本文主要是介绍分布式高性能缓存Hazelcast 概览,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一. Hazelcast
1. Hazelcast简介
Hazelcast 是由Hazelcast公司开发的一款开源的分布式内存级别的缓存数据库,可以为基于JVM环境运行的各种应用提供分布式集群和分布式缓存服务。
利用Hazelcast可以满足“分布式”、“集群服务”、“网格式内存数据”、“分布式缓存“、“弹性可伸缩服务”等的要求。
2. Hazelcast的应用
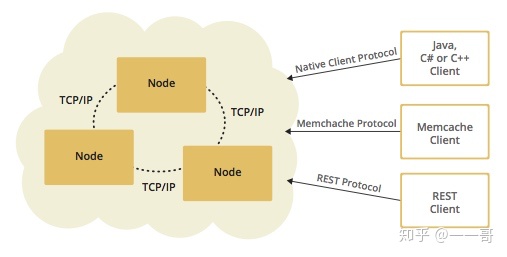
Hazelcast提供了对很多 Java 接口的分布式实现,如Map, Queue, ExecutorService, Lock以及 JCache。它以一个 JAR 包的形式提供服务,并且提供了 Java, C/C++, .NET 以及 REST 客户端。
在应用时,可以将Hazelcast的jar包直接嵌入到任何使用Java、C++、.NET开发的产品中,我们只需要在应用中引入一个jar包,进行简单的配置和编码就可以实现。
目前Hazelcast已经更新到4.X版本。
3. Hazelcast版本区别
Hazelcast 分为开源版和商用版,开源版本遵循 Apache License 2.0 开源协议可以免费使用,商用版本需要获取特定的License。两者之间最大的区别在于:商用版本提供了数据的高密度存储。
我们知道在JVM中,有自己特定的GC机制,无论数据是在堆中还是栈中,只要发现无效引用的数据块,就有可能被回收。而Hazelcast的分布式数据都存放在JVM的内存中,频繁的读写数据会导致大量的GC开销。使用商业版的Hazelcast会拥有高密度存储的特性,大大降低JVM的内存开销,从而降低GC开销。
3. Hazelcast的特性
3.1 自治集群(无中心化)
Hazelcast 没有任何中心节点(每个节点都是可以运行在任意服务器的独立JVM),在运行的过程中,它自己选定集群中的某个节点作为中心点来管理所有的节点。
3.2 数据按应用分布式存储
Hazelcast 的数据是分布式存储的。它会尽量将数据存储在需要使用该项数据的节点上,以实现数据去中心化的目的。
在传统的数据存储模型中(MySql、MongDB、Redis等),数据都是独立于应用单独存放的,当需要提升数据库的性能时,需要不断加固单个数据库应用的性能。
即使现在大量的数据库已经可以支持集群模式或读写分离,但是基本思路都是某几个库支持写入数据,其他的库不断的拷贝更新数据副本。这样做的坏处一是会产生大量脏读的问题,二是会消耗大量的资源来传递数据——从数据源频繁读写数据会耗费额外资源,当数据量增长或创建的主从服务越来越多时,这个消耗呈指数级增长。
使用 Hazelcast 可以有效的解决数据中心化问题,它将数据分散的存储在每个节点中,节点越多越分散。每个节点都有各自的应用服务,而Hazelcast集群会根据每个应用的数据使用情况分散存储这些数据,在应用过程中数据会尽量“靠近”应用存放。这些在集群中的数据共享整个集群的存储空间和计算资源。
3.3 抗单点故障
集群中的节点是无中心化的,每个节点都有可能随时退出或随时进入。因此,在集群中存储的数据都会有一个备份(可以配置备份的个数,也可以关闭数据备份)。这样的方式有点类似于 hadoop,某项数据存放在一个节点时,在其他节点必定有至少一个备份存在。当某个节点退出时,节点上存放的数据会由备份数据替代,而集群会重新创建新的备份数据。
3.4 简单易用
Hazelcast 的所有功能只需引用一个jar包,除此之外,它不需要依赖任何第三方包。因此可以非常便捷高效的将其嵌入到各种应用服务器中,而不必担心带来额外的问题(jar包冲突、类型冲突等)。它仅仅提供一系列分布式功能,而不需要绑定任何框架来使用,因此适用于任何场景。
3.5 其他特性
Hazelcast 还支持服务器/客户端模型,支持脚本管理、能够和 Docker 快速整合等。
4. Hazelcast功能
- 提供了分布式id生成器(IdGenerator);
- 提供了分布式事件驱动(Distributed Events);
- 提供了分布式计算(Distributed Computing);
- 提供了分布式查询(Distributed Query)。
- 提供java.util.{Queue, Set, List, Map}分布式实现。
- 提供java.util.concurrency.locks.Lock分布式实现。
- 提供java.util.concurrent.ExecutorService分布式实现。
- 提供用于一对多关系的分布式MultiMap。
- 提供用于发布/订阅的分布式Topic(主题)。
- 通过JCA与J2EE容器集成和事务支持。
- 提供用于安全集群的Socket层加密。
- 支持同步和异步持久化。
- 为Hibernate提供二级缓存Provider 。
- 通过JMX监控和管理集群。
- 支持动态HTTP Session集群。
- 利用备份实现动态分割。
- 支持动态故障恢复。
总的来说在独立JVM中经常使用的数据结果或模型,Hazelcast 都提供了分布式集群的实现。
5. Hazelcast原理
Hazelcast 提供了 Map、Queue、MultiMap、Set、List、Semaphore、Atomic 等常用接口的分布式实现。以Map接口为例,当我们通过Hazelcast创建一个Map实例后,我们在节点A调用 Map::put("A","A_DATA") 方法添加数据,然后可以在节点B使用 Map::get("A") 获取到值为"A_DATA" 的数据。
6. Hazelcast存储数据的实现过程
6.1 Hazelcast分区
由于Hazelcast 服务之间是端对端的,没有主从之分,集群中所有的节点都存储等量的数据以及进行等量的计算。
Hazelcast 默认情况下把数据存储在 271 个区上,这个值可以通过系统属性 hazelcast.partition.count来配置。
6.2 Hazelcast分区存储原理
对于一个给定的键,在经过序列化、哈希并对分区总数取模之后能得到此键对应的分区号,所有的分区等量的分布与集群中所有的节点中,每个分区对应的备份也同样分布在集群中。
也就是说 Hazelcast 会使用哈希算法对数据进行分区,比如对于一个给定的map中的键,或者topic和list中的对象名称,分区存储的过程如下:
- 先序列化此键或对象名称,得到一个byte数组;
- 然后对上面得到的byte数组进行哈希运算;
- 再进行取模后的值即为分区号;
- 最后每个节点维护一个分区表,存储着分区号与节点之间的对应关系,这样每个节点都知道如何获取数据。
6.3 Hazelcast集群实现原理
Hazelcast通过分片来存储和管理所有进入集群的数据,采用分片的方案目标是保证数据可以快速被读写、通过冗余保证数据不会因节点退出而丢失、节点可线性扩展存储能力。下面将从理论上说明Hazelcast是如何进行分片管理的。
6.3.1 分片
Hazelcast的每个数据分片(shards)被称为一个分区(Partitions)。分区是一些内存段,根据系统内存容量的不同,每个这样的内存段都包含了几百到几千项数据条目,默认情况下,Hazelcast会把数据划分为271个分区,并且每个分区都有一个备份副本。当启动一个集群成员时,这271个分区将会一起被启动。
下图展示了集群只有一个节点时的分区情况。
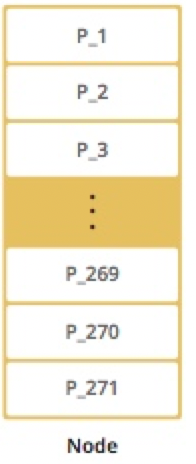
从一个节点的分区情况可以看出,当只启动一个节点时,所有的271个分区都存放在一个节点中。
然后我们启动第二个节点,会出现下面这样的集群分区方式。
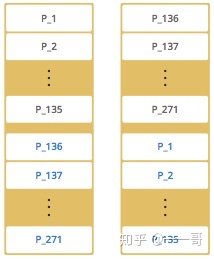
其中黑色的字体表示分区,蓝色的字体表示备份。节点1存储了标号为1到135的分区,这些分区会同时备份到节点2中。而节点2则存储了136到271的分区,并备份到了节点1中。
此时如果再添加2个新的节点到集群中,Hazelcast会一个一个的移动分区和备份到新的节点中,使得集群数据分布平衡。
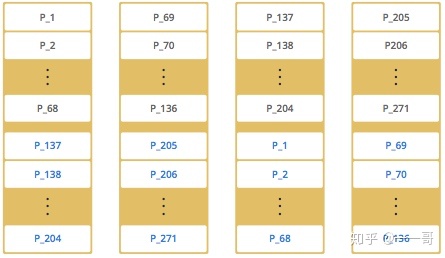
注意:
实际中分区并不是有序的分布,而是随机分布,上面的示例只是为了方便理解,重要的是理解 Hazelcast 的平均分布分区以及备份。
6.4 重分区
集群中最老的节点(或者说最先启动)负责定时发送分区表到其他节点,这样如果有其他节点加入或者离开集群,所有的节点也能更新分区表。
这个定时任务时间间隔可以通过系统属性 hazelcast.partition.table.send.interval来配置,缺省值为15秒。
重分区会发生在:
- 节点加入集群;
- 节点离开集群。
此时最老节点会更新分区表,然后分发,再接着集群开始移动分区,或者从备份恢复分区。
注意:
如果最老的节点挂了,次老节点会接手这个任务。
7. Hazelcast的使用方式
有两种方式,嵌入式和客户端服务器。
- 嵌入式: Hazelcast 服务器的 jar 包被导入到宿主应用程序中,服务器启动后缓存数据会被存在于各个宿主应用中,优点是可以更低延迟的数据访问。
- 客户端服务器: Hazelcast 客户端的 jar 包被导入宿主应用程序中,服务器 jar 包独立运行于 JVM 中。优点是更容易调试以及有更可靠的性能,最重要的是有更好的扩展性。
转自:知乎一一哥
这篇关于分布式高性能缓存Hazelcast 概览的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








