本文主要是介绍[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
贡献:为 one-to-one 的unpaired image translation 的生成图像提供多样性
提出假设:1、图像可以分解为style code 与 content code;2、不同领域的图像,共享一个content space,但是属于不同的style space;
style code captures domain-specific properties, and content code is domain-invariant. we refer to “content” as the underling spatial structure and “style” as the rendering of the structure
本文基于上述假设,使用c (content code)与s (style code)来表征图像进行图像转换任务。

related works
1、style transfer分为两类:example-guided style transfer 与collection style transfer (cyclegan)
2、Learning disentangled representations:InfoGAN and β-VAE
Model
模型训练流程图:

生成器模型:由两个encoder+MLP+decoder组成

损失函数
Bidirectional reconstruction loss
Image reconstruction
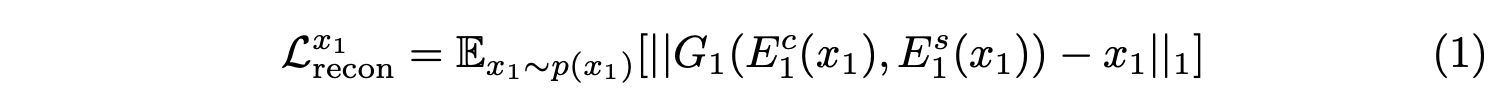
Latent reconstruction
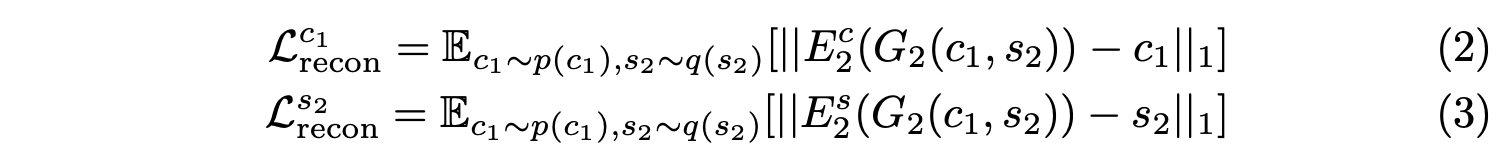
Adversarial loss
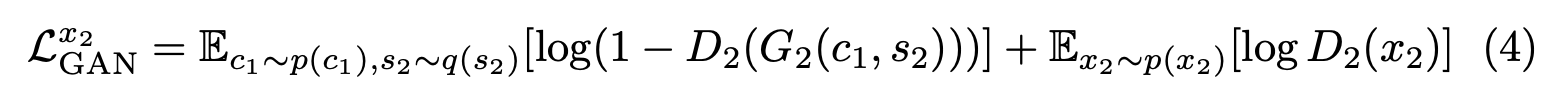
Total loss

Domain-invariant perceptual loss(补充)
可选择使用的一个损失:
传统的perceptual loss即使用两幅图像的VGG特征差异作为距离损失;这里提出的损失的改进即对特征进行了IN层归一化,去除原始特征的均值方差(为domain-specific信息),用于计算损失的两幅图像是真实图像与合成图像(同一content不同style)
实验发现,用了IN改进,same scene 的距离会小于同一domain的图像。

作者发现图像大小大于512时,该损失能加速训练。。。(感觉没什么用 )
评价指标与结果
LPIPS衡量多样性;Human performance score 衡量合成质量; CIS(IS改进版本)


代码笔记
训练时,主代码部分
# Start training
iterations = trainer.resume(checkpoint_directory, hyperparameters=config) if opts.resume else 0
while True:for it, (images_a, images_b) in enumerate(zip(train_loader_a, train_loader_b)):trainer.update_learning_rate()images_a, images_b = images_a.cuda().detach(), images_b.cuda().detach()with Timer("Elapsed time in update: %f"):# Main training codetrainer.dis_update(images_a, images_b, config)trainer.gen_update(images_a, images_b, config)torch.cuda.synchronize()# Dump training stats in log fileif (iterations + 1) % config['log_iter'] == 0:print("Iteration: %08d/%08d" % (iterations + 1, max_iter))write_loss(iterations, trainer, train_writer)# Write imagesif (iterations + 1) % config['image_save_iter'] == 0:with torch.no_grad():test_image_outputs = trainer.sample(test_display_images_a, test_display_images_b)train_image_outputs = trainer.sample(train_display_images_a, train_display_images_b)write_2images(test_image_outputs, display_size, image_directory, 'test_%08d' % (iterations + 1))write_2images(train_image_outputs, display_size, image_directory, 'train_%08d' % (iterations + 1))# HTMLwrite_html(output_directory + "/index.html", iterations + 1, config['image_save_iter'], 'images')if (iterations + 1) % config['image_display_iter'] == 0:with torch.no_grad():image_outputs = trainer.sample(train_display_images_a, train_display_images_b)write_2images(image_outputs, display_size, image_directory, 'train_current')# Save network weightsif (iterations + 1) % config['snapshot_save_iter'] == 0:trainer.save(checkpoint_directory, iterations)iterations += 1if iterations >= max_iter:sys.exit('Finish training')
trainer为MUNIT_Trainer类对象,该类包含了MUNIT模型的几乎所有操作,包括各个网络的初始化,优化器定义,网络前馈、网络优化等。这个类会相对冗杂,好处就是训练的主函数就只需要调用update_D与update_G就完事了,算是一种训练代码的风格。另一种代码风格就是StarGAN、StarGAN v2的,各个网络单独定义,没有Trainer这种类,因此train的主函数会比较复杂。
1、该类的初始化定义如下:
class MUNIT_Trainer(nn.Module):def __init__(self, hyperparameters):super(MUNIT_Trainer, self).__init__()lr = hyperparameters['lr']# Initiate the networksself.gen_a = AdaINGen(hyperparameters['input_dim_a'], hyperparameters['gen']) # auto-encoder for domain aself.gen_b = AdaINGen(hyperparameters['input_dim_b'], hyperparameters['gen']) # auto-encoder for domain bself.dis_a = MsImageDis(hyperparameters['input_dim_a'], hyperparameters['dis']) # discriminator for domain aself.dis_b = MsImageDis(hyperparameters['input_dim_b'], hyperparameters['dis']) # discriminator for domain bself.instancenorm = nn.InstanceNorm2d(512, affine=False)self.style_dim = hyperparameters['gen']['style_dim']# fix the noise used in samplingdisplay_size = int(hyperparameters['display_size'])self.s_a = torch.randn(display_size, self.style_dim, 1, 1).cuda()self.s_b = torch.randn(display_size, self.style_dim, 1, 1).cuda()# Setup the optimizersbeta1 = hyperparameters['beta1']beta2 = hyperparameters['beta2']dis_params = list(self.dis_a.parameters()) + list(self.dis_b.parameters())gen_params = list(self.gen_a.parameters()) + list(self.gen_b.parameters())self.dis_opt = torch.optim.Adam([p for p in dis_params if p.requires_grad],lr=lr, betas=(beta1, beta2), weight_decay=hyperparameters['weight_decay'])self.gen_opt = torch.optim.Adam([p for p in gen_params if p.requires_grad],lr=lr, betas=(beta1, beta2), weight_decay=hyperparameters['weight_decay'])self.dis_scheduler = get_scheduler(self.dis_opt, hyperparameters)self.gen_scheduler = get_scheduler(self.gen_opt, hyperparameters)# Network weight initializationself.apply(weights_init(hyperparameters['init']))self.dis_a.apply(weights_init('gaussian'))self.dis_b.apply(weights_init('gaussian'))# Load VGG model if neededif 'vgg_w' in hyperparameters.keys() and hyperparameters['vgg_w'] > 0:self.vgg = load_vgg16(hyperparameters['vgg_model_path'] + '/models')self.vgg.eval()for param in self.vgg.parameters():param.requires_grad = False1.1 生成器AdaINGen的定义如下:
class AdaINGen(nn.Module):# AdaIN auto-encoder architecturedef __init__(self, input_dim, params):super(AdaINGen, self).__init__()dim = params['dim']style_dim = params['style_dim']n_downsample = params['n_downsample']n_res = params['n_res']activ = params['activ']pad_type = params['pad_type']mlp_dim = params['mlp_dim']# style encoderself.enc_style = StyleEncoder(4, input_dim, dim, style_dim, norm='none', activ=activ, pad_type=pad_type)# content encoderself.enc_content = ContentEncoder(n_downsample, n_res, input_dim, dim, 'in', activ, pad_type=pad_type)self.dec = Decoder(n_downsample, n_res, self.enc_content.output_dim, input_dim, res_norm='adain', activ=activ, pad_type=pad_type)这篇关于[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!