本文主要是介绍国人为什么不再唯金牌论?——我用Python分析东京奥运会,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面的话
欢迎扫码关注我的公众号,与我一同进步!主要致力于学习
- 使用深度学习解决计算机视觉相关问题
- Python为主的互联网应用服务
- 基于MIPS指令集的CPU微体系结构设计

引言
今年的夏季奥运会于我们大多数国人来说,都是继北京奥运会之后非常有参与感的一届奥运会。我认为,主要有如下几个原因:
- 2020年夏季奥运会举办城市在日本东京,而东京时间与北京时间的时差只有一个小时。我们不用黑白颠倒就可以赶上所有的赛事直播。
- 国内的部分城市相继出现了部分新冠肺炎确诊病例,大部分人的暑期计划由“出游”转变为“家里蹲”。
- 今年的中国代表团出现了大量的90后、00后军团,他们代表了中国青年一代,在奥运会上的亮眼表现得到了社会的广泛关注。
- … …

于我来说,今年也利用各种各样的空闲时间,通过或直播、或回放的方式,观看了中国代表团的部分赛事。闲暇之余,也参与了微博上相关话题的讨论。其中,一个话题名为"#国人为何不再唯金牌论#"引起了我的极大兴趣。虽然我浏览了相关话题的评论,但仍觉得不过瘾。便萌想到可以获取到评论的数据,再利用Python进行分析。
获取数据
要想对数据进行分析,首先要获取数据。这一步,我们通过对网络请求进行分析获取。
首先,进入到微博手机版的界面(PC端界面无法获取到数据)。
链接地址:https://m.weibo.cn/
进入后的界面如图所示。
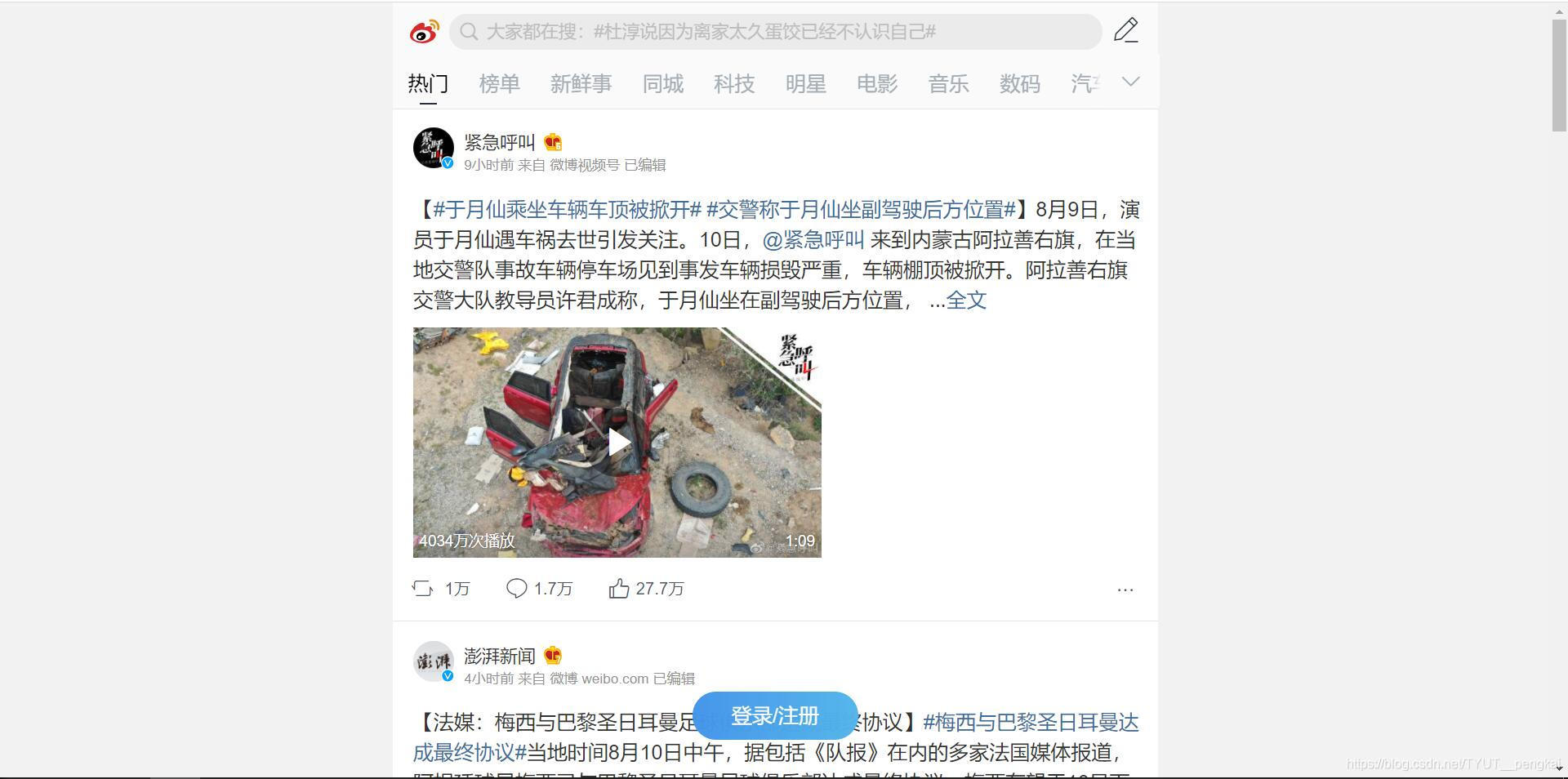
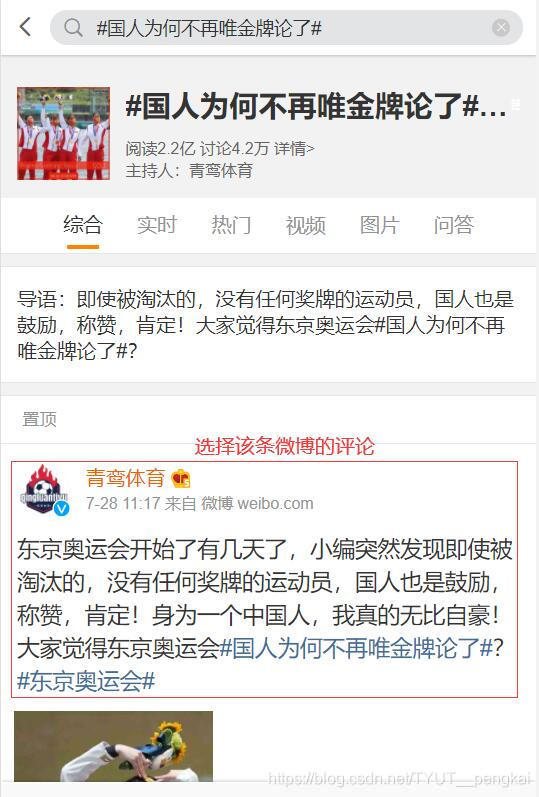
我们在搜索框中输入“#国人为何不再唯金牌论了#”,就可以看到如下图所示的界面。我们选择置顶的第一条微博,并点击进去。
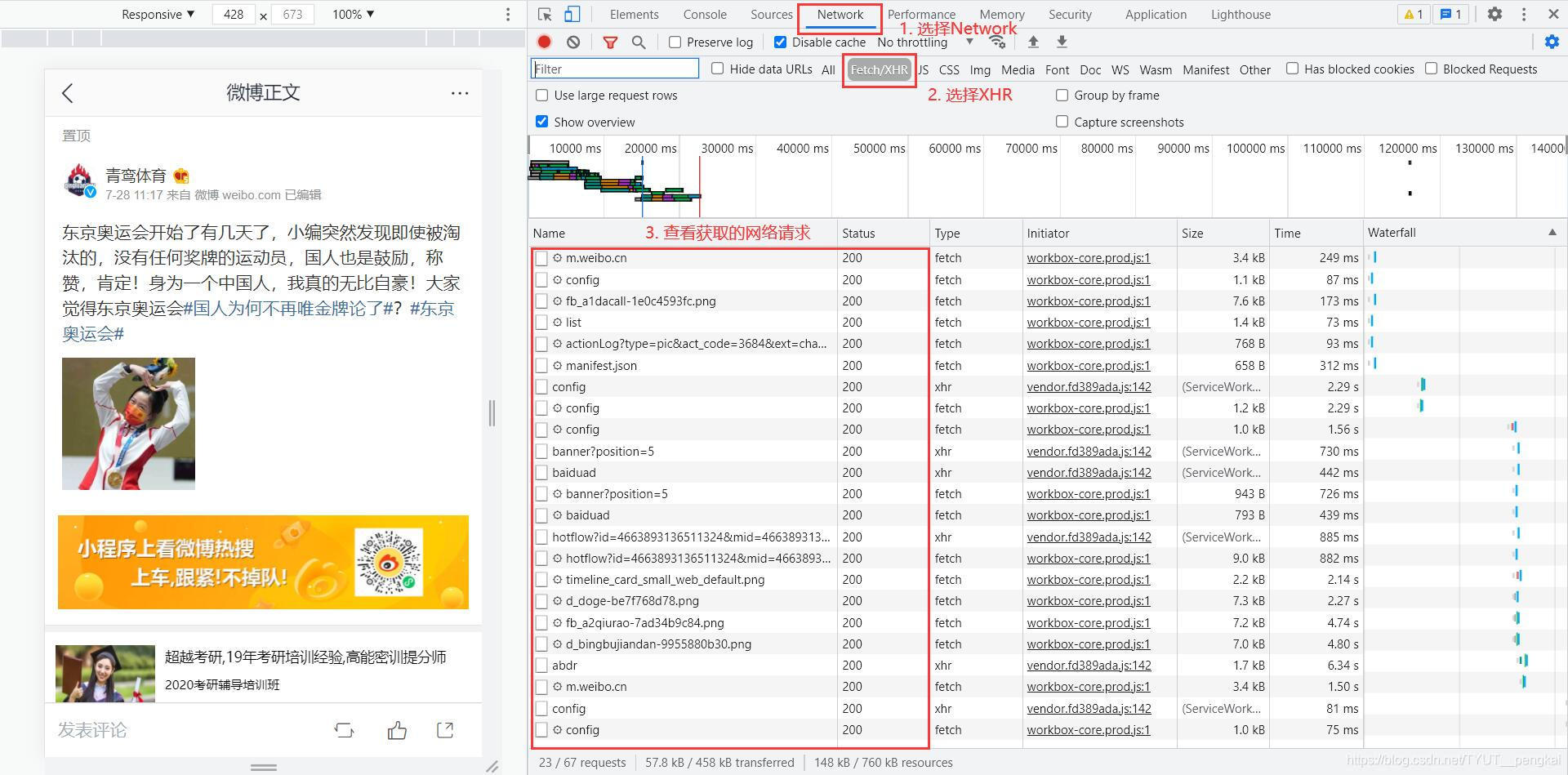
同时,按"F12"或者鼠标右击页面,选择"检查"。我们选择新出现的功能栏中的“Network”,并选择"XHR",就可以看到该页面加载过程中的网络请求了。
观察得到的网络请求中,我们会发现有一条以“hotflow”为开头的网络请求。点击进入到该请求中,查看响应的信息,发现为我们所需要的评论信息。
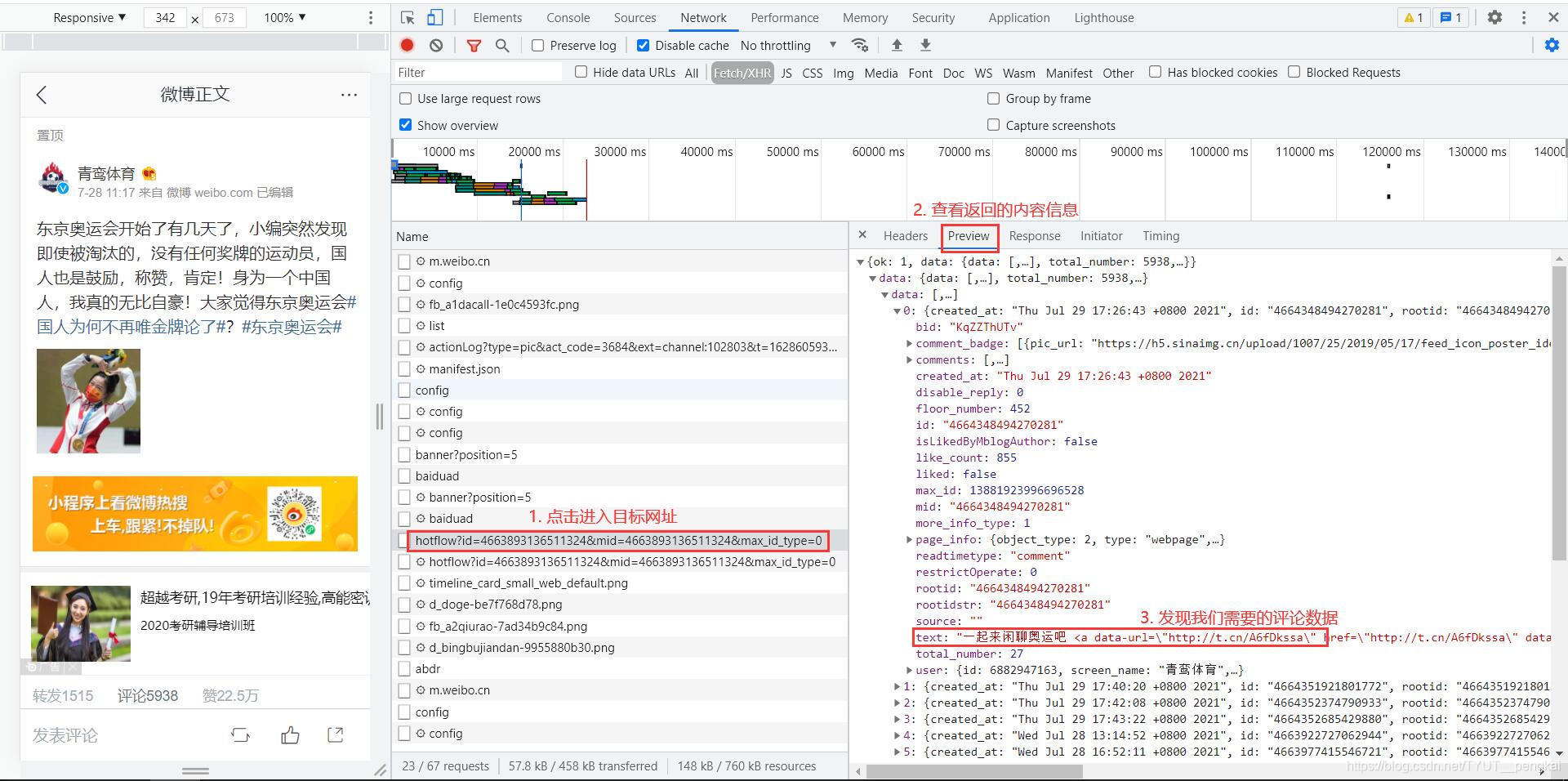
据此可得出结论,该目标网址就是我们需要的评论信息的网址。它将数据封装成json格式返回。因此,只要我们可以获取到该网址的返回值,就可以获取评论信息。
但是,新的问题又出现了:这只有20条评论信息,可是原微博有5000+评论信息。其他信息去哪了?在进行分析之后可以发现,评论信息是动态加载的,当我们不断向下拖动信息时,就可以获得所有的评论信息啦~
解决了所有问题之后,我们只剩下最后一步,将得到的信息进行处理,把我们需要的评论内容进行处理之后保存到文本文件中。我们使用如下的Python程序实现。
def get_data(review_file_path):"""在文件中读取数据,并对数据进行处理:param review_file_path: 评论文件的存储路径,string:return: 评论信息"""review_contents = []with open(review_file_path, 'r') as f:lines = f.readlines()f.close()n = len(lines)for i in range(n):line = json.loads(lines[i])review_datas = line['data']['data']data_nums = len(review_datas)# 设置开始读取评论的位置if i == 0:start = 1else:start = 0for j in range(start, data_nums):# 正则匹配处理文本其他信息pattern_01 = re.compile(r'<span class="url-icon">.*?</span>', re.S)pattern_02 = re.compile(r'<a .*?>.*?</a>', re.S)origin_review_content = review_datas[j]['text']review_content = re.sub(pattern_01, '', origin_review_content)review_content = re.sub(pattern_02, '', review_content)review_contents.append(review_content)return review_contents
最终获取的数据信息和评论信息(经过处理之后的数据信息)可通过如下链接下载。
数据信息
链接:https://pan.baidu.com/s/1EYC1kUf1p9XYQ_fOt_kp1w
提取码:dcn2
注:本文仅获取了1000条评论数据。
分析数据
对经过处理后的评论信息,使用Python的第三方库进行分词并将结果绘制为词云,它通过调用库函数即可,这里不再赘述。使用如下的Python程序实现。
def draw_picture(review_content_file_path):data = open(review_content_file_path, 'r', encoding='utf-8').read()# 分词word_list = jieba.cut(data, cut_all=True)word_list_result = ' '.join(word_list)# 词云的配置word_cloud = WordCloud(# 设置背景background_color='white',# 设置显示的最大的词云数量max_words=50,# 设置词的跨度font_step=10,# 设置字体font_path=r'C:\Windows\Fonts\simsun.ttc',# 设置词云的高度和宽度height=300,width=300,# 设置配色方案random_state=30)# 得到结果my_cloud = word_cloud.generate(word_list_result)plt.imshow(my_cloud)plt.axis("off")plt.show()
最终的绘制结果如图所示。

尾声
从图中不难看出,一些亮眼的字眼,如:“自信”、“强大”、“证明”、“努力”、“国人”。他们给出了这个问题最好的回答:我们的国家强大了,我们的民族正在复兴,我们比以往任何时刻都更加坚定道路自信、理论自信、文化自信,我们不再需要用金牌证明自己。而这也是这届奥运会令我最震撼、最骄傲、最受益的地方!

完整代码
文章的最后奉上实现该分析的完整程序。
#!/usr/bin/env python
# -*- coding:utf-8 -*-"""
@ModuleName: get_data
@Function:
@Author: PengKai
@Time: 2021/8/6 22:52
"""import re
import json
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordClouddef get_data(review_file_path):"""在文件中读取数据,并对数据进行处理:param review_file_path: 评论文件的存储路径,string:return: 评论信息"""review_contents = []with open(review_file_path, 'r') as f:lines = f.readlines()f.close()n = len(lines)for i in range(n):line = json.loads(lines[i])review_datas = line['data']['data']data_nums = len(review_datas)# 设置开始读取评论的位置if i == 0:start = 1else:start = 0for j in range(start, data_nums):pattern_01 = re.compile(r'<span class="url-icon">.*?</span>', re.S)pattern_02 = re.compile(r'<a .*?>.*?</a>', re.S)origin_review_content = review_datas[j]['text']review_content = re.sub(pattern_01, '', origin_review_content)review_content = re.sub(pattern_02, '', review_content)review_contents.append(review_content)return review_contentsdef store_contents(review_contents):"""将得到的评论信息保存在文件中:param review_contents: 评论信息,List:return: None"""n = len(review_contents)with open('./review_data.txt', 'w', encoding='utf-8') as f:for i in range(n):text = review_contents[i] + '\n'f.write(text)f.close()def draw_picture(review_content_file_path):data = open(review_content_file_path, 'r', encoding='utf-8').read()# 分词word_list = jieba.cut(data, cut_all=True)word_list_result = ' '.join(word_list)# 词云的配置word_cloud = WordCloud(# 设置背景background_color='white',# 设置显示的最大的词云数量max_words=50,# 设置词的跨度font_step=10,# 设置字体font_path=r'C:\Windows\Fonts\simsun.ttc',# 设置词云的高度和宽度height=300,width=300,# 设置配色方案random_state=30)# 得到结果my_cloud = word_cloud.generate(word_list_result)plt.imshow(my_cloud)plt.axis("off")plt.show()if __name__ == '__main__':review_file_path = './data.txt'review_contents = get_data(review_file_path)store_contents(review_contents)review_content_file_path = './review_data.txt'draw_picture(review_content_file_path)
这篇关于国人为什么不再唯金牌论?——我用Python分析东京奥运会的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



