本文主要是介绍Prometheus+Grafana+Node-exporter+Alertmanager+Python3+Nginx搭建大盘监控以及告警提醒,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
部署方式
非k8s方式
资源占用情况
![]()
![]()
![]()
![]()
![]()
![]()
tar包下载
prometheus(国内镜像):https://mirrors.tuna.tsinghua.edu.cn/github-release/prometheus/prometheus/2.34.0%20_%202022-03-15/prometheus-2.34.0.linux-amd64.tar.gz
pushgateway(国外镜像,较慢):https://github.com/prometheus/pushgateway/releases/download/v1.4.2/pushgateway-1.4.2.linux-amd64.tar.gz
node-exporter(国外镜像,较慢): https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
Grafana(国内镜像):https://repo.huaweicloud.com/grafana/8.4.7/grafana-enterprise-8.4.7.linux-amd64.tar.gz
Alertmanager(国外镜像,较慢):https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
清华大学开源软件镜像站:清华大学 TUNA 协会
prometheus
简介
rometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。
特点
1)多维度数据模型
每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定:这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。
2)灵活的查询语言(PromQL):可以对采集的metrics指标进行加法,乘法,连接等操作;
3)可以直接在本地部署,不依赖其他分布式存储;
4)通过基于HTTP的pull方式采集时序数据;
5)可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端;
6)可通过服务发现或者静态配置来发现目标服务对象(targets)。
7)有多种可视化图像界面,如Grafana等。
8)高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。
9)做高可用,可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
下载和安装
进入工作目录
cd /opt/systemControl
远程下载
wget https://mirrors.tuna.tsinghua.edu.cn/github-release/prometheus/prometheus/2.34.0%20_%202022-03-15/prometheus-2.34.0.linux-amd64.tar.gz
解压prometheus-2.34.0.linux-amd64.tar.gz
tar -zxvf prometheus-2.34.0.linux-amd64.tar.gz
备份配置文件 prometheus.yml
cp prometheus.yml prometheus.yml.bak
修改配置文件 prometheus.yml
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "fly-prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.basic_auth:username: admin password: xxxxxxxxstatic_configs:- targets: ["localhost:9100"] #从localhost:9100 pull数据
9100是从node_export或者pushgateway拉取数据使用,这里设置9100那么node-exporter的监听端口就一定要是9100.
启动
nohup ./prometheus &
注意:有些prometheus.yml配置basic_auth账号密码是无效的,具体原因目前为止,有考虑到安全性,因此使用了nginx代替认证。
basic_auth:username: adminpassword: xxxxxxxx
下载httpd-tools密码文件生成工具
cd yum install httpd-tools -y
设置密码和账号文件
htpasswd -bc /opt/systemControl/prometheus-2.37.6.linux-amd64/ssl/htpasswd username password
nginx配置认证
server {listen 8070;、、考虑到安全箱9090不直接暴露,使用8070代替9090暴露server_name localhost;location / {proxy_pass http://127.0.0.1:9090/;auth_basic "Please enter the user name and password";auth_basic_user_file /opt/systemControl/prometheus-2.37.6.linux-amd64/ssl/htpasswd;}}
因此grafana想从prometheus拉取数据从原先的9090变为8070,这样解决认证不生效的问题
重启nginx
nginx -s reload
访问http://ip:8070/
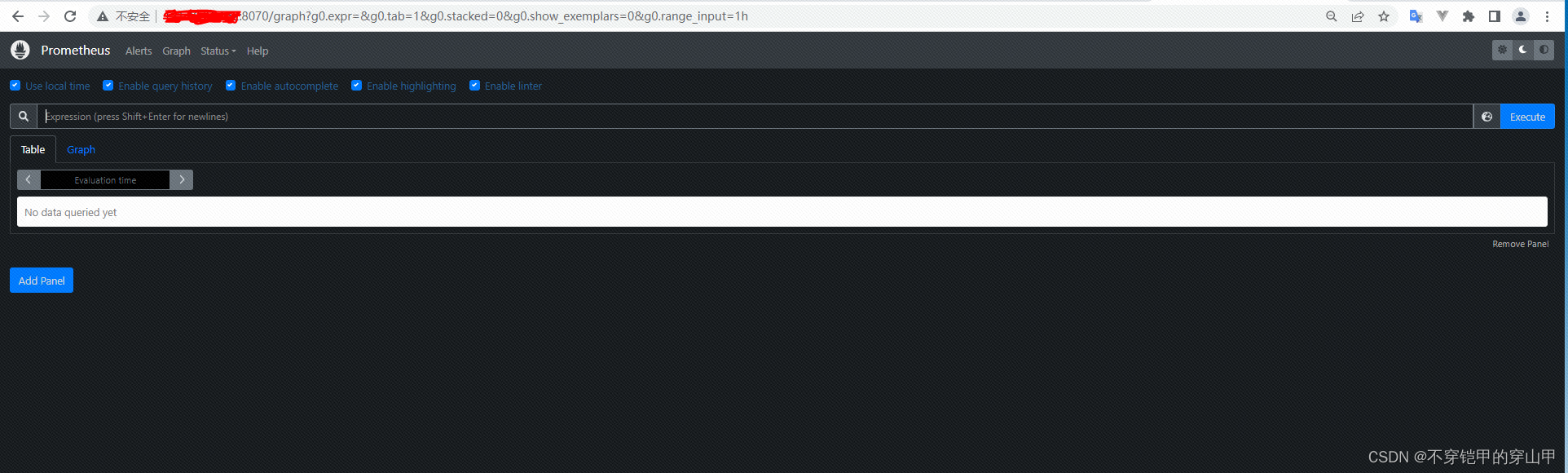
node_exportrt
简介
Prometheus是一款基于时序数据库的开源监控告警系统,它是SoundCloud公司开源的,SoundCloud的服务架构是微服务架构,他们开发了很多微服务,由于服务太多,传统的监控已经无法满足它的监控需求,于是他们在2012就着手开发新的监控系统。Prometheus的原作者Matt T. Proud在2012年加入SoundCloud公司,他之前服务于Google公司,他从google的监控系统Borgmon中获取灵感,与另外一名工程师Julius Volz合作开发了开源监控系统Prometheus。(总之感觉是因为有了这个前google工程师到来,才有能力开发了Prometheus)。后来其他开发人员陆续加入了这个项目,并在 SoundCloud 内部继续开发,最终于 2015 年 1 月将其发布。后来在2016年,SoundCloud把它捐献给了云原生基金会(Cloud Native Computing Foundation),在它下面继续孵化。
Prometheus是用go语言开发。它的很多理念跟google的SRE不谋而合。所以有时间,可以去看看google SRE那本书,可以更好的理解Prometheus。
特点
-
多维数据模型(时序由 metric 名字和 k/v 的labels构成)
-
灵活的查询语言(PromQL)
-
无依赖的分布式存储;单节点服务器都是自治的
-
采用 http 协议,使用pull模式拉取数据,简单易懂
-
监控目标,可以采用服务发现和静态配置方式
-
支持多种统计数据模型和界面展示。可以和Grafana结合展示。
下载和安装
进入工作目录
cd /opt/systemControl
下载
wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
解压
tar -zxvf node_exporter-1.3.1.linux-amd64.tar.gz
启动
nohup ./node_exporter --web.listen.address="0.0.0.0:9100" & 或nohup ./node_exporter --web.listen-address=":9100" &
granafa
简介
Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。目前使用grafana的公司有很多,如paypal、ebay、intel等。
特点
①可视化:快速和灵活的客户端图形具有多种选项。面板插件为许多不同的方式可视化指标和日志。
②报警:可视化地为最重要的指标定义警报规则。Grafana将持续评估它们,并发送通知。
③通知:警报更改状态时,它会发出通知。接收电子邮件通知。
④动态仪表盘:使用模板变量创建动态和可重用的仪表板,这些模板变量作为下拉菜单出现在仪表板顶部。
⑤混合数据源:在同一个图中混合不同的数据源!可以根据每个查询指定数据源。这甚至适用于自定义数据源。
⑥注释:注释来自不同数据源图表。将鼠标悬停在事件上可以显示完整的事件元数据和标记。
⑦过滤器:过滤器允许您动态创建新的键/值过滤器,这些过滤器将自动应用于使用该数据源的所有查询。
下载和安装
进入工作目录
cd /opt/systemControl
下载
wget https://repo.huaweicloud.com/grafana/8.4.7/grafana-enterprise-8.4.7.linux-amd64.tar.gz
解压
tar -zxvf grafana-enterprise-8.4.7.linux-amd64.tar.gz
配置文件账号和密码,
注意grafana启动先从配置文件中读取账号和密码信息存入到data目录下存入数据库,下载再启动即使修改了账号和密码但是数据库数据已经存在不会更新,解决办法:
1.第一次启动先改配置,再启动服务(本人使用)
cd /opt/systemControl/grafana-8.4.7/conf
vim defaults.ini

2.非第一次启动,删除data目录(会丢失接麦你已配置数据,需要重新配置),接着修改配置文件,再次启动服务
3.修改数据库
下载sqllite工具
yum install sqllite -y
修改密码
cd data #打开数据库 sqlite3 grafana.db #查看数据库中包含的表 .tables#查看user表内容 select * from user;#重置admin用户的密码为默认admin update user set password = '59acf18b94d7eb0694c61e60ce44c110c7a683ac6a8f09580d626f90f4a242000746579358d77dd9e570e83fa24faa88a8a6', salt = 'F3FAxVm33R' where login = 'admin';#退出sqlite3 .exit
好了,可以使用admin、admin登录了。
修改指定用户为管理员
udpate user set is_admin = 1 where login = 'xxxx';
启动
cd bin nohup ./grafana-server &
访问地址http://ip:3000/
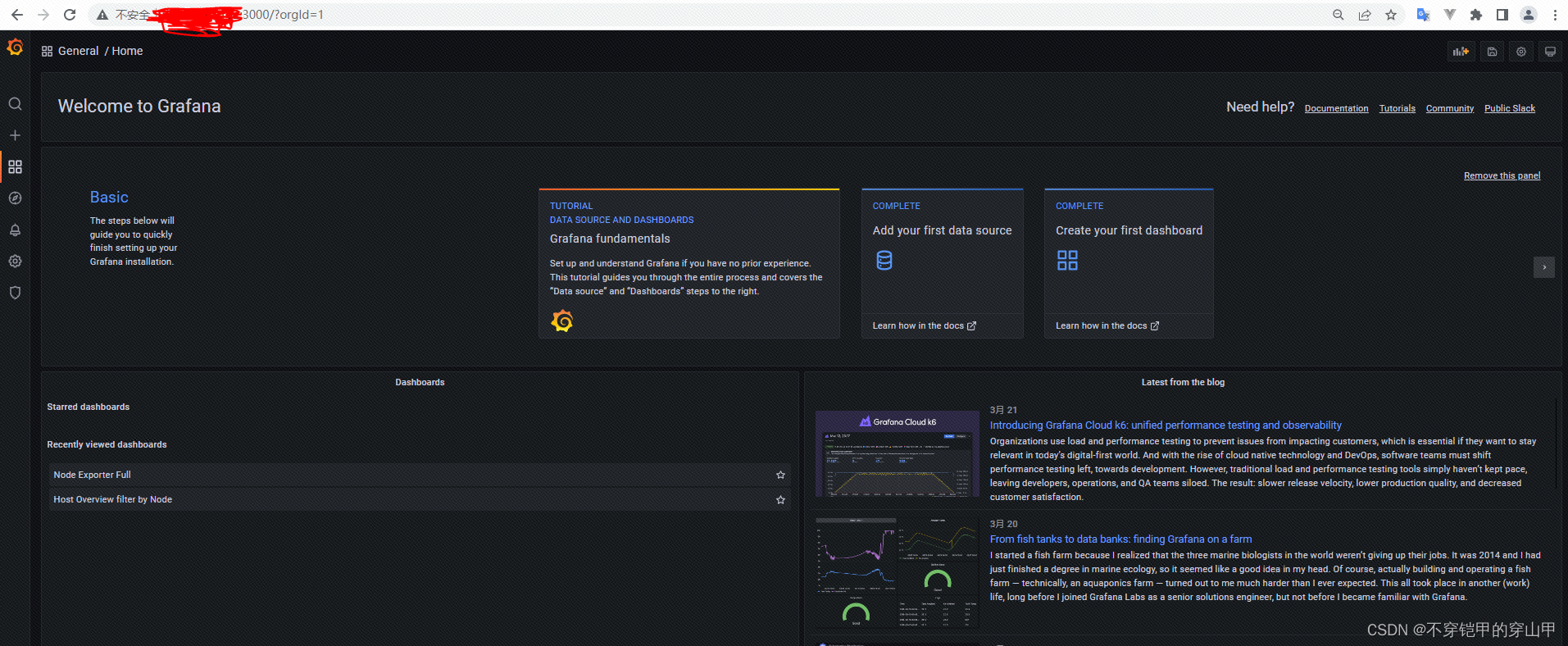
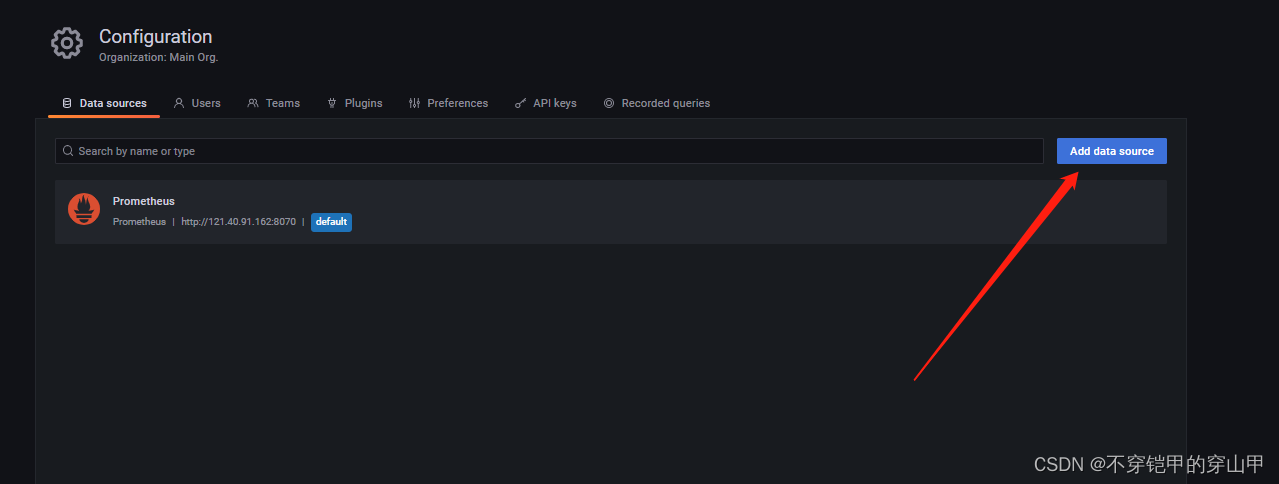
配置数据源
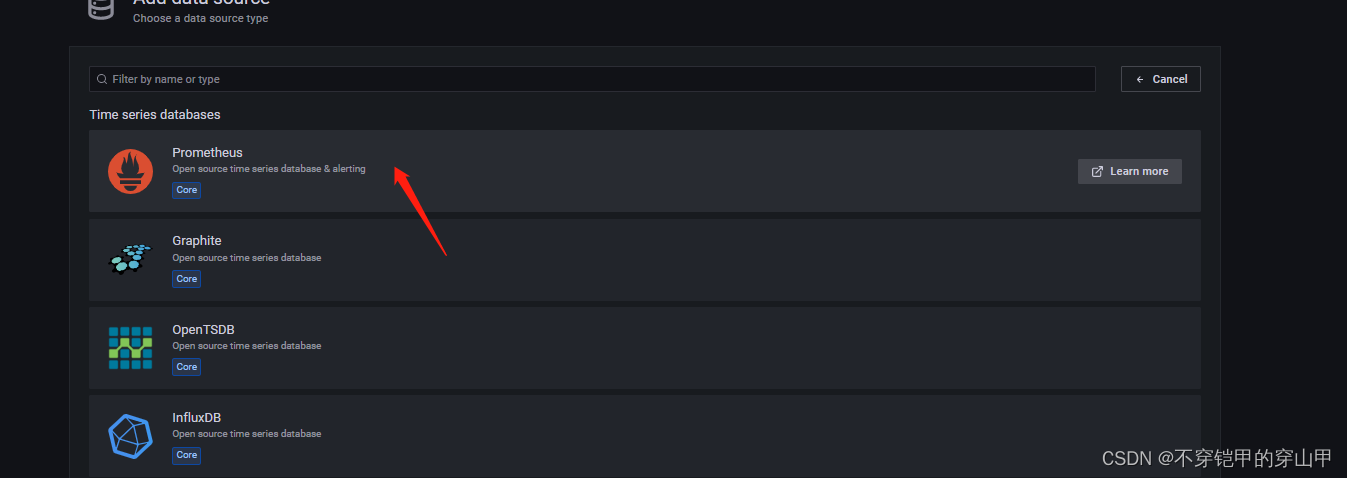
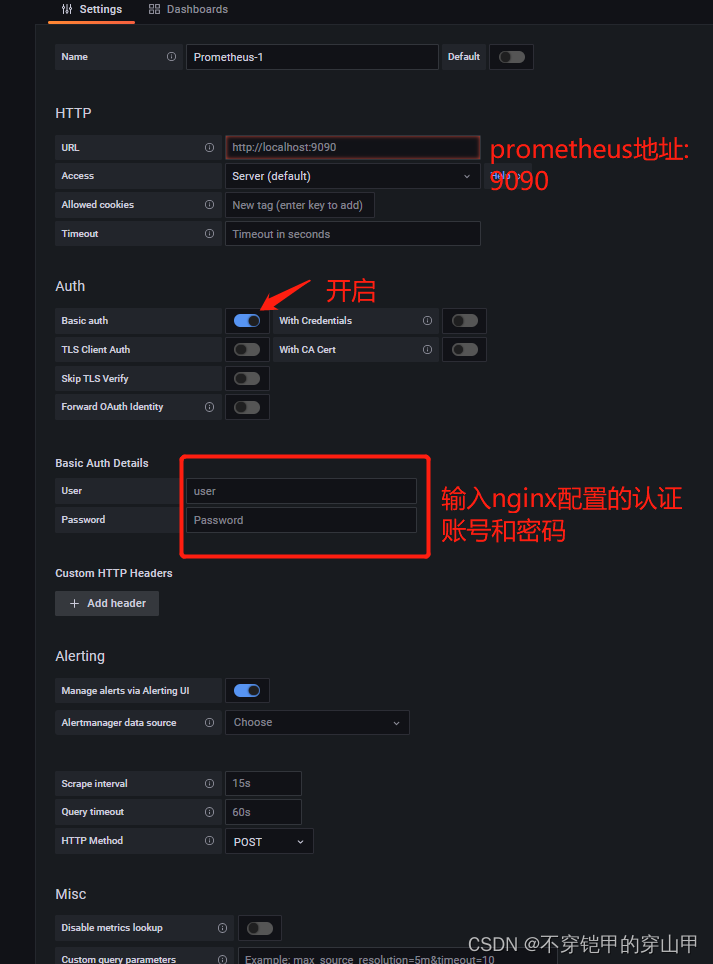
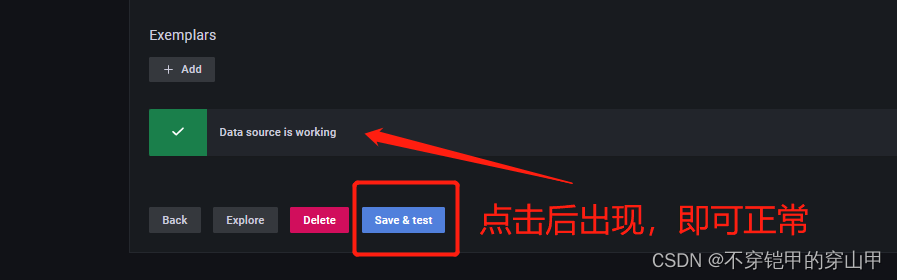
配置大盘模板


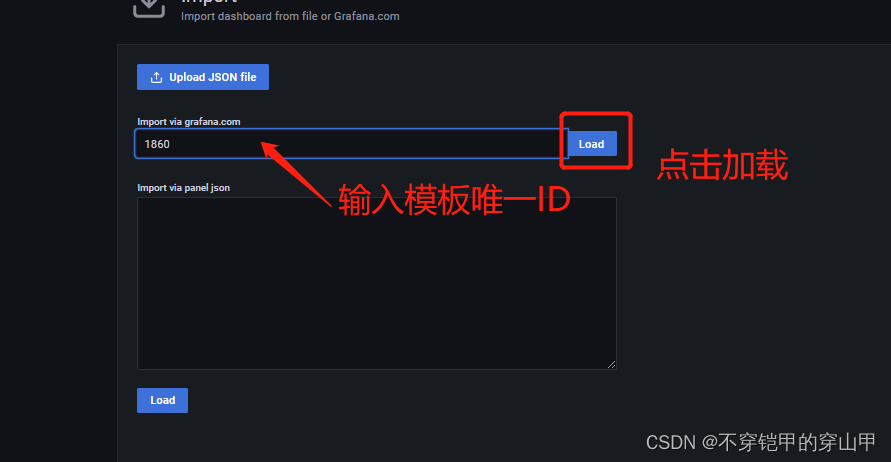
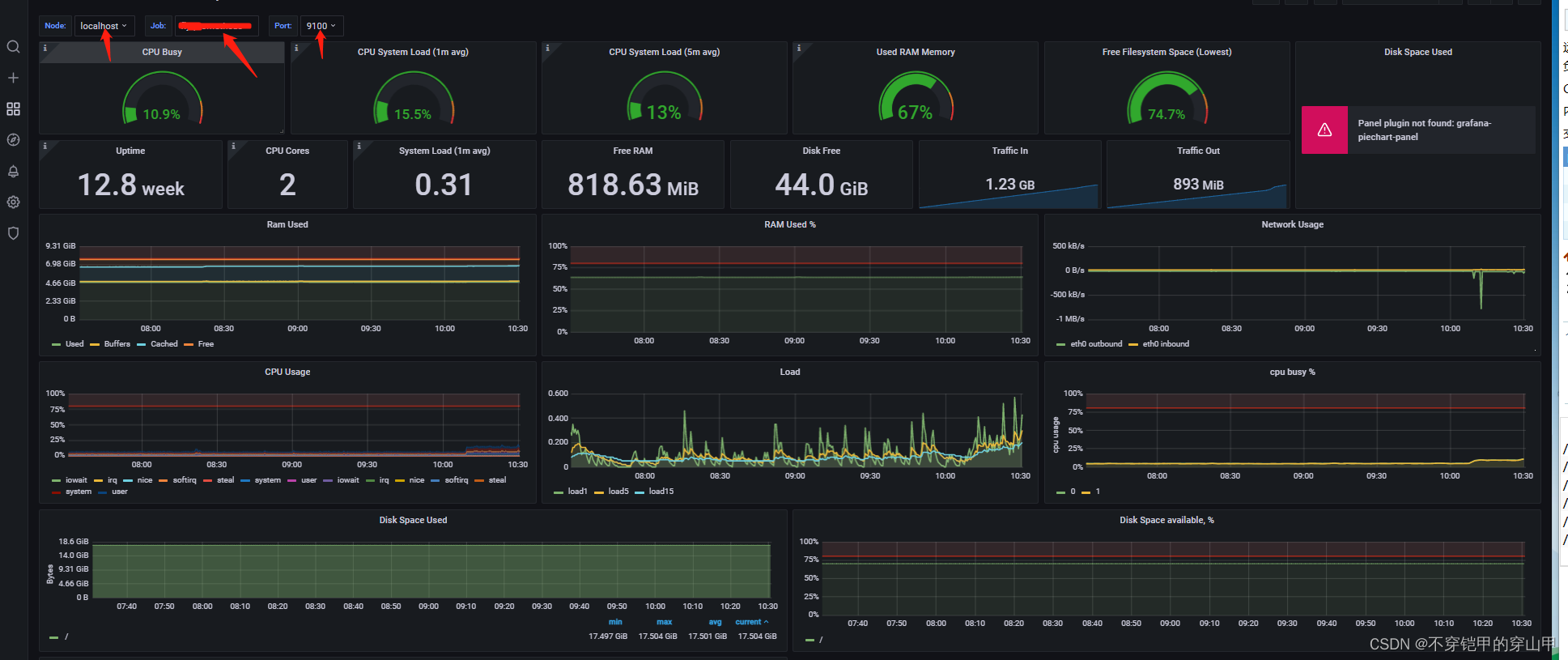
grafana官方模板库Dashboards | Grafana Labs
有些模板是不适合非k8s方式,可以多尝试几款。
Alertmanager
简介
Prometheus的报警功能主要是利用Alertmanager这个组件。当Alertmanager接收到 Prometheus 端发送过来的 Alerts 时,Alertmanager 会对 Alerts 进行去重复,分组,按标签内容发送不同报警组,包括:邮件,微信,webhook。
使用prometheus进行告警分为两部分:Prometheus Server中的告警规则会向Alertmanager发送。然后,Alertmanager管理这些告警,包括进行重复数据删除,分组和路由,以及告警的静默和抑制。
特点
Alertmanager除了提供基本的告警通知能力以外,还主要提供了如:分组、抑制以及静默等告警特性:
group(分组)
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
例如,当集群中有数百个正在运行的服务实例,并且为每一个实例设置了告警规则。假如此时发生了网络故障,可能导致大量的服务实例无法连接到数据库,结果就会有数百个告警被发送到Alertmanager。 而作为用户,可能只希望能够在一个通知中中就能查看哪些服务实例收到影响。这时可以按照服务所在集群或者告警名称对告警进行分组,而将这些告警内聚在一起成为一个通知。 告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置。
Inhibition(抑制)
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。 例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。 抑制机制同样通过Alertmanager的配置文件进行设置。
Silences(静默)
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。 静默设置需要在Alertmanager的Werb页面上进行设置。
下载和安装
进入工作目录
cd /opt/systemControl
下载
wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0 /alertmanager-0.24.0.linux-amd64.tar.gz
解压alertmanager-0.24.0.linux-amd64.tar.gz
tar -zxvf alertmanager-0.24.0.linux-amd64.tar.gz
alertmanager和prometheus的整合
prometheus
新增规则文件 servers_survival.yml
cd /systemControl/prometheus-2.37.6.linux-amd64 mkdir rules touch servers_survival.yml vim servers_survival.yml
servers_survival.yml文件内容如下:
groups:- name: servers_statusrules:- alert: CPU负载1分钟告警expr: node_load1{job!~"(nodes-dev-GPU|hw-nodes-test-server|hw-nodes-prod-ES|hw-nodes-prod-MQ)"} / count (count (node_cpu_seconds_total{job!~"(nodes-dev-GPU|hw-nodes-test-server|hw-nodes-prod-ES|hw-nodes-prod-MQ)"}) without (mode)) by (instance, job) > 2.5for: 1m labels:level: warningannotations:summary: "{{ $labels.instance }} CPU负载告警 "description: "{{$labels.instance}} 1分钟CPU负载(当前值: {{ $value }})"- alert: CPU使用率告警expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle",job!~"(IDC-GPU|hw-nodes-prod-ES|nodes-test-GPU|nodes-dev-GPU)"}[30m])) by (instance) > 0.85for: 1m labels:level: warningannotations:summary: "{{ $labels.instance }} CPU使用率告警 "description: "{{$labels.instance}} CPU使用率超过85%(当前值: {{ $value }} )"- alert: CPU使用率告警 expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle",job=~"(IDC-GPU|hw-nodes-prod-ES)"}[30m])) by (instance) > 0.9for: 1mlabels:level: warningannotations:summary: "{{ $labels.instance }} CPU负载告警 "description: "{{$labels.instance}} CPU使用率超过90%(当前值: {{ $value }})"- alert: 内存使用率告警expr: (1-node_memory_MemAvailable_bytes{job!="IDC-GPU"} / node_memory_MemTotal_bytes{job!="IDC-GPU"}) * 100 > 90labels:level: criticalannotations:summary: "{{ $labels.instance }} 可用内存不足告警"description: "{{$labels.instance}} 内存使用率已达90% (当前值: {{ $value }})"- alert: 磁盘使用率告警expr: 100 - (node_filesystem_avail_bytes{fstype=~"ext4|xfs", mountpoint !~ "/var/lib/[kubelet|rancher].*" } / node_filesystem_size_bytes{fstype=~"ext4|xfs", mountpoint !~ "/var/lib/[kubelet|rancher].*"}) * 100 > 85labels:level: warningannotations:summary: "{{ $labels.instance }} 磁盘使用率告警"description: "{{$labels.instance}} 磁盘使用率已超过85% (当前值: {{ $value }})"
prometheus修改prometheus.yml文件
alerting:alertmanagers:- static_configs:- targets:- 127.0.0.1:9093 #填写alertmanager服务地址rule_files:- "./rules/servers_survival.yaml" scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "fly-prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.basic_auth:username: adminpassword: xxxxxxstatic_configs:- targets: ["localhost:9100"]
重新启动prometheus
alertmanager
备份alertmanager .yml文件
cp alertmanager.yml alertmanager.yml.bak
vim alertmanager.yml
修改alertmanager.yml文件(比较详细的模板) ,想要webHook的往下看。
global:resolve_timeout: 5m# 整合qq邮件smtp_smarthost: 'smtp.qq.com:465'smtp_from: '1451578387@qq.com'smtp_auth_username: '1451578387@qq.com'smtp_auth_identity: 'xxxxxx'smtp_auth_password: 'xxxxxx'smtp_require_tls: false
route: #根路由,当子路由没有找到匹配则使用根路由进行转发group_by: ['alertname'] # 根据什么分组,此处配置的是根据告警的名字分组,没有指定 group_by 貌似是根据规则文件的 groups[n].name 来分组的。group_wait: 10s # 当产生一个新分组时,告警信息需要等到 group_wait 才可以发送出去。group_interval: 10s # 如果上次告警信息发送成功,此时又来了一个新的告警数据,则需要等待 group_interval 才可以发送出去repeat_interval: 120s # 如果上次告警信息发送成功,且问题没有解决,则等待 repeat_interval 再次发送告警数据receiver: 'email' # 告警的接收者,需要和 receivers[n].name 的值一致。routes: #子路由#匹配告警- matchers: #匹配标签- developer="dev1"#指定告警通道receiver: dev1Tunnel- matchers: #匹配标签- developer="dev2"receiver: defaultTunnel
receivers:
- name: 'email'email_configs:- to: '1451578387@qq.com'
- name: dev1Tunnelwechat_configs:- to_tag: 1#告警恢复,发送消息send_resolved: truemessage: '{{ template "wechat.message" . }}'agent_id: 1000001message_type: markdownapi_secret: API_SECRET- name: dev2Tunnelwechat_configs:- to_tag: 2send_resolved: truemessage: '{{ template "wechat.message" . }}'agent_id: 1000002message_type: markdownapi_secret: API_SECRET
告警抑制
指的是当某类告警产生的时候,于此相关的别的告警就不用发送告警信息了。
比如:我们对某台机器的CPU的使用率进行了监控,比如 使用到 80% 和 90% 都进行了监控,那么我们可能想如果CPU使用率达到了90%就不要发送80%的邮件了。
告警规则
如果 cpu 在5分钟的使用率超过 80% 则产生告警信息。
如果 cpu 在5分钟的使用率超过 90% 则产生告警信息。
groups:
- name: Cpurules:- alert: Cpu01expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 80"for: 1mlabels:severity: info # 自定一个一个标签 info 级别annotations:summary: "服务 {{ $labels.instance }} cpu 使用率过高"description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过去5分钟内使用过高,cpu 使用率 {{humanize $value}}."- alert: Cpu02expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 90"for: 1mlabels:severity: warning # 自定一个一个标签 warning 级别annotations:summary: "服务 {{ $labels.instance }} cpu 使用率过高"description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过去5分钟内使用过高,cpu 使用率 {{humanize $value}}."
alertmanager.yml 配置抑制规则
抑制规则:
如果 告警的名称 alertname = Cpu02 并且 告警级别 severity = warning ,那么抑制住 新的告警信息中 标签为 severity = info 的告警数据。并且源告警和目标告警数据的 instance 标签的值必须相等。
# 抑制规则,减少告警数据 inhibit_rules: - source_match: # 匹配当前告警规则后,抑制住target_match的告警规则alertname: Cpu02 # 标签的告警名称是 Cpu02severity: warning # 自定义的告警级别是 warningtarget_match: # 被抑制的告警规则severity: info # 抑制住的告警级别equal:- instance # source 和 target 告警数据中,instance的标签对应的值需要相等。
alertmanager.yml 简单配置用于测试(实操用的这个模板,webHook),由于无法直接调用企业微信群或者钉钉群的webHook链接,我们可以通过启用一个5000端口的python服务,使用python服务作为中间转发为我们去调用。
route:group_by: ['servers_status']group_wait: 30sgroup_interval: 5mrepeat_interval: 1hreceiver: 'web.hook' receivers:- name: 'web.hook'webhook_configs:- url: 'http://127.0.0.1:5000/' #回调请求路径 python服务器 #inhibit_rules:# - source_match:# severity: 'critical'# target_match:# severity: 'warning'# equal: ['alertname', 'dev', 'instance']
启动
nohup ./alertmanager --web.listen.address="0.0.0.0:9093"
python服务器
下载
#安装python3,centos7系统自带的是python2。 yum install -y python3 #安装需要的python的包 pip3 install requests pip3 install arrow pip3 install flask
进入工作空间
cd /opt/systemControl
创建python服务目录,并切入
mkdir pythonServer cd pythonServer
创建python文件
touch app.py
app.py文件内容:
# -*- coding: utf-8 -*-
import os
import json
import requests
import arrow
from flask import Flask
from flask import request
app = Flask(__name__)
def bytes2json(data_bytes):data = data_bytes.decode('utf8').replace("'", '"')return json.loads(data)
def makealertdata(data):for output in data['alerts'][:]:try:pod_name = output['labels']['pod']except KeyError:try:pod_name = output['labels']['pod_name']except KeyError:pod_name = 'null'try:namespace = output['labels']['namespace']except KeyError:namespace = 'null'try:message = output['annotations']['message']except KeyError:try:message = output['annotations']['description']except KeyError:message = 'null'print(output)if output['status'] == 'firing':status_zh = '报警'title = '【%s】xxxx环境 %s 有新的报警' % (status_zh, output['labels']['alertname'])send_data = {"msgtype": "markdown","markdown": {"content": "## %s \n\n" %title +">**告警级别**: %s \n\n" % output['labels']['level'] +">**告警类型**: %s \n\n" % output['labels']['alertname'] +">**告警主机**: %s \n\n" % output['labels']['instance'] +">**告警详情**: %s \n\n" % output['annotations']['description'] +">**触发时间**: %s \n\n" % arrow.get(output['startsAt']).to('Asia/Shanghai').format('YYYY-MM-DD HH:mm:ss ZZ')}}elif output['status'] == 'resolved':status_zh = '恢复'title = '【%s】xxxx环境 %s 有报警恢复' % (status_zh, output['labels']['alertname'])send_data = {"msgtype": "markdown","markdown": {"content": "## %s \n\n" %title +">**告警级别**: %s \n\n" % output['labels']['level'] +">**告警类型**: %s \n\n" % output['labels']['alertname'] +">**告警主机**: %s \n\n" % output['labels']['instance'] +">**告警详情**: %s \n\n" % output['annotations']['description'] +">**触发时间**: %s \n\n" % arrow.get(output['startsAt']).to('Asia/Shanghai').format('YYYY-MM-DD HH:mm:ss ZZ') +">**触发结束时间**: %s \n" % arrow.get(output['endsAt']).to('Asia/Shanghai').format('YYYY-MM-DD HH:mm:ss ZZ')}}return send_data
def send_alert(data):#此处获取环境变量“ROBOT_TOKEN”,会在docker-compose的配置文件中配置,docker-compose启动docker时向docker容器注入环境变量#print(data)token = os.getenv('ROBOT_TOKEN')#if not token:# print('you must set ROBOT_TOKEN env')# return#url = 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=%s' % tokenurl = 'webhookUrl' #钩子URLsend_data = makealertdata(data)print(send_data)req = requests.post(url, json=send_data)print(req)result = req.json()if result['errcode'] != 0:print('notify dingtalk error: %s' % result['errcode'])
@app.route('/', methods=['POST', 'GET'])
def send():if request.method == 'POST':post_data = request.get_data()#print(post_data)send_alert(bytes2json(post_data))return 'success'else:return 'weclome to use prometheus alertmanager dingtalk webhook server!'if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
启动
nohup python3 app.py &
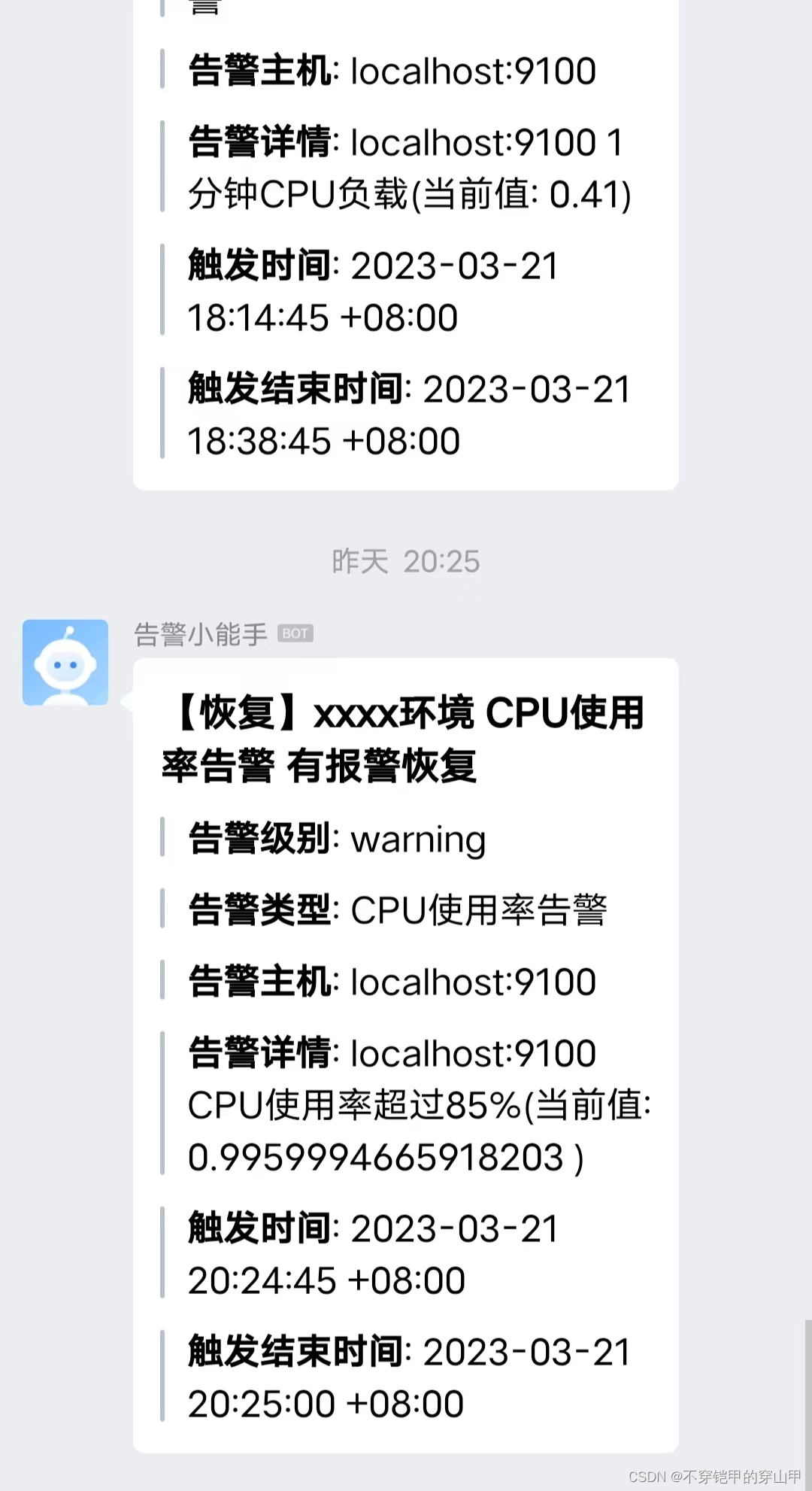
千万不要放弃,人生就是这样。
这篇关于Prometheus+Grafana+Node-exporter+Alertmanager+Python3+Nginx搭建大盘监控以及告警提醒的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



