本文主要是介绍【业务功能篇17】Springboot +shedlock锁 实现定时任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
业务场景:我们在业务开发过程时,有时需要用到一些定时功能,定期的执行一些数据处理,比如每天固定时间去执行数据,判断是否有符合逻辑的情况,就生成一个告警单,提供给业务查看。
这里接着上一篇技术帖 继续补充定时任务的设计开发 【业务功能篇16】Springboot+mybatisplus+ShedLock框架根据一定的逻辑数据处理规则,定时任务生成告警单
Shedlock是个分布式锁,大致实现,就是针对多个服务,提供一个公有的存储,来维护这个锁(类似悲观锁机制)官方解释是他永远只是一个锁,并非是一个分布式任务调度器。一般shedLock被使用的场景是,你有个任务,你只希望他在单个节点执行,而不希望他并行执行,而且这个任务是支持重复执行的。
ShedLock的作用,确保任务在同一时刻最多执行一次。如果一个任务正在一个节点上执行,则它将获得一个锁,该锁将阻止从另一个节点(或线程)执行同一任务。如果一个任务已经在一个节点上执行,则在其他节点上的执行不会等待,只需跳过它即可 。
ShedLock使用Mongo,JDBC数据库,Redis,Hazelcast,ZooKeeper或其他外部存储进行协调,即通过外部存储来实现锁机制。当第一个微服务执行定时任务的时候,会定时任务进行锁操作,然后其他的定时任务就不会再执行,锁操作有一定的时长,超过这个时长以后,再一次,所有的定时任务进行争抢下一个定时任务的执行权限,如此循环。保证了即使是其中的一个定时任务挂掉了,到一定的时间以后,锁也会释放,其他的定时任务依旧会进行执行权的争夺,执行定时任务。
* 分布式锁,保障多节点部署定时任务只执行一次。 * 本质上是通过对主键进行抢占,因此需要确保数据库中存在shedlock表
一、配置POM依赖
<!-- 分布式定时任务锁--><dependency><groupId>net.javacrumbs.shedlock</groupId><artifactId>shedlock-spring</artifactId><version>4.14.0</version></dependency><dependency><groupId>net.javacrumbs.shedlock</groupId><artifactId>shedlock-provider-jdbc-template</artifactId><version>4.43.0</version></dependency>二、配置启动类
import lombok.extern.slf4j.Slf4j;import net.javacrumbs.shedlock.spring.annotation.EnableSchedulerLock;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.boot.autoconfigure.security.servlet.SecurityAutoConfiguration;
import org.springframework.boot.builder.SpringApplicationBuilder;
import org.springframework.boot.web.servlet.support.SpringBootServletInitializer;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.scheduling.annotation.EnableScheduling;@Slf4j
@EnableCaching
@SpringBootApplication(exclude = {org.springframework.boot.actuate.autoconfigure.security.servlet.ManagementWebSecurityAutoConfiguration.class,SecurityAutoConfiguration.class,DataSourceAutoConfiguration.class
}
)
// 开启定时任务注解
@EnableScheduling
// 开启定时任务锁,默认设置锁最大占用时间为30分钟
@EnableSchedulerLock(defaultLockAtMostFor = "30m")
public class Application extends SpringBootServletInitializer {@Overrideprotected SpringApplicationBuilder configure(SpringApplicationBuilder application) {return application.sources(Application.class);}public static void main(String[] args) {SpringApplication.run(Application.class, args);}
}
三、创建分布式锁配置类
package com.xxx.config;import net.javacrumbs.shedlock.core.LockProvider;
import net.javacrumbs.shedlock.provider.jdbctemplate.JdbcTemplateLockProvider;
import net.javacrumbs.shedlock.spring.annotation.EnableSchedulerLock;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.scheduling.annotation.EnableScheduling;import javax.annotation.Resource;
import javax.sql.DataSource;
import java.util.TimeZone;/*** 分布式锁,保障多节点部署定时任务只执行一次。* 本质上是通过对主键进行抢占,因此需要确保数据库中存在shedlock表。MySql建表语句如下:* CREATE TABLE shedlock(name VARCHAR(64) NOT NULL, lock_until TIMESTAMP(3) NOT NULL,* locked_at TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3), locked_by VARCHAR(255) NOT NULL, PRIMARY KEY (name));*/
@Configuration
@EnableScheduling
@EnableSchedulerLock(defaultLockAtMostFor = "30m")
public class ShedLockConfig {@ResourceDataSource dataSource;/*** 配置锁的提供者*/@Beanpublic LockProvider lockProvider() {return new JdbcTemplateLockProvider(JdbcTemplateLockProvider.Configuration.builder().withJdbcTemplate(new JdbcTemplate(dataSource)).withTableName("shedlock").withTimeZone(TimeZone.getDefault()).build());}
}
四、创建对应的定时任务表
CREATE TABLE shedlock(name VARCHAR(64) NOT NULL, lock_until TIMESTAMP(3) NOT NULL,locked_at TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3), locked_by VARCHAR(255) NOT NULL, PRIMARY KEY (name));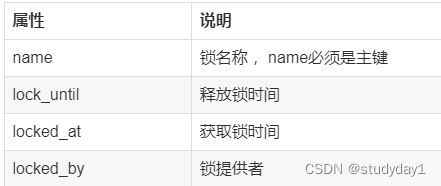
五、创建定时任务
- 定时任务类上加入注解 @Component @EnableScheduling 注册bean,开启定时任务
- 定时方法上加入注解:
- SchedulerLock 分布式锁对象 name值,会插入shedlock表中的name字段,PT2H表示不超过2个小时的锁
-
Scheduled 定时任务每天 早上9点执行一次
@SchedulerLock(name = "keyword_warning", lockAtLeastFor = "PT2H", lockAtMostFor = "PT2H")
@Scheduled(cron = "0 0 09 * * ?") -
@EnableAsync 注解在类上
开启异步,还需要在具体的任务方法加@Async表示需要异步 ,定时任务默认是同步的,主要是为了定时可以按时跑起来,比如说我们任务是每10秒执行一次,但是任务逻辑跑完不止10秒,这样就需要等任务执行完再接着跑,这样频率就没有达到预期效果,所以我们开启异步,多线程去每隔10秒运行任务,即使任务10秒内没跑完也会开启其他线程来跑,而这里的线程池的数量,是系统默认给的,这里可以通过配置参数在yaml文件自定义spring.task.execution.pool.core-size=5 .max-size=20 进行设置
看需求来判断是否使用异步:如果任务执行几分钟完成,然后每天执行一次,那大可不必使用异步
- @Asnyc 注解在对应的定时任务的方法上,表示需要异步执行
package com.xxx.task;import com.xxx.ProdMesKeywordWarnRuleService;
import com.xxx.utils.SpringBeanUtils;
import lombok.extern.slf4j.Slf4j;
import net.javacrumbs.shedlock.spring.annotation.SchedulerLock;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import javax.annotation.Resource;/*** 告警单预警*/
//开启异步,还需要在具体的任务方法加@Async表示需要异步 ,定时任务默认是同步的,主要是为了定时可以按时跑起来,比如说我们任务是每10秒执行一次,但是任务逻辑跑完不止10秒,这样就需要等任务执行完再接着跑,这样频率就没有达到预期效果,所以我们开启异步,多线程去每隔10秒运行任务,即使任务10秒内没跑完也会开启其他线程来跑,而这里的线程池的数量,是系统默认给的,这里可以通过配置参数在yaml文件自定义
//spring.task.execution.pool.core-size=5 .max-size=20 进行设置
//@EnableAsync 看需求来判断 如果任务执行几分钟完成,然后每天执行一次,那大可不必使用异步//开启定时功能 还需要在具体扥任务方法加@Scheduled表示定时频率
@EnableScheduling
@Component
@EnableScheduling
@Slf4j
public class ProdMesKeywordWarnSchedule {@Resourceprivate ProdMesKeywordWarnRuleService warnService;//@Async 需要异步,则开启即可@SchedulerLock(name = "keyword_warning", lockAtLeastFor = "PT2H", lockAtMostFor = "PT2H")@Scheduled(cron = "0 0 09 * * ?")public void createPreWarning() {if (!SpringBeanUtils.isTestProfile()) {//非测试环境时,运行告警单生成的方法warnService.createPreWarningPeriodically();warnService.sendMsOnTen();}}
}
六、定时任务的参数配置:
SchedulerLock 参数
- @SchedulerLock
只有带注释的方法被锁定,库忽略所有其他计划的任务。您还必须指定锁的名称。同一时间只能执行一个任务。 - name
分布式锁名称,注意 锁名称必须唯一。 - lockAtMostFor & lockAtMostForString
指定在执行节点死亡时应将锁保留多长时间。这只是一个备用选项,在正常情况下,任务完成后立即释放锁定。 您必须将其设置lockAtMostFor为比正常执行时间长得多的值。如果任务花费的时间超过 lockAtMostFor了所导致的行为,则可能无法预测(更多的进程将有效地持有该锁)。
lockAtMostFor 单位 毫秒
lockAtMostForString 使用“ PT14M” 意味着它将被锁定不超过14分钟。 - lockAtLeastFor & lockAtLeastForString
该属性指定应保留锁定的最短时间。其主要目的是在任务很短且节点之间的时钟差的情况下,防止从多个节点执行。
ShedLock支持两种模式的Spring集成,分别是 预定方法代理、TaskScheduler代理。我们默认选择最简单也是最实用的方式:预定方法代理(即 @SchedulerLock 的形式),ShedLock会围绕每个带有@SchedulerLock注释的方法创建AOP代理。这种方法的主要优点是它不依赖于Spring调度。缺点是即使直接调用该方法也会应用锁定。还应注意,当前仅支持返回void的方法,如果您注释并调用具有非void返回类型的方法,则会引发异常。
Scheduled参数 cron定时写法
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import java.util.Date;@Component
public class Jobs {//表示方法执行完成后5秒@Scheduled(fixedDelay = 5000)public void fixedDelayJob() throws InterruptedException {System.out.println("fixedDelay 每隔5秒" + new Date());}//表示每隔3秒@Scheduled(fixedRate = 3000)public void fixedRateJob() {System.out.println("fixedRate 每隔3秒" + new Date());}//表示每天8时30分0秒执行@Scheduled(cron = "0 0,30 0,8 ? * ? ")public void cronJob() {System.out.println(new Date() + " ...>>cron....");}
}
- cron表达式:比如你要设置每天什么时候执行,就可以用它
cron表达式,有专门的语法,而且感觉有点绕人,不过简单来说,大家记住一些常用的用法即可,特殊的语法可以单独去查。
cron一共有7位,但是最后一位是年,可以留空,所以我们可以写6位:- * 第一位,表示秒,取值0-59
* 第二位,表示分,取值0-59
* 第三位,表示小时,取值0-23
* 第四位,日期天/日,取值1-31
* 第五位,日期月份,取值1-12
* 第六位,星期,取值1-7,星期一,星期二...,注:不是第1周,第二周的意思
另外:1表示星期天,2表示星期一。
* 第7为,年份,可以留空,取值1970-2099
- (*)星号:可以理解为每的意思,每秒,每分,每天,每月,每年...
- (?)问号:问号只能出现在日期和星期这两个位置。
- (-)减号:表达一个范围,如在小时字段中使用“10-12”,则表示从10到12点,即10,11,12
- (,)逗号:表达一个列表值,如在星期字段中使用“1,2,4”,则表示星期一,星期二,星期四
- (/)斜杠:如:x/y,x是开始值,y是步长,比如在第一位(秒) 0/15就是,从0秒开始,每15秒,最后就是0,15,30,45,60 另:*/y,等同于0/y
- 0 0 3 * * ? 每天3点执行
- 0 5 3 * * ? 每天3点5分执行
- 0 5 3 ? * * 每天3点5分执行,与上面作用相同
- 0 5/10 3 * * ? 每天3点的 5分,15分,25分,35分,45分,55分这几个时间点执行
- 0 10 3 ? * 1 每周星期天,3点10分 执行,注:1表示星期天
- 0 10 3 ? * 1#3 每个月的第三个星期,星期天 执行,#号只能出现在星期的位置
这篇关于【业务功能篇17】Springboot +shedlock锁 实现定时任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





