本文主要是介绍[源码解析] 快手八卦 --- 机器学习分布式训练新思路(3),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[源码解析] 快手八卦 — 机器学习分布式训练新思路(3)
文章目录
- [源码解析] 快手八卦 --- 机器学习分布式训练新思路(3)
- 0x00 摘要
- 0x02 去中心化
- 2.1 示例用法
- 2.2 去中心化培训概述
- 2.3 去中心化训练算法
- 2.4 Decentralized SGD
- 2.5 通信开销
- 2.6 分析
- 2.6.1 DecentralizedAlgorithmImpl
- 2.6.1.1 定义
- 2.6.1.2 初始化状态
- 2.6.1.3 初始化操作
- 2.6.1.4 Post操作
- 2.6.2 BaguaBucket
- 2.6.2.1 append_decentralized_synchronous_op
- 2.6.2.2 BaguaBucket
- 2.6.2.3 DecentralizedFullPrecisionSynchronous
- 2.6.2.3.1 发送
- 2.6.2.3.2 拷贝回来
- 0x03 异步
- 3.1 示例用法
- 3.2 异步模型平均
- 3.3 算法
- 3.4 分析
- 3.4.1 异步通信实现
- 3.4.2 初始化操作
- 3.4.3 加锁解锁
- 3.4.4 计算线程
- 3.4.4.1 前向传播
- 3.4.4.2 后向传播
- 3.4.5 通信线程
- 3.4.5.1通知后端
- Python
- Rust
- 3.4.5.2 归并
- Python
- Rust
- 0xEE 个人信息
- 0xFF 参考
0x00 摘要
“Bagua“ 是快手和苏黎世理工(ETH Zürich)联合开发的分布式训练框架。其专门针对分布式的场景设计特定的优化算法,实现算法和系统层面的联合优化,力图极致化分布式训练的效率。其特点是:
-
并行性能显著提高;
-
对网络环境更鲁棒;
-
“一键式”使用;
-
分布式通讯算法易拓展性;
-
可用于工业级场景大规模使用;
-
安全、故障易排查;
本文以:
- 快手官方公共号文章 快手八卦!突破 TensorFlow、PyTorch 并行瓶颈的开源分布式训练框架来了!
- “bagua"论文 https://arxiv.org/pdf/2107.01499.pdf
- “bagua"官方网站 https://tutorials.baguasys.com/
- “bagua" 演示文档
- 项目 GitHub 地址:https://github.com/BaguaSys/bagua
为基础来分析学习。本文介绍去中心化和异步通信。
本系列前两篇文章是:
[源码解析] 快手八卦 — 机器学习分布式训练新思路(1)
[源码解析] 快手八卦 — 机器学习分布式训练新思路(2)
0x02 去中心化
官方文章中是这样介绍其设计思路的:
- 中心化或是去中心化(Centralized or Decentralized):在中心化的通讯模式中,梯度或模型的同步过程需要所有的工作节点进行参与,因此,较高的网络延时往往会导致训练效率的降低。去中心化的通信模式 往往可以有效的解决这一问题:在该模式下,工作节点可以被连接成特定的拓扑结构(例如环),在通信过程中,每一个工作节点只与和它相邻的节点进行通信。
以下结合 https://tutorials.baguasys.com/algorithms/decentralized 来学习。
2.1 示例用法
用户可以在源码之中找到运行去中心化 SGD 的完整示例,这里只是简单介绍。
您需要初始化八卦算法:
from bagua.torch_api.algorithms import decentralized
algorithm = decentralized.DecentralizedAlgorithm()
然后用以下方法装饰您的模型:
model = model.with_bagua([optimizer], algorithm)
2.2 去中心化培训概述
Decentralized SGD 是一种数据并行的分布式学习算法,它消除了所有 worker 之间必有存在一个集中式全局模型的需求,这使得它在通信模式上与基于 Allreduce 或基于参数服务器的算法有很大不同。使用去中心化 SGD,每个 worker 只需要与一个或几个特定的 worker 交换数据,而不是全局聚合数据。因此,去中心化通信的通信连接数比 Allreduce 少得多,通信开销比 Parameter Server 更均衡。尽管去中心化 SGD 可能会导致每个 worker 的模型不同,但理论上已经证明,去中心化 SGD 算法的收敛速度与其对应中心化版本相同。
2.3 去中心化训练算法
目前,不时有许多去中心化训练算法被提出。这些令人惊叹的工作集中在去中心化训练的不同方面,如对等选择(peer selection)、数据压缩、异步等,并提供了许多远见。到目前为止,八卦已经结合了两种基本的去中心化算法,即去中心化 SGD和 低精度去中心化 SGD。凭借八卦对去中心化的自动系统支持,我们预计在不久的将来会实现越来越多的去中心化算法。
2.4 Decentralized SGD
现在我们将描述在八卦中实现的 Decentralized SGD 算法。让我们假设worker 的数量是 n,worker上的模型参数 是:
x ( i ) , i ∈ { 0 , . . . , n − 1 } x^{(i)} ,i∈ \{0,...,n−1\} x(i),i∈{0,...,n−1}
每个工作人员都能够直接从任何其他工作人员发送或接收数据。在每次迭代 t 中,算法重复以下步骤:
-
迭代t 之中,每个worker 计算本地梯度 g t ( t ) g^{(t)}_t gt(t)
-
将本地模型与其选定的对等模型做平均:
x t + 1 2 ( i ) = x t ( i ) + x t ( j ) 2 x_{t+\frac{1}{2}}^{(i)} = \frac{x^{(i)}_{t} + x_t^{(j)}}{2} xt+21(i)=2xt(i)+xt(j) -
用局部梯度更新平均模型
X t + 1 ( i ) = X t + 1 2 ( i ) − γ g t ( i ) X^{(i)}_{t+1} = X^{(i)}_{t+\frac{1}{2}} - γg_t^{(i)} Xt+1(i)=Xt+21(i)−γgt(i)
在第 2 步中,我们采用一种策略为每次迭代中的每个 worker 选择一个 peer,这样所有 worker 都正确配对并且数据交换是有效的,因为每个 worker 可以在迭代之间与不同的 peer 交换数据。简而言之,我们的策略将工作人员平均分成两组,并在两组之间动态配对 worker,每次迭代都不同。
2.5 通信开销
去中心化 SGD 的通信开销与网络程度(degree of network)高度相关,即一个 worker 与其他 worker 的连接数。不同的拓扑或策略会导致不同程度的网络。很明显,我们之前描述的Decentralized SGD算法的网络度为1。因此,在每次迭代中,一个worker只需要与一个worker建立一个连接来交换模型大小1倍的数据。我们比较了不同通信模式在最繁忙节点延迟和带宽方面的通信复杂性。
| 算法 | 延迟复杂度 | 带宽复杂度 |
|---|---|---|
| Allreduce(环) | O(n) | O(1) |
| 参数服务器 | O(1) | O(n) |
| 八卦的Decentralized SGD | O(1) | O(1) |
2.6 分析
前面官方教程之中,这部分是关键:
在第 2 步中,我们采用一种策略为每次迭代中的每个 worker 选择一个 peer,这样所有 worker 都正确配对并且数据交换是有效的,因为每个 worker 可以在迭代之间与不同的 peer 交换数据。简而言之,我们的策略将工作人员平均分成两组,并在两组之间动态配对 worker,每次迭代都不同。
我们就以此出发来进行分析学习。
2.6.1 DecentralizedAlgorithmImpl
2.6.1.1 定义
参数 peer_selection_mode 可以有两种选择:
all表示在每个通信步骤中平均所有worker的权重。shift_one是指每个 worker 在每个通信步骤中选择一个不同的对等点进行权重平均。
class DecentralizedAlgorithmImpl(AlgorithmImpl):def __init__(self,process_group: BaguaProcessGroup,hierarchical: bool = True,peer_selection_mode: str = "all",communication_interval: int = 1,):"""Implementation of the`Decentralized SGD <https://tutorials.baguasys.com/algorithms/decentralized>`_algorithm.Args:process_group (BaguaProcessGroup): The process group to work on.hierarchical (bool): Enable hierarchical communication.peer_selection_mode (str): Can be ``"all"`` or ``"shift_one"``. ``"all"`` means all workers'weights are averaged in each communication step. ``"shift_one"`` means each workerselects a different peer to do weights average in each communication step.communication_interval (int): Number of iterations between two communication steps."""super(DecentralizedAlgorithmImpl, self).__init__(process_group)self.hierarchical = hierarchicalself.peer_selection_mode = peer_selection_modeself.communication_interval = communication_intervalself.cuda_event = torch.cuda.Event()
2.6.1.2 初始化状态
_init_states 方法把权重张量初始化到 bucket._peer_weight。
提一下,LowPrecisionDecentralizedAlgorithmImpl 是初始化了左右两个 peer_weight,因为精力所限,本文不对其进行分析,有兴趣的读者可以自行深入。
def _init_states(self, bucket: BaguaBucket):weight_tensor = bucket.flattened_tensor()bucket._peer_weight = weight_tensor.to_bagua_tensor("peer_weight")
2.6.1.3 初始化操作
init_operations 使用 append_decentralized_synchronous_op 配置了 bucket 的 _decentralized_op 成员变量。
def init_operations(self,bagua_module: BaguaModule,bucket: BaguaBucket,
):self._init_states(bucket)torch.cuda.synchronize()bucket.clear_ops()decentralized_op = bucket.append_decentralized_synchronous_op( # 配置成员变量peer_weight=bucket._peer_weight,hierarchical=self.hierarchical,peer_selection_mode=self.peer_selection_mode,group=self.process_group,)bucket._decentralized_op = decentralized_op
2.6.1.4 Post操作
init_post_backward_hook 注册了 post hook 操作,会把去中心化平均的结果拷贝回来,后面会在进行细化分析。
def init_post_backward_hook(self, bagua_module: BaguaModule):def hook():if self._should_communicate(bagua_module):bagua_module._bagua_backend.wait_pending_comm_ops()torch.cuda.current_stream().record_event(self.cuda_event)self.cuda_event.synchronize()for bucket in bagua_module.bagua_buckets:bucket._decentralized_op.copy_back_peer_weight( # 拷贝回来bucket.backend_bucket)return hook
算法如下,append_decentralized_synchronous_op 用来通信,init_post_backward_hook 把去中心化平均的结果拷贝回来。
+--------------------------------------------------------------------+
|DecentralizedAlgorithmImpl |
| |
| process_group |
| |
| decentralized_op = bucket.append_decentralized_synchronous_op |
| |
| peer_selection_mode |
| |
| init_post_backward_hook |
| |
+--------------------------------------------------------------------+
2.6.2 BaguaBucket
我们接下来进入 BaguaBucket,其是聚集了一系列 Bagua 张量,其最终调用 backend_bucket 进行处理,就是 rust 的 BaguaBucketPy。
class BaguaBucket:def __init__(self, tensors: List[BaguaTensor], name: str, flatten: bool, alignment: int = 1) -> None:"""Create a Bagua bucket with a list of Bagua tensors."""self.tensors = tensors"""The tensors contained within the bucket."""self.bagua_module_name = tensors[0].bagua_module_nameself._bagua_backend = get_backend(self.bagua_module_name)self.name = name"""The bucket's name."""self.padding_tensor = Noneif alignment > 1:padding = sum(tensor.numel() for tensor in self.tensors) % alignmentif padding > 0:padding = alignment - paddingself.padding_tensor = torch.zeros(padding, dtype=self.tensors[0].dtype, device=self.tensors[0].device).to_bagua_tensor("bagua_padding_tensor_bucket_" + name)self._all_tensors = (self.tensors + [self.padding_tensor]if self.padding_tensor is not Noneelse self.tensors)self.backend_tensor = Noneself.flatten = flattenif self.flatten:self._flatten_()torch.cuda.empty_cache()self.backend_bucket = B.BaguaBucketPy( # 底层实现name, [tensor._bagua_backend_tensor for tensor in self._all_tensors])for tensor in self._all_tensors:tensor._bagua_bucket = self
2.6.2.1 append_decentralized_synchronous_op
append_decentralized_synchronous_op 是往桶添加了操作,当bucket中的所有张量都标记为ready时,该操作将由Bagua后端按照附加顺序执行。参数 peer_weight 的意义是用于与对等模型求平均值的张量,应与桶张量的总大小相同。
append_decentralized_synchronous_op 不是 inplace 操作,这意味着桶权重首先复制到peer_weight,去中心化平均的结果放置在 peer_weight,然后使用op.copy_back_peer_weight(self) 将结果再拷贝回来。具体在前面 init_post_backward_hook 之中有拷贝回来的操作。
我们还可以注意到,如果采取了 hierarchical 模式,则传入了 inter, intra 两种communicator。
def append_decentralized_synchronous_op(self,peer_weight: BaguaTensor,hierarchical: bool = True,peer_selection_mode: str = "all",group: Optional[BaguaProcessGroup] = None,
):"""Append a decentralized synchronous operation to a bucket. It will do gossipy style model averaging among workers."""if group is None:group = _get_default_group()if hierarchical:return self.backend_bucket.append_decentralized_synchronous_op(_bagua_backend_comm(group.get_inter_node_communicator()),_bagua_backend_comm(group.get_intra_node_communicator()),hierarchical=hierarchical,peer_selection_mode=peer_selection_mode,peer_weight=peer_weight._bagua_backend_tensor,)else:return self.backend_bucket.append_decentralized_synchronous_op(_bagua_backend_comm(group.get_global_communicator()),None,hierarchical=hierarchical,peer_selection_mode=peer_selection_mode,peer_weight=peer_weight._bagua_backend_tensor,)
2.6.2.2 BaguaBucket
我们来到了 Rust 世界,BaguaBucket 的 append_decentralized_synchronous_op 操作之中,如果是 “all” 或者 “shift_one”,则会调用 DecentralizedFullPrecisionSynchronous。
pub fn append_decentralized_synchronous_op(&mut self,communicator_internode: Option<&BaguaSingleCommunicator>,communicator_intranode: Option<&BaguaSingleCommunicator>,hierarchical: bool,peer_selection_mode: String,peer_weight: BaguaTensor,
) -> Arc<DecentralizedFullPrecisionSynchronous> {let communicator =BaguaCommunicator::new(communicator_internode, communicator_intranode, hierarchical).expect("cannot create communicator");let comm_op = Arc::new(DecentralizedFullPrecisionSynchronous {communicator,peer_selection_mode: match peer_selection_mode.as_str() {"all" => PeerSelectionMode::All,"shift_one" => PeerSelectionMode::ShiftOne,&_ => {unimplemented!("unsupported peer_selection_mode for decentralized algorithm (should be `all` or `shift_one`)")}},step: Default::default(),peer_weight,});self.inner.lock().comm_ops.push(comm_op.clone() as Arc<dyn CommOpTrait + Send + Sync>);comm_op
}
2.6.2.3 DecentralizedFullPrecisionSynchronous
DecentralizedFullPrecisionSynchronous 位于 rust/bagua-core/bagua-core-internal/src/comm_ops/decentralized_full_precision_synchronous.rs 之中。
其定义如下:
pub struct DecentralizedFullPrecisionSynchronous {pub communicator: BaguaCommunicator,pub peer_selection_mode: PeerSelectionMode,pub step: Mutex<usize>,pub peer_weight: BaguaTensor,
}
2.6.2.3.1 发送
再回忆一下官方思路。
在第 2 步中,我们采用一种策略为每次迭代中的每个 worker 选择一个 peer,这样所有 worker 都正确配对并且数据交换是有效的,因为每个 worker 可以在迭代之间与不同的 peer 交换数据。简而言之,我们的策略将工作人员平均分成两组,并在两组之间动态配对 worker,每次迭代都不同。
具体就是通过下面代码实现的。关键点在函数的最后一句,通过调整step, 计算出下一个peer,这样每次peer都不同。
// 计算出下一个peer,关键点在函数的最后一句,通过调整step,每次peer都不同let peer_rank = if c.rank < c.nranks / 2 {((step + rank) % ((nranks + 1) / 2)) + (nranks / 2)} else {(rank - (nranks / 2) - step).rem_euclid(nranks / 2)} ......c.send(&t.raw, peer_rank); // 发送c.recv(peer_tensor, peer_rank); // 接受......*self.step.lock() += 1; // 这里是关键点!递增到下一个peer
全部代码如下:
impl CommOpTrait for DecentralizedFullPrecisionSynchronous {fn execute_background_communication(&self,bucket: Arc<BaguaBucket>,comm_op_channels: &BaguaCommOpChannels,) {let bucket_guard = bucket.inner.lock();let stream_ptr = self.communicator.stream_ptr();// 获取不同的communicatorlet mut communication_tensor = match &self.communicator {BaguaCommunicator::SingleCommunicator(_) => {bucket_guard.get_communication_tensor(stream_ptr, false, false)}BaguaCommunicator::HierarchicalCommunicator(x) => match x {BaguaHierarchicalCommunicator::Leader(_) => {bucket_guard.get_communication_tensor(stream_ptr, true, true)}BaguaHierarchicalCommunicator::Worker(_) => {bucket_guard.get_communication_tensor(stream_ptr, false, false)}},};let peer_mode = &self.peer_selection_mode;let mut peer_guard = self.peer_weight.inner.write();let mut peer_tensor = peer_guard.raw.as_mut();let step = { *self.step.lock() } as i64;self.communicator.execute_communication( // 执行通信&mut communication_tensor,true,true,false,&mut |c, t| {match peer_mode {PeerSelectionMode::All => {// 做普通 allreduce{peer_tensor.clone_from(&t.raw, c.stream_ptr);let _guard = NCCLGroupGuard::new();c.allreduce_inplace(peer_tensor, BaguaReductionOp::AVG);}}PeerSelectionMode::ShiftOne => { // shift_one let rank = c.rank as i64;let nranks = c.nranks as i64;// 计算出下一个peer,关键点在函数的最后一句,通过调整step,每次peer都不同let peer_rank = if c.rank < c.nranks / 2 {((step + rank) % ((nranks + 1) / 2)) + (nranks / 2)} else {(rank - (nranks / 2) - step).rem_euclid(nranks / 2)} as i32;{let _guard = NCCLGroupGuard::new();c.send(&t.raw, peer_rank); // 发送c.recv(peer_tensor, peer_rank); // 接受}peer_tensor.average_inplace(&t.raw, c.stream_ptr);},PeerSelectionMode::Ring => {unimplemented!() // 没有实现},}},);*self.step.lock() += 1; // 这里是关键点!递增到下一个pee}
}
没有精力去研究rust,所以使用源码中的测试代码 tests/torch_api/test_decentralized.py 来看看,八卦在这方面真心做的不错。
def get_peer_rank(peer_selection_mode, rank, nranks, step, communication_interval):comm_step = step // communication_intervalif peer_selection_mode == "shift_one":if rank < nranks // 2:return ((comm_step + rank) % ((nranks + 1) // 2)) + (nranks // 2)else:return (rank - (nranks // 2) - comm_step) % (nranks // 2)else:ValueError("Unsupported `peer_selection_mode`")step = 1
for i in range(6):print("iteration : ", i)print("peer is : ", get_peer_rank("shift_one", 1, 5, step, 1))step += 1"""
iteration : 0
peer is : 4
iteration : 1
peer is : 2
iteration : 2
peer is : 3
iteration : 3
peer is : 4
iteration : 4
peer is : 2
iteration : 5
peer is : 3
"""
整理出图如下,worker 1 每次分别和 worker 4, worker 2,worker 3 进行交换。
+--------------+| || Worker 0 || || |+--------------++--------------+| |+-------> | Worker 2 |
+--------------+ | peer 2 | |
| | | | |
| Worker 1 | | +--------------+
| +---+
| | | +--------------+
+--------------+ | | || | Worker 3 |+-------> | || peer 3 | || +--------------+|| +--------------+| | |+--------> | Worker 4 |peer 1 | || |+--------------+
2.6.2.3.2 拷贝回来
copy_back_peer_weight 就是前面提到的回拷贝操作。
impl DecentralizedFullPrecisionSynchronous {pub fn copy_back_peer_weight(&self, bucket: Arc<BaguaBucket>) { // 拷贝回去let bucket_guard = bucket.inner.lock();let stream_ptr = self.communicator.stream_ptr();let mut communication_tensor =bucket_guard.get_communication_tensor(stream_ptr, false, false);self.communicator.execute_communication(&mut communication_tensor,false,false,true,&mut |c, t| {t.raw.clone_from(self.peer_weight.inner.read().raw.as_ref(), c.stream_ptr);},);}
}
我们再给出一个示意图。
+---------------------------------------------------------------------+
|DecentralizedAlgorithmImpl |
| |
| process_group |
| |
| decentralized_op = bucket.append_decentralized_synchronous_op |
| + |
| peer_selection_mode | |
| | |
| init_post_backward_hook | |
| ^ | |
| | | |
| | | |
+---------------------------------------------------------------------+| || |
+-----------------------------------------------------------+ +----------+
| BaguaBucket | | | | Worker 0 |
| | | | +----------+
| | v |
| | | +----------+
| | DecentralizedFullPrecisionSynchronous { | | Worker 1 |
| | | +----------+
| | PeerSelectionMode::ShiftOne { |
| | | peer2 +----------+
| | c.send(&t.raw, peer_rank);+--------+----> | Worker 2 |
| | c.recv(peer_tensor, peer_rank) | | +----------+
| | } | |
| | } | |peer3 +----------+
| | | +----> | Worker 3 |
| | | | +----------+
| | | |
| +--+ copy_back_peer_weight | |peer4 +----------+
| | +----> | Worker 4 |
+-----------------------------------------------------------+ +----------+
0x03 异步
关于异步通信,官方文档思路如下:
-
同步或是异步(Synchronous or Asynchronous):同步模式中,在每一次迭代过程中,所有工作节点都需要进行通信,并且下一步迭代必须等待当前迭代的通信完成才能开始。反之,异步式分布算法 [2] 则不需要等待时间:当某个节点完成计算后就可直接传递本地梯度,进行模型更新。
我们接下来用 https://tutorials.baguasys.com/algorithms/async-model-average 结合代码来分析学习。
3.1 示例用法
首先初始化八卦算法:
from bagua.torch_api.algorithms import async_model_average
algorithm = async_model_average.AsyncModelAverageAlgorithm()
然后对模型使用算法
model = model.with_bagua([optimizer], algorithm)
与运行同步算法不同,您需要在训练过程完成时(例如,当您要运行测试时)明确停止通信线程:
model.bagua_algorithm.abort(model)
要在再次开始训练时恢复通信线程,请执行以下操作:
model.bagua_algorithm.resume(model)
3.2 异步模型平均
在Gradient AllReduce 等同步通信算法中,同一迭代中每个 worker 都需要以锁步(lock-step)方式运作。当系统中没有落后者(straggler)时,这种同步算法相当有效,并可以提供更容易推理的确定性训练结果。然而,当系统中存在落后者时,使用同步算法时,更快的 worker 必须在每次迭代中等待最慢的 worker,这会极大地损害整个系统的性能。为了处理掉队者,我们可以使用异步算法,其中 worker 不需要同步。八卦提供的异步模型平均算法就是这样的异步算法。
3.3 算法
在异步模式平均算法可以被描述为如下:
每个 worker 都维护一个本地模型 X. 第 i 个 worker 维护 $ x^{(i)}$ ,每个 worker 并行运行两个线程。第一个线程进行梯度计算(称为计算线程),另一个线程进行通信(称为通信线程)。对于每个 worker i, 有一个锁 m i m_i mi,控制对其模型的访问。
第 i 个 worker 上的计算线程重复以下步骤:
- 获取锁 m i m_i mi。
- 在一批输入数据上计算局部梯度 $∇ F (x^{(i)}) $。
- 释放锁 m i m_i mi.
- 用局部梯度更新模型,$x^{(i)} = x^{(i)} - γ∇ F (x^{(i)}) $。
第 i 个 worker 上的通信线程重复以下步骤::
- 获取锁 m i m_i mi。
- 与所有其他 worker 的模型通信以平均本地模型 X ( i ) X^{(i)} X(i): X ( i ) = 1 n ∑ j = 1 n X ( j ) X^{(i)} = \frac{1}{n} \sum^n_{j=1}X^{(j)} X(i)=n1∑j=1nX(j)
- 释放锁 m i m_i mi.
每个 worker 独立并发地运行这两个线程。
3.4 分析
大家可以看到,本质上就是计算线程和通信线程都是自己操作,但是依赖锁进行彼此协调,达到了异步的目的。
3.4.1 异步通信实现
AsyncModelAverageAlgorithmImpl 是异步通信的实现。
class AsyncModelAverageAlgorithmImpl(AlgorithmImpl):def __init__(self,process_group: BaguaProcessGroup,peer_selection_mode: str = "all",sync_interval_ms: int = 500,warmup_steps: int = 0,):"""Implementation of the`AsyncModelAverage <https://tutorials.baguasys.com/algorithms/async-model-average.html>`_algorithm.The asynchronous implementation is experimental, and imposes some restrictions.With such asynchronous algorithm, the number of iterations on each worker are different. Thereforethe current implementation assumes that the dataset is an endless stream, and all workers continuouslysynchronize between each other.Users should call :meth:`abort` to manually stop the algorithm's continuous synchronization process.For example, for a model wrapped with `.with_bagua(...)`, you can abort with `model.bagua_algorithm.abort(model)`,and resume with `model.bagua_algorithm.resume(model)`.Args:process_group (BaguaProcessGroup): The process group to work on.peer_selection_mode (str): The way how workers communicate with each other. Currently ``"all"`` is supported.``"all"`` means all workers' weights are synchronized during each communication.sync_interval_ms (int): Number of milliseconds between model synchronizations.warmup_steps (int): Number of steps to warm up by doing gradient allreduce before doing asynchronousmodel averaging. Use 0 to disable."""super(AsyncModelAverageAlgorithmImpl, self).__init__(process_group)self.peer_selection_mode = peer_selection_modeself.sync_interval_ms = sync_interval_msself.step_id = 0self.warmup_steps = warmup_stepsself.cuda_event = torch.cuda.Event()self.abort_event = threading.Event()self.dummy_tensor = torch.Tensor([0]).byte().cuda()# 线程池self.executor = concurrent.futures.ThreadPoolExecutor(max_workers=1)self.scheduled = Falseprocess_ranks = list(_pg_group_ranks[self.process_group])self.thread_group = new_group(process_ranks, stream=torch.cuda.Stream(priority=-1))
3.4.2 初始化操作
init_operations 的 这部分调用是在 _bagua_reset_algorithm_buckets 之中,每个 BaguaModule 都会做设置,主要是设置:热身时期是同步操作/其他时间是异步操作,这里忽略了大部分代码。
def _bagua_reset_algorithm_buckets(self):self._bagua_cleanup_algorithm()raw_buckets = self._bagua_autotune_get_buckets()self.bagua_buckets.extend(self.bagua_algorithm.tensors_to_buckets(raw_buckets))for name, param in self.named_parameters():# 忽略 real_hook_factory 定义if param.requires_grad:param_tmp = param.expand_as(param)grad_acc = param_tmp.grad_fn.next_functions[0][0]hook = grad_acc.register_hook(real_hook_factory(name, param))hook.grad_acc = grad_accself._bagua_algorithm_hooks.append(hook)optimizer_hook = self.bagua_algorithm.init_post_optimizer_step_hook(self)for optimizer in self.bagua_optimizers:if not hasattr(optimizer, "_bagua_original_step"):optimizer._bagua_original_step = optimizer.step# 忽略 new_step_factory 定义optimizer.step = new_step_factory(optimizer)for bucket in self.bagua_buckets:self.bagua_algorithm.init_operations( # 这里调用对算法的初始化操作self,bucket,)self._bagua_backend.register_ordered_buckets([bucket.backend_bucket for bucket in self.bagua_buckets])
就是对于除了热身期间之外,每个桶都设定了异步通信。
def init_operations(self,bagua_module: BaguaModule,bucket: BaguaBucket,
):bagua_module._bagua_backend.wait_pending_comm_ops()bucket.clear_ops()if self.step_id < self.warmup_steps:bucket.append_centralized_synchronous_op( # 热身时期是同步操作hierarchical=False,average=True,group=self.process_group,)else:# 其他时间是异步操作async_op = bucket.append_asynchronous_model_average_op(peer_selection_mode=self.peer_selection_mode, group=self.thread_group)bucket._async_op = async_op
3.4.3 加锁解锁
我们接下来看看加锁释放锁的基础操作。bagua/torch_api/algorithms/async_model_average.py 之中有:
def _lock_model(self, bagua_module: BaguaModule):torch.cuda.current_stream().record_event(self.cuda_event)self.cuda_event.synchronize() # CUDA同步操作for bucket in bagua_module.bagua_buckets:bucket._async_op.lock_weight() # 加锁操作def _unlock_model(self, bagua_module: BaguaModule):torch.cuda.current_stream().record_event(self.cuda_event)self.cuda_event.synchronize() # CUDA同步操作for bucket in bagua_module.bagua_buckets:bucket._async_op.unlock_weight() # 释放锁
lock_weight 和 unlock_weight 的实现在 rust 代码之中。
impl DecentralizedFullPrecisionAsynchronous {pub fn lock_weight(&self) {let raw_mutex = unsafe { self.weight_mutex.raw() };raw_mutex.lock();}pub fn unlock_weight(&self) {unsafe {let raw_mutex = self.weight_mutex.raw();raw_mutex.unlock();};}
}
3.4.4 计算线程
计算线程之中,和加锁解锁关键步骤如下:
3.4.4.1 前向传播
前向传播时候,先进行加锁,如果异步循环通信线程没有启动,则会进行启动。
def init_forward_pre_hook(self, bagua_module: BaguaModule):def hook(input):if (self.step_id > self.warmup_stepsand self.sync_interval_ms > 0 # noqa: W503):self._lock_model(bagua_module) # 枷锁if not hasattr(self, "future"):self.future = self.executor.submit(self._run_async_loop, bagua_module # 启动异步循环通信线程)self.scheduled = Truereturn hook
3.4.4.2 后向传播
后向传播结束之后,会对锁进行释放,就是说,前向传播时候加锁启动线程,后向传播时候解锁,这期间进行计算。
def init_backward_hook(self, bagua_module: BaguaModule):def hook(parameter_name, parameter):if self.step_id <= self.warmup_steps:parameter._bagua_grad.bagua_mark_communication_ready() # 通知后端可以通信return hookdef init_post_backward_hook(self, bagua_module: BaguaModule):def hook():if self.step_id <= self.warmup_steps:bagua_module._bagua_backend.wait_pending_comm_ops() # 等待else:self._unlock_model(bagua_module) # 解锁return hook
此时逻辑如下:
+---------------------------------------------------------------------------+
| AsyncModelAverageAlgorithmImpl |
| |
| +-----------------------------+ +----------------------+ |
| | Computation thread | | BaguaBucket | |
| | | set async_op | +----------------+ | |
| | init_operations +----------------------> | | _async_op | | |
| | | | | | | |
| | | lock_weight() | | | | |
| | init_forward_pre_hook +------------------> | | | | |
| | | unlock_weight() | | | | |
| | init_post_backward_hook+-----------------> | | | | |
| | | | | | | |
| | | | +----------------+ | |
| +-----------------------------+ +----------------------+ |
| |
| +-----------------------------+ |
| | Communation thread | |
| | | |
| | _run_async_loop | |
| | | |
| | | |
| +-----------------------------+ |
| |
+---------------------------------------------------------------------------+
3.4.5 通信线程
通信线程主循环如下,主要是通知后端,进行通信。
def _run_async_loop(self, bagua_module: BaguaModule):comm_step = 0while True:state = self._negotiate()if state == _AsyncInternalState.ABORT:breakstart_time = time.time()for bucket in bagua_module.bagua_buckets: # 遍历桶for tensor in bucket.tensors: # 遍历张量# 通知后端,进行通信tensor.bagua_mark_communication_ready_without_synchronization() bagua_module._bagua_backend.wait_pending_comm_ops()duration = (time.time() - start_time) * 1000comm_step += 1time.sleep(self.sync_interval_ms / 1000)
3.4.5.1通知后端
Python
bagua_mark_communication_ready_without_synchronization 的实现如下,调用后端的 mark_communication_ready。
def bagua_mark_communication_ready_without_synchronization(self):"""Mark a Bagua tensor ready immediately, without `CUDA event <https://pytorch.org/docs/stable/generated/torch.cuda.Event.html?highlight=event#torch.cuda.Event>`_ synchronization."""self.bagua_backend.mark_communication_ready(self._bagua_backend_tensor,0,)
Rust
mark_communication_ready 的实现在 rust 之中。位置是 rust/bagua-core/bagua-core-py/src/lib.rs。
pub fn mark_communication_ready(&mut self,tensor: PyRef<BaguaTensorPy>,ready_cuda_event_ptr: u64,py: Python,
) -> PyResult<()> {let inner = &tensor.inner;py.allow_threads(|| {self.inner.mark_communication_ready(inner, ready_cuda_event_ptr)}).map_err(|e| PyRuntimeError::new_err(format!("{:?}", e)))
}
rust/bagua-core/bagua-core-internal/src/lib.rs 之中有:
pub fn mark_communication_ready(&mut self,tensor: &BaguaTensor,ready_cuda_event_ptr: u64,
) -> Result<(), BaguaCoreError> {let tracer = global::tracer("bagua-core");let mut span = tracer.start("tensor_ready");span.set_attribute(KeyValue::new("tensor_name", tensor.name()));tensor.mark_comm_ready(ready_cuda_event_ptr);while self.should_schedule()? {let bucket = self.ordered_buckets.pop_front().unwrap();bucket.reset_comm_ready();let bucket_clone = bucket.clone();self.ordered_buckets.push_back(bucket);self.schedule_comm(bucket_clone)?;}Ok(())
}
schedule_comm 在 rust/bagua-core/bagua-core-internal/src/lib.rs 之中。
pub fn schedule_comm(&self, bucket: Arc<BaguaBucket>) -> Result<(), BaguaCoreError> {let event_channel = BaguaEventChannel::new("comm_op");self.channels.schedule_channel_sender.send(BaguaScheduledCommOp {name: format!("comm op for bucket {}", bucket.name),ops: {let guard = bucket.inner.lock();guard.comm_ops.clone() // 获取bucket的op,进行调用},bucket,event_channel: event_channel.clone(),}).map_err(|e| BaguaCoreError::InternalChannelError(format!("{:?}", e)))?;Ok(self.channels.not_waited_events_sender.send(event_channel).map_err(|e| BaguaCoreError::InternalChannelError(format!("{:?}", e)))?)
}
发送了一个 BaguaScheduledCommOp。
pub struct BaguaScheduledCommOp {pub name: String,pub bucket: Arc<BaguaBucket>,pub ops: Vec<Arc<dyn CommOpTrait + Send + Sync>>,pub event_channel: BaguaEventChannel,
}
逻辑如下:
+---------------------------------------------------+ +----------------------------+
| AsyncModelAverageAlgorithmImpl | | BaguaBucket |
| | | +------------------------+ |
| +-----------------------------+ | | | _async_op | |
| | Computation thread | | | | | |
| | | set async_op | | | | |
| | init_operations +----------------------------> | | | |
| | | | | | | |
| | | lock_weight() | | | | |
| | init_forward_pre_hook +------------------------> | | | |
| | | unlock_weight()| | | | |
| | init_post_backward_hook+-----------------------> | | | |
| | | | | +------------------------+ |
| | | | +----------------------------+
| +-----------------------------+ |
| +---------------------------------+ |
| | Communation thread | | +----------------------------+
| | +-----------------------------+ | | | BaguaCommBackendPy |
| | | | | | | |
| | | _run_async_loop +----------------------------> | mark_communication_ready |
| | | | | | | + |
| | +-----------------------------+ | | | | |
| +---------------------------------+ | | v |
+---------------------------------------------------+ | schedule_comm || |+----------------------------+
3.4.5.2 归并
schedule_comm 最终会调用到 bucket.comm_ops,该变量在初始化时候被配置为 DecentralizedFullPrecisionAsynchronous,所以我们需要回头来一步一步看看如何归并。
前面初始化操作时候有使用 bucket.append_asynchronous_model_average_op 进行配置。
def init_operations(self,bagua_module: BaguaModule,bucket: BaguaBucket,
):bagua_module._bagua_backend.wait_pending_comm_ops()bucket.clear_ops()if self.step_id < self.warmup_steps:bucket.append_centralized_synchronous_op( # 热身时期是同步操作hierarchical=False,average=True,group=self.process_group,)else:# 其他时间是异步操作async_op = bucket.append_asynchronous_model_average_op( # 进行归并配置peer_selection_mode=self.peer_selection_mode, group=self.thread_group)bucket._async_op = async_op
Python
append_asynchronous_model_average_op 代码在 bagua/torch_api/bucket.py。其作用是:
-
将异步模型归并操作附加到bucket。此操作将在训练模型时启用 worker 之间的连续模型平均。当bucket中的所有张量都标记为ready时,操作将由Bagua后端按照追加的顺序执行。
-
此操作旨在与计算过程并行运行。它返回对op的引用。op具有独占访问模型的锁。调用
op.lock_weight()获取锁,调用op.unlock_weight()释放锁。 -
重点在于,张量 ready 之后进行操作。
def append_asynchronous_model_average_op(self, peer_selection_mode: str, group: Optional[BaguaProcessGroup] = None
):"""Append an asynchronous model average operation to a bucket. This operation will enable continuousmodel averaging between workers while training a model.The operations will be executed by the Bagua backend in the order they are appendedwhen all the tensors within the bucket are marked ready.This operation is intended to run in parallel with the computation process. It returns a referenceto the op. The op features a lock to exclusively access the model. Call ``op.lock_weight()`` toacquire the lock and ``op.unlock_weight()`` to release it.Args:peer_selection_mode (str): The way how workers communicate with each otehr. Currently ``"all"`` is supported.``"all"`` means all workers' weights are averaged during each communication.group: The process group to work on. If ``None``, the default process group will be used.Returns:The asynchronous model average operation itself."""if group is None:group = _get_default_group()return self.backend_bucket.append_decentralized_asynchronous_op(_bagua_backend_comm(group.get_global_communicator()),None,peer_selection_mode=peer_selection_mode,torch_stream=torch.cuda.current_stream().cuda_stream,)
Rust
append_decentralized_asynchronous_op 函数在 rust 之中,其调用了 DecentralizedFullPrecisionAsynchronous,就是往 bucket.comm_ops 之上添加了一个 DecentralizedFullPrecisionAsynchronous。
pub fn append_decentralized_asynchronous_op(&mut self,communicator_internode: Option<&BaguaSingleCommunicator>,communicator_intranode: Option<&BaguaSingleCommunicator>,peer_selection_mode: String,torch_stream: u64,) -> Arc<DecentralizedFullPrecisionAsynchronous> {let communicator =BaguaCommunicator::new(communicator_internode, communicator_intranode, false).expect("cannot create communicator");let comm_op = Arc::new(DecentralizedFullPrecisionAsynchronous {communicator,peer_selection_mode: match peer_selection_mode.as_str() {"all" => PeerSelectionMode::All,&_ => {unimplemented!("unsupported peer_selection_mode for decentralized asynchronous algorithm (should be `all`)")}},torch_stream,weight_mutex: Arc::new(Mutex::new(true)),});self.inner.lock().comm_ops // 插入到 bucket 的 comm_ops.push(comm_op.clone() as Arc<dyn CommOpTrait + Send + Sync>);comm_op}
DecentralizedFullPrecisionAsynchronous 里面有加锁,释放锁,CUDA 同步操作等等,恰好与前面提到的前向传播/后向传播对应。
impl CommOpTrait for DecentralizedFullPrecisionAsynchronous {fn execute_background_communication(&self,bucket: Arc<BaguaBucket>,comm_op_channels: &BaguaCommOpChannels,) {let bucket_guard = bucket.inner.lock();let comm_stream = self.communicator.stream_ptr();let mut communication_tensor = match &self.communicator {BaguaCommunicator::SingleCommunicator(_) => {bucket_guard.get_communication_tensor(comm_stream, false, false)}BaguaCommunicator::HierarchicalCommunicator(x) => {panic!("asynchronous op only accepts non-hierarchical communicator");}};let peer_mode = &self.peer_selection_mode;let torch_stream = self.torch_stream;self.communicator.execute_communication(&mut communication_tensor,false,false,false,&mut |c, t| {let start_time = std::time::Instant::now();let temp_buf = CUDA_DEVICE_MEMORY_POOL[t.raw.device_id()].try_pull(t.raw.num_elements_allocated() * t.raw.dtype().bytes()).expect("cannot allocate cuda memory");let mut temp_tensor = BaguaTensorRaw {ptr: temp_buf.ptr,num_elem_allocated: t.raw.num_elements_allocated(),dtype: t.raw.dtype().clone(),num_elem: t.raw.num_elements(),device_id: t.raw.device_id(),pool_allocations: vec![Arc::new(temp_buf)],};let reduced_buf = CUDA_DEVICE_MEMORY_POOL[t.raw.device_id()].try_pull(t.raw.num_elements_allocated() * t.raw.dtype().bytes()).expect("cannot allocate cuda memory");let mut reduced_tensor = BaguaTensorRaw {ptr: reduced_buf.ptr,num_elem_allocated: t.raw.num_elements_allocated(),dtype: t.raw.dtype().clone(),num_elem: t.raw.num_elements(),device_id: t.raw.device_id(),pool_allocations: vec![Arc::new(reduced_buf)],};let src_ready_event = CUDA_EVENT_POOL.take().event;// use default stream to copy weightstemp_tensor.clone_from(&t.raw, torch_stream as u64);unsafe {cpp::cpp!([src_ready_event as "cudaEvent_t",comm_stream as "cudaStream_t",torch_stream as "cudaStream_t"]{CUDACHECK(cudaEventRecord(src_ready_event, torch_stream));CUDACHECK(cudaStreamWaitEvent(comm_stream, src_ready_event , 0));});}match peer_mode {PeerSelectionMode::All => {c.allreduce(&temp_tensor, &mut reduced_tensor, BaguaReductionOp::SUM);}PeerSelectionMode::Ring => {unimplemented!()}PeerSelectionMode::ShiftOne => {unimplemented!()}};{// 获取 ready eventlet ready_event = CUDA_EVENT_POOL.take().event;unsafe {cpp::cpp!([ready_event as "cudaEvent_t",comm_stream as "cudaStream_t"]{// CUDA 同步操作CUDACHECK(cudaEventRecord(ready_event, comm_stream));CUDACHECK(cudaEventSynchronize(ready_event));});}self.lock_weight(); // 加锁t.raw.async_model_average(&reduced_tensor,&temp_tensor,c.nranks as f32,comm_stream,);unsafe {cpp::cpp!([ready_event as "cudaEvent_t",comm_stream as "cudaStream_t"]{// 对CUDA进行操作CUDACHECK(cudaEventRecord(ready_event, comm_stream));CUDACHECK(cudaEventSynchronize(ready_event));});}self.unlock_weight(); // 解锁}tracing::debug!("#{} async model average update cost: {:?}",c.rank,start_time.elapsed());},);}
}在 rust/bagua-core/bagua-core-internal/kernels/bagua_kernels.cu 之中有最终操作。
__global__ void async_model_average(float *tensor, const float *reduced_tensor_copy, const float *tensor_copy, const float nranks, const int N) {for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < N; i += blockDim.x * gridDim.x) { tensor[i] += reduced_tensor_copy[i] / nranks - tensor_copy[i];}
}
我们总结逻辑如下:
- (1)init_operations 会进行一系列调用,生成了一个DecentralizedFullPrecisionAsynchronous,赋值在bucket 的 comm_ops 和 aysnc_op 之上。
计算线程之中做如下操作:
- (2)计算线程之中,在前向传播之前设置了hook,其中会 lock weight。
- (3)计算线程之中,在后向传播之前设置了hook,其中会 unlock weight。
通讯线程之中做如下操作:
- (4)会调用 mark_communication_ready 进行通信设置。
- (5)mark_communication_ready 最终调用到 schedule_comm,其会启动 bucket.comm_ops,bucket.comm_ops 就是 DecentralizedFullPrecisionAsynchronous。
- DecentralizedFullPrecisionAsynchronous 之中会:
- (6)lock weight。
- (7)会进行异步模型归并。
- (8)会 unlock weight。
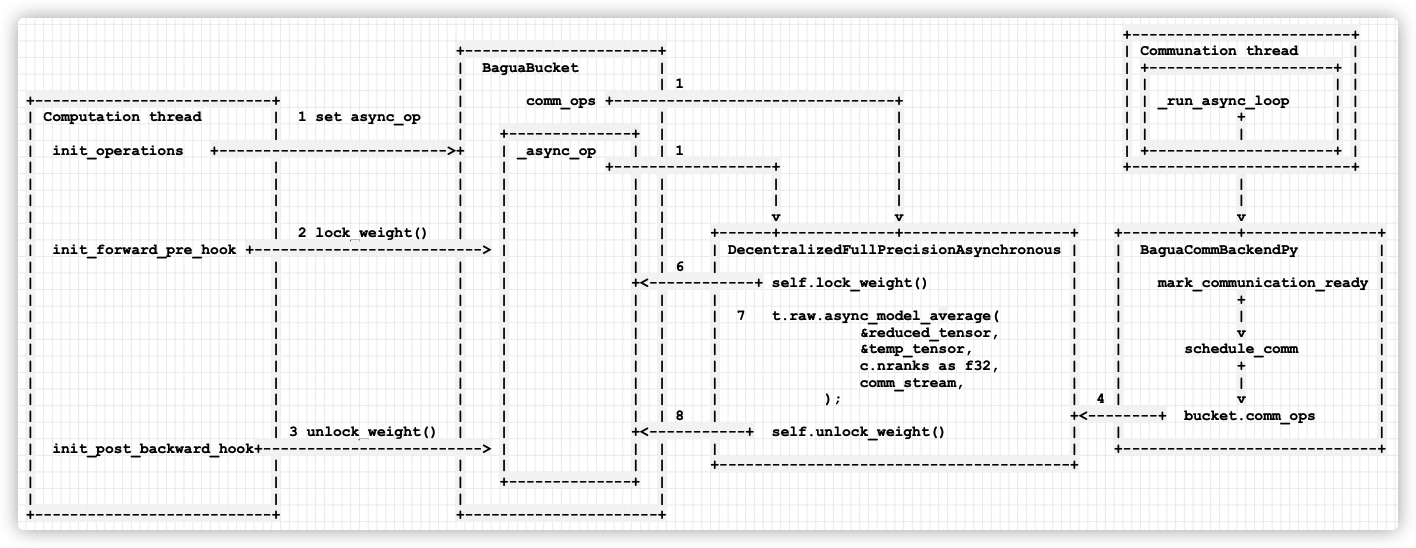
+---------------------------------------------------+ +----------------------+ +----------------------------------------+| AsyncModelAverageAlgorithmImpl | | BaguaBucket | | DecentralizedFullPrecisionAsynchronous || | | 1 | | || +-----------------------------+ | | comm_ops +--------> | 6 self.lock_weight() || | Computation thread | 1 set async_op | | | | || | | | | +--------------+ | | || | init_operations +---------------------------->+ | _async_op 1 | | | 7 t.raw.async_model_average( || | | | | | +--------> | &reduced_tensor, || | | | | | | | | &temp_tensor, || | | | | | | | | c.nranks as f32, || | | | | | | | | comm_stream, || | | 2 lock_weight() | | | | | | ); || | init_forward_pre_hook +----------------------------> | | | | || | | 3 unlock_weight()| | | | | | || | init_post_backward_hook+---------------------------> | | | | 8 self.unlock_weight() || | | | | +--------------+ | | || | | | | | +--------+-------------------------------+| +-----------------------------+ | +----------------------+ ^| | |
+--------------------------------------------------------------------------------------------------------------------------------+| | || +---------------------------------+ | || | Communation thread | | +-----------------------------+ || | +-----------------------------+ | | | BaguaCommBackendPy | || | | | | 4 | | | || | | _run_async_loop +--------------------------------> mark_communication_ready | || | | | | | | + | | 5| | +-----------------------------+ | | | | | || +---------------------------------+ | | v | |+---------------------------------------------------+ | schedule_comm | || + | || | | || v | || bucket.comm_ops +-----------+| |+-----------------------------+
手机如下:
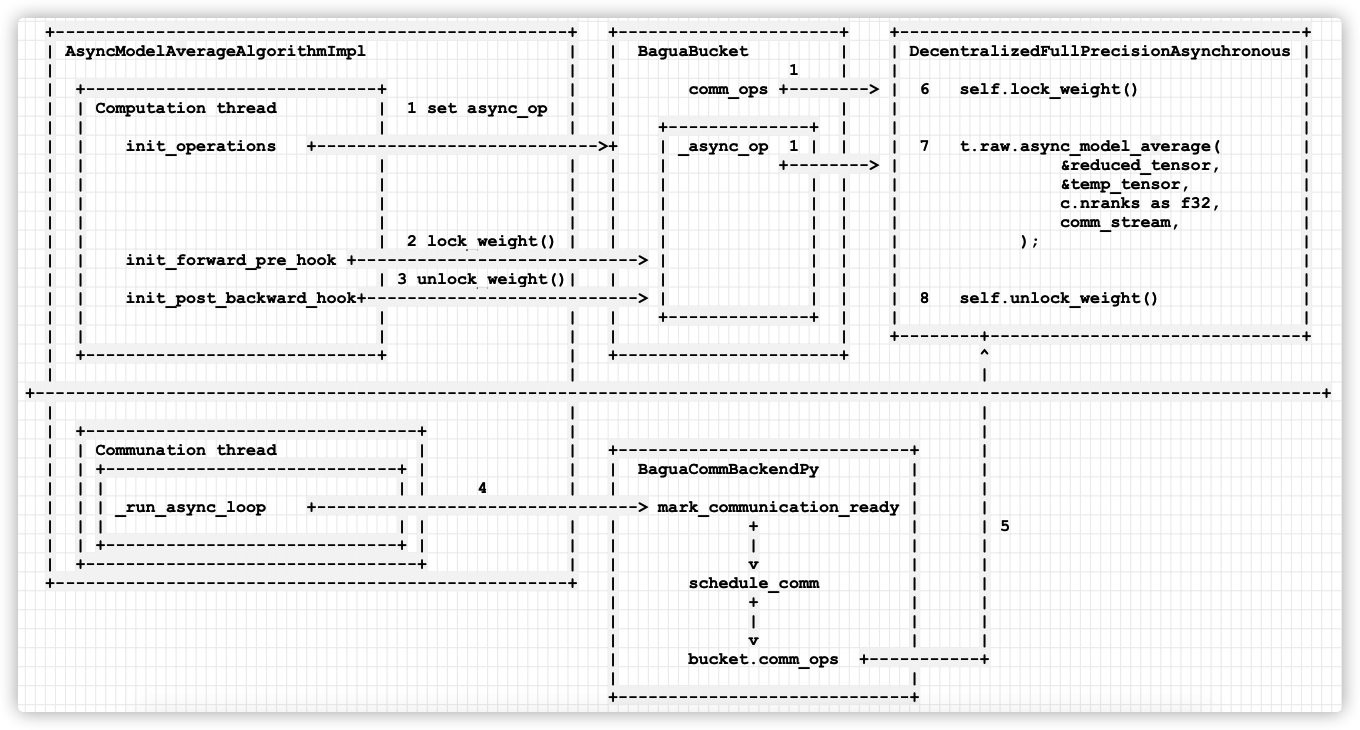
或者我们换一个角度来看,就是左右两个线程都操作桶,通过锁来协调竞争,特色除了锁之外,就在DecentralizedFullPrecisionAsynchronous 之中。这里需要注意的是,数值 1 的意义是设置,就是 bucket 的 _async_op 和 comm_ops 都配置成 DecentralizedFullPrecisionAsynchronous,最后通讯线程之中(4)会调用 mark_communication_ready 进行通信设置。
+-------------------------++----------------------+ | Communation thread || BaguaBucket | | +---------------------+ || | 1 | | | |
+---------------------------+ | comm_ops +--------------------------------+ | | _run_async_loop | |
| Computation thread | 1 set async_op | | | | | + | |
| | | +--------------+ | | | | | | |
| init_operations +-------------------------->+ | _async_op | | 1 | | +---------------------+ |
| | | | +------------------+ | +-------------------------+
| | | | | | | | |
| | | | | | | | |
| | | | | | v v v
| | 2 lock_weight() | | | | +------+-------------+-------------------+ +-------------+---------------+
| init_forward_pre_hook +--------------------------> | | | | DecentralizedFullPrecisionAsynchronous | | BaguaCommBackendPy |
| | | | | | 6 | | | |
| | | | +<------------+ self.lock_weight() | | mark_communication_ready |
| | | | | | | | | + |
| | | | | | | 7 t.raw.async_model_average( | | | |
| | | | | | | &reduced_tensor, | | v |
| | | | | | | &temp_tensor, | | schedule_comm |
| | | | | | | c.nranks as f32, | | + |
| | | | | | | comm_stream, | | | |
| | | | | | | ); | 4 | v |
| | | | | | 8 | +<--------+ bucket.comm_ops |
| | 3 unlock_weight() | | +<-----------+ self.unlock_weight() | | |
| init_post_backward_hook+-------------------------> | | | | | +-----------------------------+
| | | | | | +----------------------------------------+
| | | +--------------+ |
| | | |
+---------------------------+ +----------------------+
手机如下:
至此,八卦框架分析完毕,这个框架无论是论文,代码,文档,介绍网站,PPT都非常给力,推荐有兴趣的朋友继续深入研究。
0xEE 个人信息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考
如果您想及时得到个人撰写文章的消息推送,或者想看看个人推荐的技术资料,敬请关注。

0xFF 参考
PyTorch internals
快手八卦!突破 TensorFlow、PyTorch 并行瓶颈的开源分布式训练框架来了!
https://arxiv.org/pdf/2107.01499.pdf
https://tutorials.baguasys.com/algorithms/decentralized
[1] Dean, Jeffrey, Greg S. Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao et al. “Large scale distributed deep networks.” (2012).
[2] Zhengyuan Zhou, Panayotis Mertikopoulos, Nicholas Bambos, Peter Glynn, Yinyu Ye, Li-Jia Li, and Li Fei-Fei. 2018. Distributed asynchronous optimization with unbounded delays: How slow can you go?. In International Conference on Machine Learning. PMLR, 5970–5979.
[3] DanAlistarh, DemjanGrubic, JerryLi, RyotaTomioka, and MilanVojnovic. 2016. QSGD: Communication-efficient SGD via gradient quantization and encoding. arXiv preprint arXiv:1610.02132 (2016).
[4] Dan Alistarh, Torsten Hoefler, Mikael Johansson, Sarit Khirirat, Nikola Konstanti- nov, and Cédric Renggli. 2018. The convergence of sparsified gradient methods. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 5977–5987.
[5] Anastasia Koloskova, Sebastian Stich, and Martin Jaggi. 2019. Decentralized stochastic optimization and gossip algorithms with compressed communication. In International Conference on Machine Learning. PMLR, 3478–3487.
[6] Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, Wei Zhang, and Ji Liu. 2017. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 5336–5346.
[7] Christopher De Sa, Matthew Feldman, Christopher Ré, and Kunle Olukotun. 2017. Understanding and optimizing asynchronous low-precision stochastic gradient descent. In Proceedings of the 44th Annual International Symposium on Computer Architecture. 561–574.
[8] Xiangru Lian, Wei Zhang, Ce Zhang, and Ji Liu. 2018. Asynchronous decentral- ized parallel stochastic gradient descent. In International Conference on Machine Learning. PMLR, 3043–3052.
[9] Hanlin Tang, Shaoduo Gan, Ce Zhang, Tong Zhang, and Ji Liu. 2018. Com- munication compression for decentralized training. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 7663–7673.
[10] Ji Liu, Ce Zhang, et al. 2020. Distributed Learning Systems with First-Order Methods. Foundations and Trends® in Databases 9, 1 (2020), 1–100.
这篇关于[源码解析] 快手八卦 --- 机器学习分布式训练新思路(3)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





