本文主要是介绍韦伯首批照片引发论文竞速大战:晚13秒即错失首发,科研党纷纷肝得起飞,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
在韦伯望远镜传回首批照片仅仅过去两周之后,天文学的新成果真是扎了堆了。
这一边,人类已知宇宙最古老星系纪录被打破。
韦伯望远镜观测到了一个距地球135亿光年的星系GLASS-z13,比之前哈勃望远镜看到的GN-z11,还要远1亿光年。

另一边,太阳系外一颗距离地球1150光年的行星上被发现有明显的水特征及云雾。
还有团队仅仅从韦伯传回的第一张照片里,就新发现了16个星系。
其中一个可以追溯到宇宙大爆炸后7亿年。
当然还包括太阳系内,韦伯只是“瞥”了一眼木星(曝光仅75秒),就观测到木卫一与木星相互作用下产生的大气现象。

在这个7月,韦伯望远镜让全球天文学家真是像过年一样喜庆啊。
有学者直言:
几乎韦伯传回的每一张照片,都值得我们仔细研究!
实际上,大家已经在加速“肝”成果了。
在韦伯传回第一批照片的3天后,有两个团队发表了相关分析论文,发表时间仅仅相隔了13秒。
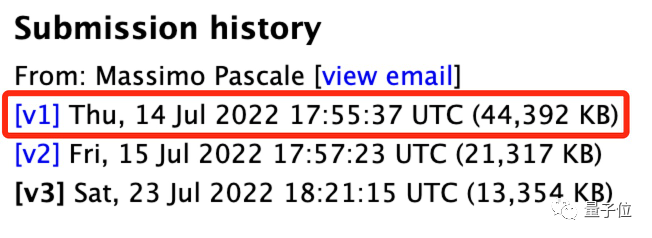
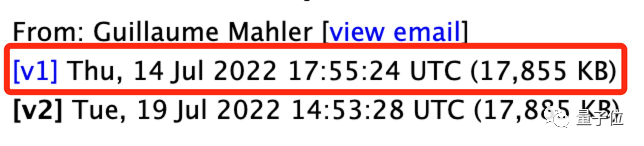
一旁“看热闹”的网友表示:
毫无疑问,韦伯望远镜会是研究人员的大宝库。

带来了哪些新发现?
首先最值得关注的,莫过于人类已知宇宙最古老星系纪录被刷新。
有两个研究团队都发现了它的存在。
在传回数据中,研究人员最先锁定了两个极其遥远的星系。
其中一个,可以发出来自宇宙大爆炸4亿年后的光,这一纪录与哈勃望远镜此前观测到的最古老星系持平。
另一个就是GLASS-z13了,它被认为在宇宙大爆炸3亿年后出现。
这两个星系实际上都非常小,大约只有银河系的100分之一。
但它们之中的恒星生成速度却异常快,已经形成了是太阳质量10亿倍的恒星。

与此同时,Quantamagazine透露,还有另一个团队也发现了非常遥远的星系。
他们的成果主要集中在宇宙大爆炸5亿年后左右的星系,但目前这一结果还没有对外公布。
还有更多星系开始走入天文学家的视野中。
仅在公布的第一张照片里,目前就已经发现了16个星系。
针对其中的一个光斑,学者认为它来自宇宙大爆炸之后7亿年左右。
而通过光谱检测仪,科学家们希望可以检测到这些看到的早期星系中,是否有重元素(除去氢氦以外的所有化学元素),尤其是氧。
要知道,天文界一直在努力寻找没有重元素的星系。
一旦找到这样的星系,将可以成为第一代恒星是由原始氢和氦组成的确凿证据。

除此之外,韦伯望远镜由于观测细节更多,为人们研究星系结构,提供了更有影响力的数据。
比如一个距离我们大约2400万光年的星系NGC7496。
直到现在,它的恒星形成区都还被黑暗笼罩着。而此前哈勃望远镜无法穿透这些厚厚的尘埃和气体,窥见其背后的样貌。
但是韦伯望远镜可以看到从宇宙尘埃中反射回来的红外光,从而能探测到恒星形成、发生核聚变的时间点。
科学家表示,从韦伯这次传回的数据中,他们非常惊喜地发现NGC7496是一个非常“标准”的星系。
这对于研究普遍的恒星形成过程具有重要意义。
另一边,还有科学家发现,在韦伯望远镜拍下的南环状星云的侧面,藏着一个非常典型的盘状星系。
之前它被误以为是星云本身的一部分。
而这个发现,对于研究银河系中央凸起的结构,具有重要意义。

实际上,天文学家对于韦伯望远镜还寄予了更多希望。
比如认为它应该也能探测到更为遥远的超新星、超大质量黑洞撕裂等现象。
One More Thing
那么,韦伯望远镜这么厉害,哈勃这个“老古董”是不是就完全没用了?
显然不是。

康奈尔大学天文学家尼古拉斯·李维斯表示:我们仍旧需要哈勃。
实际上,我正在努力给哈勃争取一笔更大的预算。
因为哈勃望远镜可以弥补韦伯的一些不足,比如对于可见光和紫外线波段,韦伯望远镜其实并不擅长。
但这些波长上也还有很多重要信息需要关注。
参考链接:
[1]https://www.quantamagazine.org/two-weeks-in-the-webb-space-telescope-is-reshaping-astronomy-20220725/
[2]https://www.cnet.com/science/space/features/no-nasas-revolutionary-hubble-space-telescope-is-not-done-yet/
这篇关于韦伯首批照片引发论文竞速大战:晚13秒即错失首发,科研党纷纷肝得起飞的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









