本文主要是介绍Potential-based shaping and Q-value initialization are equivalent(静态势能塑形相当于初始化agent的Q-table),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
------事实证明,塑形是提高强化学习表现的一种有力但不稳定的手段。Ng,Harada 和 Russell (1999)提出了一种基于势能的塑形算法,通过增加塑形奖励来保证学习器学会最佳行为。
------在这篇文章中,我们证明了这个塑形算法和几个强化学习算法所需的初始化步骤之间的某些相似之处。更具体地说,我们证明了一个基于塑形算法的势能函数的初始 Q Q Q 值的强化学习器在整个学习过程中作出的更新与接受基于塑形势能的奖励的学习器相同。我们进一步证明,在一个广泛的策略范畴下,这两个学习器的行为是不可区分的。比较提供了直观的成形算法的理论性质,以及一个更简单的方法捕捉算法的利益的建议。此外,这种等价提出了以前没有解决的关于基于势能塑形的学习效率的问题。
1. Potential-Based Shaping
------塑形是提高强化学习任务中学习性能的常用技术。塑形的想法是为学习器提供额外奖励,鼓励他们朝着环境中的高奖励状态前进。如果任意应用这些塑形奖励,它们就有可能分散agent对环境中预期目标的注意力。在这种情况下,agent会收敛于一个在存在塑形奖励时最优但在原始任务方面次优的策略。
------Ng、Harada和Russell(1999)提出了一种方法,以确保最优策略保持其最佳性的方式增加塑形奖励。他们将强化学习任务建模为马尔可夫决策过程(MDP),agent试图找到一个最大化折扣未来奖励的策略(Sutton&Barto,1998)。它们定义了状态上的势能函数 Φ ( ⋅ ) Φ(·) Φ(⋅)。从状态 s s s转换到 s ′ s' s′的塑形奖励定义为 Φ Φ Φ:
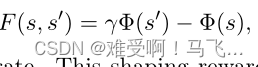
------其中 γ γ γ是 MDP 的折扣率。对于agent经历的每一个状态转换,这种塑形奖励都会加入到环境奖励中。势能函数可以看作是在状态空间上定义了一个地形(topography)。因此,从一种状态转换到另一种状态的塑形奖励就是这种状态势能的折现变化。基于势能的塑形保证了通过一系列状态的循环不会从塑形中获得净收益。事实上,在标准条件下,Ng等人证明,任何对MDP而言最优的策略,如果增加了基于势能的塑形奖励,则对未分段的MDP而言也是最优的。
2. New Results
------许多强化学习算法通过保持 Q Q Q值来学习最优策略。 Q Q Q值是对在给定状态下采取给定动作的预期未来回报的估计。结果表明,利用状态势能函数初始化agent的 Q Q Q值可以达到基于势能的塑形效果。我们证明这个结果只适用于 Q Q Q学习算法,但结果也适用于 Sarsa 和其他 TD 算法。
------我们定义了两个强化学习agent, L L L和 L ′ L' L′,他们在整个学习过程中会经历相同的 Q Q Q值变化。设agent L L L的 Q Q Q表的初始值为 Q ( s , a ) = Q 0 ( s , a ) Q(s,a)=Q_0(s,a) Q(s,a)=Q0(s,a)。基于势能函数Φ的基于势能的塑形奖励 F F F将在学习期间应用。另一个agent L ′ L' L′将 Q Q Q表初始化为 Q 0 ′ ( s , a ) = Q 0 ( s , a ) + Φ ( s ) Q'_0(s,a)=Q_0(s,a)+Φ(s) Q0′(s,a)=Q0(s,a)+Φ(s)。该agent不会获得定型奖励。
------假设一个经验是一个4元组< s , a , r , s ′ s,a,r,s' s,a,r,s′>,表示agent在状态 s s s中采取动作 a a a,转换到状态 s s s并获得奖励 r r r。两个agent的 Q − v a l u e Q-value Q−value都是使用 Q − l e a r n i n g Q-learning Q−learning的标准更新规则基于经验更新的。 Q ( s , a ) Q(s,a) Q(s,a)用基于势能的塑形奖励来更新,而 Q ′ ( s , a ) Q'(s,a) Q′(s,a)在没有塑形奖励的情况下更新:
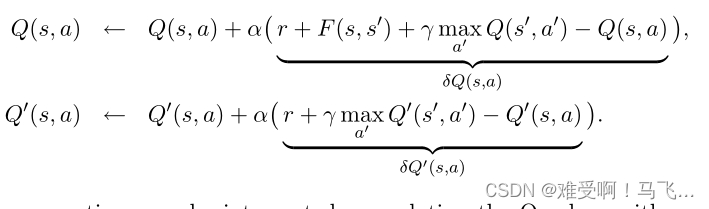
------上述等式可以解释为使用按学习率 α α α 缩放的误差项更新 Q Q Q 值(假设agent的 α α α 相同)。 我们将误差项称为 δ Q ( s , a ) δQ(s, a) δQ(s,a) 和 δ Q ′ ( s , a ) δQ'(s, a) δQ′(s,a)。我们还跟踪学习过程中 Q Q Q 和 Q ′ Q' Q′ 的总变化。 Q ( s , a ) Q(s, a) Q(s,a) 和 Q ′ ( s , a ) Q'(s, a) Q′(s,a) 中原始值和当前值之间的差分别称为 Δ Q ( s , a ) ΔQ(s, a) ΔQ(s,a) 和 Δ Q ′ ( s , a ) ΔQ'(s, a) ΔQ′(s,a)。agent的 Q Q Q 值可以表示为它们的初始值加上更新导致的这些值的变化:
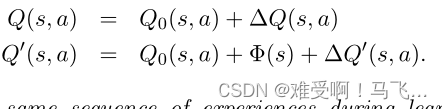
定理 1. 在学习过程中给定相同的经验序列, Δ Q ( s , a ) ΔQ(s, a) ΔQ(s,a) 总是等于 Δ Q ′ ( s , a ) ΔQ'(s, a) ΔQ′(s,a)。
证明:归纳法证明。基本情况是当 s s s 和 s ′ s' s′ 的 Q Q Q 表条目仍然是它们的初始值时。该定理适用于这种情况,因为 Δ Q ΔQ ΔQ 和 Δ Q ′ ΔQ' ΔQ′ 中的项均一致为零。
------对于归纳情况,假设所有 s s s 和 a a a 的条目 Δ Q ( s , a ) = Δ Q ′ ( s , a ) ΔQ(s, a) = ΔQ'(s, a) ΔQ(s,a)=ΔQ′(s,a)。我们表明,作为对经验 < s , a , r , s ′ s, a, r, s' s,a,r,s′> 的响应,误差项 δ Q ( s , a ) δQ(s, a) δQ(s,a) 和 δ Q ′ ( s , a ) δQ'(s, a) δQ′(s,a) 是相等的。
------首先,我们检查在存在基于势能的塑形奖励的情况下对 Q ( s , a ) Q(s, a) Q(s,a) 执行的更新:
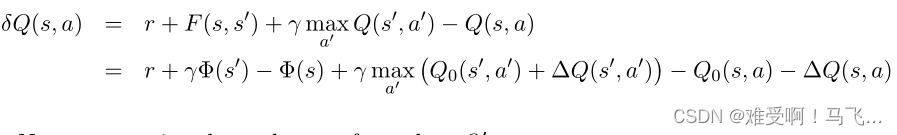
现在我们检查对 Q ′ Q' Q′ 执行的更新:
两个 Q 表都用相同的值更新,因此 Δ Q ( ⋅ ) ΔQ(·) ΔQ(⋅) 和 Δ Q ′ ( ⋅ ) ΔQ'(·) ΔQ′(⋅) 相等。
当我们考虑agent如何选择动作时,可以理解证明的含义。大多数策略都是根据学习器的 Q Q Q 值定义的。我们将基于优势的策略定义为在给定状态下选择动作的策略,其概率由该状态的 Q Q Q 值的差异决定,而不是它们的绝对大小。因此,如果将某个常数添加到所有 Q Q Q 值,则下一个动作的概率分布将不会改变。
定理 2。 如果 L L L 和 L ′ L' L′ 学习了相同的经验序列并使用基于优势的策略,则它们的下一步行动将具有相同的概率分布。
证明: 回想一下 Q Q Q 值是如何定义的:
----我们证明了 Δ Q ( s , a ) ΔQ(s, a) ΔQ(s,a) 和 Δ Q ′ ( s , a ) ΔQ'(s, a) ΔQ′(s,a) 如果用相同的经验更新它们是相等的。 因此,两个 Q Q Q 表之间的唯一区别是 Q ′ Q' Q′ 中状态势能的增加。由于此添加在给定状态下的所有操作中是统一的,因此不会影响策略。
----事实证明,强化学习中使用的几乎所有策略都是基于优势的。最重要的此类策略是贪婪策略。两种最流行的探索策略,e-greedy 和 Boltzmann soft-max,也是基于优势的。对于这些策略中的任何一个,上述初始化和基于势能的塑形之间的学习没有区别。
3. 目标导向任务中的形成 Shaping in Goal-Directed Tasks
----已经表明,初始 Q Q Q 值对目标导向任务的强化学习效率有很大影响 (Koenig & Simmons, 1996)。这些问题的特征在于具有某个目标区域的状态空间。智能体的任务是找到一个尽快到达这个目标区域的策略。显然,在找到最优策略之前,代理必须在探索期间至少找到一次目标状态。由于 Q Q Q 值初始化低于其最佳值,代理可能需要在状态和动作空间中以指数方式学习时间才能找到目标状态。然而,在确定性环境中, Q Q Q值的乐观初始化需要在找到目标之前的状态-动作空间中的多项式学习时间。请参阅 Bertsekas 和 Tsitsiklis (1996) 以进一步分析具有各种初始化的强化学习算法。因为基于势能的塑形等同于 Q 值初始化,所以在选择不会导致学习性能差的势能函数时必须小心。
4. Conclusion
------我们已经表明,基于势能的塑形的效果可以通过使用 Q − l e a r n i n g Q-learning Q−learning的agent的 Q Q Q 值的特定初始化来捕获。这些结果扩展到 Sarsa 和其他 TD 方法。此外,这些结果扩展到这些算法的版本,这些版本通过资格跟踪得到增强。
------对于离散状态环境,这些结果意味着应该简单地用势能函数初始化学习器的 Q Q Q 值,而不是改变学习算法以纳入塑造奖励。在连续状态空间的情况下,基于势能的塑形可能仍会提供一些好处。状态空间上的连续势函数类似于状态值的连续初始化。因为基于势能的塑形允许在状态空间上定义的任何函数都被用作势能函数,所以该方法可能对状态表示受限的代理有益。仔细分析这个案例将是未来研究的一个富有成效的途径。
这篇关于Potential-based shaping and Q-value initialization are equivalent(静态势能塑形相当于初始化agent的Q-table)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



