本文主要是介绍High-Efficiency Lossy Image Coding Through Adaptive Neighborhood Information Aggregation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
High-Efficiency Lossy Image Coding Through Adaptive Neighborhood Information Aggregation
文章目录
- High-Efficiency Lossy Image Coding Through Adaptive Neighborhood Information Aggregation
- 代码
Abstrat
Abstract—Questing for learned lossy image coding (LIC) with superior compression performance and computation throughput is challenging. The vital factor behind it is how to intelligently explore Adaptive Neighborhood Information Aggregation (ANIA) in transform and entropy coding modules. To this end, Integrated Convolution and Self-Attention (ICSA) unit is first proposed to form a content-adaptive transform to characterize and embed neighborhood information dynamically of any input. Then a Multistage Context Model (MCM) is devised to progressively use available neighbors following a pre-arranged spatial-channel order for accurate probability estimation in parallel. ICSA and MCM are stacked under a Variational AutoEncoder (VAE) architecture to derive rate-distortion optimized compact representation of input image via end-to-end learning. Our method reports state-of-the-art compression performance surpassing the VVC Intra and other prevalent LIC approaches across Kodak, CLIC, and Tecnick datasets;More importantly, our method offers >60× decoding speedup using a comparable-size model when compared with the most popular LIC method. All materials are made publicly accessible at https://njuvision.github.io/TinyLIC for reproducible research
摘要:寻求具有卓越压缩性能和计算吞吐量的学习有损图像编码**(LIC)具有挑战性。其背后的重要因素是如何在变换和熵编码模块中智能地探索自适应邻域信息聚合(ANIA)。为此,首先提出集成卷积和自注意力**(ICSA)单元来形成内容自适应变换,以动态地表征和嵌入任何输入的邻域信息。然后设计多级上下文模型(MCM),按照预先安排的空间通道顺序逐步使用可用的邻居,以并行地进行准确的概率估计。 ICSA 和 MCM 堆叠在变分自动编码器(VAE)架构下,通过端到端学习导出输入图像的率失真优化紧凑表示。我们的方法报告了最先进的压缩性能,超越了 Kodak、CLIC 和 Tecnick 数据集上的 VVC Intra 和其他流行的 LIC 方法;更重要的是,与最流行的 LIC 方法相比,我们的方法使用相当大小的模型提供了 >60 倍的解码加速。所有材料均可在 https://njuvision.github.io/TinyLIC 上公开访问,以进行可重复的研究
I. Introduction
THE pursuit of high-efficiency lossy image coding is ever increasingly critical for vast networked applications such as photo sharing, commercial advertisements, remote medical diagnosis, etc. In principle, lossy image coding searches for the optimal compact representation of input source in a computationally feasible way that leads to the best rate-distortion (R-D) performance [1] defined in
追求高效有损图像编码对于照片共享、商业广告、远程医疗诊断等众多网络应用变得越来越重要。原则上,有损图像编码以计算可行的方式搜索输入源的最优紧凑表示,从而导致在中定义的最佳率失真(R-D)性能[1]
Here, λ is the Lagrange multiplier that controls the desired compression trade-off between the rate and distortion. R represents the number of bits to encode the input data, and D can be measured using Mean Square Error (MSE) or Multiscale Structural Similarity (MS-SSIM) [2]. Though conceptually any input source can be represented using vector quantization, it is practically infeasible for a highdimensional source because of unbearable complexity [3]. In the light of computationally manageable coding solution, it then leads to the Transform Coding that divides the image coding problem into three consecutive simple steps, e.g., transform, quantization, and entropy coding, as stated in [4].
在这里,λ 是拉格朗日乘数,用于控制速率和失真之间所需的压缩权衡。R表示对输入数据进行编码的比特数,D可以用均方误差(MSE)或多尺度结构相似性(MS-SSIM)[2]来衡量。尽管在概念上可以使用矢量量化来表示任何输入源,但由于难以承受的复杂性,高维源实际上是不可行的[3]。鉴于计算可管理的编码解决方案,它会导致变换编码,它将图像编码问题分为三个连续的简单步骤,例如变换、量化和熵编码,如 [4] 中所述。
A. Motivation
In general, the “transform” module converts an image block in the pixel domain to a latent space (e.g., frequency domain), by which less nonzero coefficients are retained to represent the input source [4]; Then the “quantization” function uses finite symbols to represent transformed coefficients with the least bitrate desire under a certain distortion target [14]. Finally, the “entropy coding” engine is devised to further reduce statistical redundancy by accurately modeling the probability distribution of each quantized symbol [15]. Finetuning the transform, quantization, and entropy coding jointly is enforced for decades to pursue better image compression as defined in (1) [13], [16]–[18].
Given that the scalar quantizer is widely applied in mainstream image compression solutions, we keep using it and have the main focus of this work on transform and entropy coding.
A.动机
一般来说,“变换”模块将像素域中的图像块转换为潜在空间(例如频域),通过该潜在空间保留较少的非零系数来表示输入源 [4];然后“量化”函数使用有限符号来表示在一定失真目标下具有最小比特率期望的变换系数 [14]。最后,设计了“熵编码”引擎,通过准确建模每个量化符号的概率分布来进一步减少统计冗余[15]。联合微调变换、量化和熵编码数十年来追求更好的图像压缩,如 (1) [13]、[16]-[18] 中所定义。鉴于标量量化器广泛应用于主流图像压缩解决方案中,我们继续使用它,并其主要重点是这项工作在变换和熵编码上。
Transform Function.
Since the 1970s, a great amount of studies have been devoted to advance the transform module, from the very first Discrete Cosine Transform (DCT) [19], to Hybrid intra Prediction/Transform (HiPT) that applies spatial intra prediction and residue DCT across variable-size tree blocks [16], [21], [22], and to Nonlinear Neural Transform using attention optimized Convolutional Neural Networks (CNN) [3], [9], [23]. All of these endeavors give a clear direction: exploiting redundancy exhaustively with better energy compaction desires content-adaptive transforms that can effectively characterize the neighborhood distribution conditioned on the dynamic input
变换函数。
自20世纪70年代以来,大量的研究致力于推进变换模块,从第一个离散余弦变换(DCT)[19]到混合内部预测/变换(HiPT),它在可变大小的树块[16],[21],[22]上应用空间内预测和残差DCT,并使用注意优化的卷积神经网络(CNN)[3],[9],[23]进行非线性神经变换。所有这些努力都提供了一个明确的方向:用更好的能量压缩详尽地利用冗余需要内容自适应变换,可以有效地表征以动态输入为条件的邻域分布
Entropy Context Model.
As revealed in a sequence of image/video coding standards, context-adaptive arithmetic coding demonstrates its superior capacity to model non-stationary and high-order statistics among syntax elements (e.g., quantized coefficients). Unlike transforms that can use block-level parallelism to some extent [24], the context model, especially in the decoding phase, operates sequentially because of causal dependency [15]. Thus, high-performance and high-throughput entropy modeling is of great importance in practice [25]. How to leverage neighborhood dependency to arrange a more appropriate order for context modeling that not only provides accurate probability estimation but also assures computationally-efficient processing in the entropy coding engine is crucial. As seen, the vital factor behind high-efficiency LIC for ensuring high-performance compression and high-throughput computation jointly is highly related to the efficient use of neighborhood information that is defined as the Adaptive Neighborhood Information Aggregation (ANIA).
熵上下文模型。
如一系列图像/视频编码标准所示,上下文自适应算术编码证明了它在语法元素(例如量化系数)之间建模非平稳和高阶统计方面的优越性能。与可以在一定程度上使用块级并行性的变换[24]不同,上下文模型,特别是在解码阶段,由于因果依赖[15]而按顺序运行。因此,高性能和高通量熵建模在实践中具有重要意义[25]。如何利用邻域依赖为上下文建模安排更合适的顺序,这不仅提供了准确的概率估计,而且保证了熵编码引擎中的计算效率处理是至关重要的。可以看出,高效LIC联合保证高性能压缩和高吞吐量计算的关键因素与有效使用邻域信息高度相关,这些信息被定义为自适应邻域信息聚合(ANIA)。
B. Our Method
This work, therefore, fulfills the use of ANIA in respective transform and entropy coding modules for high-efficiency LIC.
Content-Adaptive Transform Through Integrated Convolution & Self-Attention. Past explorations have suggested us leveraging neighborhood dependency adaptively for better transformation [20], [22]. Although deep CNN-based nonlinear transforms have been devised in a collection of LIC approaches shown in Fig. 1 because of their powerful representation capacity to embed neighborhood information of underlying content, they do have limitations [26]. For example, offline-trained CNN models are presented with fixed receptive fields and weights in inference, making them generally inefficient for unseen images that exhibit different content distribution from training samples [27].
To tackle it, we propose the Integrated Convolution and Self-Attention (ICSA) unit that is comprised of a convolutional layer and multiple self-attention layers realized by local window-based Residual Neighborhood Attention Blocks (RNABs) [28]. The convolutional layer is applied in each ICSA unit to not only reduce the data dimensionality [23] but also exploit the hierarchical characteristics of the content [20]. In comparison to fixed-weights convolutions used in pre-trained CNN models, the self-attention mechanism in succeeding RNABs can weigh and aggregate neighboring elements onthe-fly with which instantaneous content input can be better characterized to some extent.
B.因此,我们的方法这项工作满足了 ANIA 在各自的变换和熵编码模块中用于高效 LIC 的使用。
通过集成卷积和自我注意的内容自适应变换。过去的探索建议我们自适应地利用邻域依赖来更好地转换[20],[22]。尽管基于深度 CNN 的非线性变换已在图 1 所示的 LIC 方法中的集合中设计,因为它们具有强大的表示能力来嵌入底层内容邻域信息,但它们确实存在局限性 [26]。例如,离线训练的 CNN 模型在推理中呈现具有固定的感受野和权重,这使得它们对于与训练样本 [27] 表现出不同内容分布的看不见的图像通常效率低下。
为了解决这个问题,我们提出了集成卷积和自注意力 (ICSA) 单元,它由卷积层和由基于局部窗口的残差邻域注意块 (RNAB) [28] 实现的多个自注意力层组成。在每个ICSA单元中应用卷积层,不仅可以降低数据维数[23],还可以利用内容[20]的层次特征。与预训练 CNN 模型中使用的固定权重卷积相比,后续 RNAB 中的自注意力机制可以动态地权衡和聚合相邻元素,其中瞬时内容输入可以在一定程度上更好地表征。
Entropy Coding Using Multistage Context Model. Adaptive context modeling conditioned on hyperpriors and spatial-channel neighbors jointly that was originally proposed by Minnen et al. [8] and extended in succeeding followups [9], [11], [23], [29] is able to accurately approximate the probability of latent features following an autoregressive manner. However, the sequential processing of spatial or spatial-channel autoregressive neighbors (in a raster scan order) makes the image decoder extremely impractical, e.g., taking hours to reconstruct a 1080p RGB image due to element-by-element computation as reported in [23], [30]1.
使用多阶段上下文模型的熵编码。自适应上下文建模以超先验和空间通道邻居联合为条件,最初由Minnen等人提出。[8]并在随后的后续后续后续随访[9]、[11]、[23]、[29]中进行了扩展,能够以自回归的方式准确地逼近潜在特征的概率。然而,空间或空间通道自回归邻居的顺序处理(以光栅扫描顺序)使得图像解码器非常不切实际,例如,由于元素计算,需要几个小时来重建 1080p RGB 图像,如 [23]、[30]1 中所述。
Thus, devising a method that not only best maintains the performance of the autoregressive model but also enables parallel processing for high-throughput computation is of great desire. Apparently, the efficiency of the autoregressive model comes from the utilization of causal neighbors for conditional probability estimation. Simply enforcing the independent processing of each latent element by completely ignoring the inter dependency across neighbors for concurrency can improve the throughput but definitely hurt the compression performance. It urgently calls for intelligently exploiting neighborhood dependency using a different conditional manner (or scan order).
As inspired by recent studies in [10], [31] where they arranged the context prediction across evenly-grouped feature channels, and/or uniformly-grouped spatial neighbors for parallel probability estimation, we propose the Multistage Context Model (MCM) to process nonuniformly-grouped spatialchannel features in a pre-arranged context modeling order for optimal performance-complexity trade-off.
因此,设计一种不仅最好地保持自回归模型性能的方法,而且能够并行处理高通量计算是非常希望的。显然,自回归模型的效率来自于利用因果邻居进行条件概率估计。简单地通过完全忽略邻居之间的相互依赖性来实现每个潜在元素的独立处理,以提高吞吐量,但肯定会损害压缩性能。迫切需要使用不同的条件方式(或扫描顺序)智能地利用邻域依赖关系。
受 [10]、[31] 中最近的研究的启发,他们在均匀分组的特征通道之间安排上下文预测,以及/或均匀分组的空间邻居进行并行概率估计,我们提出了多阶段上下文模型 (MCM),以在预先安排的上下文建模中处理非均匀分组的空间通道特征,以实现最佳性能-复杂性权衡。
We first slice the latent feature tensor along with the channel dimension into four sub-tensors with variable channels following the Cosine slicing strategy where the number of channels increases gradually from the first to the fourth channel-grouped sub-tensor. Upon each channel-grouped sub-tensor, a Generalized Checkerboard Pattern (GCP) is utilized to group spatial neighbors for multi-step processing where concurrent context prediction is applied for same-group elements using available spatial-channel neighbors previously-processed in preceding steps. The granularity of GCP decreases from one stage to another for the processing of corresponding channel-grouped sub-tensor, e.g., 4-Step GCP at the first stage, 2-Step GCP for both the second and their stage, and direct channel-wise context prediction without spatial GCP for the last stage. As revealed later, progressively processing such non-uniformly grouped spatial-channel features ensures accurate and highthroughput context modeling simultaneously.
我们首先按照余弦切片策略将潜在特征张量和通道维度分割成四个具有可变通道的子张量,其中通道数从第一个到第四个通道分组的子张量逐渐增加。在每个通道分组的子张量上,利用广义棋盘模式 (GCP) 对空间邻居进行分组以进行多步处理,其中并发上下文预测应用于同一组元素,使用先前步骤中处理可用的空间通道邻居。GCP的粒度从一个阶段减少到另一个阶段,用于处理相应的通道分组子张量,例如第一阶段的4-Step GCP、第二阶段及其阶段的2-Step GCP,以及最后一阶段没有空间GCP的直接通道上下文预测。如后面所示,逐步处理这种非均匀分组的空间通道特征确保了准确和高通量的上下文建模。
End-to-End Architecture. We stack the ICSA and MCM units upon the prominent VAE structure to form a novel LIC. We call it TinyLIC as in Fig. 2. Such VAE architecture has been well generalized in various LICs [7]–[9], [23]. As seen, main and hyper coders are paired with encoding and decoding processes. In the main encoder, it generally performs the analysis transform ga(·) using four consecutive ICSA units to derive latent features of input image x while the main decoder mirrors the encoding as the synthesis transform gs(·)to reconstruct ˆx. To efficiently encode quantized latent featuresˆy, the MCM jointly utilizes the hyperpriors and spatialchannel neighbors, where hyperpriors are generated by the hyper coder that uses two paired ICSA units and a factorized model-based entropy coding [7].
端到端架构。我们将ICSA和MCM单元堆叠在突出的VAE结构上,形成一个新的LIC。我们称之为TinyLIC,如图2所示。这种VAE架构在各种LICs[7]-[9]、[23]中得到了很好的推广。可以看出,主编码和超参数编码与编码和解码过程配对。在主编码器中,它通常使用四个连续的ICSA单元执行分析变换ga(·)来导出输入图像x的潜在特征,而主解码器将编码反映为合成变换gs(·)来重建ˆx。为了有效地编码量化的潜在特征ˆy,MCM联合利用超先验和空间信道邻居,其中超先验由使用两个配对ICSA单元的超编码器和基于分解模型的熵编码[7]生成。
C. Contribution
Our contributions are summarized below:
- This work shows that high-efficiency LIC with both high-performance compression and high-throughput computation can be successfully fulfilled by adaptive neighborhood information aggregation (ANIA) to best exploit neighborhood characteristics in transform and entropy coding; As for transform function, the ANIA dynamically adapts itself to the input to best embed neighborhood information; while for entropy coding, it carefully arranges the order of context modeling upon non-uniformly grouped spatial-channel features, which not only retains the efficiency as the autoregressive model but also enables high-throughput parallel processing.
- This work exemplifies the design of ANIA by using the Integrated Convolution and Self-Attention unit for contentadaptive transform, and the Multistage Context Model in entropy coding, respectively, to form the proposed TinyLIC; Extensive comparisons report the superior compression efficiency of the TinyLIC, outperforming the VVC Intra and other notable LICs for three popular datasets; More importantly, theTinyLIC offers the best complexity-performance tradeoff, reporting > 10 absolute percentage BD-rate points improvement against the same HEVC Intra, > 60× decoding speedup with a comparable-size model to the Minnen’18 [8] - the seminal foundation for other LIC approaches.
- The proposed TinyLIC further reports its generalization by thoroughly examining a variety of settings in modular components such as the backbone structure (e.g., feature embedding, self-attention method), entropy context modeling (e.g., conditional estimation method) in ablation studies. Additional experiments are also carried out to report the efficiency of the TinyLIC in a companion supplementary material.
C.贡献我们的贡献总结如下:
1)这项工作表明,具有高性能压缩和高吞吐量计算的高效率 LIC 可以通过自适应邻域信息聚合 (ANIA) 成功实现,以最好地利用变换和熵编码中的邻域特征;至于变换函数,ANIA 动态地适应输入以最好地嵌入邻域信息;而对于熵编码,它仔细安排上下文建模在非均匀采样的空间通道特征上的顺序,这不仅保留了自回归模型的效率,而且可以实现高吞吐量的并行处理。
2)这项工作举例说明了ANIA的设计,分别使用集成卷积和自注意单元进行内容自适应变换,以及熵编码中的多级上下文模型来形成所提出的TinyLIC;大量的比较报告了TinyLIC优越的压缩效率,在三个流行的数据集上优于VVC Intra和其他显著的LICs;更重要的是,TinyLIC提供了最佳的复杂度-性能权衡,报告了> 10个绝对百分比的BD-rate点相对于相同的HEVC Intra提高,> 60×解码加速,与Minnen’18[8]相当大小的模型,这是其他LIC方法的重要基础。
3)提出的TinyLIC通过彻底检查模块化组件中的各种设置,如主干结构(如特征嵌入、自我注意方法)、熵上下文建模(如条件估计方法)在消融研究中进一步报告其泛化。还进行了额外的实验,以报告 TinyLIC 在配套补充材料中的效率。
II. RELATED WORK
This section briefs the developments in transform coding for image compression including classical rules-based approaches and recently-emerged learning-based solutions
本节简要介绍了图像压缩变换编码的发展,包括经典的基于规则的方法和最近出现的基于学习的解决方案
A. Rules-based Transform Coding
Fixed-Weights Transforms. Prominent transforms like DCT (Discrete Cosine Transform) [19] and Wavelet [32] use linear transformations that are generally comprised of a set of linear and orthogonal bases. They have been used in famous image coding standards like JPEG [33] and JPEG2000 [34]. Later, DCT alike Integer transforms [35] are adopted in intra profile of respective H.264/AVC [36], HEVC [6], and VVC [13] to process predictive residues.
Apparently, linear transformation with fixed bases can not best exploit the redundancy because the content of the underlying image block is non-stationary and does not strictly follow the mathematical distribution as assumed (e.g., Gaussian source [4]). Therefore, devising transformation with datadriven bases to better exploit non-stationary content distribution attracts intensive attention. Notable approaches include the dictionary learning [37]–[39], KLT [20] and recentlyemerged CNN transforms [3] (see Sec. II-B for more details).
A.基于规则的变换编码
固定权重变换。DCT(离散余弦变换)[19]和小波[32]等突出变换使用线性变换,通常由一组线性和正交基组成。它们已被用于著名的图像编码标准,如JPEG[33]和JPEG2000[34]。随后,在各自的 H.264/AVC [36]、HEVC [6] 和 VVC [13] 的配置文件中采用了类似 DCT 的整数变换 [35] 来处理预测残差。显然,具有固定碱基的线性变换不能最好地利用冗余,因为底层图像块的内容是非平稳的,并且不像假设的那样严格遵循数学分布(例如,高斯源 [4])。因此,设计具有数据驱动基础的转换以更好地利用非平稳内容分布引起了极大的关注。值得注意的方法包括字典学习[37]-[39]、KLT[20]和最近合并的CNN变换3。
Content-Adaptive Transforms.
Although data-driven transforms have improved energy compaction [20] to some extent compared with fixed-basis DCT or wavelet, the model generalization is still a challenging problem due to fixed weights after training. For example, if the distribution of test data is different from the training samples, energy compaction is largely suffered with poor coding performance [20].
Given that neighborhood pixels often presented high coherency, adaptively weighting local spatial neighbors through an autoregressive predictive means [40] or predefined directional patterns [21], [22] had been proposed and extensively studied over the past decades. Since the late 1990s, spatial intra prediction was integrated with the aforementioned fixedbasis transforms (e.g., DCT), forming the normative toolset in mainstream intra profiles of video coding standards like H.264/AVC Intra, HEVC Intra, and VVC Intra, because of the superior performance on redundancy removal and energy compaction [20].
内容自适应变换。
尽管与固定基DCT或小波相比,数据驱动变换在一定程度上提高了能量压缩[20],但由于训练后权值固定,模型泛化仍然是一个具有挑战性的问题。例如,如果测试数据的分布与训练样本不同,能量压缩在很大程度上受到编码性能较差[20]的影响。
鉴于邻域像素通常具有较高的一致性,在过去的几十年里,通过自回归预测均值[40]或预定义的方向模式[21]、[22]自适应地加权局部空间邻居。自20世纪90年代末以来,空间内预测与上述固定基变换(如DCT)相结合,在H.264/AVC Intra、HEVC Intra和VVC Intra等视频编码标准的主流内剖面中形成了规范工具集,因为在冗余去除和能量压缩[20]上具有更好的性能。
Such Hybrid intra Prediction/Transform (HiPT) dynamically characterizes and embeds spatial neighbors, making it content adaptive. Then after, variable-size HiPT has been extended along with the recursive tree structures, by which the nonstationary image characteristics in different regions can be well and adaptively captured and modeled.
The use of reconstructed neighbors in HiPT leverages the neighborhood coherency through handcrafted rules to best reflect the dynamics of the input content, which motivates us to develop the content-adaptive transformation from a learning perspective.
这种混合内部预测/变换(HiPT)动态表征和嵌入空间邻居,使其内容自适应。然后,将可变大小的HiPT与递归树结构一起扩展,通过递归树结构可以很好地自适应地捕获和建模不同区域的非平稳图像特征。
HiPT 中使用重构邻居通过手工规则利用邻域一致性来最好地反映输入内容的动态,这促使我们从学习的角度开发内容自适应转换。
Entropy Model. Quantized transform coefficients are subsequently encoded into binary strings for efficient storage or network delivery, by further exploiting their statistical correlations. Extensive explorations conducted in the past [15] have clearly revealed that an accurate context model conditioned on neighborhood elements plays a vital role in high-efficiency entropy coding. Examples include the context-adaptive variablelength coding (CAVLC) and context-adaptive binary arithmetic4coding (CABAC) [15]. And, because of the superior efficiency offered by the arithmetic codes, CABAC, and its variants, are widely deployed in mainstream compression recommendations like HEVC, VVC, JPEG2000, etc, where associated context models are mainly developed following empirical rules and experimental observations.
Computation throughput limitation incurred by the sequential data dependency in context modeling was extensively investigated since the standardization of HEVC a decade ago. High-throughput and high-performance were then jointly evaluated during the development of the entropy coding engine [25], [41]. Well-known examples include symbol parsing dependency unknitting, bins grouping, etc that more or less rely on the utilization of contextual correlation in a local neighborhood.
熵模型。量化变换系数随后通过进一步利用它们的统计相关性编码到二进制字符串中,以实现高效的存储或网络传递。过去[15]进行的广泛探索清楚地表明,以邻域元素为条件的准确上下文模型在高效熵编码中起着至关重要的作用。例子包括上下文自适应可变长度编码 (CAVLC) 和上下文自适应二进制算术 4 编码 (CABAC) [15]。而且,由于算术代码CABAC及其变体提供的卓越效率被广泛应用于HEVC、VVC、JPEG2000等主流压缩推荐中,相关上下文模型主要按照经验规则和实验观察开发。
自十年前HEVC标准化以来,顺序数据依赖在上下文建模中引起的计算吞吐量限制得到了广泛的研究。在熵编码引擎[25]、[41]的开发过程中,对高通量和高性能进行了联合评估。众所周知的示例包括符号解析依赖项 unknitting、bin 分组等,或多或少依赖于局部邻域中上下文相关性的利用率。
B. Learning-based Transform Coding
Given that LIC methods jointly optimize transform and entropy coding modules through end-to-end learning, we review them together.
B.基于学习的变换编码鉴于 LIC 方法通过端到端学习联合优化变换和熵编码模块,我们将它们一起回顾。
CNN Models. As CNNs have shown their remarkable capacity for generating compact representation features from underlying image data in various visual tasks, numerous attempts have been made in recent years to use CNN models for image compression. For instance, in 2017, Ball ́e et al. [42] showed that stacking convolutions could replace the traditional transform coding to form an end-to-end trainable image compression method with better efficiency than the JPEG [17], in which a CABAC alike entropy coding engine was used. Then, hyperpriors and spatial-channel neighbors were jointly used in [8], [9], [23] for context modeling assuming the Gaussian distribution following an autoregressive manner, which further improved the image compression efficiency. As seen such a context model conditioned on joint hyperprior and autoregressive neighbors mostly utilized the local correlations. Recently, Qian et al. [43] and Kin et al. [44] extended the utilization of only local correlation to the use of both global and local correlation by the inclusion of additional global priors.
In addition to these methods mainly utilizing convolutions to aggregate information locally, our early exploration in [23] applied nonlocal attention to optimizing intermediate features generated by the convolutional layer for more effective information embedding. However, the nonlocal computation is expensive since it typically requires a large amount of space to host a correlation matrix with the size of Hf Wf × Hf Wf . Here Hf and Wf are the height and width of the input feature map. A similar convolution-based spatial attention mechanism was also used in [9] and other related works.
CNN 模型。由于 CNN 已经显示出它们在各种视觉任务中从底层图像数据生成紧凑表示特征的显着能力,近年来已经进行了大量尝试,以使用 CNN 模型进行图像压缩。例如,2017年,Balĺe等人。[42]表明,堆叠卷积可以取代传统的变换编码,形成比JPEG[17]更好的端到端可训练图像压缩方法,其中使用了CABAC类熵编码引擎。然后,[8]、[9]、[23]中联合使用超先验和空间通道邻居进行上下文建模,假设高斯分布遵循自回归的方式,进一步提高了图像压缩效率。可以看出,以联合超先验和自回归邻居为条件的上下文模型大多利用了局部相关性。最近,Qian 等人。 [43] 和 Kin 等人。 [44] 通过包含额外的全局先验,扩展了仅使用局部相关性来使用全局和局部相关性。
除了这些方法主要利用卷积在局部聚合信息外,我们在[23]的早期探索将非局部注意应用于优化卷积层生成的中间特征,以实现更有效的信息嵌入。然而,非局部计算是昂贵的,因为它通常需要大量的空间来承载一个大小为Hf Wf × Hf Wf的相关矩阵。这里Hf和Wf是输入特征映射的高度和宽度。[9] 和其他相关工作也使用了类似的基于卷积的空间注意机制。
ViT Models. LIC solutions discussed above mainly leveraged CNNs to formulate nonlinear transform and highperformance entropy coding. With the surge of self-attention based Vision Transformers (ViT) in various tasks [45]–[50], a number of attempts had been made to apply Transformer alike schemes to improve transform and entropy coding in a LIC. For example, Zhu et al. [51] replaced stacked convolutions with Swin Transformer [50] to form the nonlinear transform and kept using the channel-wise context prediction as in [10]; while Qian et al. [12] retained CNN transform but replaced the convolution-based context modeling with the Transformer. Coincidentally at the same time, our preliminary study in [29] extended the Transformer architecture to both transform and entropy coding modules.
Discussion. Most works have claimed that the ability of long-range dependency capturing in ViTs improves the CNN models that operate locally. Yet, we have a different view: we believe that the compression gains are mainly contributed by the self-attention mechanism that can best weigh neighborhood information of the dynamic input. As reported in [52], largekernel convolutions can also capture relatively long-range dependency as ViTs for various tasks.
ViT 模型。上面讨论的 LIC 解决方案主要利用 CNN 来制定非线性变换和高性能熵编码。随着基于自我注意的视觉转换器 (ViT) 在各种任务中的兴起 [45]-[50],已经进行了许多尝试来应用类似 Transformer 的方案来改进 LIC 中的变换和熵编码。例如,Zhu等人[51]用Swin Transformer[50]替换了堆叠卷积,形成非线性变换,并使用[10]中的通道上下文预测保持;而Qian等人[12]保留了CNN变换,但用Transformer替换了基于卷积的上下文建模。同时巧合的是,我们在[29]中的初步研究将Transformer架构扩展到转换和熵编码模块。
讨论。大多数工作声称,ViTs 中远程依赖捕获的能力提高了在本地操作的 CNN 模型。然而,我们有不同的观点:我们认为压缩增益主要是由自注意力机制贡献的,该机制可以最好地权衡动态输入的邻域信息。正如 [52] 中所报道的,大内核卷积还可以捕获相对远程依赖关系,因为 ViT 用于各种任务。
Efficient Entropy Model. Computation efficiency is another key factor determining whether the solution can be used in practice. Existing LIC approaches were rigorously criticized for exhaustive computing and caching. The most computationally exhaustive subsystem is the sequential processing of syntax elements in entropy coding. For instance, the decoding runtime of a popular context model conditioned on joint hyperprior and spatial autoregressive neighbors is a function of O(H×W ), which is unbearable for practical image applications. Massively-parallel context modeling was then developed by exploring channel-wise concurrency like channelwise grouping [10], and spatial concurrency like checkerboard patterning [53] or column-wise/row-wise parallelism [23] to improve the throughput with reasonable performance compromise.
高效的熵模型。计算效率是决定解决方案在实践中是否可以使用的另一个关键因素。现有的 LIC 方法受到严格批评以进行详尽的计算和缓存。计算量最大的子系统是熵编码中语法元素的顺序处理。例如,以联合超先验和空间自回归邻居为条件的流行上下文模型的解码运行时间是 O(H×W ) 的函数,这对于实际的图像应用来说是不利的。然后通过探索通道级并发(如通道分组[10])和空间并发(如棋盘模式[53]或列/行并行[23])来开发大规模并行上下文建模,以提高吞吐量,并具有合理的性能折衷。
He et al. [53] solely relied on the 2-step checkerboard pattern to perform context modeling across grouped spatial neighbors. Although it significantly improved computational efficiency, the context probability estimation of half of the latent features used the hyperpriors only, which led to a noticeable performance loss to the default autoregressive model (see reproduced results of “P” model in Fig. 11). Minnen et al. [10] then proposed a channel-wise conditional model by slicing the latent feature tensor into ten equal-channel groups to avoid the use of spatial autoregressive neighbors for context modeling. The probability of latent features in the latter grouped channels can be predicted using the hyperpriors and the previously-processed groups. This method showed better R-D performance than the serial autoregressive model by additionally costing a huge amount of parameters and multiply-accumulation operations. Later, the combination of non-uniform channel grouping and uniform 2-Step spatial checkerboard grouping in each grouped channels was given in [31] with improved efficiency. The aforementioned methods performed the uniform feature grouping either spatially or channel-wisely to do context modeling following a prearranged order.
The proposed MCM groups the latent features nonuniformly from both spatial and channel dimensions. In this way, our method extends existing methods in [10], [31], [53] with a generalized solution which offers the best performance complexity tradeoff as reported in subsequent studies.
He等人[53]仅依靠两步棋盘模式对分组的空间邻居进行上下文建模。虽然它显着提高了计算效率,但一半的潜在特征的上下文概率估计仅使用超先验,这导致默认自回归模型的性能损失明显(参见图 11 中“P”模型的重现结果)。Minnen等人[10]通过将潜在特征张量切片为十个相等的通道组,提出了一种通道条件模型,以避免使用空间自回归邻居进行上下文建模。使用超先验和先前处理的组可以预测后一个分组通道中潜在特征的概率。这种方法通过额外花费大量参数和乘法累加操作,显示出比串行自回归模型更好的 R-D 性能。随后,[31]给出了各分组通道中非均匀信道分组和均匀两步空间棋盘分组的组合,提高了效率。上述方法在空间上或通道明智地执行统一特征分组,以按照预先安排的顺序进行上下文建模。
所提出的MCM从空间和通道维度不均匀地对潜在特征进行分组。通过这种方式,我们的方法将 [10]、[31]、[53] 中的现有方法扩展为广义解决方案,该解决方案提供了在后续研究中报告的最佳性能复杂性权衡。
代码
python examples/train.py -m tinylic -d /path/to/my/image/dataset/ --epochs 400 -lr 1e-4 --batch-size 8 --cuda --save
F:\universityMemory\智能视频编码\data\flicker_2W_images\flicker_2W_images
python examples/train.py -m tinylic -d F:/universityMemory/智能视频编码/data/flicker_2W_images/flicker_2W_images/ --epochs 400 -lr 1e-4 --batch-size 8 --cuda --save
python examples/train.py -m tinylic -d flicker_2W_images/flicker_2W_images/ --epochs 400 -lr 1e-4 --batch-size 8 --cuda --save
python examples/train.py -m tinylic -d flicker_2W_images/ --epochs 10 -lr 1e-4 --batch-size 4 --cuda --save
python examples/train.py -m tinylic -d flicker_2W_images/ --epochs 10 -lr 1e-4 --batch-size 4 --cpu
flicker_2W_images\flicker_2W_images
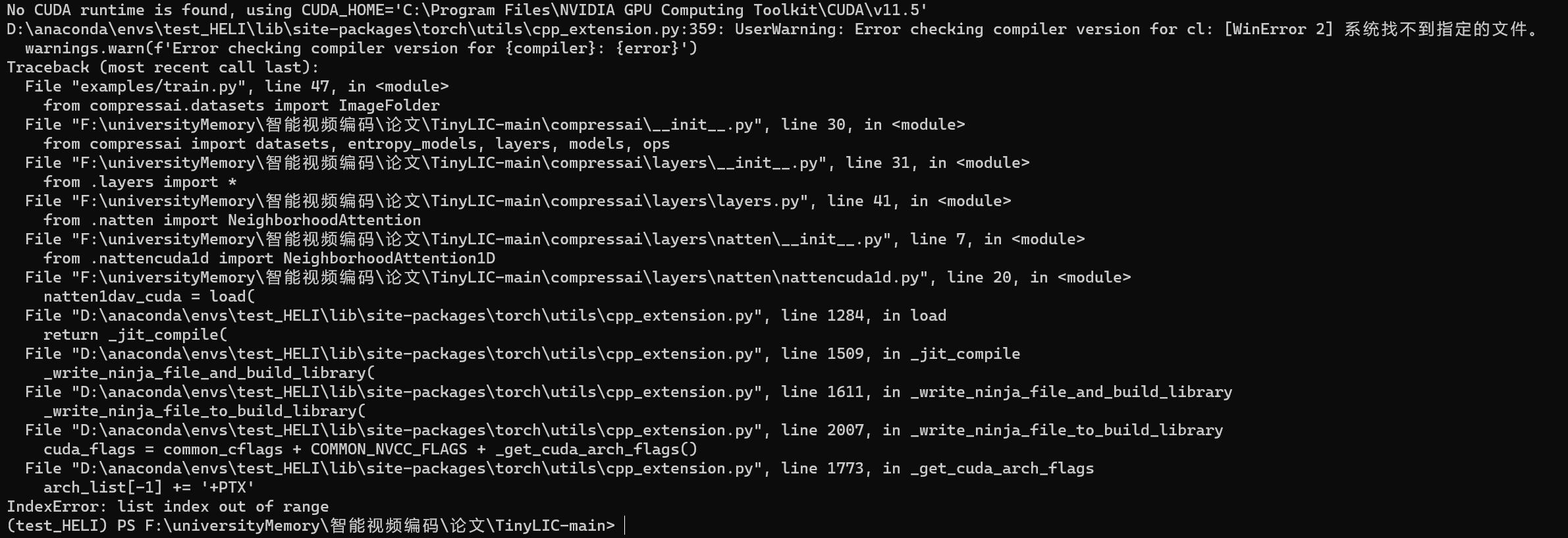
创建虚拟环境后直接pip install -e .得到的结果如下
而且我发现这样的话安装的pytorch是最新版的,如下图所示。

那如果我不pip install -e .,而是pip requirements.txt,报错找不到compressai
print(torch.__version__) ##1.8.1+cpu
print(torch.cuda.is_available())
print(torch.version.cuda) ##检查PyTorch所用的CUDA版本:
然后我把torch删了,下载了gpu版本的
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
print(torch.__version__)
1.8.1+cu111
>>> print(torch.cuda.is_available())
True
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html

python -m compressai.utils.eval_model checkpoint path/to/eval/data/ -a tinylic -p path/to/pretrained/model --cuda
python -m compressai.utils.eval_model checkpoint F:/universityMemory/智能视频编码/data/flicker_2W_images/flicker_2W_images/ -a tinylic -p F:\universityMemory\智能视频编码\论文\TinyLIC-main\pretrained\pretrained\mse\checkpoint_q1.pth.tar --cuda

python -m compressai.utils.eval_model checkpoint path/to/eval/data/ -a tinylic -p path/to/pretrained/model --cuda
总结:
- 要先在compressai里运行setup.py,运行的命令也和普通运行python的命令不一样
python setup.py install - 每次安装pytorch的时候可以先测试一下能不能用以及相应的版本
- pip torch的时候如果出现killed,可以去他后面那个网址里下载(坏处就是要一个一个下载(只有pytorch需要下载,其他torchvision啥的都可以直接pip install 的,但是后面也要加那个网址(可能不加也没事的)),版本记得要匹配好)
- 有时候明明下载的gpu版本的pytoch(认为后面带+cu就是gpu版本的),测试的时候是cpu的,可以到文件夹里看看Lib/site-packages
- 报错:找不到数据集,可以去看看他是怎么加载数据集的代码,就比如这个项目中就是从给定路径下找train文件夹,所以这时我们要自己去建立一个train文件夹
这篇关于High-Efficiency Lossy Image Coding Through Adaptive Neighborhood Information Aggregation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








