本文主要是介绍Scala学习笔记——reduce、fold、scan,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Scala学习笔记之reduce、fold、scan
文章目录
- `Scala`学习笔记之`reduce`、`fold`、`scan`
- `1. reduce化简`
- 概念与区别:
- 示例:
- `1.` 计算给定集合的元素和:
- `2.` 计算`n!`:
- `2. fold折叠`
- 概念与区别:
- 示例:
- `1.` 计算`n!`(`reduce`的优化):
- `2.` 统计字符串中每个字符出现的频次:
- `3. scan扫描`
- 概念与区别:
1. reduce化简
概念与区别:
- 在
Scala中,我们可以使用reduce这种二元操作对集合中的元素进行归约。reduce包含reduceLeft和reduceRight两种操作,前者从集合的头部开始操作,后者从集合的尾部开始操作。- 特别的,如果我们不指定
reduce是left还是right默认情况下会使用reduceLeft执行操作。
reduce、reduceLeft、reduceRight源码:
//reduce
def reduce[A1 >: A](op: (A1, A1) => A1): A1 = reduceLeft(op)//reduceLeft
def reduceLeft[B >: A](op: (B, A) => B): B = {if (isEmpty)throw new UnsupportedOperationException("empty.reduceLeft")var first = truevar acc: B = 0.asInstanceOf[B]for (x <- self) {if (first) {acc = xfirst = false}else acc = op(acc, x)}acc
}//reduceRight
def reduceRight[B >: A](op: (A, B) => B): B = {if (isEmpty)throw new UnsupportedOperationException("empty.reduceRight")reversed.reduceLeft[B]((x, y) => op(y, x))
}
从源码可以看出,reduce默认就是从左向右归约,然后对这两个元素进行指定的操作(指定的操作即reduce传入的参数),如果集合为空会报错empty.reduceLeft,如果只有一个元素,则返回该元素。
reduceLeft就是从左向右归约,reduceRight就是从右向左归约。
仔细观察这三个方法,可以发现reduce和reduceLeft还是有区别的,reduce的参数中那个函数的两个参数类型是要一致的,而reduceLeft中的参数中那个函数的两个参数类型可以不一样,但第一个参数类型必须是第二个参数类型的父类(或本类)。
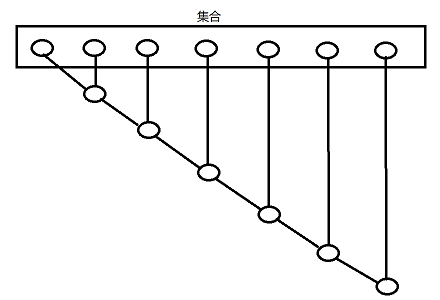
reduce与reduceLeft运行示意图(从左往右归约):
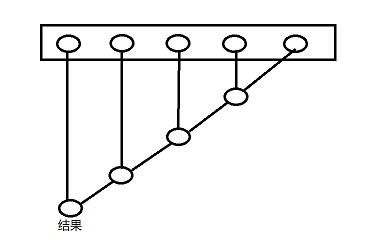
reduceRight运行示意图(从右向左归约):
示例:
1. 计算给定集合的元素和:
(一般这些元素满足运算交换律的话,使用reduceLeft和reduceRight结果是一样的)
def sum_reduce(seq: Seq[Int]) = {seq.reduce(_ + _) // 下划线是占位符,用来表示当前获取的两个元素,两个下划线之间的是操作符,表示对两个元素进行的操作,这里是加法操作(也可以使用乘法*或者减法-等其他操作)}def sum_reduceLeft(seq: Seq[Int]) = {seq.reduceLeft(_ + _)}def sum_reduceRight(seq: Seq[Int]) = {seq.reduceRight(_ + _)}println(sum_reduce(1 to 5)) // (((1 + 2) + 3) + 4) + 5 = 15println(sum_reduceLeft(1 to 5)) // (((1 + 2) + 3) + 4) + 5 = 15println(sum_reduceRight(1 to 5)) // 1 + (2 + (3 + (4 + 5))) = 15// 如果是减法,则reduceLeft和reduceRight结果不一样。// reduceLeft:(((1 - 2) - 3) - 4) - 5 = -13// reduceRight:1 - (2 - (3 - (4 - 5))) = 3
2. 计算n!:
def test(n: Int): Int = {1 to n reduce (_ * _) // 用reduceLeft、reduceRight结果是一样的}println(test(4)) // 24println(test(0)) // 报错
2. fold折叠
概念与区别:
fold和reduce的区别就是fold给了初始值,运算步骤和reduce还是一样的。
上面的示例2当n < 1时候就会报错了,因为没有元素,所以我们可以用fold进行改进,具体代码看下面示例。
另外,foldLeft和foldRight还有专属符号代替:
foldLeft /:
foldRight :\
冒号所在方是需要折叠的列表方,需要折叠的列表永远不靠着\
fold、foldLeft、foldRight源码:
//folddef fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 = foldLeft(z)(op)//foldLeft def foldLeft[B](z: B)(op: (B, A) => B): B = {var result = zthis foreach (x => result = op(result, x))result}//foldRightdef foldRight[B](z: B)(op: (A, B) => B): B =reversed.foldLeft(z)((x, y) => op(y, x))
同样,观察源码,虽然fold和foldLeft运算步骤差不多,但是还是有区别的,同样是类型的问题,fold要求传入函数的那两个参数类型一致,而foldLeft的第一个参数是没有限制的,可以传入List、Map等等。
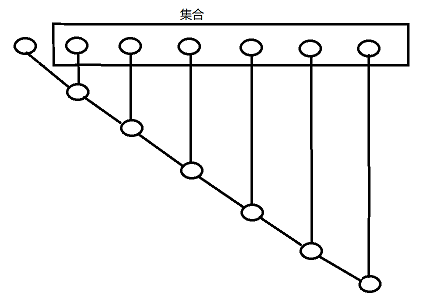
fold与foldLeft运行示意图(从左往右归约):
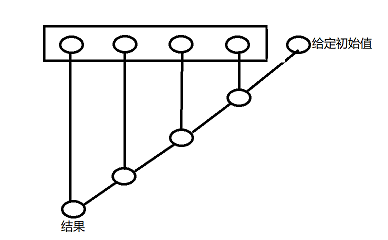
foldRight运行示意图(从右向左归约):
示例:
1. 计算n!(reduce的优化):
def test(n: Int): Int = {(1 to n).foldLeft(1)(_ * _)// 或者,注意下面的也是foldLeft,记住口诀:冒号所在方是需要折叠的列表方,需要折叠的列表永远不靠着\// (1 /: (1 to n)) (_ * _)}println(test(0)) // 1println(test(4)) // 24
2. 统计字符串中每个字符出现的频次:
def test(str: String): Map[Char, Int] = {str.foldLeft(Map[Char, Int]())((m, c) => m + (c -> (m.getOrElse(c, 0) + 1)))// 或者// (Map[Char, Int]() /: str) ((m, c) => m + (c -> (m.getOrElse(c, 0) + 1)))}test("Hello World!").foreach(t => println(t._1, t._2))/*结果:(e,1)(!,1)( ,1)(l,3)(H,1)(W,1)(r,1)(o,2)(d,1)*/
3. scan扫描
概念与区别:
如果理解了fold的话,学习scan将会很简单,scan就是在fold的基础上,存储了fold的中间结果,如下图,即存储了圈起来的中间值。
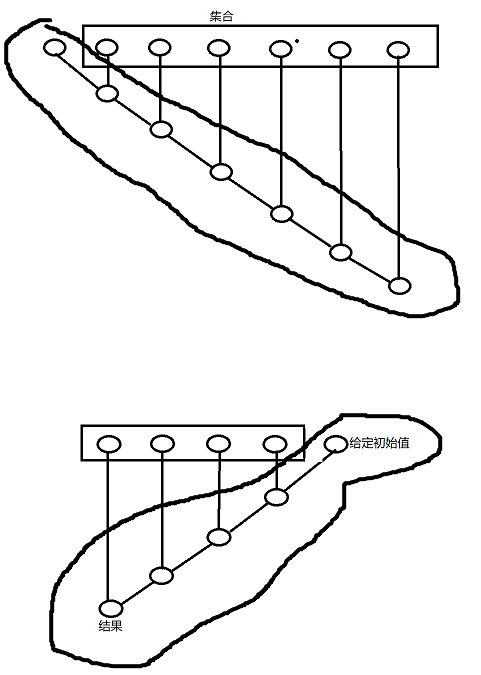
同样是求n!,我们来看scan的结果,可以看出scan把所有中间结果都保存到了一个集合当中:
def main(args: Array[String]): Unit = {test(5).foreach(println)/*结果:112624120*/}def test(n: Int) = {(1 to n).scan(1)(_ * _)}
这篇关于Scala学习笔记——reduce、fold、scan的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







