本文主要是介绍【软件测试】超细HttpRunner接口自动化框架使用案例,一篇策底打通...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
1、HttpRunner框架安装
# 安装httprunner
pip install httprunner# 当然也可以指定版本安装
pip install httprunner==2.3.2# 检验安装是否成功
hrun -V
2、HttpRunner框架demo介绍
#创建HttpRunner项目
hrun --startproject demo #指定目录创建HttpRunner项目
hrun --startproject D:\TestSoftware\Pychram\PychramProject\demo
#api文件:* 用以保存单个独立的接口,最好是可以单独运行的(例如:保存一个公共方法用于case调用,调用格式:api/XXX.json或者是api/XXX.yaml)
# testcase文件:* 用以保存一个或者多个接口组成的测试用例(也能集合其它case进行顺序执行,调用格式:testcase/xxx.json或者是api/XXX.yaml)# 执行测试用例则在项目控制台下:
hrun testcases/xx.json
# 或
hrun testcases/xx.yaml# testsuites文件:* 多个测试用例的集合(用例集执行顺序是无序的)
# reports文件:* 运行用例后生成测试报告的位置# debugtalk.py文件:* 在文件中定义方法(可以用其它.py文件写方法再进行调用,调用格式:${getdemo()))# .env文件:* 自定义变量(调用格式:${.ENV(demo)}
因不同公司要求不一样,JSON与Yaml文件可以在:http://www.json2yaml.com/ 上互传
3、以JSON文件处理不同方式的请求
1)get方式发送请求
# 在testcases下新建 get请求.json
{"config": {"name": "模块名称","base_url": "主机IP地址和端口"},"teststeps": [{"name":"Get方式","request": {"url": "/Api url地址","method": "GET","params": {"username": "abc","password": "123","phone": "12345678901","email": "abc@163.com"}}}]
}
2)post方式发送请求
# 在testcases下新建 post请求.json
{"config": {"name": "模块名称","base_url": "主机IP地址和端口"},"teststeps": [{"name": "Post方式","request": {"url": "API url地址","method": "POST","data": {"username": "zhangsan","password": "123"}},"validate":[{"contains": ["content.msg","登录成功!!"]}]}]
}
3)json方式发送请求
# 在testcases下新建 json请求.json
{"config": {"name": "模块名称","base_url": "主机IP地址和端口"},"teststeps": [{"name": "json报文处理","request": {"url": "/Api url地址","method": "POST","json": {"username": "lisi","password": "123","phone": "123456","email": "lisi@163.com"}},"validate": [{"eq": ["content.msg","注册成功"]}]}]
}
4)上传文件
首先在debugtalk.py文件里添加getFile函数
def getFile():f = open("文件存放地址\\文件名称.png",mode="rb")return f
# 在testcases下新建 Uploadfile.json
# 使用${getFile()} 引用函数
{"config": {"name": "模块名称","base_url": "主机IP地址和端口"},"teststeps": [{"name": "上传文件","request": {"url": "/Api url地址","method": "POST","data": {"username": "lisi"},"files":{"pic": ["woman0.png","${getFile()}","image/png"]}}}]
}
5)参数化
第一种方式-variables设置变量
# 在testcases下新建 parameter.json
{"config": {"name": "模块名称","base_url": "主机IP地址和端口","variables": {"name": "a8","pwd": "123456"}},"teststeps": [{"name": "参数化","request": {"url": "/Api url地址","method": "POST","data": {"username": "$name","password": "$pwd"}},"validate": [{"eq":["content.msg","success"]}]}]
}
第二种方式–p获取函数
首先在项目目录下新建package dada,在data下创建user.csv文件
name,pwd,extra
a1,123,success
a2,456,登录失败
#¥@,123,登录失败
再在testsuites目录下新建 login_param.json
{"config": {"name": "login_参数化处理"},"testcases": [{"name": "loginTest","testcase": "testcases/login.json", "parameters": [{"name-pwd-extra":"${P(data/user.csv)}"}]}]
}
最后在testcases目录下,新建login.json
# 直接引用自定义名称
{"config": {"name": "模块名称","base_url": "主机Ip和端口"},"teststeps": [{"name": "登录","request": {"url": "Api url地址","method": "POST","data": {"username": "$name","password": "$pwd"}},"validate":[{"contains": ["content.msg","$extra"]}]}]
}
6)接口依赖处理
# 在testcases下新建 api依赖.json
{"config": {"name": "模块名称","base_url": "主机IP地址和端口","variables": {"name": "b1","pwd": "123456","email": "b1@163.com"}},"teststeps": [{"name": "获取验证码","request": {"url": "/Api url地址","method": "GET"},"extract": [{"code": "content.data.code"}],"validate": [{"eq": ["content.msg","success"]}]},{"name": "注册","request": {"url": "/Api url地址","method": "POST","data": {"username": "$name","password":"$pwd" ,"email":"$email" ,"verifyCode":"$code"}},"validate": [{"contains": ["content.msg","注册成功"]}]}]
}
4、批量执行case
在testsuites目录下新建 批量执行.json
{"config": {"name": "接口自动化学习案例"},"testcases": [{"name": "测试_get请求","testcase": "testcases/get请求.json"},{"name": "测试_post请求","testcase": "testcases/post请求.json"},{"name": "测试_json请求","testcase": "testcases/json请求.json"},{"name": "测试_json请求","testcase": "testcases/Uploadfile.json"},{"name": "测试_依赖处理","testcase": "testcases/api依赖.json"}]
}
控制台
hrun testsuites/批量执行.json
5、输出测试报告
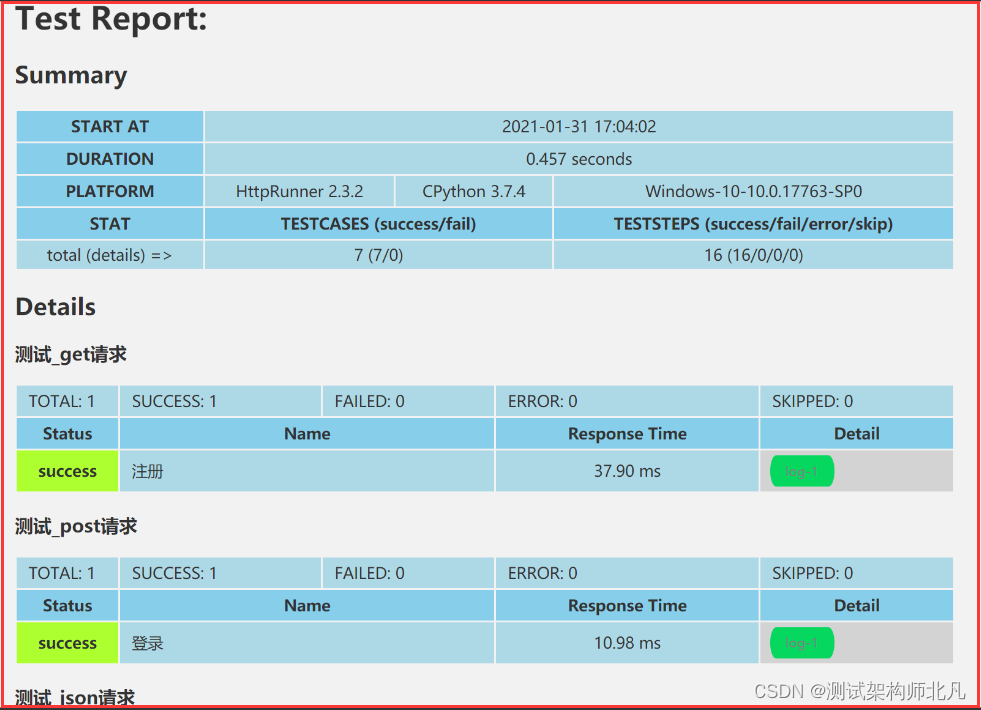
1)原生测试报告
通过控制台 hrun testsuites/xx.json 测试通过后,在项目目录下的reports下自动生成报告
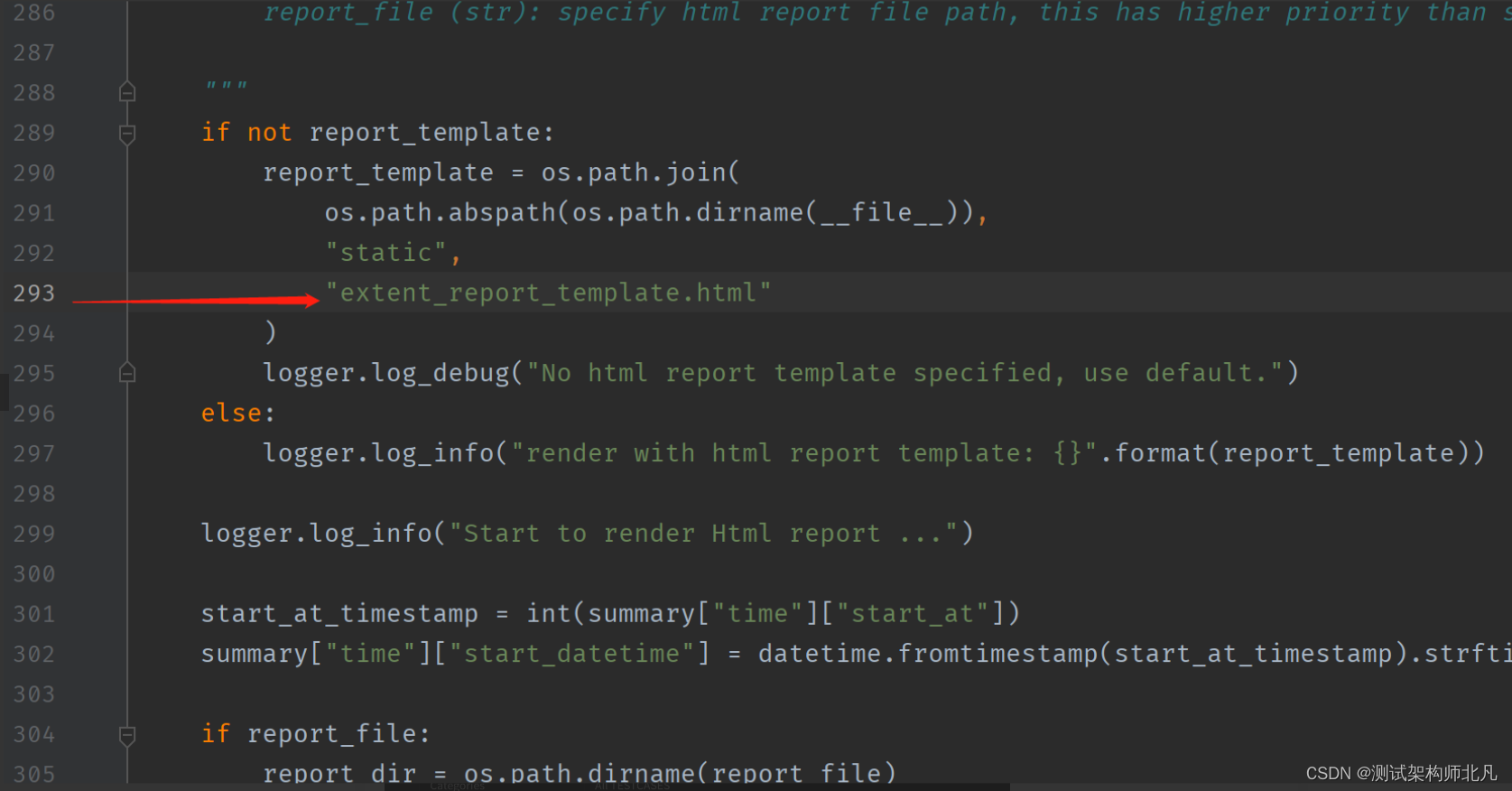
2)测试报告优化
进入在Lib\site-packages\httprunner\static下 ,添加extent_report_template.html,在Lib\site-packages\httprunner下,修改report.py中的默认报告路径
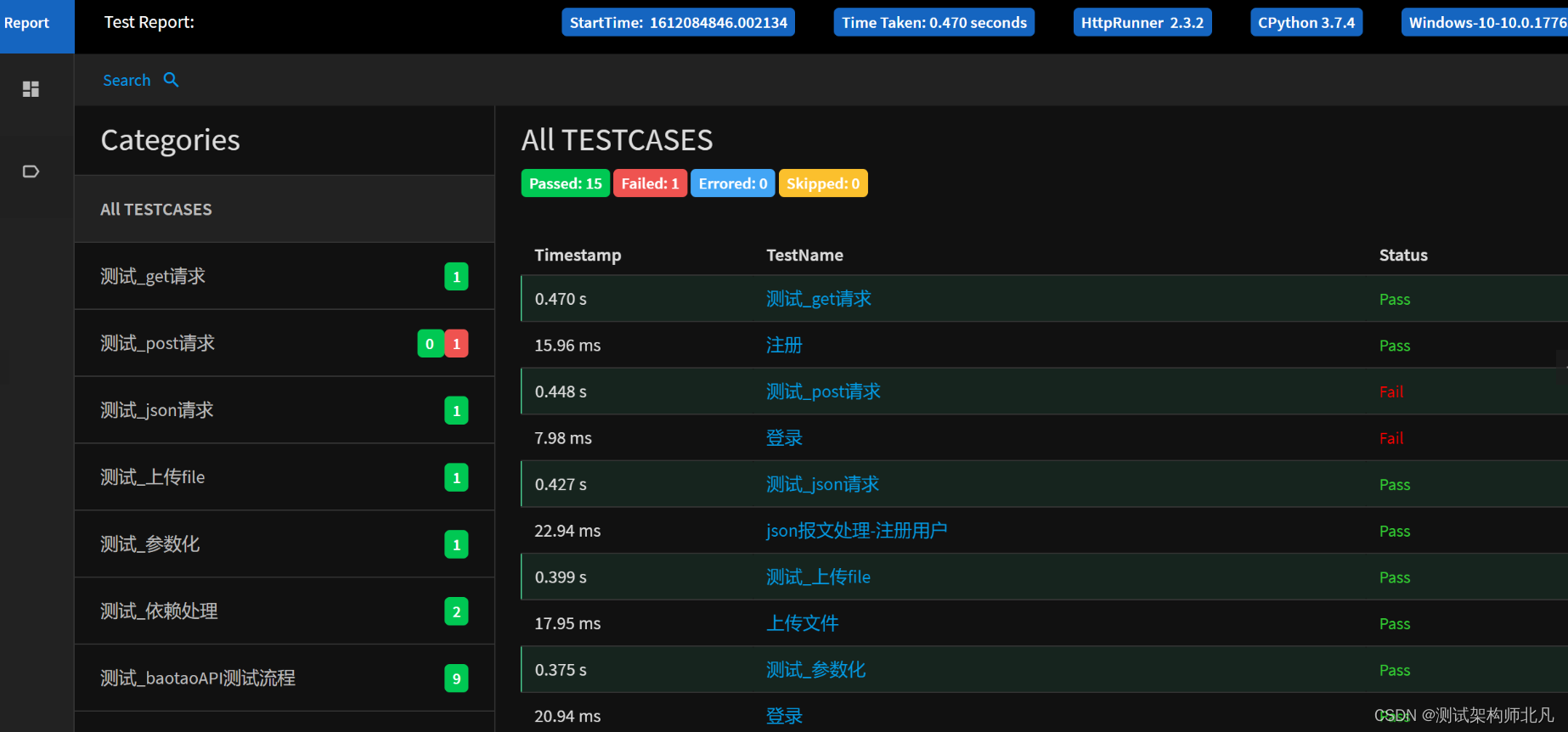
修改后变更为:
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
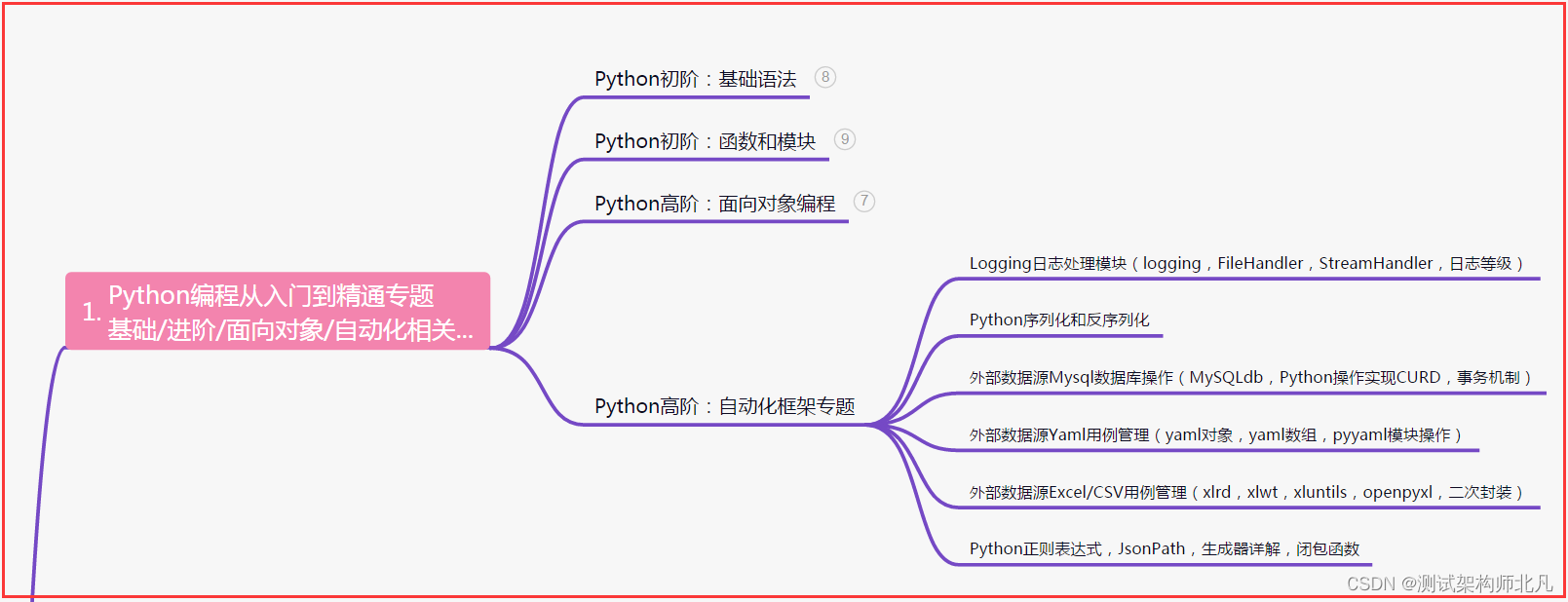
二、接口自动化项目实战
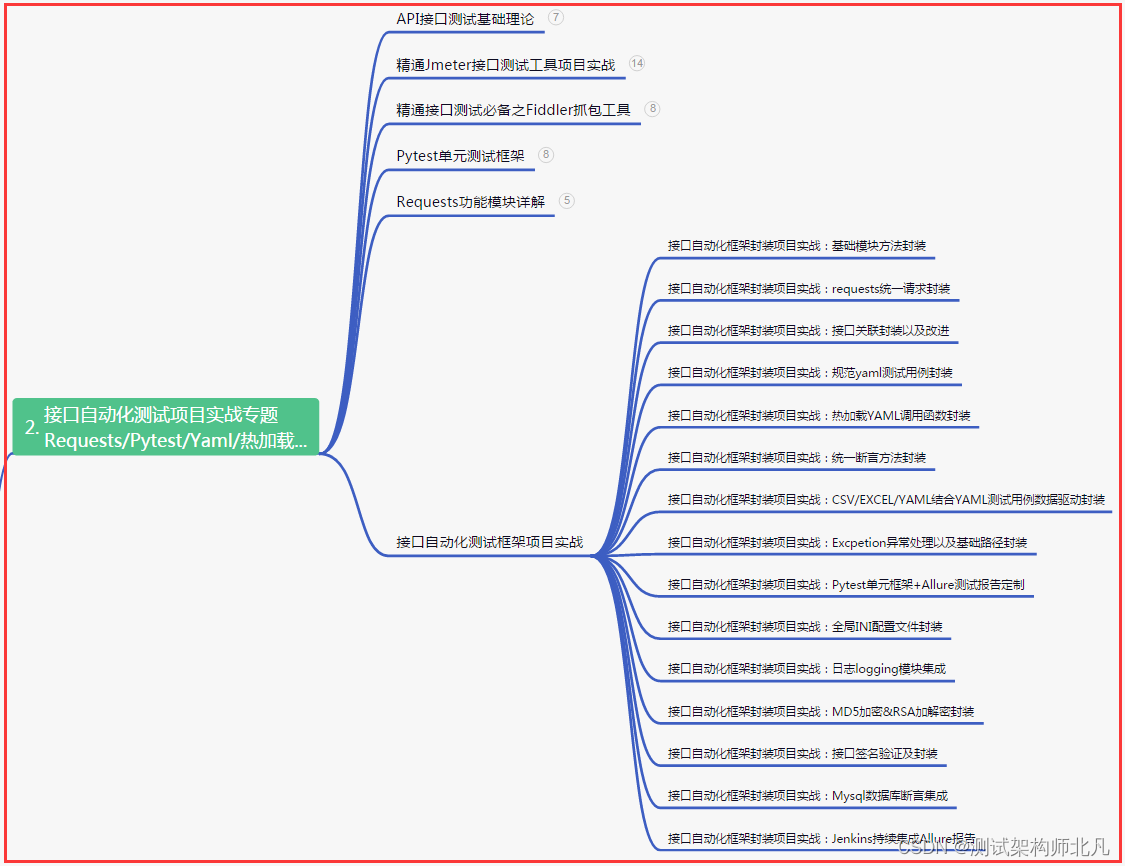
三、Web自动化项目实战
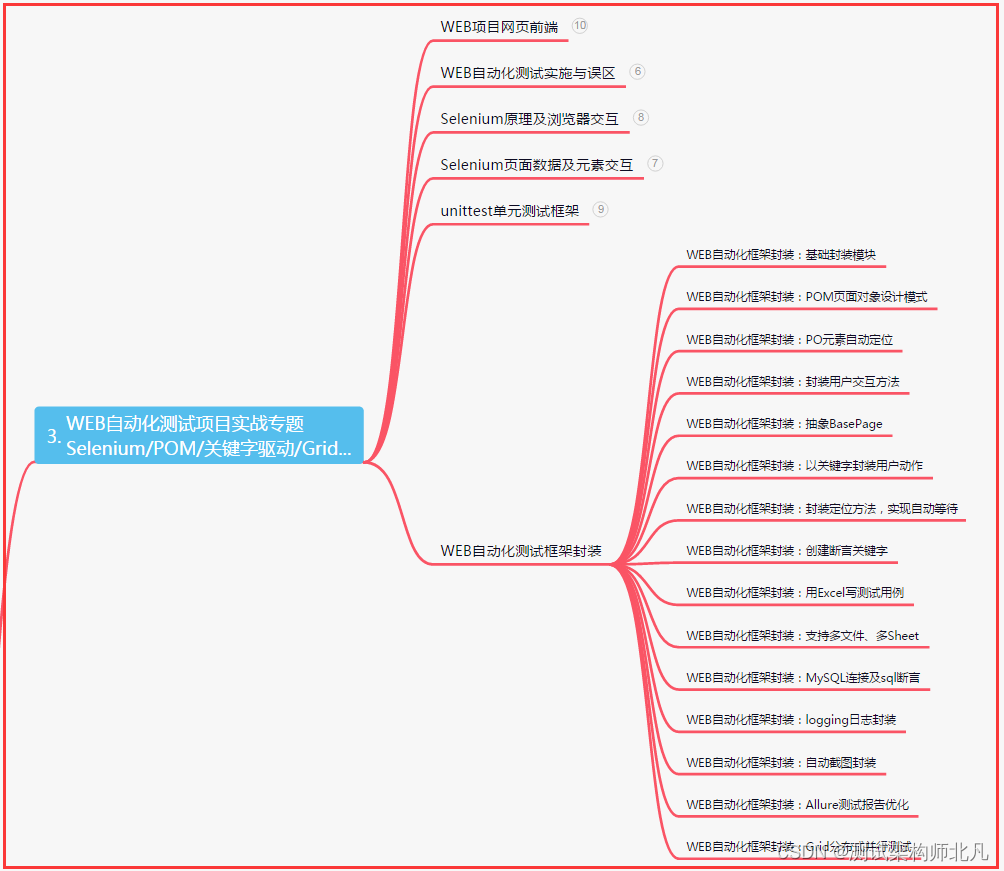
四、App自动化项目实战
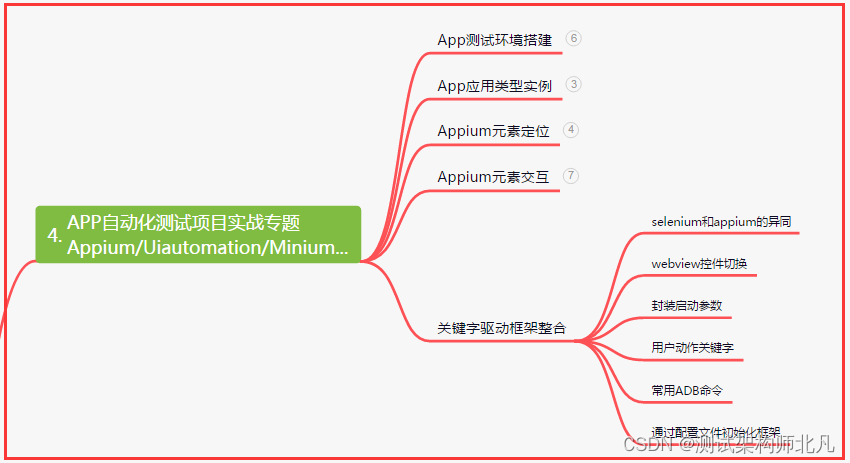
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试
九、总结(尾部小惊喜)
只要你有梦想,就要勇敢地去追求它,不要被困难和阻碍所吓倒。相信自己的能力和价值,坚定地走下去,成功就在前方等待着你!
每一次的努力都是一次积累,每一次的奋斗都是一次成长。不要畏惧困难,坚持追逐梦想,因为只有不停前行,才能创造属于自己的辉煌人生!
成功需要的不仅仅是才华和机遇,更需要的是坚持和不懈的努力。只要你保持着热情和毅力,就一定能够实现自己的理想!
这篇关于【软件测试】超细HttpRunner接口自动化框架使用案例,一篇策底打通...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






