本文主要是介绍PowerBI--使用PowerQuery清洗数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
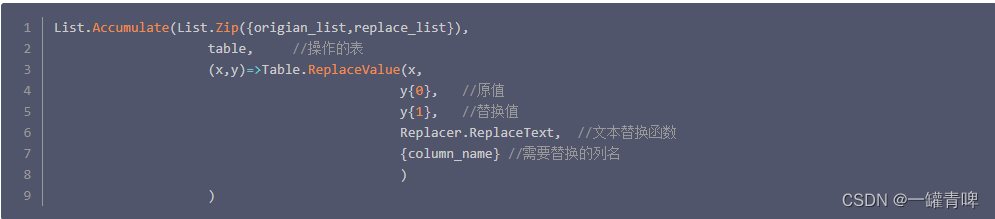
1、使用List.Accumulate批量值的替换:List.Accumulate(List.Zip({{original_list}, {replace_list}}), table, (x,y)=>Table.ReplaceValue(x, y{0}, y{1}, Replacer.ReplaceValue, {columns}))
let源 = MySQL.Database("192.168.9.128", "Stock_10jqka", [ReturnSingleDatabase=true]),Stock_10jqka_Daily_Stock_Info = 源{[Schema="Stock_10jqka",Item="Daily_Stock_Info"]}[Data],排序 = Table.ReorderColumns(Stock_10jqka_Daily_Stock_Info,{"代码", "名称", "主力净量", "散户数量", "主力金额", "涨幅%", "星级", "现价", "涨速", "总手", "换手", "量比", "总金额", "涨跌", "买价", "卖价", "现手", "涨速%", "实体涨幅", "现均差%", "换手%", "委比%", "总市值", "流通市值", "流通比例", "内盘", "外盘", "内外比", "备注", "TTM市盈率", "净利润?", "市净率", "每股盈利", "昨收", "开盘", "开盘涨幅", "最高", "最低", "5日涨幅", "10日涨幅", "20日涨幅", "年初至今", "振幅%", "买量", "卖量", "笔数", "贡献度", "机构动向", "异动类型", "总股本", "流通股本", "利润总额", "净利润增长率", "每股净资产", "金叉个数", "净流入", "大单流入", "大单流出", "大单净额", "大单净额占比", "大单总额", "大单总额占比", "中单流入", "中单流出", "中单净额", "中单净额占比", "中单总额", "中单总额占比", "小单流入", "小单流出", "小单净额", "小单净额占比", "小单总额", "小单总额占比", "今日增仓占比%", "今日排名", "今日涨幅%", "2日增仓占比%", "2日排名", "2日涨幅", "3日增仓占比%", "3日排名", "3日涨幅", "5日增仓占比%", "5日排名", "10日增仓占比%", "10日排名", "细分行业", "所属行业", "利空", "利好", "数据日期", "Id"}),替换异常值 = List.Accumulate(List.Zip({{"--", "有", "无"}, {"", "True", "False"}}),排序,(x,y)=>Table.ReplaceValue(x, y{0}, y{1},Replacer.ReplaceValue,{"主力净量", "散户数量", "主力金额", "涨幅%", "星级", "现价", "涨速", "总手", "换手", "量比", "总金额", "涨跌", "买价", "卖价", "现手", "涨速%", "实体涨幅", "现均差%", "换手%", "委比%", "总市值", "流通市值", "流通比例", "内盘", "外盘", "内外比", "备注", "TTM市盈率", "净利润?", "市净率", "每股盈利", "昨收", "开盘", "开盘涨幅", "最高", "最低", "5日涨幅", "10日涨幅", "20日涨幅", "年初至今", "振幅%", "买量", "卖量", "笔数", "贡献度", "机构动向", "异动类型", "总股本", "流通股本", "利润总额", "净利润增长率", "每股净资产", "金叉个数", "净流入", "大单流入", "大单流出", "大单净额", "大单净额占比", "大单总额", "大单总额占比", "中单流入", "中单流出", "中单净额", "中单净额占比", "中单总额", "中单总额占比", "小单流入", "小单流出", "小单净额", "小单净额占比", "小单总额", "小单总额占比", "今日增仓占比%", "今日排名", "今日涨幅%", "2日增仓占比%", "2日排名", "2日涨幅", "3日增仓占比%", "3日排名", "3日涨幅", "5日增仓占比%", "5日排名", "10日增仓占比%", "10日排名","利空", "利好"})),数据类型转换 = Table.TransformColumnTypes(替换异常值,{{"主力净量", type number}, {"散户数量", type number}, {"主力金额", type number}, {"涨幅%", type number}, {"星级", type number}, {"现价", type number}, {"涨速", type number}, {"总手", type number}, {"换手", type number}, {"量比", type number}, {"总金额", type number}, {"涨跌", type number}, {"买价", type number}, {"卖价", type number}, {"现手", type number}, {"涨速%", type number}, {"实体涨幅", type number}, {"现均差%", type number}, {"换手%", type number}, {"委比%", type number}, {"总市值", type number}, {"流通市值", type number}, {"流通比例", type number}, {"内盘", type number}, {"外盘", type number}, {"内外比", type number}, {"备注", type number}, {"TTM市盈率", type number}, {"净利润?", type number}, {"市净率", type number}, {"每股盈利", type number}, {"昨收", type number}, {"开盘", type number}, {"开盘涨幅", type number}, {"最高", type number}, {"最低", type number}, {"5日涨幅", type number}, {"10日涨幅", type number}, {"20日涨幅", type number}, {"年初至今", type number}, {"振幅%", type number}, {"买量", type number}, {"卖量", type number}, {"笔数", type number}, {"贡献度", type number}, {"机构动向", type number}, {"异动类型", type number}, {"总股本", type number}, {"流通股本", type number}, {"利润总额", type number}, {"净利润增长率", Currency.Type}, {"每股净资产", type number}, {"金叉个数", type number}, {"净流入", type number}, {"大单流入", type number}, {"大单流出", type number}, {"大单净额", type number}, {"大单净额占比", type number}, {"大单总额", type number}, {"大单总额占比", type number}, {"中单流入", type number}, {"中单流出", type number}, {"中单净额", type number}, {"中单净额占比", type number}, {"中单总额", type number}, {"中单总额占比", type number}, {"小单流入", type number}, {"小单流出", type number}, {"小单净额", type number}, {"小单净额占比", type number}, {"小单总额", type number}, {"小单总额占比", type number}, {"今日增仓占比%", type number}, {"今日排名", type number}, {"今日涨幅%", type number}, {"2日增仓占比%", type number}, {"2日排名", type number}, {"2日涨幅", type number}, {"3日增仓占比%", type number}, {"3日排名", type number}, {"3日涨幅", type number}, {"5日增仓占比%", type number}, {"5日排名", type number}, {"10日增仓占比%", type number}, {"10日排名", type number}})
in数据类型转换2、使用Table.ReplaceValue进行条件替换;
情景如下:
如何找出一列中包含任意数字的行?比如,我们想找出车号列。车号中,肯定是要包含0-9的一个数字的,如果没数字的话,就认为此行作废。
Table.SelectRows( table, each List.Count(Splitter.SplitterTextbyAnyDelimiter({"0".."9"})(_[车号]))>1)
3、实例
let文件夹 = "D:\采购对账\安丘尚居\",文件表 = Table.SelectRows( Folder.Files(文件夹), each Text.Contains([Name], "尚居")),// 最近文件 = List.Min(List.MaxN(Table.SelectRows(文件表, each Text.Contains([Name], "鑫汇")),1)),最新时间 = List.Max(文件表[Date modified]),示例文件 = 文件夹& Table.SelectRows(文件表, each [Date modified]=最新时间)[Name]{0},源 = Excel.Workbook(File.Contents(示例文件)),展开 = Table.SelectRows(源,each not Text.Contains([Name],"$"))[Data]{0},提标 = Table.RenameColumns(展开, List.Zip({Table.ColumnNames(展开), List.Transform(Table.ToList( Table.Transpose(Table.FindText(展开, "车"))), each Text.Remove(_, " "))}),MissingField.Ignore),筛选 = Table.SelectRows(提标, each List.Count(Splitter.SplitTextByAnyDelimiter({"0".."9"})([车号]))>1),改类型 = Table.TransformColumnTypes(筛选,{{"毛重时间", type datetime}, {"毛重", type number}, {"皮重", type number}, {"净重", type number}, {"皮重时间", type datetime}}),分组 = Table.ExpandTableColumn(Table.Group(改类型, {"车号"}, {"尚居", each _}), "尚居", {"毛重时间", "净重","流水号"}, {"尚居.毛重时间", "尚居.净重","尚居.流水号"}),排序 = Table.Buffer(Table.Sort(分组, {{"车号", Order.Ascending},{"尚居.毛重时间", Order.Ascending}})),索引 = Table.AddIndexColumn(排序, "索引", 0, 1, Int64.Type),二出 = Table.AddColumn(索引, "尚居.下次出厂时间", each try if [车号] = 索引{[索引]+1}[车号] then 索引{[索引]+1}[尚居.毛重时间] else 月底日期 otherwise 月底日期)in二出
这篇关于PowerBI--使用PowerQuery清洗数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





