明

4. Java正则表达式常用类

4.1 Pattern类
4.1.1 matches方法:用于整体匹配,在验证输入的字符串是否满足条件使用
示例代码:以下实例中使用了正则表达式 .runoob. 用于查找字符串中是否包了 runoob 子串:
public static void main(String[] args) {String content = "I am noob from runoob.com.";String pattern = ".*runoob.*";boolean isMatch = Pattern.matches(pattern, content);System.out.println("字符串中是否包含了 'runoob' 子字符串? " + isMatch);}
运行结果:

4.2 Matcher类
4.2.1 索引方法
索引方法提供了有用的索引值,精确表明输入字符串中在哪能找到匹配:
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public int start() | 返回以前匹配的初始索引。 |
| 2 | public int start(int group) | 返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引 |
| 3 | public int end() | 返回最后匹配字符之后的偏移量。 |
| 4 | public int end(int group) | 返回在以前的匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量。 |
4.2.2 查找方法
查找方法用来检查输入字符串并返回一个布尔值,表示是否找到该模式:
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public boolean lookingAt() | 尝试将从区域开头开始的输入序列与该模式匹配。 |
| 2 | public boolean find() | 尝试查找与该模式匹配的输入序列的下一个子序列。 |
| 3 | public boolean find(int start) | 重置此匹配器,然后尝试查找匹配该模式、从指定索引开始的输入序列的下一个子序列。 |
| 4 | public boolean matches() | 尝试将整个区域与模式匹配。 |
4.2.3 替换方法
替换方法是替换输入字符串里文本的方法:
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public Matcher appendReplacement(StringBuffer sb, String replacement) | 实现非终端添加和替换步骤。 |
| 2 | public StringBuffer appendTail(StringBuffer sb) | 实现终端添加和替换步骤。 |
| 3 | public String replaceAll(String replacement) | 替换模式与给定替换字符串相匹配的输入序列的每个子序列。 |
| 4 | public String replaceFirst(String replacement) | 替换模式与给定替换字符串匹配的输入序列的第一个子序列。 |
| 5 | public static String quoteReplacement(String s) | 返回指定字符串的字面替换字符串。这个方法返回一个字符串,就像传递给Matcher类的appendReplacement 方法一个字面字符串一样工作。 |
4.2.4 start 和 end 方法
下面是一个对单词 “cat” 出现在输入字符串中出现次数进行计数的例子:
public class Test {private static final String REGEX = "\\bcat\\b";private static final String INPUT = "cat cat cat cattie cat";public static void main(String[] args) {Pattern p = Pattern.compile(REGEX);Matcher m = p.matcher(INPUT); // 获取 matcher 对象int count = 0;while (m.find()) {count++;System.out.println("Match number " + count);System.out.println("start(): " + m.start());System.out.println("end(): " + m.end());}}
}
运行结果:

4.2.5 matches 和 lookingAt 方法
matches 和 lookingAt 方法都用来尝试匹配一个输入序列模式。它们的不同是 matches 要求整个序列都匹配,而lookingAt 不要求。
lookingAt 方法虽然不需要整句都匹配,但是需要从第一个字符开始匹配。
这两个方法经常在输入字符串的开始使用。
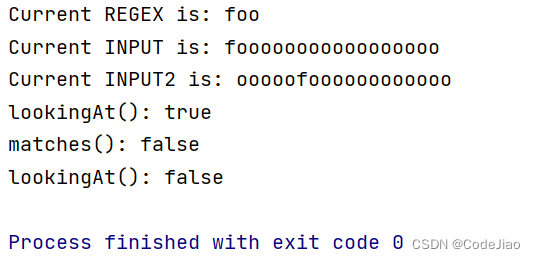
我们通过下面这个例子,来解释这个功能:
public class Test {private static final String REGEX = "foo";private static final String INPUT = "fooooooooooooooooo";private static final String INPUT2 = "ooooofoooooooooooo";private static Pattern pattern;private static Matcher matcher;private static Matcher matcher2;public static void main(String[] args) {pattern = Pattern.compile(REGEX);matcher = pattern.matcher(INPUT);matcher2 = pattern.matcher(INPUT2);System.out.println("Current REGEX is: " + REGEX);System.out.println("Current INPUT is: " + INPUT);System.out.println("Current INPUT2 is: " + INPUT2);System.out.println("lookingAt(): " + matcher.lookingAt());System.out.println("matches(): " + matcher.matches());System.out.println("lookingAt(): " + matcher2.lookingAt());}
}
运行结果:
4.2.6 replaceFirst 和 replaceAll 方法
replaceFirst 和 replaceAll 方法用来替换匹配正则表达式的文本。不同的是,replaceFirst 替换首次匹配,replaceAll 替换所有匹配。
下面的例子来解释这个功能:
public class Test {private static String REGEX = "dog";private static String INPUT = "The dog says meow. All dogs say meow.";private static String REPLACE = "cat";public static void main(String[] args) {Pattern p = Pattern.compile(REGEX);Matcher m = p.matcher(INPUT);INPUT = m.replaceAll(REPLACE);System.out.println(INPUT);}
}
运行结果:

4.3 PatternSyntaxException类
PatternSyntaxException 是一个非强制异常类,它指示一个正则表达式模式中的语法错误。
PatternSyntaxException 类提供了下面的方法来帮助我们查看发生了什么错误。
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public String getDescription() | 获取错误的描述。 |
| 2 | public int getIndex() | 获取错误的索引。 |
| 3 | public String getPattern() | 获取错误的正则表达式模式。 |
| 4 | public String getMessage() | 返回多行字符串,包含语法错误及其索引的描述、错误的正则表达式模式和模式中错误索引的可视化指示。 |
这篇关于Java正则表达式介绍和使用规则(Pattern类、Matcher类、PatternSyntaxException类)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






