本文主要是介绍dataphin时间参数配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
节点参数配置说明
参数配置是用以支持代码中所用参数具体做参数值赋值,类似全局变量作用,从而支持节点调度时,参数可以自动被替换执行。
Dataphin调度系统(Voldemort)节点配置的原则
节点代码中引用参数的方式为: n o d e P a r a m 节 点 参 数 配 置 的 格 式 为 K e y A = V a l u e A ; K e y B = V a l u e B , 不 同 参 数 配 置 之 间 的 用 分 号 ; 进 行 分 隔 节 点 的 K e y 不 区 分 大 小 写 , 因 此 K e y A = V a l u e A 和 k e y a = V a l u e A 是 一 样 的 , 在 引 用 配 置 参 数 的 时 候 , 也 不 会 区 分 大 小 写 , 因 此 在 引 用 配 置 参 数 的 时 候 , 可 以 使 用 {nodeParam} 节点参数配置的格式为 KeyA=ValueA; KeyB=ValueB, 不同参数配置之间的用分号;进行分隔 节点的Key不区分大小写, 因此KeyA=ValueA和keya=ValueA是一样的, 在引用配置参数的时候, 也不会区分大小写, 因此在引用配置参数的时候, 可以使用 nodeParam节点参数配置的格式为KeyA=ValueA;KeyB=ValueB,不同参数配置之间的用分号;进行分隔节点的Key不区分大小写,因此KeyA=ValueA和keya=ValueA是一样的,在引用配置参数的时候,也不会区分大小写,因此在引用配置参数的时候,可以使用{KeyA}或 k e y a 或 {keya}或 keya或{keyA}都是可以的.
节点配置支持参数的引用, 引用格式为 KeyA= K e y B ; K e y B = V a l u e B , 使 用 引 用 符 号 KeyB; KeyB=ValueB, 使用引用符号 KeyB;KeyB=ValueB,使用引用符号, 则此时相当于KeyA=ValueB; KeyB=ValueB. 但是这里必须注意, Voldemort会进行循环引用的检测, 因此KeyA= K e y B ; K e y B = KeyB; KeyB= KeyB;KeyB=KeyA或者bizdate=$bizdate这种参数配置在Voldemort中是非法的.
伏地魔提供默认的节点参数配置项, 包括:
默认参数值:{yyyyMMdd}为业务日期,即当前日期的前一天T-1,[yyyyMMdd]为执行日期,即当前日期T
默认参数:bizdate,nodeid,taskid,生产业务板块名和生产项目名.其中 nodeid是节点id, taskid是节点生成实例时候的实例id, bizdate默认为当前日期的前一天,即参数默认参数值赋值为{yyyyMMdd},eg:如果今天是2018年1月10日, 则默认bizdate=20180109,生产业务板块名为当前系统所有生产业务板块名,开发环境执行时替换为开发板块名,生产环境执行时替换为生产板块名,eg:如果系统有Dev-Prod模式生成的生产业务板块为是LD_demo, 则默认生产环境里 L D d e m o 执 行 代 码 时 更 新 为 L D d e m o , 开 发 环 境 里 {LD_demo}执行代码时更新为LD_demo,开发环境里 LDdemo执行代码时更新为LDdemo,开发环境里{LD_demo}执行代码时更新为LD_demo_dev。 默认参数bizdate的设置及执行效果
可以在节点代码中直接引用这些参数配置项。①支持代码中自定义参数,引用默认参数值,如time= t o d a y , 调 度 参 数 配 置 为 t o d a y = {today},调度参数配置为 today= today,调度参数配置为today=[yyyyMMdd],则2019年2月28日调度执行时,执行代码为time=20190228. ②如果用户配置的参数和默认参数有重复冲突, 则用户配置的参数赋值会覆盖默认规则. 例如配置了bizdate=ABC, 则在节点代码中引用bizdate时, 该bizdate的值会被替换为ABC,而不是具体日期参数值yyyymmdd。 默认参数bizdate配置为其他参数值的设置及执行效果
即席查询支持参数识别与设置,但是与调度系统规则有所不同,{bizdate}执行时,系统会识别并默认填入执行日期为默认值(2019年2月28日查询执行时,执行代码为替换为20190228),其他参数不会填入默认值,系统会记住当前界面会话下,用户最新填入的参数值,会话有效期内,执行时默认填入最新参数值。
Dataphin调度系统(Voldemort)时间参数的配置
日调度等:提供基于业务日期和预计执行时间两种方式, 基于业务日期的方式: ${yyyyMMdd}; 基于预计执行时间的方式: [ y y y y M M d d ] 。 可 参 考 示 例 配 置 , 实 现 月 调 度 、 年 调 度 小 时 、 分 钟 调 度 : 提 供 基 于 小 时 和 分 钟 偏 移 , 而 实 现 的 小 时 调 度 、 分 钟 调 度 , 暂 不 支 持 秒 。 H H 表 示 小 时 , m i ( 或 m m ) 表 示 分 钟 , s s 表 示 秒 , 小 时 的 偏 移 : d e l t a / 24 , 分 钟 的 偏 移 : d e l t a / 24 / 60 。 例 如 在 指 定 执 行 时 间 前 一 小 时 的 表 达 式 为 : [yyyyMMdd]。可参考示例配置,实现月调度、年调度 小时、分钟调度:提供基于小时和分钟偏移,而实现的小时调度、分钟调度,暂不支持秒。HH表示小时,mi(或mm)表示分钟,ss表示秒,小时的偏移: delta/24, 分钟的偏移: delta/24/60。 例如在指定执行时间前一小时的表达式为: [yyyyMMdd]。可参考示例配置,实现月调度、年调度小时、分钟调度:提供基于小时和分钟偏移,而实现的小时调度、分钟调度,暂不支持秒。HH表示小时,mi(或mm)表示分钟,ss表示秒,小时的偏移:delta/24,分钟的偏移:delta/24/60。例如在指定执行时间前一小时的表达式为:[HH-1/24], 在业务日期前1分钟:${HHmmss-1/24/60}
特别说明:如果配置的时间参数只精确到日, 那么小写的mm会被识别为月份。当同时有月和分钟存在的时候, 为了避免歧义, 需要将月大写为MM, 将分钟小写为mm,否则会统一识别为分钟,从而导致月份参数出错(比如更新为大于12的数值)
具体的配置可以参考下面的表格
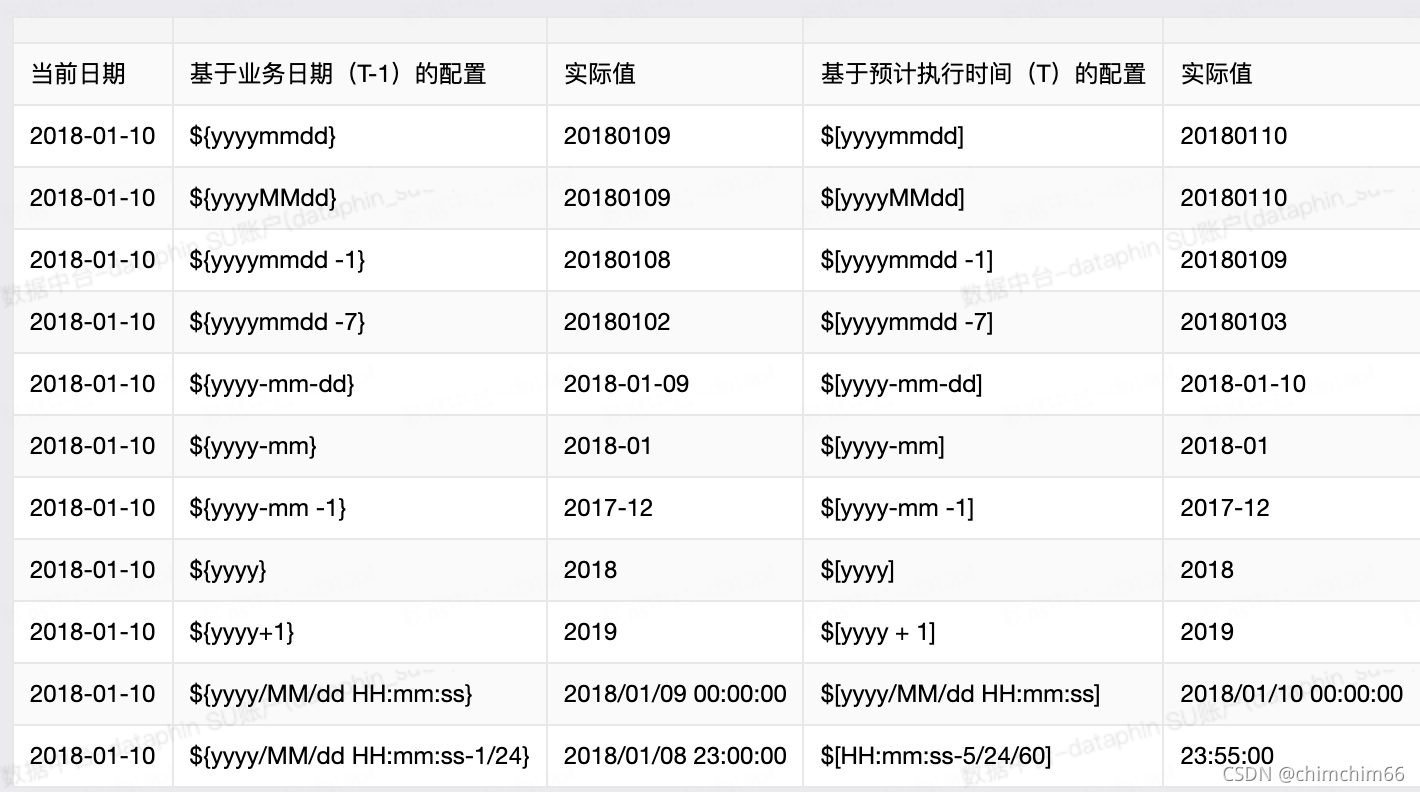
特别说明:
周期实例: 系统时间=T(取生成实例的时间) bizdate=T-1(根据系统时间获取默认取值,调度配置参数取值可修改)→影响数据读写的时间分区值 预计执行时间=bizdate+1=T(根据bizdate获取)→影响数据生成时间
补数据实例: 系统时间=T(取生成实例的时间) Bizdate<=T(补数据时传入值)→影响数据读写的时间分区值 预计执行时间=Bizdate+1 →影响数据生成时间 ①如Bizdate+1<=T,取Bizdate+1 ②如bizdate+1>T,特殊处理为T 执行时,会根据调度配置时实例预计执行小时运行(如调度配置设置了定时以及分时段运行等)
这篇关于dataphin时间参数配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








