今天一个朋友问我这样一个问题,他们OA的应用数据库和接口数据库部署在两台不同的server。
接口server主要负责和第三方系统进行集成,第三方系统调接口创建OA单据,OA系统进行审批,OA审批完毕后。调用接口server的接口。OA将审批的流转记录及附件返回第三方系统。
为保障数据及接口的安全。数据先保存在OAserver的中间数据库,然后通过OA定时代理传到接口server上。
可是。这种做法遇到一个问题。用户要求退回时可以马上反馈给第三方系统。
为了保障数据及附件可以及时反馈到第三方系统。故本文採用的函件收集器的新邮件到达前触发代理的方式实现。
【实现方式】
退回时,OA给函件收集器数据库发送一封邮件。实现退回的业务代码逻辑写在函件收集器的新邮件到达前触发的代理里面。当邮件到达前代理同一时候触发,从而达到及时退回的效果。
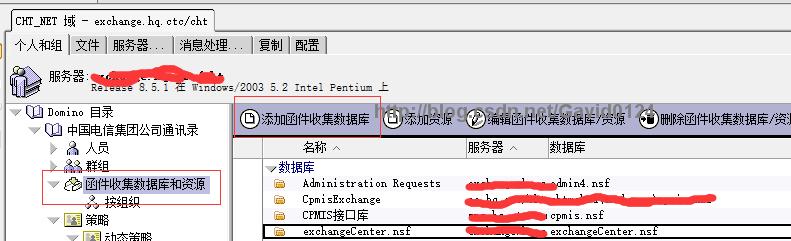
【函件收集器的配置】
Administratorclient-->个人和组-->函件收集数据库和资源-->加入函件收集库

【给函件库发邮件】

【函件库创建新邮件到达前触发代理】

将要实现代码逻辑写在此代理中。
【使用方法】
用于第三方系统接口以发邮件的方式触发。如:消息中心、公文上下行文等等。
不同的系统平台不一样,可是发邮件的功能基本每一个系统都能够实现。这样通过邮件的方式就可实现接口的触发。









