本文主要是介绍基于CycleGAN的图像季节转换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(1) 季节转换图像数据集简介
下载地址: https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/, 或者 https://www.kaggle.com/datasets/balraj98/summer2winter-yosemite
注意:Kaggle中提供了一些代码案例,keras官网也提供了代码案例,可供参考。

(2) CycleGAN模型简介
Cycle-GAN是一个2017年推出的直击产业痛点的模型。众所周知,在一系列视觉问题上是很难以找到匹配的高质量图像作为target来供模型学习的,比如在超分辨领域内对于一个低分辨率的物体图像,未必能找到同样场景的高分辨率图像,这使得一系列深度学习模型的适应性有限。上述的困难总结起来就是:由于模型训练时必须依赖匹配的图像,而除非有目的的去产生这样的图像否则无法训练,并且很容易造成数据有偏。
Cycle-GAN训练的目的则避开了上述困难;该模型的思路是旨在形成一个由数据域A到数据域B的普适性映射,学习的目标是数据域A和B的风格之间的变换而非具体的数据a和b之间的一一映射关系。从这样的思路出发Cycle-GAN对于数据一一匹配的依赖性就不存在了,可以解决一系列问题,因此该模型的设计思路与具体做法十分值得学习。
循环生成对抗网络是一种无监督生成对抗网络,它的主要想法是训练两对生成器-判别器模型以将图像从一个领域转换为另一个领域,在这过程中我们要求循环一致性。即在序列地应用生成器后,我们应该得到一个相似于原始 L1 损失的图像。因此我们需要一个循环损失函数(cyclic loss),它能确保生成器不会将一个领域的图像转换到另一个和原始图像完全不相关的领域。
并且,CycleGAN本质上是两个镜像对称的GAN,构成了一个环形网络。
两个GAN共享两个生成器,并各自带一个判别器,即共有两个判别器和两个生成器。一个单向GAN两个loss,两个即共四个loss。
该模型包含两个映射函数 G : X —> Y 和 F : Y —> X,以及相关的对抗式鉴别器 DY 和 DX。DY 鼓励 G 将 X 翻译为 Y 风格的图像,反之亦然。为了进一步规范映射,研究者引入了两个「循环协调损失函数」,确保转换后的风格在反转换后可以回到处理之前的状态,如下图所示:
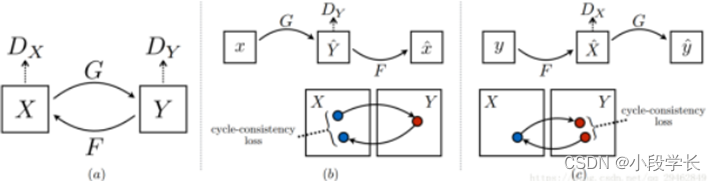
总的来说,基于Cycle-GAN的模型具有较强的适应性,能够适应一系列的视觉问题场合,比如超分辨,风格变换,图像增强等等场合。
(1) 季节转换图像数据的读取
import time
from options.train_options import TrainOptions
from data import create_dataset
from models import create_model
from util.visualizer import Visualizerif __name__ == '__main__':opt = TrainOptions().parse() # get training optionsdataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other optionsdataset_size = len(dataset) # get the number of images in the dataset.print('The number of training images = %d' % dataset_size)model = create_model(opt) # create a model given opt.model and other optionsmodel.setup(opt) # regular setup: load and print networks; create schedulersvisualizer = Visualizer(opt) # create a visualizer that displayve images and plotstotal_iters = 0 # the total number of training iterationsfor epoch in range(opt.epoch_count, opt.niter + opt.niter_decay + 1): # outer loop for different epochs; we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>epoch_start_time = time.time() # timer for entire epochiter_data_time = time.time() # timer for data loading per iterationepoch_iter = 0 # the number of training iterations in current epoch, reset to 0 every epochfor i, data in enumerate(dataset): # inner loop within one epochiter_start_time = time.time() # timer for computation per iterationif total_iters % opt.print_freq == 0:t_data = iter_start_time - iter_data_timevisualizer.reset()total_iters += opt.batch_sizeepoch_iter += opt.batch_sizemodel.set_input(data) # unpack data from dataset and apply preprocessingmodel.optimize_parameters() # calculate loss functions, get gradients, update network weightsif total_iters % opt.display_freq == 0: # display images on visdom and save images to a HTML filesave_result = total_iters % opt.update_html_freq == 0model.compute_visuals()visualizer.display_current_results(model.get_current_visuals(), epoch, save_result)if total_iters % opt.print_freq == 0: # print training losses and save logging information to the disklosses = model.get_current_losses()t_comp = (time.time() - iter_start_time) / opt.batch_sizevisualizer.print_current_losses(epoch, epoch_iter, losses, t_comp, t_data)if opt.display_id > 0:visualizer.plot_current_losses(epoch, float(epoch_iter) / dataset_size, losses)if total_iters % opt.save_latest_freq == 0: # cache our latest model every <save_latest_freq> iterationsprint('saving the latest model (epoch %d, total_iters %d)' % (epoch, total_iters))save_suffix = 'iter_%d' % total_iters if opt.save_by_iter else 'latest'model.save_networks(save_suffix)iter_data_time = time.time()if epoch % opt.save_epoch_freq == 0: # cache our model every <save_epoch_freq> epochsprint('saving the model at the end of epoch %d, iters %d' % (epoch, total_iters))model.save_networks('latest')model.save_networks(epoch)print('End of epoch %d / %d \t Time Taken: %d sec' % (epoch, opt.niter + opt.niter_decay, time.time() - epoch_start_time))model.update_learning_rate()
(2) 基于CycleGAN模型的图像季节转换
import os
from options.test_options import TestOptions
from data import create_dataset
from models import create_model
from util.visualizer import save_images
from util import htmlif __name__ == '__main__':opt = TestOptions().parse() # get test options# hard-code some parameters for testopt.num_threads = 0 # test code only supports num_threads = 1opt.batch_size = 1 # test code only supports batch_size = 1opt.serial_batches = True # disable data shuffling; comment this line if results on randomly chosen images are needed.opt.no_flip = True # no flip; comment this line if results on flipped images are needed.opt.display_id = -1 # no visdom display; the test code saves the results to a HTML file.dataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other optionsmodel = create_model(opt) # create a model given opt.model and other optionsmodel.setup(opt) # regular setup: load and print networks; create schedulers
# create a websiteweb_dir = os.path.join(opt.results_dir, opt.name, '%s_%s' % (opt.phase, opt.epoch)) # define the website directorywebpage = html.HTML(web_dir, 'Experiment = %s, Phase = %s, Epoch = %s' % (opt.name, opt.phase, opt.epoch))# test with eval mode. This only affects layers like batchnorm and dropout.# For [pix2pix]: we use batchnorm and dropout in the original pix2pix. You can experiment it with and without eval() mode.# For [CycleGAN]: It should not affect CycleGAN as CycleGAN uses instancenorm without dropoutif opt.eval:model.eval()for i, data in enumerate(dataset):if i >= opt.num_test: # only apply our model to opt.num_test images.breakmodel.set_input(data) # unpack data from data loadermodel.test() # run inferencevisuals = model.get_current_visuals() # get image resultsimg_path = model.get_image_paths() # get image pathsif i % 5 == 0: # save images to an HTML fileprint('processing (%04d)-th image... %s' % (i, img_path))save_images(webpage, visuals, img_path, aspect_ratio=opt.aspect_ratio, width=opt.display_winsize)webpage.save()
结果与对比分析
结果
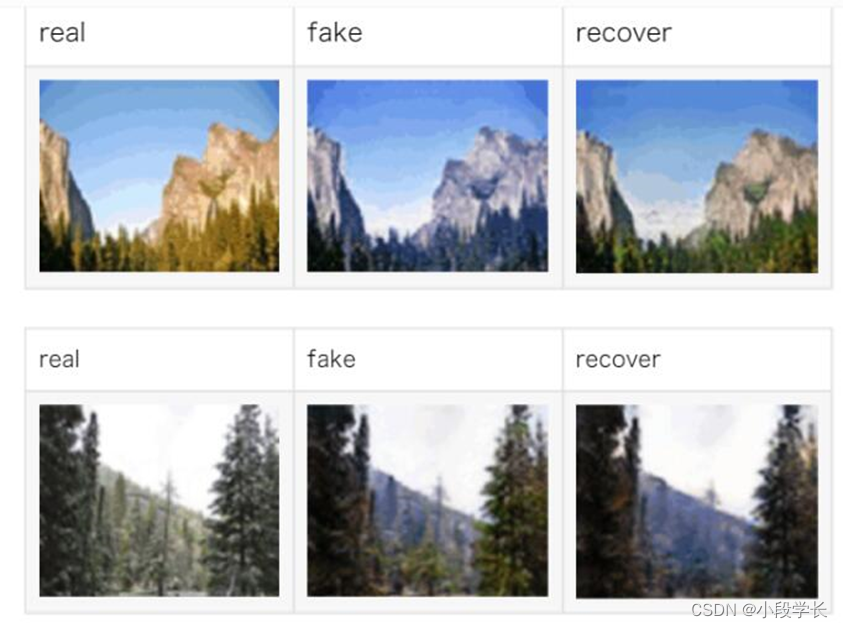


季节转换指将在某一季节拍摄的照片转换为另一个季节的照片,例如将夏季的照片转换为冬季。在下面的示例中, CycleGAN 实现了冬天和夏天拍摄的风景照之间的相互转换。
对于 Unpaired 问题来说,只是用普通 GAN 的话可以学到的模型有很多种。种类数目为领域 X 和领域 Y 之间的随机映射数目,所以只是用普通 GAN 损失函数无法保证输入 x 能够得到对应领域的 y。而 Cycle 一致性的出现,降低了随机映射的数目,从而保证得到的输出不再是随机的,因此能够实现图片从一个领域到另一个领域的转换。
出现的问题及解决方法
出现的问题:
1.数据集下载慢;
2.代码运行不出来;
3.关于实验结果的分析难以得出;
解决办法:
1.更换网络重新下载;
2.查错,修改代码重新运行;
3.多次对比实验结果进行分析。
结果分析与体会
对于 Unpaired 问题来说,只是用普通 GAN 的话可以学到的模型有很多种。种类数目为领域 X 和领域 Y 之间的随机映射数目,所以只是用普通 GAN 损失函数无法保证输入 x 能够得到对应领域的 y。而 Cycle 一致性的出现,降低了随机映射的数目,从而保证得到的输出不再是随机的,因此能够实现图片从一个领域到另一个领域的转换。
循环生成对抗网络是一种无监督生成对抗网络,它的主要想法是训练两对生成器-判别器模型以将图像从一个领域转换为另一个领域,在这过程中我们要求循环一致性。即在序列地应用生成器后,我们应该得到一个相似于原始 L1 损失的图像。因此我们需要一个循环损失函数(cyclic loss),它能确保生成器不会将一个领域的图像转换到另一个和原始图像完全不相关的领域。
并且,CycleGAN本质上是两个镜像对称的GAN,构成了一个环形网络。
两个GAN共享两个生成器,并各自带一个判别器,即共有两个判别器和两个生成器。一个单向GAN两个loss,两个即共四个loss。
其实在CycleGAN之前,就已经有了Domain Adaptation模型,比如Pix2Pix,不过Pix2Pix要求训练数据必须是成对的,而现实生活中,要找到两个域(画风)中成对出现的图片是相当困难的,因此CycleGAN诞生了,它只需要两种域的数据,而不需要他们有严格对应关系,这使得CycleGAN的应用更为广泛。
Cycle-GAN训练的目的则避开了上述困难;该模型的思路是旨在形成一个由数据域A到数据域B的普适性映射,学习的目标是数据域A和B的风格之间的变换而非具体的数据a和b之间的一一映射关系。从这样的思路出发Cycle-GAN对于数据一一匹配的依赖性就不存在了,可以解决一系列问题,因此该模型的设计思路与具体做法十分值得学习。
cycleGAN是一种由Generative Adversarial Networks发展而来的一种无监督机器学习,是在pix2pix的基础上发展起来的,主要应用于非配对图片的图像生成和转换,可以实现风格的转换,比如把照片转换为油画风格,或者把照片的橘子转换为苹果、马与斑马之间的转换等。因为不需要成对的数据集就能够转换,所以在数据准备上会简单很多,十分具有应用前景。
参考文献:
[1] https://keras.io/examples/generative/cyclegan/
[2] https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/
[3] https://www.kaggle.com/datasets/balraj98/summer2winter-yosemite
[4] https://junyanz.github.io/CycleGAN/
[5] https://zhuanlan.zhihu.com/p/44181821
欢迎大家加我微信交流讨论(请备注csdn上添加)

这篇关于基于CycleGAN的图像季节转换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




