本文主要是介绍【字符识别】基于matlab BP神经网络字符识别【含Matlab源码 1358期】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✅博主简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,Matlab项目合作可私信。
🍎个人主页:海神之光
🏆代码获取方式:
海神之光Matlab王者学习之路—代码获取方式
⛳️座右铭:行百里者,半于九十。
更多Matlab仿真内容点击👇
Matlab图像处理(进阶版)
路径规划(Matlab)
神经网络预测与分类(Matlab)
优化求解(Matlab)
语音处理(Matlab)
信号处理(Matlab)
车间调度(Matlab)
⛄一、手写数字识别技术简介
1 案例背景
手写体数字识别是图像识别学科下的一个分支,是图像处理和模式识别研究领域的重要应用之一,并且具有很强的通用性。由于手写体数字的随意性很大,如笔画粗细、字体大小、倾斜角度等因素都有可能直接影响到字符的识别准确率,所以手写体数字识别是一个很有挑战性的课题。在过去的数十年中,研究者们提出了许多识别方法,并取得了一定的成果。手写体数字识别的实用性很强,在大规模数据统计如例行年检、人口普查、财务、税务、邮件分拣等应用领域都有广阔的应用前景"。
本案例讲述了图像中手写阿拉伯数字的识别过程,对手写数字识别的基于统计的方法进行了简要介绍和分析,并通过开发一个小型的手写体数字识别系统来进行实验。手写数字识别系统需要实现手写数字图像的读取功能、特征提取功能、数字的模板特征库的建立功能及识别功能。
2 BP算法与实现过程
2.1 BP算法基本原理
将已知输入向量和相应的输出向量(期望输出)作为训练样本,并假定即将学习的网络已被赋予一组权值。为消除梯度幅度的不利影响,利用弹性反向传播算法通过过如下步骤更新权值(图1):首先,使用初始权值(不管正确与否)从输入层开始向前传播,计算出所有神经元的输出,这样输出层的输出与期望输出(即输出值与目标值)之间存在较大的误差。然后,计算作为神经元权值函数的]误差函数(损失函数或目标函数、代价函数)的梯度,根据误差降低最快的方向来调整更新权值,通过将输出误差反向传播给隐含层来不断调整误差函数。在计算误差梯度的同时,使用与上面同样的方法更新隐含层的权值。反复迭代更新,直到损失函数达到预定的理想目标。在弹性反向传播算法的学习过程中,权值的修正值即为学习率,而梯度只影影响权值变化的方向,即正负。
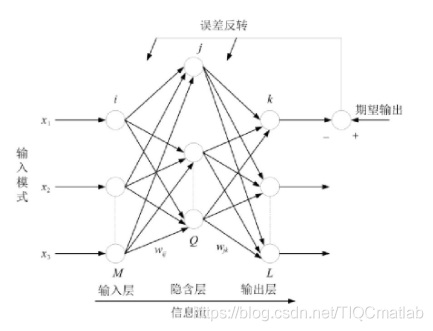
图1 反向传播神经网络模型
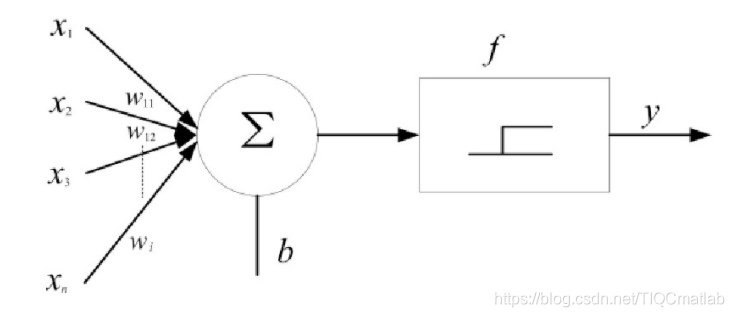
1.2 感知器神经网络
感知器(multilayer perceptron, MLP) 神经网络是模式识别的简单二元分类人工网络, 它通过权值模仿神经细胞的突触,用激活函数模仿细胞体,偏置即为阈值。单层的感知器网络结构如图2所示。单层感知器可将外部输入x分成两类:当感知器的输出y为正数或零时,输入属于第一类;当感知器的输出为负数时,输入属于第二类。
1.3 实现过程
(1)图像读取
在本文中,设计并自建了样本的数据库,库中有0~9共10个阿拉伯数字的5000张不同的手写数字图像,均为白底黑色的bmp格式的文件, 每个数字对应500张图片。实验要从每一个数字中都随机选取450张手写图像作为训练样本,每一个数字剩下的50张作为测试样本。部分数字样张如图3所示。
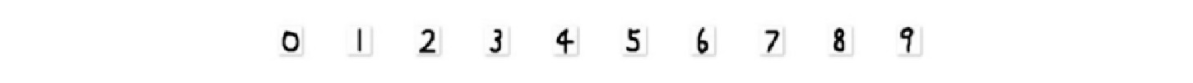
图3 数字样张
(2)提取特征
本设计中的训练样本数量多,而而一般神经网络输入层的神经元数就是训练样本向量的维数,因此需要对训练样本向量做降维预处理。预处理过程就是通过灰度阈值函数将图像转换成二值图像。降维前需先将所有图像做一次缩放,以确保每个图像的输入向量都具有相同的像素。本设计选定图像缩放的高度和宽度分别为70像素点和50像素点,符合一般手写阿拉伯数字的高宽比。对这些缩放后的图像作纵横切割,如图4所示,每10×10个像素点作为一系列像素块,构成一张包含35个像素块的二值图像计算每一个像素块中0和1的占比,并用它作为模式的一个特征值,这样可以构成5x7的特征值矩阵。考虑到感知器神申经网络输入向量只能是一维,故需要将此矩阵转换成一维向量作为训练样本的输入,转置后共生成35个一维向量。

图4 缩放后的图像切割
(3)构造标签
无论是训练样本还是测试样本,都需要构造标签,前者用于映射的学习,后者用于判断训练网络的正确率。一般地,输出层神经元个数即为分类网络中的分类类别数。阿拉伯数字是10类,故输出神经元数为10。每个类由具体的500个图像构成,包含训练样本和测试样本。通过提取特征每个类均生成35个一维向量:用500个列向量(1000000000)T来标注模式1,即数字1;(0100000000)标注模式2,即数字2;(0010000000)标注模式3,即数字3;依此类推,最后的(0000000001)标注模式0,即数字0。运行代码如下:
(4)随机选定训练样本和测试样本测试
利用MATLAB中已有的rand()伪随机数生成函数来生成5000个介于0和1之间的伪随机数。将生成的伪随机数做升序排序,通过索引来记录随机数原来的位置,并将原来的位置组合成新的行向量。在本设计中,输入层的神经元有35个,输出层神经元有10个,选取25为中间隐含层神经元个数。
(5)数字识别与正确率的计算
对比测试前的标签和仿真后的输出,用测试前的标签值减去输出值,得到误差值,将误差为0的视为正确识别,求出神经网络的正确率。具体运行代码如下:
⛄二、部分源代码
clc; clear all; close all;
warning off all;
% 获取字符集
fd = fullfile(pwd, ‘images’, ‘dbx’);
fds = dir(fd);
ts = [];
for i = 1 : length(fds)
if isequal(fds(i).name, ‘.’) || isequal(fds(i).name, ‘…’)
continue;
end
ts{end+1} = fds(i).name;
end
files = GetAllFiles(fd);
% 提取字符集合的特征向量
db_file = fullfile(pwd, ‘VL.mat’);
if exist(db_file, ‘file’)
load(db_file);
else
VT = [];
LT = [];
for i = 1 : length(files)
im = imread(files{i});
[~, v] = get_feature(im);
% 特征
VT = [VT v];
[pn, ~, ~] = fileparts(files{i});
[~, nm, ~] = fileparts(pn);
for j = 1 : length(ts)
if isequal(ts{j}, nm)
% 标签
LT = [LT j];
break;
end
end
end
save(db_file, ‘VT’, ‘LT’);
end
% BP训练
net_file = fullfile(pwd, ‘bp_net.mat’);
if exist(net_file, ‘file’)
load(net_file);
else
p_train=VT;
t_train=LT;
[pn,minp,maxp,tn,mint,maxt] = premnmx(p_train, t_train);
threshold=minmax(pn);
net=newff(threshold,[30,20,10,1],{'tansig','tansig','tansig','purelin'},'trainlm');
net.trainParam.epochs=10000;
net.trainParam.goal=1e-5;
net.trainParam.show=50;
net.trainParam.lr=0.01;
net=train(net,pn,tn);
% 存储网络
save(net_file, 'net', 'minp', 'maxp', 'mint', 'maxt');
end
m=1;%图片的亮度系数对与识别成功率影响很大,如果图片本身对比度很高(你的图片的对比度就很高)值设为1即可,如果光线较暗可适当提高数值反之亦然。
%类似我文件夹中的图片,需将m设置为0.5~0.3,否则连续域处理无法实现程序无法响应
[fn,pn,fi]=uigetfile(‘.jpg’,‘选择图片’); %选择图片
I=imread([pn fn]);figure(1),imshow(I);title(‘原始图像’);%显示原始图像
%J=imadjust(I,[0.2 0.6],[0 1],m);figure(2),imshow(J);title(‘灰度图像’); %调整图像灰度并调高亮度
grayimg = I;BWimg = grayimg;[width,height]=size(grayimg);%灰度图数据传递,导入宽高
%thresh = graythresh(I); %自动确定二值化阈值;
A=im2bw(I,0.6); % thresh=0.5 表示将灰度等级在128以下的像素全部变为黑色,将灰度等级在128以上的像素全部变为白色。
figure(3);imshow(A);title(‘二值化图像’);%显示图像
bw = edge(A,‘sobel’,‘vertical’); figure(4); imshow(bw);title(‘边缘图像’); % 垂直边缘检测
Z = strel(‘rectangle’,[30,18]);%连通域处理
bw_close=imclose(bw,Z);figure(5);imshow(bw_close);title(‘闭操作’);%连通域闭处理
%bw_open = imopen(bw,Z);figure(6);imshow(bw_open );title(“开操作”);%连通域开处理
showImg = grayimg;%灰度图数据传递
%图像数据二值化处理,如果图像尺度过大会使处理时间几何倍增加,所以尽量使用小尺度图片,(你的图片完全OK)我提供个测试图片就属于过大的了
for i=1:width
for j=1:height
if(BWimg(i,j) == 255)
showImg(i,j)= grayimg(i,j);
else
showImg(i,j)= 0;
end
end
end
figure(6);
imshow(showImg);%可视化显示二值化图像
[l,m] = bwlabel(bw_close); %连续域标签
status=regionprops(l,‘BoundingBox’);%图像区域度量
centroid = regionprops(l,‘Centroid’);%字符区域度量
imshow(I);hold on;
a=[-7,-7,7,7];
if m>1
for i=1:m
if status(i).BoundingBox(1,3) > status(i).BoundingBox(1,4)%归一化预处理
status(i).BoundingBox(1,4)=status(i).BoundingBox(1,3);
else
status(i).BoundingBox(1,3)=status(i).BoundingBox(1,4);
end
status(i).BoundingBox=status(i).BoundingBox+a;
rectangle(‘position’,status(i).BoundingBox,‘edgecolor’,‘g’);%字符画框
text(centroid(i,1).Centroid(1,1)-25,centroid(i,1).Centroid(1,2)-25, num2str(i),‘Color’, ‘r’) %字符框标号
end
for i=1:m
cropimg_2 = imcrop(A,status(i).BoundingBox);%画框部分图像截取
cropimg_2 = imresize(cropimg_2,[28,28]); %将图像调整为2828的
%cropimg_2 = imcomplement(cropimg_2);
[file_path,,]= fileparts(mfilename(‘fullpath’));
disp(file_path)
imwrite(cropimg_2,[file_path,’\LXJC\‘,num2str(m,’%02d’),‘.bmp’],‘bmp’)%将截取部分的图像暂时存储在LXSB文件中
filePath = [file_path,‘\LXJC\’,num2str(m,‘%02d’),‘.bmp’];%打开图像
if isequal(filePath, 0)
break;
end
[~, p_test] = get_feature(im);
p2n = tramnmx(p_test,minp, maxp);
r=sim(net,p2n);
r2n = postmnmx(r,mint,maxt);r = ts{r};
figure;imshow(cropimg_2);title(r, 'FontSize', 16);
end
else
end
function [bwz, p] = get_feature(im)
% 计算特征向量
bw = im2bw(im,graythresh(im));
bw = ~bw;
[r, c] = find(bw);
rect = [min©-1 min®-1 max©-min©+2 max®-min®+2];
bwt = imcrop(bw, rect);
rate = 70/size(bwt, 1);
rc = round(size(bwt)rate);
bwt = imresize(bwt, rc, ‘bilinear’);
if size(bwt, 2) < 50
bwz = zeros(70, 50);
ss = round((size(bwz, 2)-size(bwt,2))0.5);
tt = round((size(bwz, 1)-size(bwt,1))0.5);
bwz(:, ss:ss+size(bwt,2)-1) = bwt;
else
bwz = imresize(bwt, [70 50], ‘bilinear’);
end
bwz = logical(bwz);
for k=1:7
for k2=1:5
dt=sum(bwz(((k10-9):(k10)),((k210-9):(k2*10))));
f((k-1)*5+k2)=sum(dt);
end
end
f=((100-f)/100);
p = f(😃;
function filePath = OpenImageFile(imgfilePath)
% 打开文件
% 输出参数:
% filePath——文件路径
if nargin < 1
imgfilePath = fullfile(pwd, ‘images/testx/Ⅰ-003.bmp’);
end
% 读取文件
[filename, pathname, ~] = uigetfile( …
{ ‘.bmp;.jpg;.tif;.png;.gif’,‘All Image Files’;…
'.', '所有文件 (.*)’}, …
‘选择文件’, …
‘MultiSelect’, ‘off’, …
imgfilePath);
filePath = 0;
return;
end
filePath = fullfile(pathname, filename);
⛄三、运行结果
⛄四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]李亚光,郑小平,肖广耀,田亚强,陈连生.BP神经网络在中厚板字符识别中的应用[J].华北理工大学学报(自然科学版). 2022,44(04)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
🍅 仿真咨询
1 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化
2 机器学习和深度学习方面
卷积神经网络(CNN)、LSTM、支持向量机(SVM)、最小二乘支持向量机(LSSVM)、极限学习机(ELM)、核极限学习机(KELM)、BP、RBF、宽度学习、DBN、RF、RBF、DELM、XGBOOST、TCN实现风电预测、光伏预测、电池寿命预测、辐射源识别、交通流预测、负荷预测、股价预测、PM2.5浓度预测、电池健康状态预测、水体光学参数反演、NLOS信号识别、地铁停车精准预测、变压器故障诊断
3 图像处理方面
图像识别、图像分割、图像检测、图像隐藏、图像配准、图像拼接、图像融合、图像增强、图像压缩感知
4 路径规划方面
旅行商问题(TSP)、车辆路径问题(VRP、MVRP、CVRP、VRPTW等)、无人机三维路径规划、无人机协同、无人机编队、机器人路径规划、栅格地图路径规划、多式联运运输问题、车辆协同无人机路径规划、天线线性阵列分布优化、车间布局优化
5 无人机应用方面
无人机路径规划、无人机控制、无人机编队、无人机协同、无人机任务分配
6 无线传感器定位及布局方面
传感器部署优化、通信协议优化、路由优化、目标定位优化、Dv-Hop定位优化、Leach协议优化、WSN覆盖优化、组播优化、RSSI定位优化
7 信号处理方面
信号识别、信号加密、信号去噪、信号增强、雷达信号处理、信号水印嵌入提取、肌电信号、脑电信号、信号配时优化
8 电力系统方面
微电网优化、无功优化、配电网重构、储能配置
9 元胞自动机方面
交通流 人群疏散 病毒扩散 晶体生长
10 雷达方面
卡尔曼滤波跟踪、航迹关联、航迹融合
这篇关于【字符识别】基于matlab BP神经网络字符识别【含Matlab源码 1358期】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









