本文主要是介绍用户行为价值购买率预测——二分类问题(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
作者此次参加了全国大学生数据分析与统计比赛,选择的是此次B题目:用户消费行为价值分析以及预测用户购买率。在此想记录一下此次比赛所做项目的整个过程。
比赛任务:
任务 1:获取数据并进行预处理,提高数据质量;
任务 2:对用户的各城市分布情况、登录情况进行分析,并分别
将结果进行多种形式的可视化展现;
任务 3:构建模型判断用户最终是否会下单购买或下单购买的概
率,并将模型结果输出为 csv 文件(参照结果输出样例
sample_output.csv)。要求模型的效果达到 85%以上;
任务 4:通过用户消费行为价值分析,给企业提出合理的建议。
**
正文:
本次我所用的学习框架是tensorflow,工具是anaconda中的jupyter notebook,环境是base。
首先导入一些基本的包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
如果遇到运行时no model .(包名)…错误的话,请打开anaconda prompt,切换到你正在使用的环境,如我正在使用的是base,在命令行中输入acttvate base,再输入命令行,conda install XX(你所缺失的包)
接着读取数据集:
train1=pd.read_csv('C:/Users/admin/Desktop/datafc/sampleB/data/user_info.csv')
train3=pd.read_csv('C:/Users/admin/Desktop/datafc/sampleB/data/visit_info.csv')
train2=pd.read_csv('C:/Users/admin/Desktop/datafc/sampleB/data/login_day.csv')
train4=pd.read_csv('C:/Users/admin/Desktop/datafc/sampleB/data/result.csv')
查看数据集的字段属性和前五个数据:
train1.head()
train2.head()
train3.head()
train4.head()
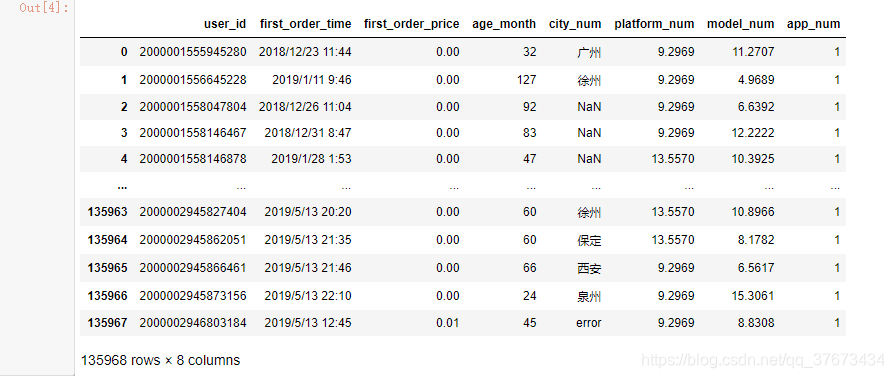
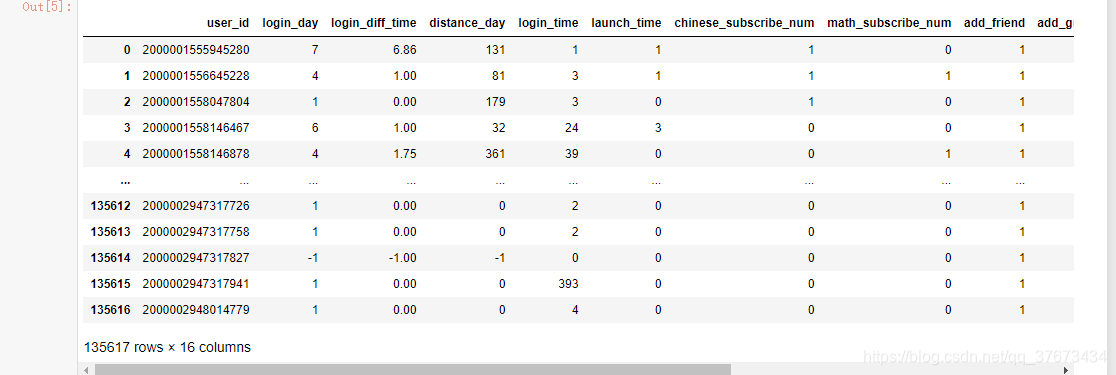
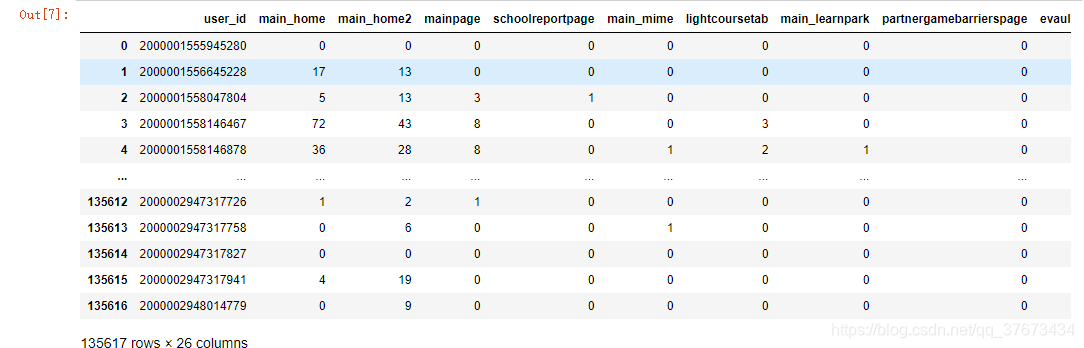
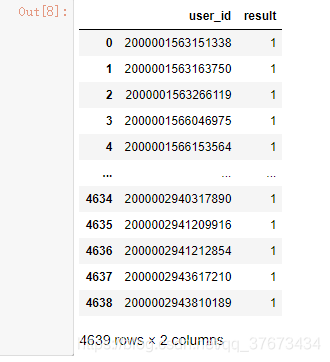
通过简单的观察可以看出,train1数据集和train2,train3数据集是有关联的,但比较维度发现,train1数据集多出来351条数据。train4则是一些购买了该产品的用户,只有4639人。没有给出测试数据集。
进一步分析数据:
train1.city_num.describe()
train1.info()

注意到train1中city_num字段存在空值:
train1.isnull().sum()#查看是否有空值
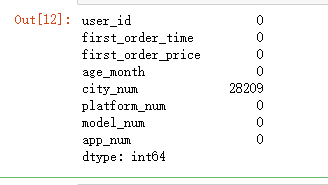
对空值进行处理:
train1['city_num']=train1['city_num'].replace('error','')
train1=train1.fillna(method="ffill",axis=0)#邻近填充法
接下来的是将这四个数据集进行合并,通过user_id来对应,并将train1中多出的无效数据进行删除,对train2和train3,train4中重复的user_id删除,首先将train1中多余数据进行删除:
train1_d=train1.drop(labels=range(135617,135967),axis=0)#对于多出来的数据进行删除法
train1_d=train1_d.drop(labels=135967,axis=0)
对train2和train3,train4中重复的user_id删除:
train2_d=train2.drop(labels='user_id',axis=1)
train3_d=train3.drop(labels='user_id',axis=1)
合并三个数据集:
train=pd.concat([train1_d,train2_d,train3_d],axis=1)#合并三个数据集
与train4结果集进行合并,注意这里要对应user_id 进行合并:
train_con=pd.merge(train,train4,on='user_id',how='outer')#与结果集合并 使用并集
train_con=train_con.fillna(value=0)#将非购买用户标出,这样result就会为0和1
train_con.describe()#查看数据集
观察到app_num字段下的值全为1 可做降维处理:
train_con.drop('app_num',axis=1, inplace=True)#降维处理
数据可视化分析:
可视化已购买用户和非购买用户,对比两类用户的占比量,判断平衡性;
plt.rc('font', family='SimHei', size=13)
fig = plt.figure()
plt.pie(train_con['result'].value_counts(),labels=train_con['result'].value_counts().index,autopct='%1.2f%%',counterclock = False)
plt.title('购买率')
plt.show()
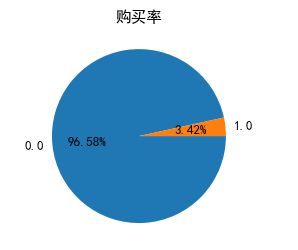
可以看出,这是一个不平衡数据集。
连续值可视化分析:
age_mouth:用户年龄,以月为单位:
plt.figure()
sns.boxenplot(x='result', y=u'age_month', data=train_con)
plt.show()#结果发现age_month里有异常值
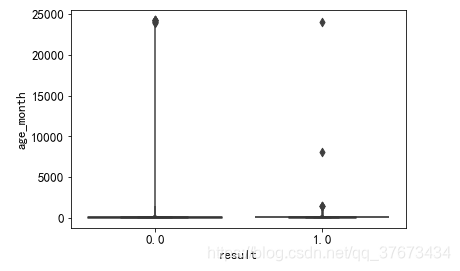
使用分位数及算法对异常值进行处理:
# 异常值处理 分位数计算法
def outlier_processing(dfx):df = dfx.copy()q1 = df.quantile(q=0.25)q3 = df.quantile(q=0.75)iqr = q3 - q1Umin = q1 - 1.5*iqrUmax = q3 + 1.5*iqr df[df>Umax] = df[df<=Umax].max()df[df<Umin] = df[df>=Umin].min()return df
train_con['age_month']=outlier_processing(train_con['age_month'])#处理异常值
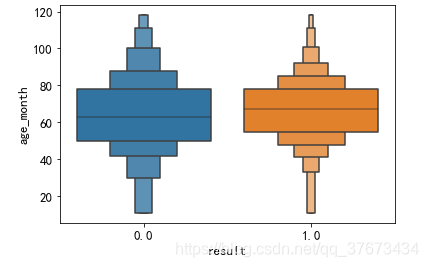
plt.figure()#重画age_month的分布图
sns.boxenplot(x='result', y=u'age_month', data=train_con)
plt.show()
train_con[train_con['result']==0]['age_month'].plot(kind='kde',label='0')#两类用户年龄的曲线图
train_con[train_con['result']==1]['age_month'].plot(kind='kde',label='1')
plt.legend()
plt.show()
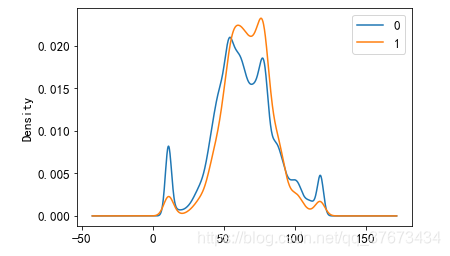
结论:两类客户的购买年龄分布差异不大。
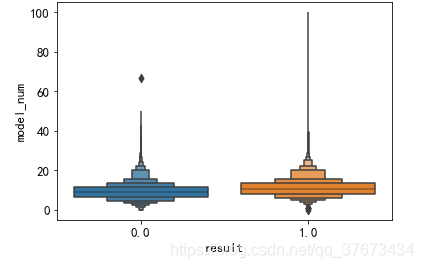
查看两类用户使用的手机型号分布:
plt.figure()#查看手机型号的分布图
sns.boxenplot(x='result', y=u'model_num', data=train_con)
plt.show()
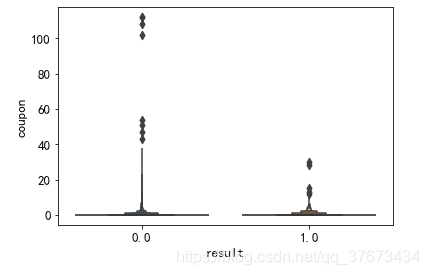
plt.figure()#查看两类客户优惠券的分布图
sns.boxenplot(x='result', y=u'coupon', data=train_con)
plt.show()
plt.figure()#查看两类客户登录天数的分布图
sns.boxenplot(x='result', y=u'login_day', data=train_con)
plt.show()
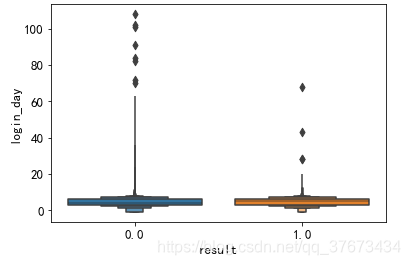
登录天数发现有负值情况 登录天数不应该有负值 属于异常值 所以进行处理:
train_con.login_day.describe()
train_con['login_day']=train_con['login_day'].replace(-1,train_con['login_day'].mean())#用平均值代替异常值
重绘两类用户登录天数的对比图:
train_con[train_con['result']==0]['login_day'].plot(kind='kde',label='0')
train_con[train_con['result']==1]['login_day'].plot(kind='kde',label='1')
plt.legend()
plt.show()#
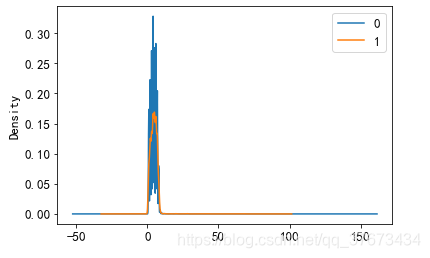
结论登录天数对购买率的影响也不大。
plt.figure()#查看两类客户登录间隔时间的分布图
sns.boxenplot(x='result', y=u'login_diff_time', data=train_con)
plt.show()
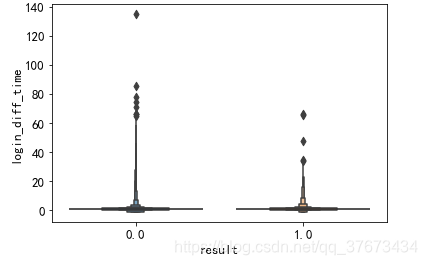
train_con.login_diff_time.describe()#发现有负值

train_con['login_diff_time']=train_con['login_diff_time'].replace(-1,train_con['login_diff_time'].mean())#用平均值代替异常值
重绘对比图:
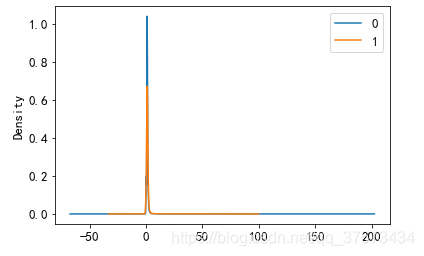
train_con[train_con['result']==0]['login_diff_time'].plot(kind='kde',label='0')
train_con[train_con['result']==1]['login_diff_time'].plot(kind='kde',label='1')
plt.legend()
plt.show()#结论 登录间隔时间对购买率的影响也不大
查看最后登录距期末时长字段:
train_con.distance_day.describe()
plt.figure()#最后登录距期末时长
sns.boxplot(y=u'distance_day', data=train_con)
plt.show()
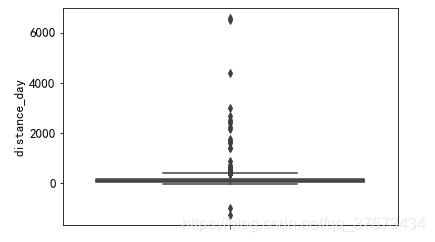

发现异常值:
train_con['distance_day']=train_con['distance_day'].replace(-1,train_con['distance_day'].mean())#用平均值代替异常值
for col in train_con.distance_day:if col < 0:train_con['distance_day']=train_con['distance_day'].replace(col,train_con['distance_day'].mean())#用平均值代替异常值
由于篇幅限制,连续型数据我只挑出需要处理和比较特殊的数据放上来,其他的连续型数据处理方式相差不大。
特征工程:
str_features = []#特征提取
num_features=[]
for col in train_con.columns:if train_con[col].dtype=='object':str_features.append(col)print(col,': ',train_con[col].unique())if train_con[col].dtype=='int64' and col not in ['user_id']:num_features.append(col)
print(str_features)
print(num_features)
分离出连续值和离散值:

接下来就是对离散值中的城市分布进行可视化分析,由于用户分布的城市非常之多,如果像先前那样画柱状图或曲线图来统计那是不现实的,实现出来的结果也无法进行分析,所以在此使用中国地图的形式,将属于各个城市的用户映射到对应的地图上中,这样能更直观地看出用户的分布情况。
首先导入相关的包:
import pyecharts #处理离散值 city用户城市分布图
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.charts import BMap#百度地图包
from pyecharts.globals import ThemeType#地图主题包
PS:第一次导入请在prompt中用conda install XX(包名)命令进行下载安装。
读取之前爬取的城市所属省份和城市出现频率的数据集,如没看过的请点击这里跳转:调用百度API正逆向地理编码——获取城市信息
fre_pro=pd.read_csv('./testcsv.csv')
pro2_name=list(fre_pro.province)
fren_pro=list(fre_pro.data)
list=[list(z)for z in zip(pro2_name,fren_pro)]
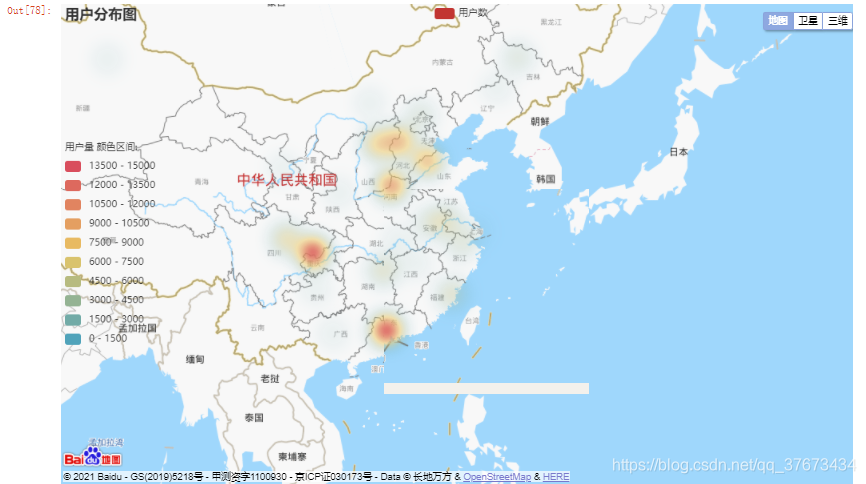
调用百度地图API进行用户城市分布可视化分析(热力图模式):
c = (#调用百度地图实现用户城市分布可视化BMap(init_opts=opts.InitOpts(width="1000px", height="600px")).add_schema(baidu_ak="PhNKW8XumikwS5TErRgDiLsPWOuTkjTU", center=[120.13066322374, 30.240018034923]).add("用户数",list,type_="heatmap", #scatter为散点图,heatmap为热力图,ChartType.EFFECT_SCATTER为涟漪图label_opts=opts.LabelOpts(formatter="{b}")).set_global_opts(title_opts=opts.TitleOpts(title="用户分布图"), visualmap_opts=opts.VisualMapOpts(min_=0,max_=15000,range_text = ['用户量 颜色区间:', ''], #分区间is_piecewise=True, #定义图例为分段型,默认为连续的图例pos_top= "middle", #分段位置pos_left="left",orient="vertical",split_number=10 #分成10个区间)).render_notebook())
c
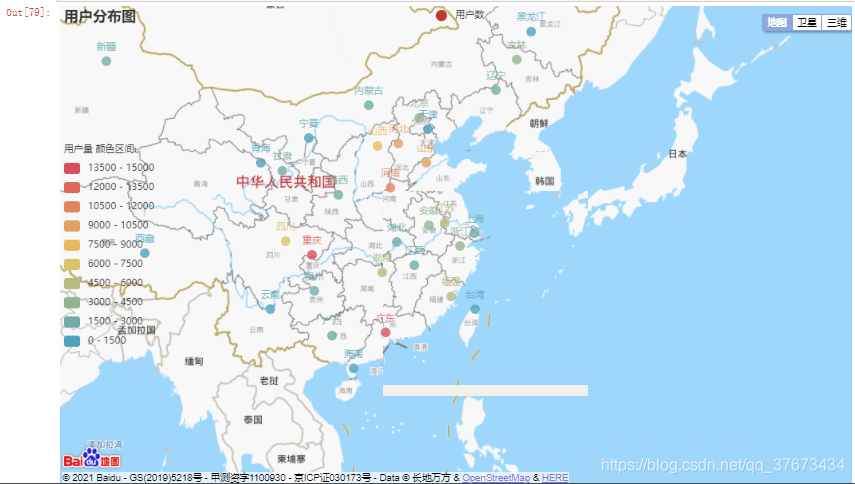
c3 = (#调用百度地图实现用户城市分布可视化,散点图BMap(init_opts=opts.InitOpts(width="1000px", height="600px")).add_schema(baidu_ak="PhNKW8XumikwS5TErRgDiLsPWOuTkjTU", center=[120.13066322374, 30.240018034923]).add("用户数",list,type_="scatter", #scatter为散点图,heatmap为热力图,ChartType.EFFECT_SCATTER为涟漪图label_opts=opts.LabelOpts(formatter="{b}")).set_global_opts(title_opts=opts.TitleOpts(title="用户分布图"), visualmap_opts=opts.VisualMapOpts(min_=0,max_=15000,range_text = ['用户量 颜色区间:', ''], #分区间is_piecewise=True, #定义图例为分段型,默认为连续的图例pos_top= "middle", #分段位置pos_left="left",orient="vertical",split_number=10 #分成10个区间)).render_notebook())
c3
pycharts自带的map:
c2 = (#调用pycharts中自带的map地图完成可视化分析,跟百度地图相比缺点是不能展示每个城市的用户数Map(init_opts=opts.InitOpts(width="1000px", height="600px",theme = ThemeType.ROMANTIC)) #可切换主题.set_global_opts(title_opts=opts.TitleOpts(title="用户分布图"),visualmap_opts=opts.VisualMapOpts(min_=0,max_=15000,range_text = ['用户量 颜色区间:', ''], #分区间is_piecewise=True, #定义图例为分段型,默认为连续的图例pos_top= "middle", #分段位置pos_left="left",orient="vertical",split_number=10 #分成10个区间)).add("用户数",list,maptype="china").render_notebook()
)
c2
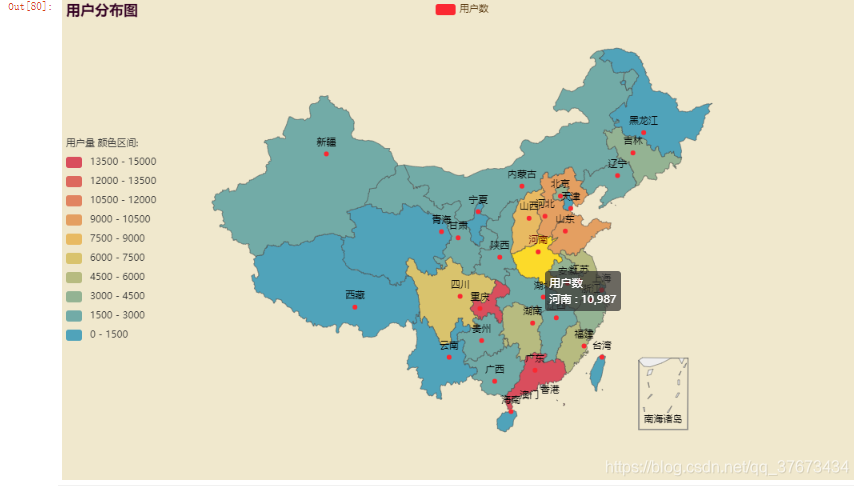
这种效果最好。
接下来将会讲解数据集划分,建模和预测评价。
这篇关于用户行为价值购买率预测——二分类问题(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





