本文主要是介绍31 select max/min/avg/sum/count/group_concat 的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
avg, sum, max, min, count 的相关使用
这里来调试一下 具体的情况, 以及看一下 索引对于相关操作的影响
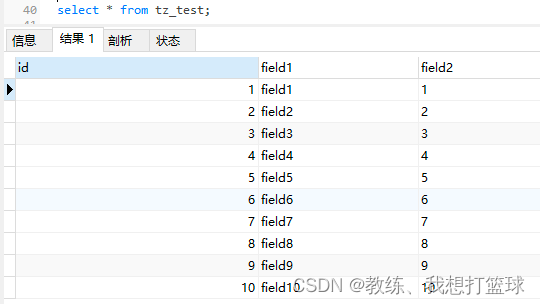
测试数据表如下
CREATE TABLE `tz_test` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`field1` varchar(12) DEFAULT NULL,`field2` varchar(16) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,KEY `field1` (`field1`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
测试数据如下
select max/min
这两者 差不多, 因此 我们这里 仅仅看一下 select max
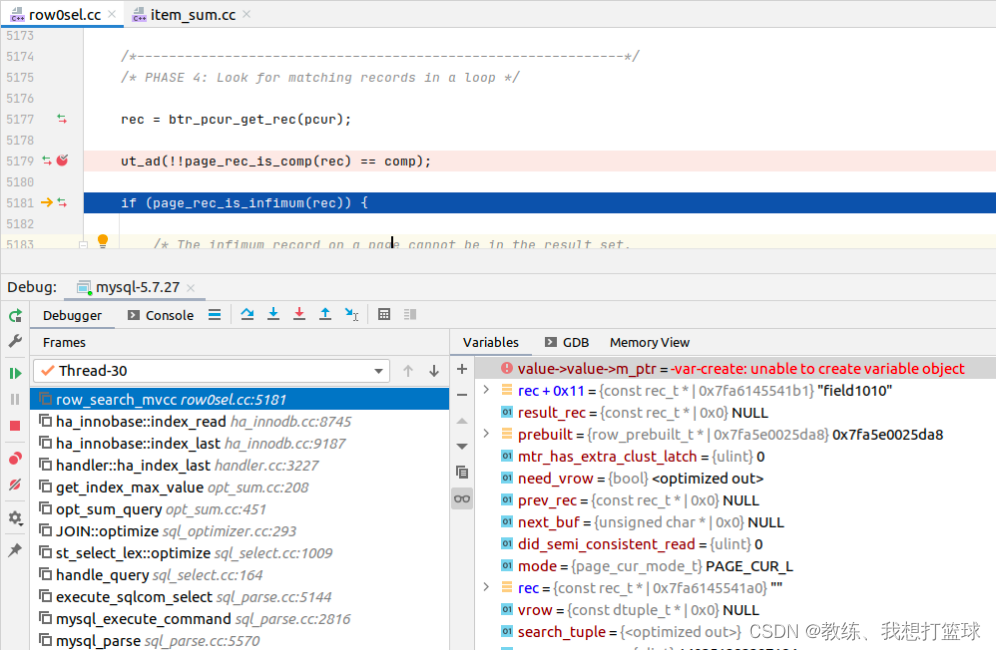
执行 “select max(id) from tz_test;” 如下
根据索引查询获取最大的值, 这里获取到的是 10 对应的记录
然后 因为有索引, 仅仅会查询 最大 的那条记录
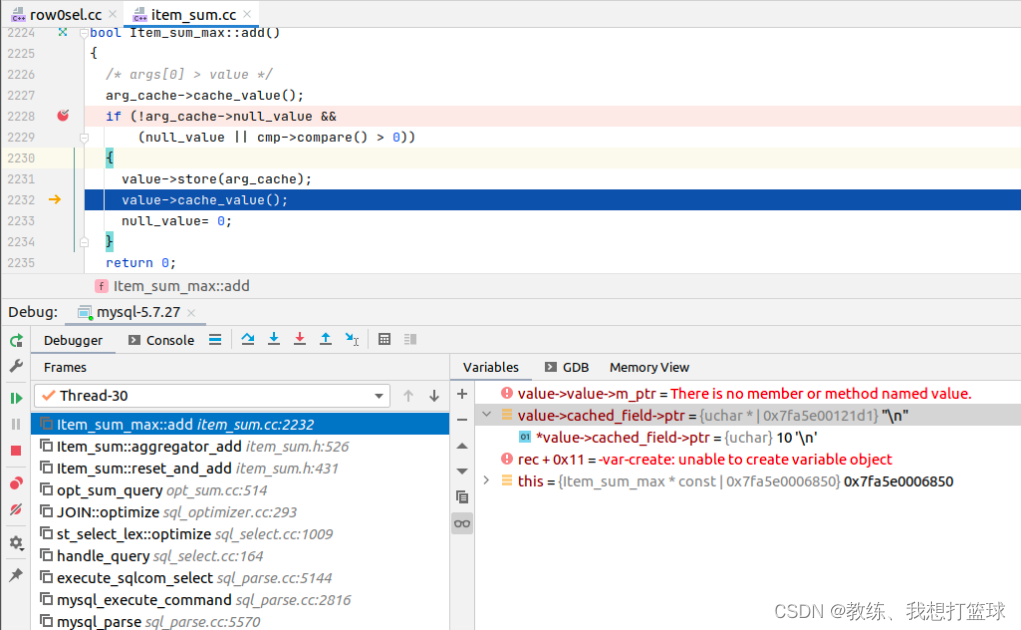
然后 merge 的时候, 只会处理 最大 的这条记录, 更新为 结果
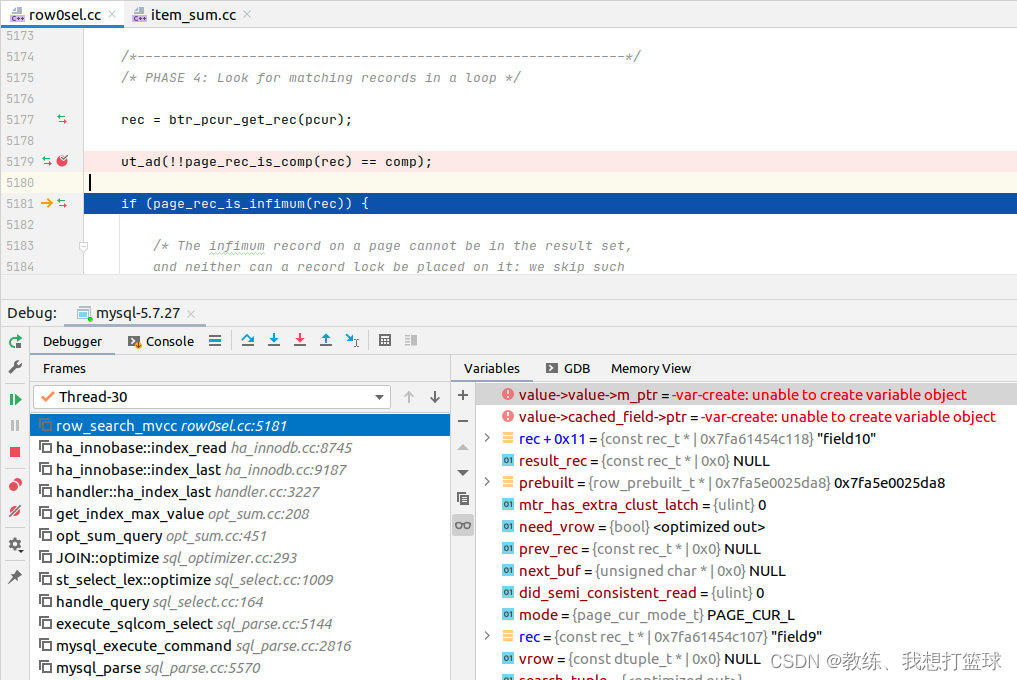
执行 “select max(field1) from tz_test;” 如下
和上面同样, field1 有索引, 然后 仅仅获取 最大的这条记录
然后 merge 的时候, 只会处理 最大 的这条记录, 更新为 结果
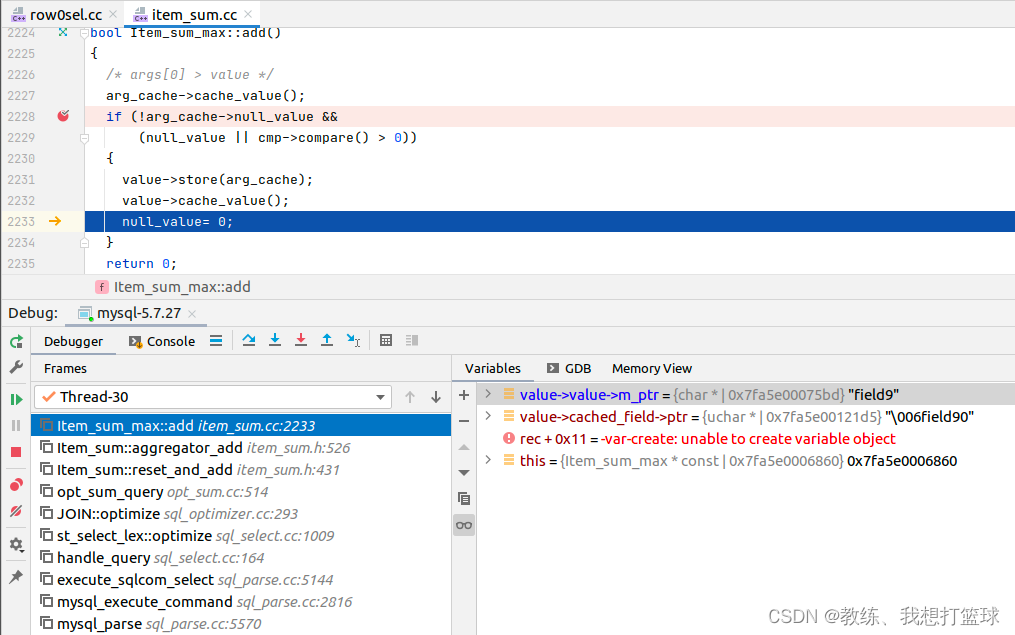
执行 “select max(field2) from tz_test;” 如下
遍历 tz_test 表的所有的记录, 然后开始 merge
从1, 2, 3, .., 10 开始遍历
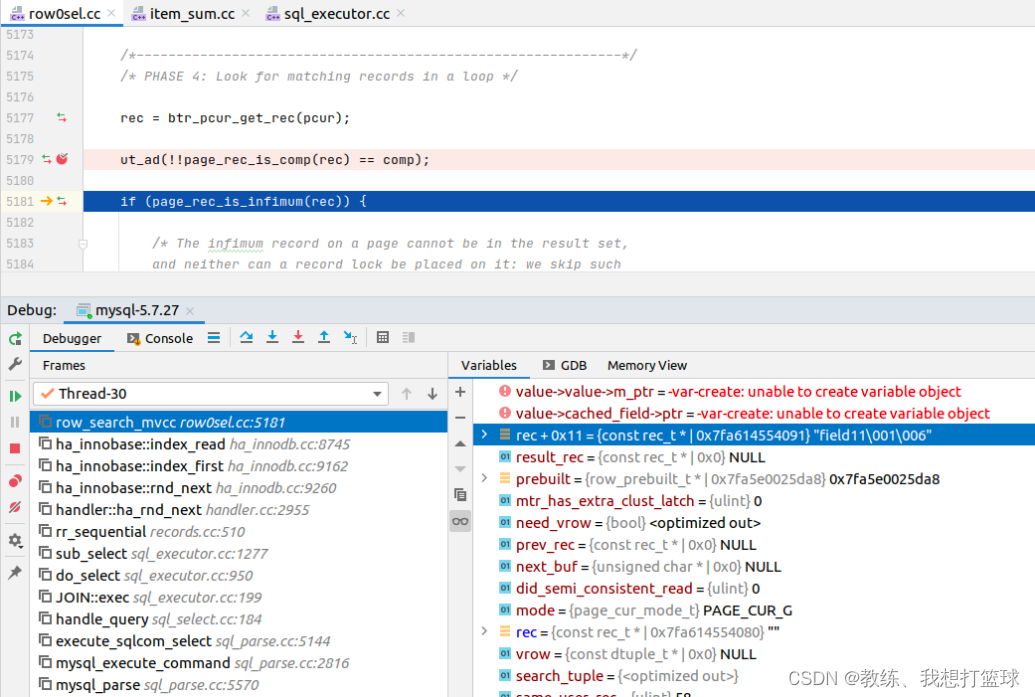
然后 merge 的时候, 依次比较, 获取最大的记录为结果
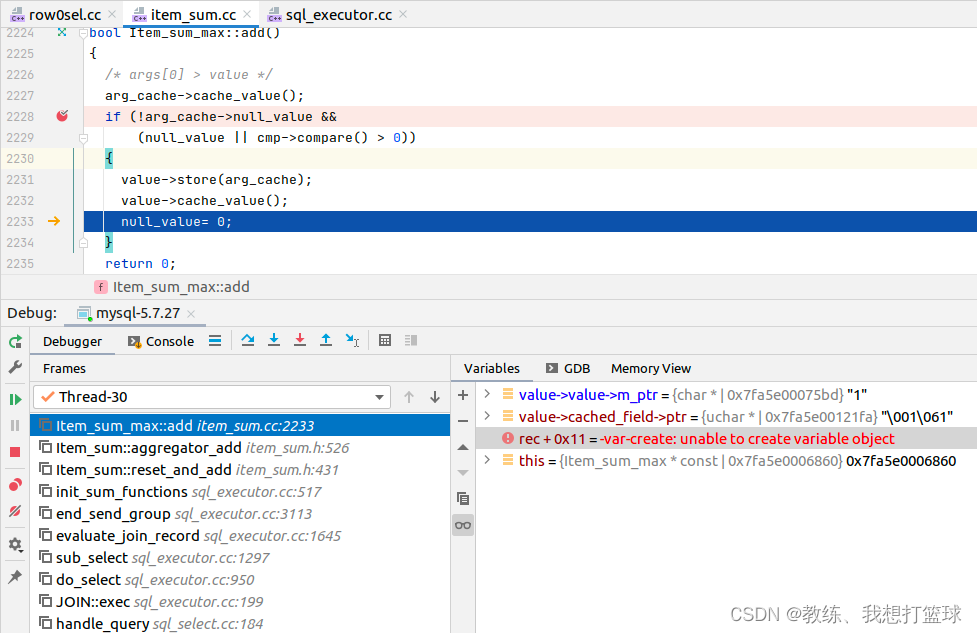
select min 的流程类似, 只是 merge 的方式 有一些差异
select count/sum/avg
执行 “select count(id) from tz_test;” 如下
遍历的数据如下, 可以看到的是 遍历的是 field1 的索引树

然后 merge 的时候, 仅仅统计数量记录为结果

执行 “select count(field1) from tz_test;” 如下
遍历的数据如下, 可以看到的是 遍历的是 field1 的索引树

执行 “select count(field2) from tz_test;” 如下
遍历的数据如下, 可以看到的是 遍历的是 tz_test 的所有记录
select sum 的流程类似, 只是 merge 的方式 有一些差异

select avg 的流程类似, 只是 merge 的方式 有一些差异

select group_concat
执行 “select group_concat(field1) from tz_test;” 如下
然后这里 如果是 “select group_concat(id) from tz_test;”, “select group_concat(field1) from tz_test;” 走的是 field1 的索引
如果是 “select group_concat(field2) from tz_test;” 走的是全表扫描
然后 我们这里 着重关注一下 group_concat 的实现
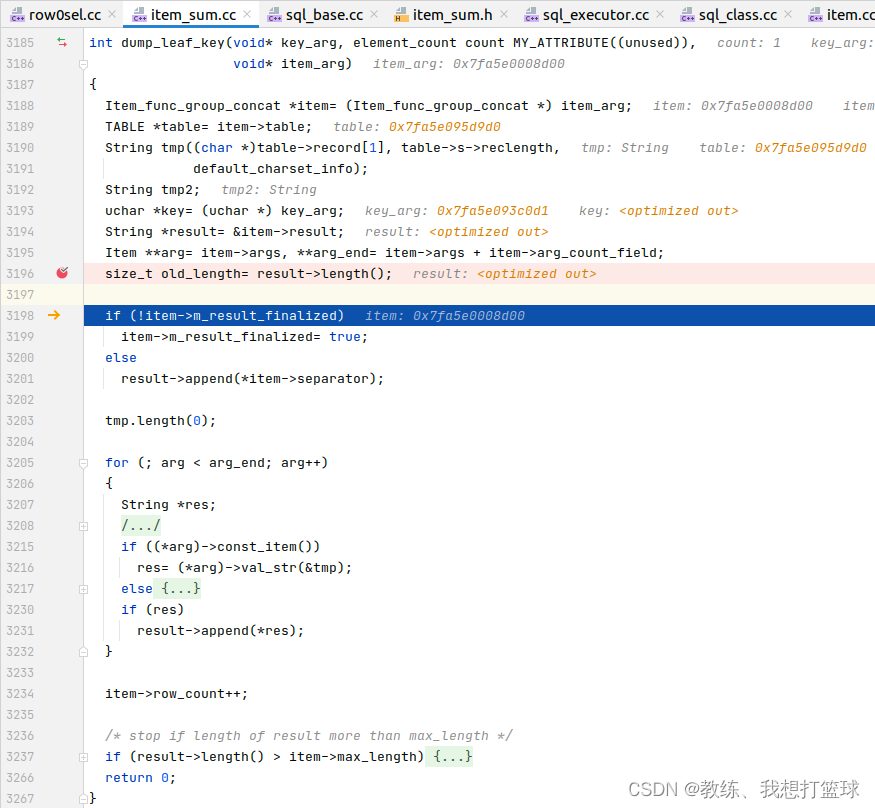
实现如下, result 作为容器, 然后使用 item->separator 来 join 选择列的值的列表
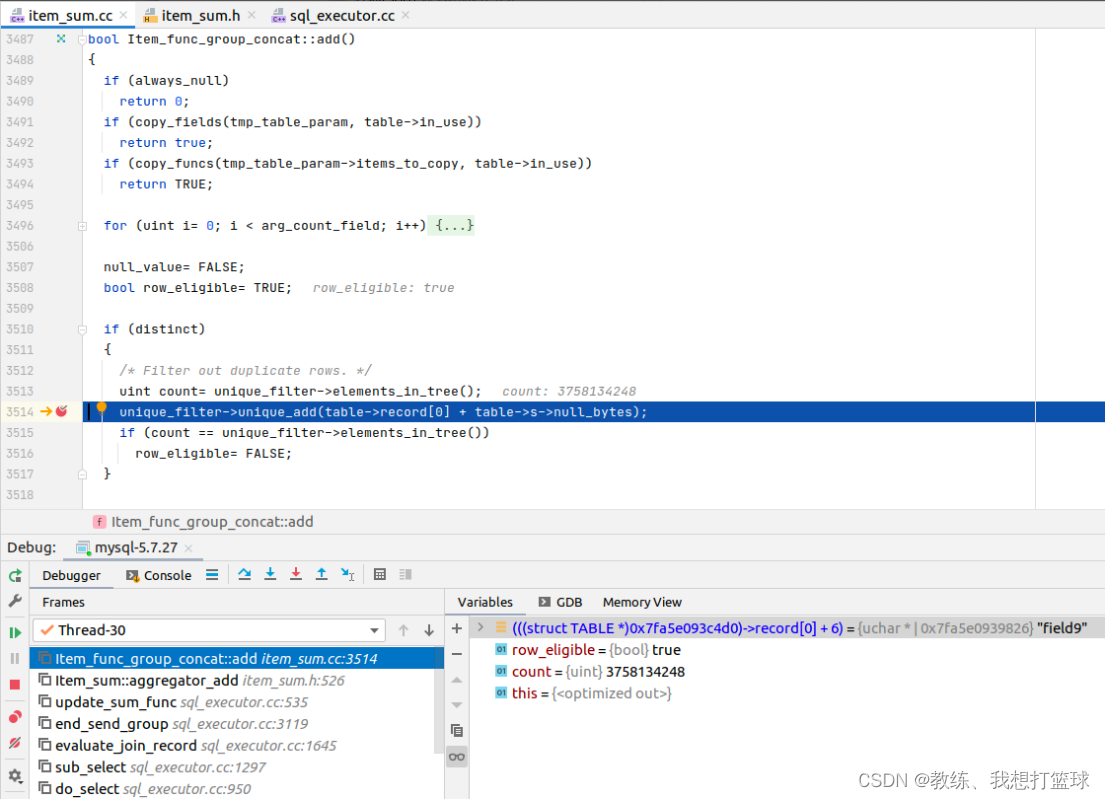
Item_func_group_concat::add 调用的这里的 dump_leaf_key
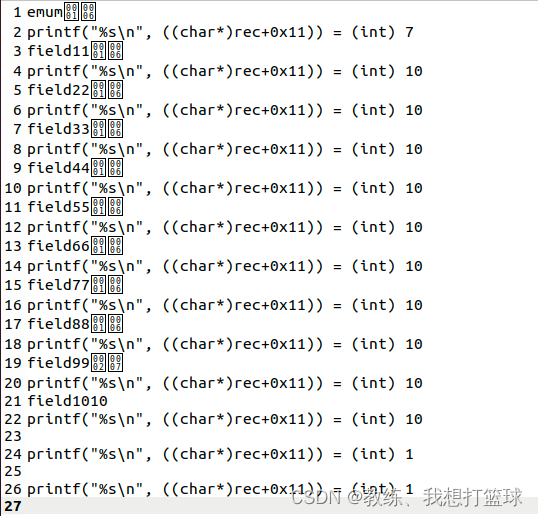
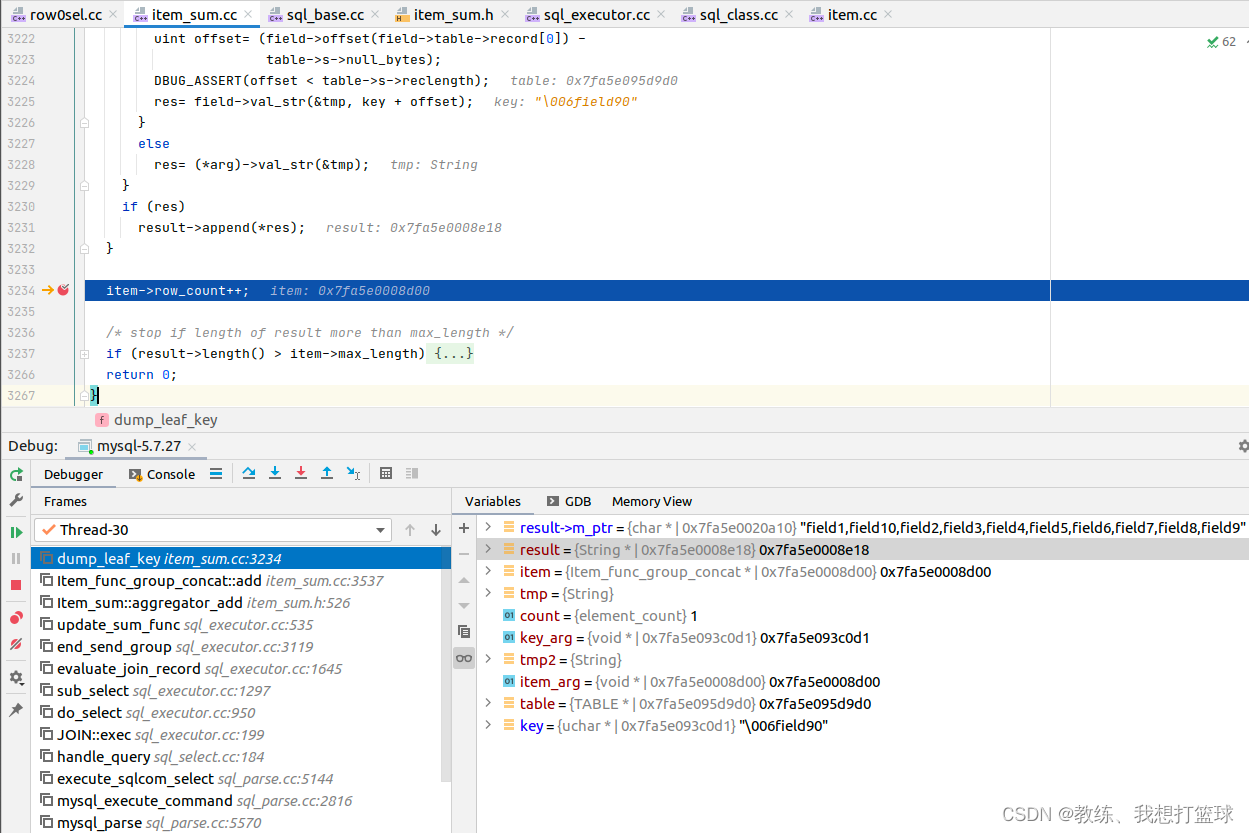
直到迭代完所有的 field1 结果如下
默认的结果顺序是由 索引field1 决定的
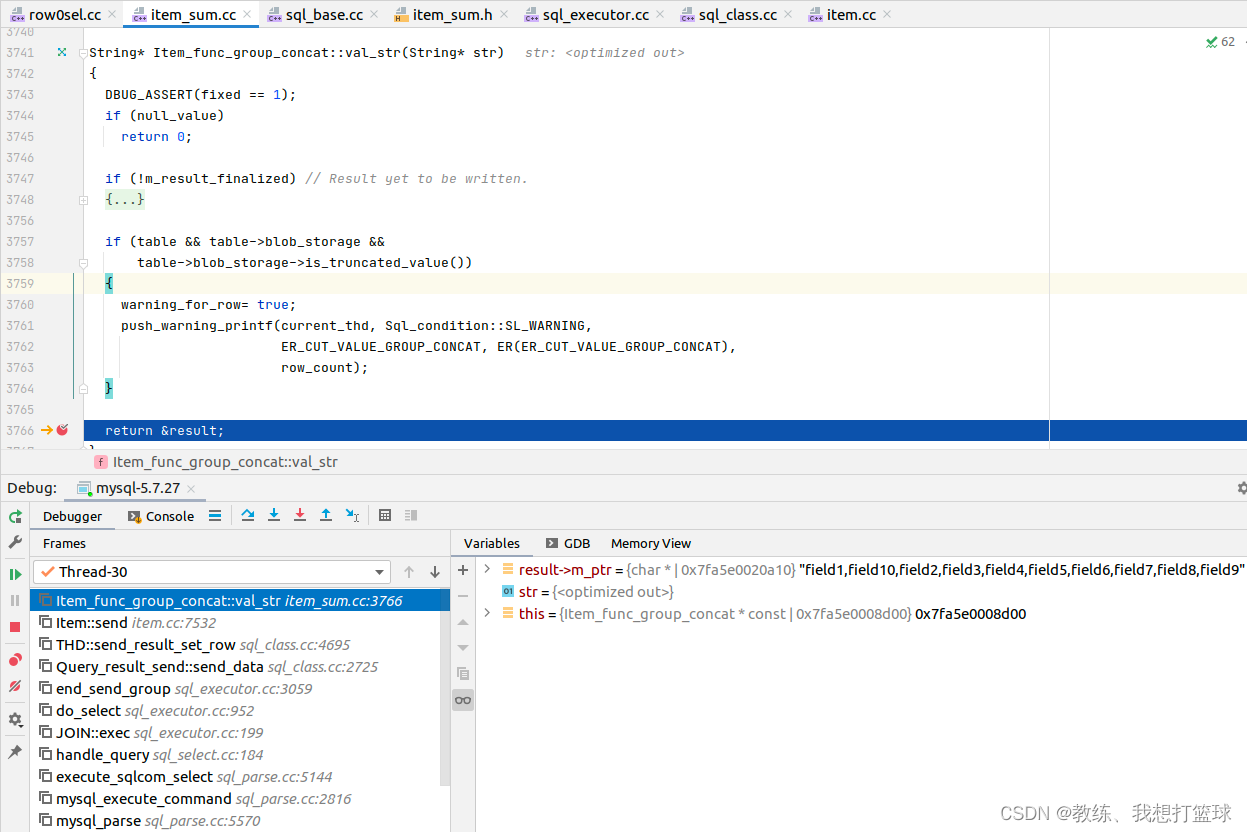
将结果响应回客户端
select group_concat(distinct)
执行 “select group_concat(distinct(field1)) from tz_test;” 如下
这里主要看一下 group_concat(distinct) 的实现
如果是增加了 distinct, group_concat 这边的实现有一些调整
将数据放到了 unique_filter 中, 然后 需要获取数据的时候从 unique_filter 中遍历数据, 返回

遍历到 field1索引记录 的最后一项
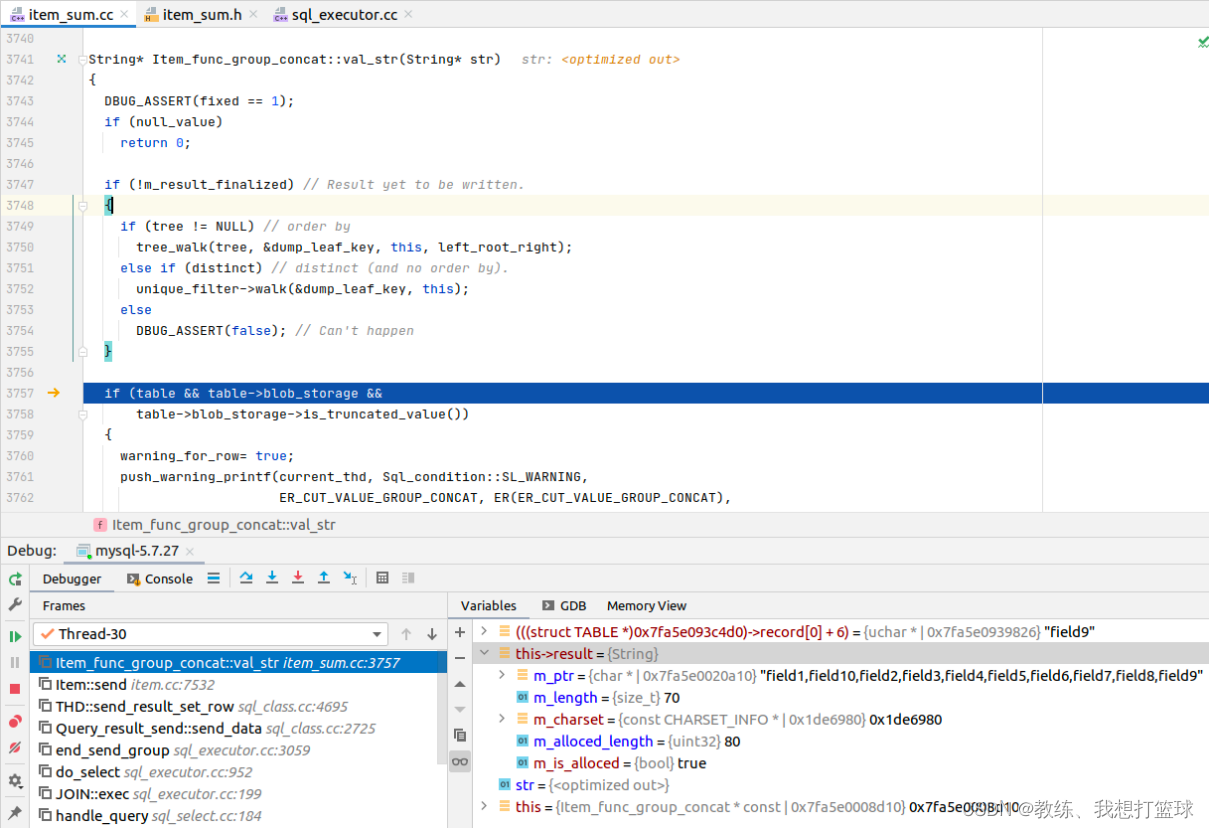
获取数据的情况如下, unique_filter->walk 遍历了采集的数据, 然后根据 “,” 来进行 join, 最终将结果存放于 this->result
完
这篇关于31 select max/min/avg/sum/count/group_concat 的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





