本文主要是介绍caffe:把图片转为lmdb或者leveldb文件(四),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
废话少说,让我们开始深度学习的第一步:制作自己的数据
1.了解文件存放
在caffe中,原作者给我们提供了一个convert_imageset.cpp.该文件放在caffe/tools/文件下,当我们把它编译了之后就会在build/tools/下面生成可执行文件。
2.源代码convert_imageset.cpp
// This program converts a set of images to a lmdb/leveldb by storing them
// as Datum proto buffers.
// Usage:
// convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
// FLAGS:图片参数数组。在tensorflow中也有类似参数组
// --gray:是否依灰度的方式打开图片,默认为false,程序调用的是opencv里面的函数imread()来打开图片。
// --shuffle:是否要打乱图片的顺序,默认为flase
// --backend:转为什么样格式的数据,默认为lmdb。可选leveldb
// --resize_width or resize_height:改变图片的大小(要求所有的图片大小一样),调用opencv
// 中的resize()函数对图像放大或者缩小,默认为0,不改变
// --check_size:检查图像的大小是否一样,默认为false
// --encoded:是否将图片编码放入到最终的数据中,default:false
// --encode_type:与前一个参数对应,将图片编码为哪一种图像
// ROOTFLODER/ 图片放的绝对路径,/home/inc/caffe/data/..
// LISTFILE:图片文件列表,经常使用txt文件,好处理,囧.. 一行一个图片
// DB_NAME:生成的db文件要放的目录
// 说明:文件列表需要自己建立,保存为一个txt文件就ok
// where ROOTFOLDER is the root folder that holds all the images, and LISTFILE
// should be a list of files as well as their labels, in the format as
// subfolder1/file1.JPEG 7
// ....#include <algorithm>
#include <fstream> // NOLINT(readability/streams)
#include <string>
#include <utility>
#include <vector>#include "boost/scoped_ptr.hpp"
#include "gflags/gflags.h"
#include "glog/logging.h"#include "caffe/proto/caffe.pb.h"
#include "caffe/util/db.hpp"
#include "caffe/util/format.hpp"
#include "caffe/util/io.hpp"
#include "caffe/util/rng.hpp"using namespace caffe; // NOLINT(build/namespaces)
using std::pair;
using boost::scoped_ptr;DEFINE_bool(gray, false,"When this option is on, treat images as grayscale ones");
DEFINE_bool(shuffle, false,"Randomly shuffle the order of images and their labels");
DEFINE_string(backend, "lmdb","The backend {lmdb, leveldb} for storing the result");
DEFINE_int32(resize_width, 0, "Width images are resized to");
DEFINE_int32(resize_height, 0, "Height images are resized to");
DEFINE_bool(check_size, false,"When this option is on, check that all the datum have the same size");
DEFINE_bool(encoded, false,"When this option is on, the encoded image will be save in datum");
DEFINE_string(encode_type, "","Optional: What type should we encode the image as ('png','jpg',...).");int main(int argc, char** argv) {
#ifdef USE_OPENCV::google::InitGoogleLogging(argv[0]);// Print output to stderr (while still logging)FLAGS_alsologtostderr = 1;#ifndef GFLAGS_GFLAGS_H_namespace gflags = google;
#endifgflags::SetUsageMessage("Convert a set of images to the leveldb/lmdb\n""format used as input for Caffe.\n""Usage:\n"" convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME\n""The ImageNet dataset for the training demo is at\n"" http://www.image-net.org/download-images\n");gflags::ParseCommandLineFlags(&argc, &argv, true);if (argc < 4) {gflags::ShowUsageWithFlagsRestrict(argv[0], "tools/convert_imageset");return 1;}const bool is_color = !FLAGS_gray;const bool check_size = FLAGS_check_size;const bool encoded = FLAGS_encoded;const string encode_type = FLAGS_encode_type;std::ifstream infile(argv[2]);std::vector<std::pair<std::string, int> > lines;std::string line;size_t pos;int label;while (std::getline(infile, line)) {pos = line.find_last_of(' ');label = atoi(line.substr(pos + 1).c_str());lines.push_back(std::make_pair(line.substr(0, pos), label));}if (FLAGS_shuffle) {// randomly shuffle dataLOG(INFO) << "Shuffling data";shuffle(lines.begin(), lines.end());}LOG(INFO) << "A total of " << lines.size() << " images.";if (encode_type.size() && !encoded)LOG(INFO) << "encode_type specified, assuming encoded=true.";int resize_height = std::max<int>(0, FLAGS_resize_height);int resize_width = std::max<int>(0, FLAGS_resize_width);// Create new DBscoped_ptr<db::DB> db(db::GetDB(FLAGS_backend));db->Open(argv[3], db::NEW);scoped_ptr<db::Transaction> txn(db->NewTransaction());// Storing to dbstd::string root_folder(argv[1]);Datum datum;int count = 0;int data_size = 0;bool data_size_initialized = false;for (int line_id = 0; line_id < lines.size(); ++line_id) {bool status;std::string enc = encode_type;if (encoded && !enc.size()) {// Guess the encoding type from the file namestring fn = lines[line_id].first;size_t p = fn.rfind('.');if ( p == fn.npos )LOG(WARNING) << "Failed to guess the encoding of '" << fn << "'";enc = fn.substr(p);std::transform(enc.begin(), enc.end(), enc.begin(), ::tolower);}status = ReadImageToDatum(root_folder + lines[line_id].first,lines[line_id].second, resize_height, resize_width, is_color,enc, &datum);if (status == false) continue;if (check_size) {if (!data_size_initialized) {data_size = datum.channels() * datum.height() * datum.width();data_size_initialized = true;} else {const std::string& data = datum.data();CHECK_EQ(data.size(), data_size) << "Incorrect data field size "<< data.size();}}// sequentialstring key_str = caffe::format_int(line_id, 8) + "_" + lines[line_id].first;// Put in dbstring out;CHECK(datum.SerializeToString(&out));txn->Put(key_str, out);if (++count % 1000 == 0) {// Commit dbtxn->Commit();txn.reset(db->NewTransaction());LOG(INFO) << "Processed " << count << " files.";}}// write the last batchif (count % 1000 != 0) {txn->Commit();LOG(INFO) << "Processed " << count << " files.";}
#elseLOG(FATAL) << "This tool requires OpenCV; compile with USE_OPENCV.";
#endif // USE_OPENCVreturn 0;
}3.一个生成图片清单的脚本文件
在~/caffe/examples/images/下新建一个脚本文件,取名inc_filelist.sh
使用cat.jpg和另一张fish_bike.jpg表示两个类别。
# /usr/bin/env sh
DATA=examples/images
echo "Create inc_train.txt..."
rm -rf $DATA/inc_train.txt
find $DATA -name *cat.jpg | cut -d '/' -f3 | sed "s/$/ 1/">>$DATA/inc_train.txt
find $DATA -name *bike.jpg | cut -d '/' -f3 | sed "s/$/ 2/">>$DATA/tmp.txt
cat $DATA/tmp.txt>>$DATA/inc_train.txt
rm -rf $DATA/tmp.txt
echo "Done.."执行前给文件加执行的
chmod u+x inc_filelist.sh
解释如下:
DATA:是在当前目录下开始的文件目录
rm:linux 删除命令,在images/目录下如果有inc_train.txt 文件,就山删除
find:在images/目录下找name为cat.jpg的文件。
cut:截取路径。
sed: 在每行的最后面加上标注。将找到的*cat.jpg文件加入标注为1,找到的*bike.jpg文件加入标注为2
cat:将两个txt文件合并为一个文件。
结果截图:
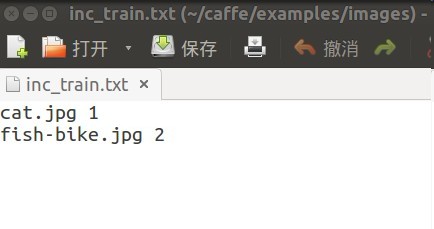
- *cat.jpg为什么用*? - 这样可以对所有cat的图片进行编号。
4.写一个脚本生成lmdb文件
在images/下新建一个create_lmdb.sh文件,内容如下:
#!/usr/bin/env sh
DATA=examples/images
rm -rf $DATA/inc_train_lmdb
build/tools/convert_imageset --shuffle --resize_height=256 --resize_width=256 \
/home/inc/caffe/examples/images/ $DATA/inc_train.txt $DATA/inc_train_lmdb运行脚本,在images文件目录下生成lmdb文件。
待续。。。
这篇关于caffe:把图片转为lmdb或者leveldb文件(四)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





