本文主要是介绍scrapy进阶《封号码罗》之如何优雅的征服世界首富亚马逊(amazon.com),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
免责声明:原创文章,仅用于学习,希望看到文章的朋友,不要随意用于商业,本作者保留当前文章的所有法律权利。欢迎评论,点赞,收藏,转发!
关于亚马逊的爬虫,针对不同的使用场合,前前后后写了有六七个了,今天拿出其中一个爬虫,也是相对其他几个爬虫难度稍微大一些的,这个爬虫用到了我之前没有使用过的一个爬虫手法,虽然头疼了一天半的时间,不过最终还是写出来了!
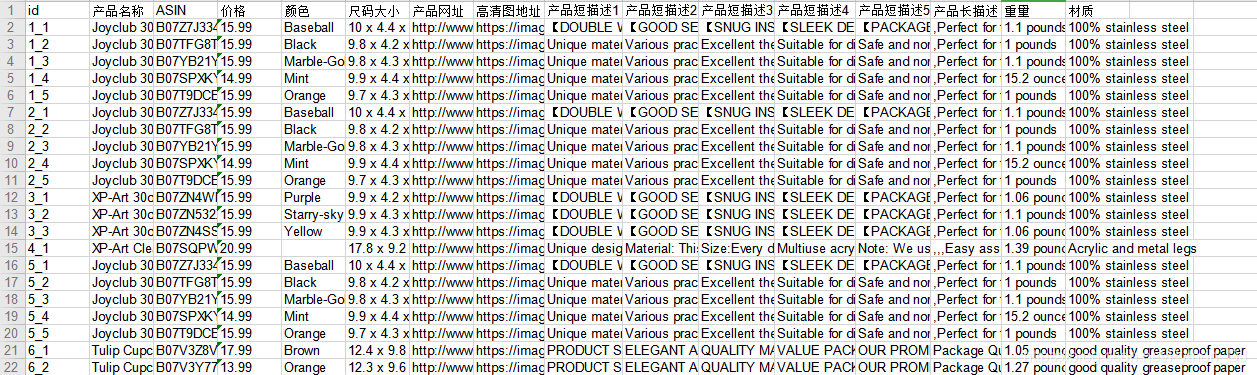
先上爬到结果,一睹芳容!
# settings.py我也就是修改了一下请求头,没有别的什么参数好设置的
DEFAULT_REQUEST_HEADERS = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3','accept-encoding': 'gzip, deflate, br','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',# 'accept-language': 'q=0.9,en;q=0.8','cookie': 'session-id=142-3668058-0487211; ubid-main=132-5736401-5537057; aws-priv=eyJ2IjoxLCJldSI6MCwic3QiOjB9; aws-target-static-id=1571291023940-335290; aws-target-data=%7B%22support%22%3A%221%22%7D; regStatus=pre-register; x-wl-uid=1LHDAujloWlUxmLRzSHozWKl4n+BjwQ2HAyx7BwxROqQZnIHpINHbdwLexNggVVlabqGiYHdV0mXMW5ff7gGrjphRIfQrPuY1K2hUDtmzEfxUq8TcFsULMzLCDQvtlRSLjglCTB2mI6s=; s_pers=%20s_fid%3D2A84D84A05E2C5F6-0DC9D42BD2FBEA5E%7C1730205389961%3B%20s_dl%3D1%7C1572354389963%3B%20gpv_page%3DUS%253AAS%253ASOA-overview-footer%7C1572354389971%3B%20s_ev15%3D%255B%255B%2527SCSOAlogin%2527%252C%25271571110956217%2527%255D%252C%255B%2527www.amz123.com%2527%252C%25271571446469054%2527%255D%252C%255B%2527SCSOAlogin%2527%252C%25271572352589980%2527%255D%255D%7C1730205389980%3B; s_fid=0AEE278A3A21C88C-034FF405EC91CDA6; s_vn=1602827024206%26vn%3D3; aws-target-visitor-id=1571291023943-752944.22_23; s_dslv=1572355541019; s_nr=1572355541021-Repeat; x-amz-captcha-1=1573628129095978; x-amz-captcha-2=py3BFrzl/i7mmCMvLgvRWQ==; session-id-time=2082787201l; x-main="ABFV62tSPQuPy5A0H2hXH2Nv6N?Zp0FnRoNywwX7sB3zYoSM94HI8tx5NgCAe1qG"; at-main=Atza|IwEBIBmgXA3krCYRAJ68T43x9IbC8ZiNWTKIS5uloe1JAnpwaOIQHK5jLLVgObHmiZ8UMEn8J5J7FK-bOFnwPodLFyBZYkW31uPz2dEqjRaK8PZrgpddmbTJ9KG4XhvcOoq0kMqfZUoBCL2QgV3ksB46tOO306Gf9BnmGk1_rTOMic7NFC9xsFzacybCm4RP4aAzuB-stwk7PoezghoWOQpT7zm3h5I8nsmK8kxUSz8iuouiG9v6gBPlyAetoPqa-3otO4yblvccuxYGaE-poYa3YrEsJRMRqAGrwpMskNgVQvNmw7E-7IkFyhCYknqjzt9P-HHs_bETzvXeCQOQteucpz3EXVBOeAf7-lAnWd4FtwA-7krD87ihhTiJANeB7yITUuXQGQP5IlHvSDcL9p37GQtI; sess-at-main="7/3eFhu1sYbjdEAn60gUzC3eSQSFPhjBNfi4dQuXwvs="; sst-main=Sst1|PQGB34zV-KtTdN4khU4KMMhpC-joyMrwsBrk4vA8n8M9ngDRZ0jZy68rXm0E8vH_CyBzoGL4W8x6XAsch693MoCyY5w1Aw2hIhCoafjkfOxhKrd9RHT0HDxZhQLAFTIs7DtW23UQkxccnPtletjCjGsCc8Cis27vApJr0p-0p6n-K9DOZzTFSV7O1l06ouOasxrVNOUjOXtxnsSRROguKnqoQSjCLUfJOnsiARe3ASEh_gRD13elbbBFrfH999dzBSL-A3UqGlXfiCXVTK3UGlWuKWftQGv6od-fjW7y5IQtE08VkOSKFIH28IsfstKJJZZ4TfVEniXGoDDGCuEexIzVeg; lc-main=en_US; i18n-prefs=USD; cdn-session=AK-608ed069117695d10fc5a061329ac781; session-token=wt43/36BLQUMTFbQvvH1QOKtBil240+5Mj4WSxFRfdFkcDCJPkc3ArqEArXxoq+VoWksSMKN62/Kq30lGL+yu/30jBNEmNBrYatWdHEBi3WCHskqtAkJsmiR0ZZdMYM6+1QSrCeiPejf7cnCLiaoyNHd0TXhurrBx5QAuBt/zOVNuSfAb13dr7TjZMHfkko4Bu0ytxEmXyMJYqI73S4b91kxLTlo4mmATe7Zx3XDNK9dl88aI5nbl9x+k1gbfilXToALWR8mIjDyYnaubUTkgQ==; skin=noskin; csm-hit=tb:CNZA0DXGWHXW3TBBB800+s-CNZA0DXGWHXW3TBBB800|1577070891800&t:1577070891800&adb:adblk_no','referer': 'https://www.amazon.com/ref=nav_logo?language=en_US','sec-fetch-mode': 'navigate',"sec-fetch-site": 'same-origin','sec-fetch-user': '?1','upgrade-insecure-requests': '1'
}
RANDOM_UA_TYPE = "chrome" # 使用谷歌的浏览器ua头
DOWNLOADER_MIDDLEWARES = {# 'yamaxun.middlewares.ProxyMiddleWare': 541,'yamaxun.middlewares.YamaxunDownloaderMiddleware': 543,'yamaxun.middlewares.RandomUserAgentMiddlware': 542,'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, # 需要将原始的设置为none
}
ITEM_PIPELINES = {# 'yamaxun.pipelines.YamaxunPipeline': 300,# 'yamaxun.pipelines.YamaxunPlPipeline': 301,# 'yamaxun.pipelines.YamaxunImgPipeline': 302,# 'yamaxun.pipelines.YamaxunFbmPipeline': 303,'yamaxun.pipelines.YamaxunCjPipeline': 304,
}
其他的都是一些常规设置,如:ROBOTSTXT_OBEY = False,不再赘述
#items.py 刚开始没头绪,本来想分主体和变体的,后来在分析中发现,没那个必要,名字没有main_也可以通用
class YamaxunCjItem(scrapy.Item):main_id = scrapy.Field() # idmain_url = scrapy.Field() # 主体urlmain_title = scrapy.Field() # 主体标题main_asin = scrapy.Field() # 主体ASINmain_price = scrapy.Field() # 主体价格main_color = scrapy.Field() # 主体颜色main_dimensions = scrapy.Field() # 主体尺码大小main_hdimgs = scrapy.Field() # 主体高清图URLmain_info_one = scrapy.Field() # 主体描述1main_info_two = scrapy.Field() # 主体描述2main_info_three = scrapy.Field() # 主体描述3main_info_four = scrapy.Field() # 主体描述4main_info_five = scrapy.Field() # 主体描述5main_description = scrapy.Field() # 主体长描述main_weight = scrapy.Field() # 主体重量main_material = scrapy.Field() # 主体材质
爬虫的主程序如下:
# -*- coding: utf-8 -*-
import scrapy
from yamaxun.items import YamaxunCjItemclass YamaxuncjSpider(scrapy.Spider):name = 'yamaxuncj'# 需要手动开启setting里面的管道custom_settings = {"ITEM_PIPELINES": {'yamaxun.pipelines.YamaxunCjPipeline': 304}}# allowed_domains = ['amazon.com']# start_urls = ['http://amazon.com']# 整个店铺 https://www.amazon.com/s?me=AHSA6JF4V43Q1&marketplaceID=ATVPDKIKX0DER# 店铺中的搜索关键字 https://www.amazon.com/s?k=thermos+cup&me=A2AJJBXRGY125X&ref=nb_sb_nossstart_url = []BASE_URL = "http://www.amazon.com"SUB_URL = "http://www.amazon.com/dp/"def __init__(self, *args, **kwargs):super(YamaxuncjSpider, self).__init__(*args, **kwargs)# goods_name = kwargs["goods_name"]# goods_name = "energy saving lamp" # 爬不同的数据,只需要修改这里,注意:保存文件名的修改,.txt和.json# self.url = "https://www.amazon.com/s?me=AHSA6JF4V43Q1&marketplaceID=ATVPDKIKX0DER"self.url = "https://www.amazon.com/s?k=thermos+cup&me=A2AJJBXRGY125X&ref=nb_sb_noss"def start_requests(self):print("当前链接是", self.url)yield scrapy.Request(url=self.url, callback=self.parse, dont_filter=True)def parse(self, response):print("---------------------------------进入到列表页------------------------------------------")# 进入到了列表页,不拿数据,主要在详情页拿数据# with open("asd.html", "w", encoding="utf-8") as f:# f.write(response.text)detail_url = response.css('a[class="a-link-normal a-text-normal"]::attr(href)').extract()if "?k" in self.url:detail_url = detail_url[1:]else:detail_url = detail_url[0:]id = 0# 测试单个商品拿数据# detail_url = [# "/Tulip-Cupcake-Liners-300-Pack-Restaurants/dp/B07V3Z8VLG/ref=sr_1_fkmr2_2?keywords=thermos+cup&m=A2AJJBXRGY125X&qid=1578100381&s=merchant-items&sr=1-2-fkmr2"]for i in detail_url:id += 1item = dict() # 设置一个空字典item["main_id"] = idurl = self.BASE_URL + iitem["main_url"] = urlprint("当前是第%d个链接" % id, url)yield scrapy.Request(url=ur这篇关于scrapy进阶《封号码罗》之如何优雅的征服世界首富亚马逊(amazon.com)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







