本文主要是介绍InPlusLab关于QoS预测综述论文被TSC录用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【导读】随着Web服务数量不断增加,越来越多的Web服务提供相似的功能。服务质量(Quality of Service,QoS)描述了Web服务的非功能特性,是区分这些功能相似Web服务的重要标准。准确的QoS预测对于这些QoS感知方法越来越重要。协同过滤(CF)是推荐系统中最成功的个性化预测技术之一,在Web服务QoS预测中也得到了广泛的应用。尽管在这方面已有大量的工作,但似乎没有一个权威的调研综述。为了弥补这一不足,最近,中山大学InPlusLab关于协同过滤在Web服务QoS预测应用的调研综述论文Web Service QoS Prediction via Collaborative Filtering: A Survey被IEEE Transactions on Services Computing(TSC)期刊录用,影响因子5.707。文章首先总结和分析了传统的基于内存和基于模型的CF-QoS预测方法以及扩展CF方法。其次,调研了混合CF-QoS预测方法,并给出了适当的分类和分析。此外,还介绍了几个用于QoS预测评估的Web服务QoS数据集,并在最后提出一些可能的未来QoS预测的研究方向。
论文下载链接: http://inpluslab.com/files/wsqos.pdf

1. 简介
QoS预测对一些QoS感知的方法非常重要,比如图1的基于QoS的服务选择:复合服务S_com由几个抽象服务(S1到S5)组成,每个抽象服务都可以从一组功能相似的具体服务(si1, si2, …, siN)中选择。QoS感知服务选择的目的是从这些功能相似的服务集合中选择合适的服务,形成一个优化的复合服务。

QoS预测的方法分类如下:
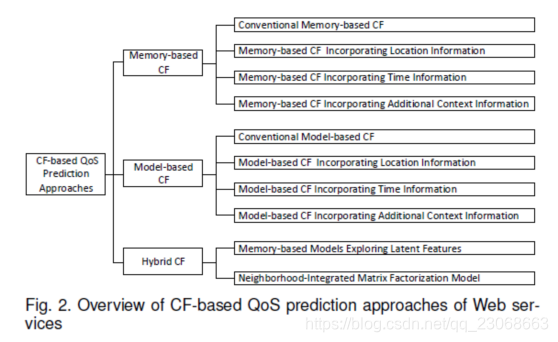
2. QoS预测问题介绍
这篇关于InPlusLab关于QoS预测综述论文被TSC录用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
